Tutorial: Laden von Daten und Ausführen von Abfragen auf einem Apache Spark-Cluster in Azure HDInsight
In diesem Tutorial erfahren Sie, wie Sie auf der Grundlage einer CSV-Datei einen Dataframe erstellen und interaktive Spark SQL-Abfragen für einen Apache Spark-Cluster in Azure HDInsight ausführen. In Spark ist ein Dataframe eine verteilte Sammlung von Daten, die in benannten Spalten organisiert sind. Dataframe entspricht vom Konzept her einer Tabelle in einer relationalen Datenbank oder einem Datenrahmen in R/Python.
In diesem Tutorial lernen Sie Folgendes:
- Erstellen eines Dataframes aus einer CSV-Datei
- Ausführen von Abfragen gegen Dataframes
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Weitere Informationen finden Sie unter Erstellen eines Apache Spark-Clusters.
Erstellen eines Jupyter Notebooks
Jupyter Notebook ist eine interaktive Notebook-Umgebung, die verschiedene Programmiersprachen unterstützt. Das Notebook ermöglicht Ihnen, mit Ihren Daten zu interagieren, Code mit Markdowntext zu kombinieren und einfache Visualisierungen durchzuführen.
Bearbeiten Sie die URL
https://SPARKCLUSTER.azurehdinsight.net/jupyter, indem SieSPARKCLUSTERdurch den Namen Ihres Spark-Clusters ersetzen. Geben Sie dann die bearbeitete URL in einem Webbrowser ein. Geben Sie die Anmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden.Wählen Sie auf der Jupyter-Webseite für Spark 2.4-Cluster die Option Neu>PySpark aus, um ein Notebook zu erstellen. Wählen Sie für das Spark 3.1-Release die Option Neu>PySpark3 aus, um ein Notebook zu erstellen, da der PySpark-Kernel in Spark 3.1 nicht mehr verfügbar ist.
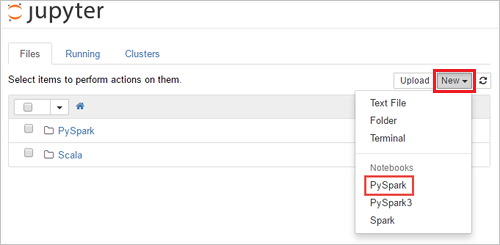
Es wird ein neues Notebook erstellt und geöffnet, das den Namen „Untitled(
Untitled.ipynb)“ hat.Hinweis
Wenn Sie den PySpark- oder PySpark3-Kernel zum Erstellen eines Notebooks verwenden, wird die
spark-Sitzung automatisch für Sie erstellt, wenn Sie die erste Codezelle ausführen. Die Sitzung muss nicht explizit erstellt werden.
Erstellen eines Dataframes aus einer CSV-Datei
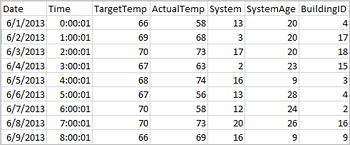
Anwendungen können Dataframes direkt auf der Grundlage von Dateien oder Ordnern im Remotespeicher (etwa in Azure Storage oder Azure Data Lake Storage), auf der Grundlage einer Hive-Tabelle oder auf der Grundlage anderer von Spark unterstützter Datenquellen (beispielsweise Azure Cosmos DB, Azure SQL-Datenbank, DW usw.) erstellen. Der folgende Screenshot zeigt eine Momentaufnahme der in diesem Tutorial verwendeten HVAC.csv-Datei. Die CSV-Datei enthält alle HDInsight Spark-Cluster. Die Daten erfassen die Temperaturunterschiede in einigen Gebäuden.
Fügen Sie den folgenden Code in eine leere Zelle des Jupyter Notebooks ein, und drücken Sie UMSCHALT+EINGABE, um den Code auszuführen. Mit dem Code werden die Typen importiert, die für dieses Szenario benötigt werden:
from pyspark.sql import * from pyspark.sql.types import *Wenn Sie eine interaktive Abfrage in Jupyter ausführen, wird in der Titelleiste Ihres Webbrowserfensters oder Ihrer Registerkarte neben dem Notebooktitel der Status (Beschäftigt) angezeigt. Sie sehen auch einen gefüllten Kreis neben dem PySpark-Text in der oberen rechten Ecke. Wenn der Auftrag abgeschlossen ist, wird ein Kreis ohne Füllung angezeigt.
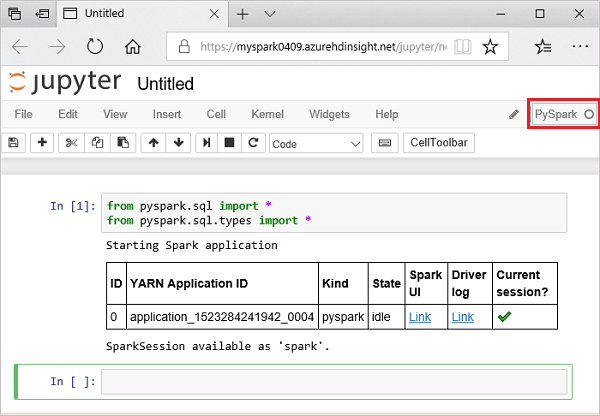
Beachten Sie die zurückgegebene Sitzungs-ID. In der obigen Abbildung lautet die Sitzungs-ID 0. Sie können die Sitzungsdetails bei Bedarf auch abrufen, indem Sie zu
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementsnavigieren. Dabei steht „CLUSTERNAME“ für den Namen Ihres Spark-Clusters und „ID“ für Ihre Sitzungs-ID.Führen Sie den folgenden Code aus, um einen Dataframe und eine temporäre Tabelle (hvac) zu erstellen.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Ausführen von Abfragen für datanami
Nach dem Erstellen der Tabelle führen Sie eine interaktive Abfrage für die Daten aus.
Führen Sie den folgenden Code in einer leeren Zelle des Notebooks aus:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Die folgende Ausgabe in Tabellenform wird angezeigt.
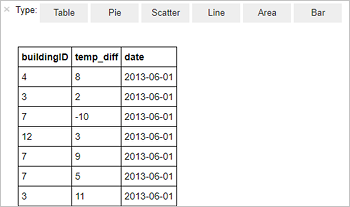
Sie können die Ergebnisse auch in anderen Visualisierungen anzeigen. Wählen Sie zum Anzeigen eines Bereichsdiagramms für die gleiche Ausgabe Bereich aus, und legen Sie die anderen Werte wie gezeigt fest.
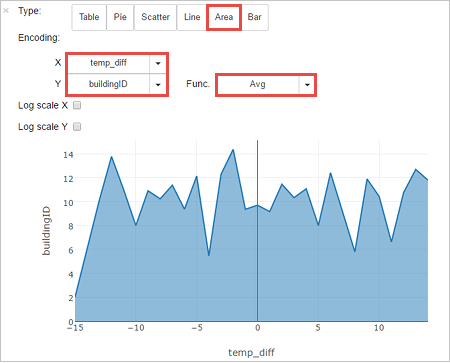
Navigieren Sie auf der Menüleiste des Notebooks zu File (Datei)>Save and Checkpoint (Speichern und Prüfpunkt).
Wenn Sie jetzt mit dem nächsten Tutorial fortfahren, lassen Sie das Notebook geöffnet. Fahren Sie andernfalls das Notebook herunter, um die Clusterressourcen freizugeben. Navigieren Sie dazu auf der Menüleiste des Notebooks zu File (Datei)>Close and Halt (Schließen und anhalten) aus.
Bereinigen von Ressourcen
Da Ihre Daten und Jupyter Notebooks bei Verwendung von HDInsight in Azure Storage oder Azure Data Lake Storage gespeichert werden, können Sie einen Cluster problemlos löschen, wenn er nicht verwendet wird. Für einen HDInsight-Cluster fallen auch dann Gebühren an, wenn er nicht verwendet wird. Da die Gebühren für den Cluster erheblich höher sind als die Kosten für den Speicher, ist es sinnvoll, nicht verwendete Cluster zu löschen. Wenn Sie vorhaben, sofort mit dem nächsten Tutorial fortzufahren, können Sie den Cluster beibehalten.
Öffnen Sie den Cluster im Azure-Portal, und wählen Sie Löschen aus.
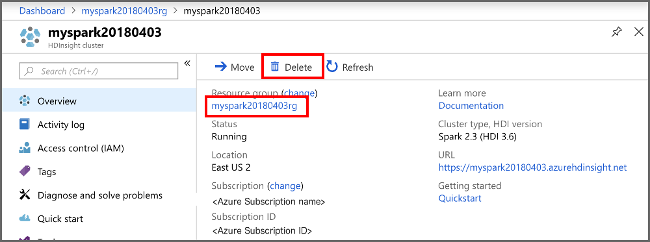
Sie können auch den Namen der Ressourcengruppe auswählen, um die Seite für die Ressourcengruppe zu öffnen, und dann Ressourcengruppe löschen auswählen. Indem Sie die Ressourcengruppe löschen, löschen Sie sowohl den HDInsight Spark-Cluster als auch das Standardspeicherkonto.
Nächste Schritte
In diesem Tutorial haben Sie erfahren, wie Sie auf der Grundlage einer CSV-Datei einen Datenrahmen erstellen und interaktive Spark SQL-Abfragen für einen Apache Spark-Cluster in Azure HDInsight ausführen. Fahren Sie mit dem nächsten Artikel fort, um zu erfahren, wie die in Apache Spark registrierten Daten in ein BI-Analyse-Tool wie Power BI gezogen werden können.