Übersicht über Apache Spark-Streaming
Apache Spark Streaming stellt Datenstromverarbeitung auf HDInsight-Spark-Clustern bereit. Dabei wird garantiert, dass jedes Eingabeereignis genau einmal verarbeitet wird, selbst wenn ein Knotenfehler auftritt. Ein Spark-Datenstrom ist ein Auftrag mit langer Ausführungszeit, der Eingabedaten aus einer Vielzahl von Quellen empfängt, einschließlich Azure Event Hubs. Außerdem: Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, rohe TCP-Sockets oder aus der Überwachung von Apache Hadoop YARN-Dateisystemen. Im Gegensatz zu einem rein ereignisgesteuerten Prozess, gruppiert ein Spark-Datenstrom Eingabedaten in Zeitfenster, z. B. in einen 2-Sekunden-Slice. Anschließend werden die einzelnen Gruppen von Daten mit map-, reduce-, join- und extract-Vorgängen transformiert. Der Spark-Stream schreibt die transformierten Daten dann in Dateisysteme, Datenbanken, Dashboards und die Konsole.
Spark Streaming-Anwendungen müssen einen Sekundenbruchteil warten, bis alle micro-batch-Instanzen von Ereignissen erfasst wurden und bevor dieser Batch zur Verarbeitung übermittelt wird. Im Gegensatz dazu verarbeitet eine ereignisgesteuerte Anwendung jedes Ereignis sofort. Die Spark-Streaming-Latenzzeit liegt in der Regel unter wenigen Sekunden. Die Vorteile des Mikrobatchansatzes sind eine effizientere Datenverarbeitung und eine Vereinfachung aggregierter Berechnungen.
Einführung in DStream
Spark-Streaming stellt einen kontinuierlichen Strom von eingehenden Daten mithilfe eines als DStream bezeichneten diskretisierten Datenstroms dar. Ein DStream kann aus Eingabequellen wie Event Hubs oder Kafka oder durch Anwendung von Transformationen auf einen anderen DStream erstellt werden.
Ein DStream stellt eine Abstraktionsebene über den Ereignisrohdaten dar.
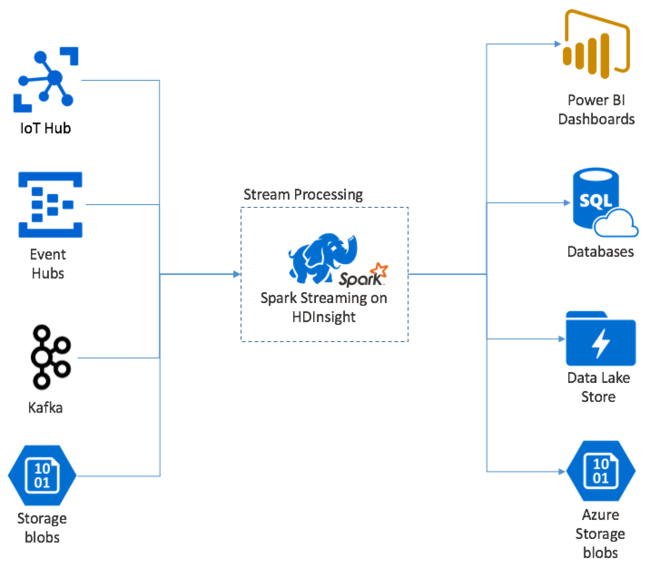
Am Anfang steht ein einzelnes Ereignis, z.B. ein Temperaturwert auf einem vernetzten Thermostat. Wenn dieses Ereignis Ihre Spark-Streaming-Anwendung erreicht, wird es auf zuverlässige Weise gespeichert (auf mehreren Knoten repliziert). Diese Fehlertoleranz gewährleistet, dass der Ausfall eines einzelnen Knotens nicht zum Verlust des Ereignisses führt. Spark Core nutzt eine Datenstruktur, die Daten auf mehrere Knoten im Cluster verteilt. Dabei speichert jeder Knoten im Allgemeinen seine eigenen Daten im Arbeitsspeicher, um die optimale Leistung zu erzielen. Diese Datenstruktur wird als Resilient Distributed Dataset (RDD) bezeichnet.
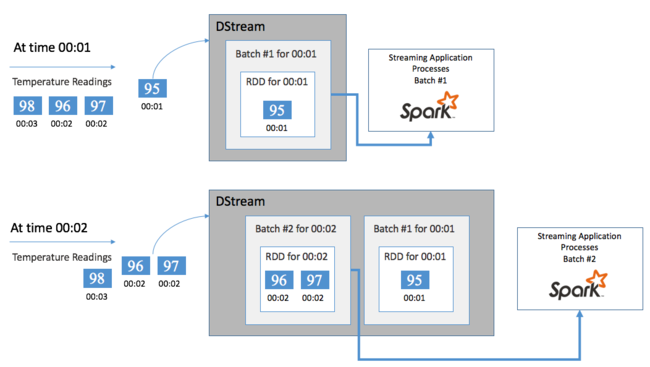
Jedes RDD stellt Ereignisse dar, die in einem als Batchintervall bezeichneten benutzerdefinierten Zeitraum gesammelt wurden. Wenn ein Batchintervall verstreicht, wird ein neues RDD erzeugt, das alle Daten dieses Intervalls enthält. Die kontinuierliche Gruppe von RDDs wird in einem DStream gesammelt. Wenn das Batchintervall z.B. eine Sekunde lang ist, gibt Ihr DStream jede Sekunde einen Batch aus, der ein RDD mit allen während dieser Sekunde erfassten Daten enthält. Bei der DStream-Verarbeitung tritt das Temperaturereignis in einem dieser Batches auf. Eine Spark-Streaming-Anwendung verarbeitet die Batches, die die Ereignisse enthalten, und führt die endgültigen Aktionen an den Daten durch, die in den einzelnen RDDs gespeichert werden.
Struktur einer Spark-Streaming-Anwendung
Eine Spark Streaming-Anwendung ist eine Anwendung mit langer Ausführungszeit, die Daten von Erfassungsquellen empfängt. Sie wendet Transformationen zur Verarbeitung der Daten an und pusht diese Daten an mindestens ein Ziel. Die Struktur einer Spark-Streaming-Anwendung besteht aus einem statischen und einem dynamischen Teil. Der statische Teil definiert, woher die Daten stammen, wie die Daten verarbeitet werden sollen und wo die Ergebnisse gespeichert werden sollen. Der dynamische Teil führt die Anwendung unendlich lange aus und wartet auf das Beendigungssignal.
Die folgende einfache Anwendung empfängt beispielsweise eine Textzeile über einen TCP-Socket und zählt, wie oft die einzelnen Wörter vorkommen.
Definieren der Anwendung
Die Definition der Anwendungslogik besteht aus vier Schritten:
- Erstellen eines StreamingContext.
- Erstellen eines DStream aus dem StreamingContext.
- Anwenden von Transformationen auf den DStream.
- Ausgeben der Ergebnisse.
Diese Definition ist statisch, und Daten werden erst dann verarbeitet, wenn Sie die Anwendung ausführen.
Erstellen eines StreamingContext
Erstellen Sie einen StreamingContext aus dem SparkContext, der auf Ihren Cluster verweist. Beim Erstellen eines StreamingContext geben Sie z.B. die Größe des Batches in Sekunden an:
import org.apache.spark._
import org.apache.spark.streaming._
val ssc = new StreamingContext(sc, Seconds(1))
Erstellen eines DStream
Mit der StreamingContext-Instanz erstellen Sie einen Eingabe-DStream für Ihre Eingabequelle. In diesem Fall überwacht die Anwendung das Erscheinen neuer Dateien im angefügten Standardspeicher.
val lines = ssc.textFileStream("/uploads/Test/")
Anwenden von Transformationen
Sie implementieren die Verarbeitung durch Anwenden von Transformationen auf den DStream. Diese Anwendung empfängt immer eine Textzeile von der Datei, unterteilt alle Zeilen in Wörter und verwendet dann ein map-reduce-Muster, um die Anzahl der Vorkommnisse der einzelnen Wörter zu zählen.
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
Ausgeben von Ergebnissen
Senden Sie die Transformationsergebnisse durch Anwenden von Ausgabevorgängen an die Zielsysteme. In diesem Fall wird das Ergebnis jedes Berechnungsdurchlaufs in der Konsole ausgegeben.
wordCounts.print()
Ausführen der Anwendung
Starten Sie die Streaminganwendung, und führen Sie sie aus, bis ein Beendigungssignal empfangen wird.
ssc.start()
ssc.awaitTermination()
Ausführliche Informationen über die Spark Streaming-API finden Sie unter Apache Spark Streaming Programming Guide (Programmierleitfaden zu Apache Spark Streaming).
Die folgende Beispielanwendung ist eigenständig, sodass Sie sie in einem Jupyter Notebook ausführen können. In diesem Beispiel wird eine simulierte Datenquelle in der Klasse DummySource erstellt, die alle fünf Sekunden den Wert eines Zählers und die aktuelle Zeit in Millisekunden ausgibt. Ein neues StreamingContext-Objekt verfügt über ein Batchintervall von 30 Sekunden. Jedes Mal, wenn ein Batch erstellt wird, untersucht die Streaminganwendung das erzeugte RDD. Dann wird das RDD in ein Spark-DataFrame konvertiert und eine temporäre Tabelle wird über dem DataFrame erstellt.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process RDDs in the batch
stream.foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Warten Sie nach dem Starten der Anwendung oben etwa 30 Sekunden lang. Dann können Sie den DataFrame in regelmäßigen Abständen abfragen, um den im Batch vorhandenen aktuellen Satz von Werten anzuzeigen, indem Sie beispielsweise die folgende SQL-Abfrage verwenden:
%%sql
SELECT * FROM demo_numbers
Die resultierende Ausgabe sollte der folgenden ähneln:
| value | time |
|---|---|
| 10 | 1497314465256 |
| 11 | 1497314470272 |
| 12 | 1497314475289 |
| 13 | 1497314480310 |
| 14 | 1497314485327 |
| 15 | 1497314490346 |
Es sind sechs Werte, da die DummySource alle 5 Sekunden einen Wert erstellt und die Anwendung alle 30 Sekunden einen Batch ausgibt.
Gleitende Fenster
Verwenden Sie die in Spark Streaming enthaltenen sliding window-Vorgänge, um Aggregationsberechnungen für DStream über einen Zeitraum durchzuführen, um beispielsweise die durchschnittliche Temperatur der letzten zwei Sekunden abzurufen. Ein gleitendes Fenster hat eine Dauer (Fensterlänge) und ein Intervall, in dem der Inhalt des Fensters ausgewertet wird (Gleitintervall).
Gleitende Fenster können sich überschneiden, sodass Sie beispielsweise ein Fenster mit einer Länge von zwei Sekunden definieren können, das einmal pro Sekunde verschoben wird. Diese Aktion bedeutet, dass das Fenster jedes Mal, wenn Sie eine Aggregationsberechnung durchführen, Daten der letzten Sekunde des vorherigen Fensters sowie die neuen Daten der nächsten Sekunde enthält.
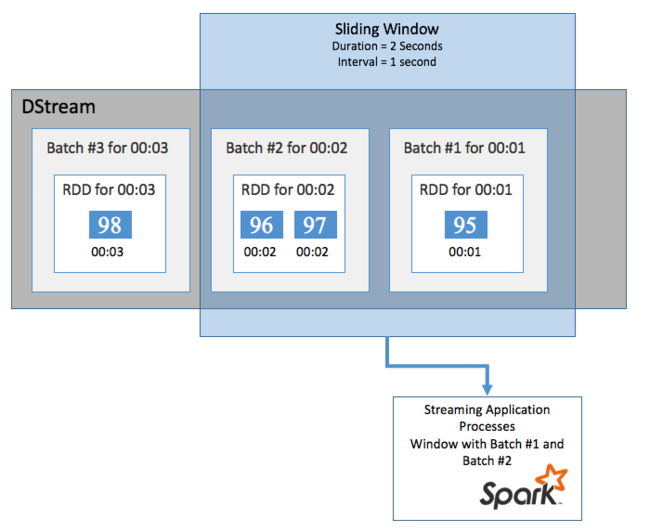
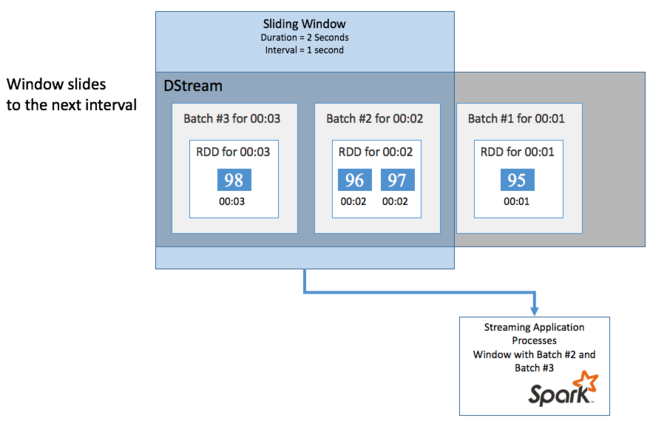
Im folgenden Beispiel wird der Code aktualisiert, der das DummySource-Objekt verwendet, um die Batches in einem Fenster mit einer Dauer von einer Minute und einem Gleiten in einer Minute zu sammeln.
class DummySource extends org.apache.spark.streaming.receiver.Receiver[(Int, Long)](org.apache.spark.storage.StorageLevel.MEMORY_AND_DISK_2) {
/** Start the thread that simulates receiving data */
def onStart() {
new Thread("Dummy Source") { override def run() { receive() } }.start()
}
def onStop() { }
/** Periodically generate a random number from 0 to 9, and the timestamp */
private def receive() {
var counter = 0
while(!isStopped()) {
store(Iterator((counter, System.currentTimeMillis)))
counter += 1
Thread.sleep(5000)
}
}
}
// A batch is created every 30 seconds
val ssc = new org.apache.spark.streaming.StreamingContext(spark.sparkContext, org.apache.spark.streaming.Seconds(30))
// Set the active SQLContext so that we can access it statically within the foreachRDD
org.apache.spark.sql.SQLContext.setActive(spark.sqlContext)
// Create the stream
val stream = ssc.receiverStream(new DummySource())
// Process batches in 1 minute windows
stream.window(org.apache.spark.streaming.Minutes(1)).foreachRDD { rdd =>
// Access the SQLContext and create a table called demo_numbers we can query
val _sqlContext = org.apache.spark.sql.SQLContext.getOrCreate(rdd.sparkContext)
_sqlContext.createDataFrame(rdd).toDF("value", "time")
.registerTempTable("demo_numbers")
}
// Start the stream processing
ssc.start()
Nach der ersten Minute ergibt dies zwölf Einträge – sechs Einträge aus jedem der beiden im Fenster gesammelten Batches.
| value | time |
|---|---|
| 1 | 1497316294139 |
| 2 | 1497316299158 |
| 3 | 1497316304178 |
| 4 | 1497316309204 |
| 5 | 1497316314224 |
| 6 | 1497316319243 |
| 7 | 1497316324260 |
| 8 | 1497316329278 |
| 9 | 1497316334293 |
| 10 | 1497316339314 |
| 11 | 1497316344339 |
| 12 | 1497316349361 |
Zu den in der Spark-Streaming-API verfügbaren „Gleitendes Fenster“-Funktionen zählen „window“, countByWindow, reduceByWindow und countByValueAndWindow. Weitere Informationen zu diesen Funktionen finden Sie unter Transformations on DStreams (DStream-Transformationen).
Setzen von Prüfpunkten
Um Resilienz und Fehlertoleranz zu gewährleisten, stellt das Spark-Streaming mithilfe von Prüfpunkten sicher, dass die Datenstromverarbeitung auch bei Knotenfehlern kontinuierlich durchgeführt werden kann. Spark erstellt Prüfpunkte für dauerhaften Speicher (Azure Storage oder Data Lake Storage). Diese Prüfpunkte speichern Metadaten von Spark Streaming-Anwendungen wie die Konfiguration und die von der Anwendung definierten Vorgänge. Außerdem werden Batches gespeichert, die in der Warteschlange eingereiht waren, aber noch nicht verarbeitet wurden. Manchmal beinhalten die Prüfpunkte auch das Speichern der Daten in den RDDs, um die Neuerstellung des Zustands der Daten aus den Daten, die in den von Spark verwalteten RDDs vorhanden sind, zu beschleunigen.
Bereitstellen von Spark-Streaminganwendungen
In der Regel erstellen Sie Spark Streaming-Anwendungen lokal in einer JAR-Datei. Anschließend stellen Sie sie in Spark in HDInsight bereit, indem Sie die JAR-Datei in den angefügten Standardspeicher kopieren. Sie können Ihre Anwendung mit den LIVY-REST-APIs, die in Ihrem Cluster verfügbar sind, mit einem POST-Vorgang starten. Der Text des POST-Vorgangs enthält ein JSON-Dokument, das den Pfad zu Ihrer JAR-Datei und den Namen der Klasse bereitstellt, deren Main-Methode die Streaminganwendung definiert und ausführt. Außerdem kann es optional die Ressourcenanforderungen des Auftrags enthalten (z. B. die Anzahl der Executor-Threads, Arbeitsspeicher und Kerne). Außerdem sind jegliche Konfigurationseinstellungen enthalten, die Ihr Anwendungscode erfordert.
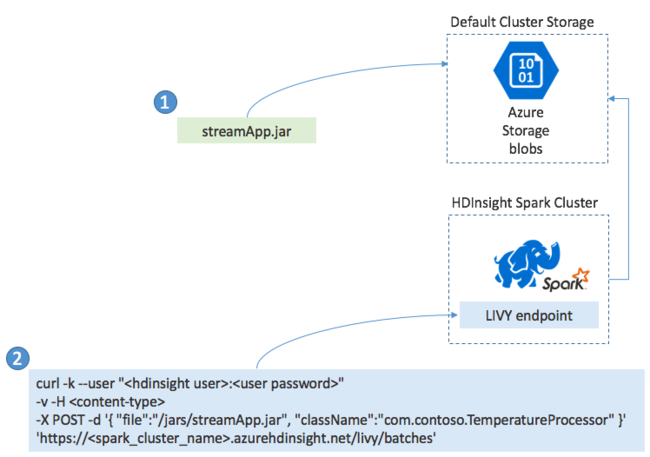
Der Status aller Anwendungen kann auch mit einer GET-Anforderung an einem LIVY-Endpunkt überprüft werden. Außerdem können Sie eine ausgeführte Anwendung durch das Senden einer DELETE-Anforderung an den LIVY-Endpunkt beenden. Weitere Informationen zur LIVY-API finden Sie unter Übermitteln von Remoteaufträgen mit Apache LIVY