Optimierung der Speicherauslastung für Apache Spark
In diesem Artikel wird erläutert, wie Sie die Speicherverwaltung Ihres Apache Spark-Clusters optimieren, um die optimale Leistung für Azure HDInsight zu erzielen.
Übersicht
Spark platziert Daten im Arbeitsspeicher. Aus diesem Grund ist die Verwaltung von Arbeitsspeicherressourcen ein sehr wichtiger Aspekt beim Optimieren der Ausführung von Spark-Aufträgen. Es gibt mehrere Verfahren, die Sie anwenden können, um den Arbeitsspeicher Ihres Clusters effizient zu nutzen.
- Legen Sie kleinere Datenpartitionen an, und berücksichtigen Sie in Ihrer Partitionierungsstrategie die Größe, den Typ und die Verteilung Ihrer Daten.
- Erwägen Sie die Verwendung der neueren, effizienteren
Kryo data serializationanstelle der standardmäßigen Java-Serialisierung. - Verwenden Sie vorzugsweise YARN, da dies
spark-submitnach Batches aufteilt. - Überwachen und optimieren Sie die Spark-Konfigurationseinstellungen.
Die folgende Abbildung zeigt die Spark-Arbeitsspeicherstruktur und einige wichtige Arbeitsspeicherparameter für den Executor.
Überlegungen zum Spark-Arbeitsspeicher
Bei Verwendung von Apache Hadoop YARN steuert YARN den von allen Containern auf jedem Spark-Knoten verwendeten Gesamtarbeitsspeicher. Das folgende Diagramm zeigt die wichtigsten Objekte und ihre Beziehungen.
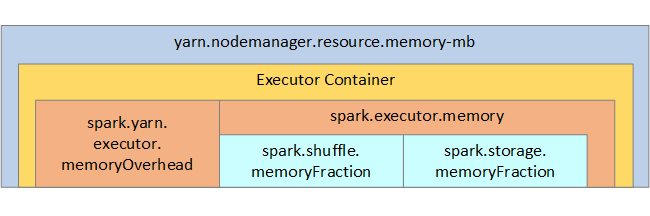
Um Meldungen zu unzureichendem Arbeitsspeicher zu beheben, versuchen Sie Folgendes:
- Überprüfen Sie die Shufflevorgänge in der DAG-Verwaltung. Verringern Sie die Datenmenge durch zuordnungsseitige Reduktion, partitionieren Sie Quelldaten vorab (oder legen Sie sie in Buckets ab), maximieren Sie einzelne Shufflevorgänge, und verringern Sie die Menge an gesendeten Daten.
- Verwenden Sie
ReduceByKeymit festem Arbeitsspeicherlimit anstelle vonGroupByKey, das Aggregationen, Fenstervorgänge und weitere Funktionen bietet, aber ein ungebundenes Arbeitsspeicherlimit aufweist. - Verwenden Sie
TreeReduce, welches einen größeren Teil der Verarbeitung in den Executors oder Partitionen ausführt, anstelle vonReduce, das die gesamte Arbeit im Treiber erledigt. - Nutzen Sie eher DataFrames als die Low-Level-RDD-Objekte.
- Erstellen Sie ComplexTypes, die Aktionen kapseln, wie z.B. „Top N“, verschiedene Aggregationen oder Fenstervorgänge.
Informationen zu weiteren Schritten für die Problembehandlung finden Sie unter OutOfMemoryError-Ausnahmen für Apache Spark in Azure HDInsight.