Komponente Daten importieren
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer.
Verwenden Sie diese Komponente, um Daten aus vorhandenen Cloud-Datendiensten in eine Pipeline für maschinelles Lernen zu laden.
Hinweis
Alle von dieser Komponente bereitgestellten Funktionen können von Datenspeichern und Datasets auf der Landing Page des Arbeitsbereichs ausgeführt werden. Die Verwendung von Datenspeichern und Datasets wird empfohlen, da hierbei zusätzliche Features wie Datenüberwachung eingeschlossen sind. Weitere Informationen finden Sie in den Artikeln Zugreifen auf Daten und Registrieren von Datasets. Nachdem Sie ein Dataset registriert haben, finden Sie es auf der Designer-Oberfläche in der Kategorie Datasets ->My Datasets (Meine Datasets). Diese Komponente ist für Studio(classic)-Benutzer reserviert, um eine vertraute Erfahrung zu gewährleisten.
Die Komponente Datenimport unterstützt das Lesen von Daten aus folgenden Quellen:
- URL über HTTP
- Azure-Cloudspeicher über Datenspeicher)
- Azure-Blobcontainer
- Azure-Dateifreigabe
- Azure Data Lake
- Azure Data Lake Gen2
- Azure SQL-Datenbank
- Azure PostgreSQL
Bevor Sie Cloudspeicher verwenden können, müssen Sie zunächst einen Datenspeicher in Ihrem Azure Machine Learning-Arbeitsbereich registrieren. Weitere Informationen hierzu finden Sie unter Zugreifen auf Daten.
Nachdem Sie die gewünschten Daten definiert und eine Verbindung mit der Quelle hergestellt haben, leitet Import Data den Datentyp jeder Spalte basierend auf den darin enthaltenen Werten ab und lädt die Daten in Ihre Designer-Pipeline. Import Data gibt ein Dataset aus, das mit beliebigen Designer-Pipelines verwendet werden kann.
Wenn sich Ihre Quelldaten ändern, können Sie das Dataset aktualisieren und neue Daten hinzufügen, indem Sie Import Data erneut ausführen.
Warnung
Wenn sich Ihr Arbeitsbereich in einem virtuellen Netzwerk befindet, müssen Sie Ihre Datenspeicher so konfigurieren, dass sie die Features des Designers zur Datenvisualisierung verwenden. Weitere Informationen zur Verwendung von Datenspeichern und Datasets in virtuellen Netzwerken finden Sie unter Verwenden von Azure Machine Learning Studio in einem virtuellen Azure-Netzwerk.
Konfigurieren von „Import Data“ (Daten importieren)
Fügen Sie die Komponente Datenimport zu Ihrer Pipeline hinzu. Sie finden diese Komponente in der Kategorie Dateneingang und -ausgang im Designer.
Wählen Sie die Komponente aus, um das rechte Fenster zu öffnen.
Wählen Sie Datenquelle und dann den Datenquellentyp aus. Dabei kann es sich um „HTTP“ oder „Datenspeicher“ handeln.
Wenn Sie „Datenspeicher“ auswählen, können Sie vorhandene Datenspeicher auswählen, die bereits in Ihrem Azure Machine Learning-Arbeitsbereich registriert sind, oder einen neuen Datenspeicher erstellen. Anschließend definieren Sie den Pfad der zu importierenden Daten im Datenspeicher. Sie können den Pfad problemlos durchsuchen, indem Sie Pfad durchsuchen auswählen.
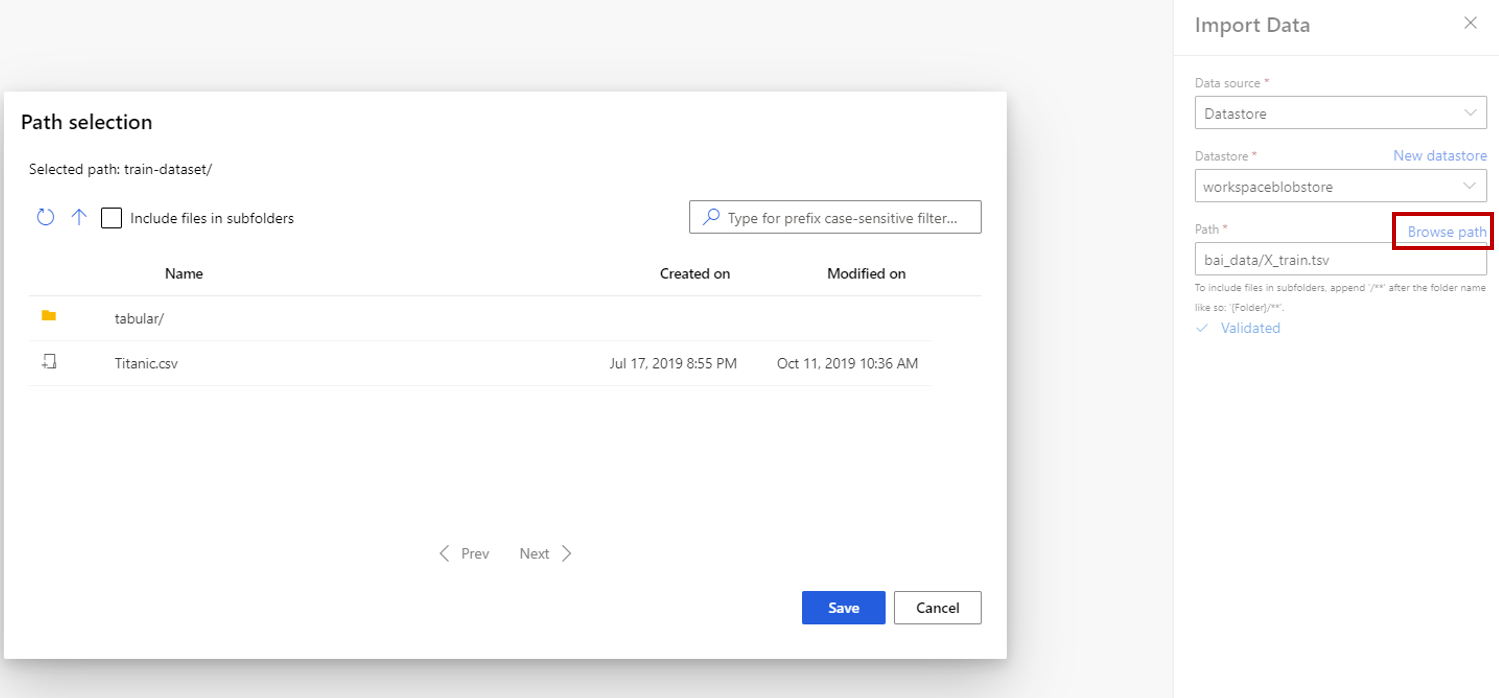
Hinweis
Die Komponente Datenimport ist nur für Tabellendaten. Wenn Sie mehrere tabellarische Datendateien einmal importieren möchten, müssen folgende Bedingungen erfüllt sein, damit keine Fehler auftreten:
- Wenn Sie alle Datendateien im Ordner einschließen möchten, müssen Sie
folder_name/**für Path (Pfad) eingeben. - Alle Datendateien müssen in Unicode-8 codiert sein.
- Bei allen Datendateien müssen Spaltenanzahl und Spaltennamen identisch sein.
- Das Ergebnis des Importierens mehrerer Datendateien ist, alle Zeilen aus mehreren Dateien in der richtigen Reihenfolge zu verketten.
- Wenn Sie alle Datendateien im Ordner einschließen möchten, müssen Sie
Wählen Sie das Vorschauschema aus, um die Spalten zu filtern, die Sie einschließen möchten. Sie können auch erweiterte Einstellungen wie Trennzeichen in den Analyseoptionen definieren.

Das Kontrollkästchen Regenerate output (Ausgabe neu generieren) entscheidet, ob die Komponente ausgeführt werden soll, um die Ausgabe zur Laufzeit neu zu generieren.
Die Auswahl ist standardmäßig deaktiviert. Das bedeutet, dass das System die Ausgabe der letzten Ausführung wiederverwendet, um die Laufzeit zu verkürzen, wenn die Komponente zuvor mit denselben Parameter ausgeführt wurde.
Wenn diese Option ausgewählt wird, führt das System die Komponente erneut aus, um die Ausgabe erneut zu generieren. Wählen Sie also diese Option aus, wenn die zugrunde liegenden Daten im Speicher aktualisiert werden, um die neuesten Daten zu erhalten.
Übermitteln Sie die Pipeline.
Wenn die Daten durch Import Data in den Designer geladen werden, wird der Datentyp jeder Spalte basierend auf den darin enthaltenen Werten (numerisch oder kategorisch) abgeleitet.
Sofern eine Spaltenüberschrift vorhanden ist, wird diese zur Benennung der Spalten im Ausgabedataset verwendet.
Wenn keine Spaltenüberschriften in den Daten enthalten sind, werden neue Spaltennamen im Format col1, col2,... , coln* generiert.

Ergebnisse
Nachdem der Import abgeschlossen wurde, klicken Sie mit der rechten Maustaste auf das Ausgabedataset, und wählen Sie Visualize (Visualisieren) aus, um zu überprüfen, ob die Daten erfolgreich importiert wurden.
Wenn Sie die Daten zur Wiederverwendung speichern möchten, anstatt jedes Mal, wenn die Pipeline ausgeführt wird, einen neuen Datensatz zu importieren, wählen Sie das Symbol Datensatz registrieren unter der Registerkarte Ausgaben+Protokolle im rechten Bereich der Komponente. Wählen Sie einen Namen für das Dataset aus. Das gespeicherte Dataset behält die Daten zum Zeitpunkt der Speicherung bei. Das Dataset wird nicht aktualisiert, wenn die Pipeline erneut ausgeführt wird, selbst wenn sich das Dataset in der Pipeline ändert. Dies kann hilfreich sein, um Momentaufnahmen von Daten zu erstellen.
Nachdem Sie die Daten importiert haben, müssen sie möglicherweise für die Modellierung und Analyse weiter aufbereitet werden:
Verwenden Sie Edit Metadata (Metadaten bearbeiten), um Spaltennamen zu ändern, einen abweichenden Datentyp für eine Spalte festzulegen, oder um anzugeben, dass einige Spalten für Bezeichnungen oder Features stehen.
Verwenden Sie Select Columns in Dataset (Spalten im Dataset auswählen), um eine Teilmenge von Spalten auszuwählen, die während der Modellierung transformiert oder verwendet werden sollen. Die umgewandelten oder entfernten Spalten können mit Hilfe der Komponente Spalten hinzufügen leicht wieder in den ursprünglichen Datensatz eingefügt werden.
Verwenden Sie Partition and Sample (Partitionieren und Stichprobe entnehmen), um das Dataset zu unterteilen, ein Sampling durchzuführen oder um Top-N-Zeilen abzurufen.
Einschränkungen
Wenn Ihre Rückschlusspipeline die Komponente Datenimport enthält, wird sie aufgrund der Zugriffsbeschränkung auf den Datenspeicher bei der Bereitstellung am Echtzeitendpunkt automatisch entfernt.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.