Herstellen einer Verbindung mit Daten in Azure Machine Learning Studio
In diesem Artikel erfahren Sie, wie Sie mit Azure Machine Learning Studio auf Ihre Daten zugreifen. Stellen Sie eine Verbindung mit Ihren Daten in Azure-Speicherdiensten mit Azure Machine Learning-Datenspeichern her. Packen Sie dann diese Daten für ML-Workflowaufgaben mit Azure Machine Learning-Datasets.
In dieser Tabelle werden die Vorteile von Datenspeichern und Datasets definiert und zusammengefasst.
| Object | BESCHREIBUNG | Vorteile |
|---|---|---|
| Datenspeicher | Um eine sichere Verbindung mit Ihrem Speicherdienst in Azure herzustellen, speichern Sie Ihre Verbindungsinformationen (Abonnement-ID, Tokenautorisierung usw.) in dem Key Vault, der dem Arbeitsbereich zugeordnet ist. | Da Ihre Informationen sicher gespeichert sind, gefährden Sie keine Authentifizierungsanmeldeinformationen oder ursprünglichen Datenquellen, und Sie müssen diese Werte nicht mehr in Ihren Skripts hartcodieren. |
| Datasets | Durch Erstellen von Datasets erstellen Sie einen Verweis auf den Speicherort der Datenquelle zusammen mit einer Kopie der zugehörigen Metadaten. Mit Datasets können Sie während des Modelltrainings auf Daten zugreifen, Daten freigeben und mit anderen Benutzern zusammenarbeiten sowie Open-Source-Bibliotheken wie Pandas für die Datenuntersuchung verwenden. | Da Datasets nur langsam ausgewertet werden und die Daten am vorhandenen Speicherort verbleiben, speichern Sie eine einzige Kopie der Daten in Ihrem Speicher. Darüber hinaus entstehen keine zusätzlichen Speicherkosten, Sie vermeiden unbeabsichtigte Änderungen an Ihren ursprünglichen Datenquellen und verbessern die Leistung von ML-Workflows. |
Um zu erfahren, welche Rolle Datenspeicher und Datasets im Workflow für den Datenzugriff in Azure Machine Learning spielen, besuchen Sie Sicherer Zugriff auf Daten.
Weitere Informationen zum Azure Machine Learning Python SDK und eine Code-First-Erfahrung finden Sie unter:
- Herstellen einer Verbindung mit Azure-Speicherdiensten mit Datenspeichern
- Erstellen von Azure Machine Learning-Datasets
Voraussetzungen
Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Zugreifen auf Azure Machine Learning Studio
Ein Azure Machine Learning-Arbeitsbereich. Erstellen von Arbeitsbereichsressourcen
- Wenn Sie einen Arbeitsbereich erstellen, werden automatisch ein Azure-Blobcontainer und eine Azure-Dateifreigabe als Datenspeicher im Arbeitsbereich registriert. Sie erhalten die Namen
workspaceblobstoreundworkspacefilestore. Für ausreichende Blobspeicherressourcen wirdworkspaceblobstoreals Standarddatenspeicher festgelegt und bereits für die Verwendung konfiguriert. Wenn Sie weitere Blobspeicherressourcen benötigen, benötigen Sie ein Azure-Speicherkonto mit einem unterstützten Speichertyp.
- Wenn Sie einen Arbeitsbereich erstellen, werden automatisch ein Azure-Blobcontainer und eine Azure-Dateifreigabe als Datenspeicher im Arbeitsbereich registriert. Sie erhalten die Namen
Erstellen von Datenspeichern
Aus diesen Azure-Speicherlösungen können Sie Datenspeicher erstellen. Für nicht unterstützte Speicherlösungen sowie zur Einsparung von Kosten für ausgehende Daten bei ML-Experimenten müssen Sie Ihre Daten in eine unterstützte Azure-Speicherlösung verschieben. Weitere Informationen zu Datenspeichern finden Sie unter dieser Ressource.
Sie können Datenspeicher mit auf Anmeldeinformationen basierendem Zugriff oder identitätsbasiertem Zugriff erstellen.
Erstellen Sie einen neuen Datenspeicher mit Azure Machine Learning Studio.
Wichtig
Wenn sich Ihr Datenspeicherkonto in einem virtuellen Netzwerk befindet, sind zusätzliche Konfigurationsschritte erforderlich, um sicherzustellen, dass von Studio auf Ihre Daten zugegriffen werden kann. Besuchen Sie Netzwerkisolation und Datenschutz, um weitere Informationen zu den entsprechenden Konfigurationsschritten zu finden.
- Melden Sie sich bei Azure Machine Learning Studio an.
- Wählen Sie Daten im linken Bereich unter Ressourcen aus.
- Wählen Sie oben Datenspeicher aus.
- Wählen Sie +Erstellen aus.
- Füllen Sie das Formular aus, um einen neuen Datenspeicher zu erstellen und zu registrieren. Das Formular aktualisiert sich ausgehend von den ausgewählten Optionen für den Azure-Speichertyp und den Authentifizierungstyp intelligent selbst. Um weitere Informationen dazu zu erhalten, wo Sie die zum Ausfüllen dieses Formulars erforderlichen Authentifizierungsanmeldeinformationen finden, besuchen Sie den Abschnitt Speicherzugriff und Berechtigungen.
Dieser Screenshot zeigt den Erstellungsbereich Azure-Blobdatenspeicher:


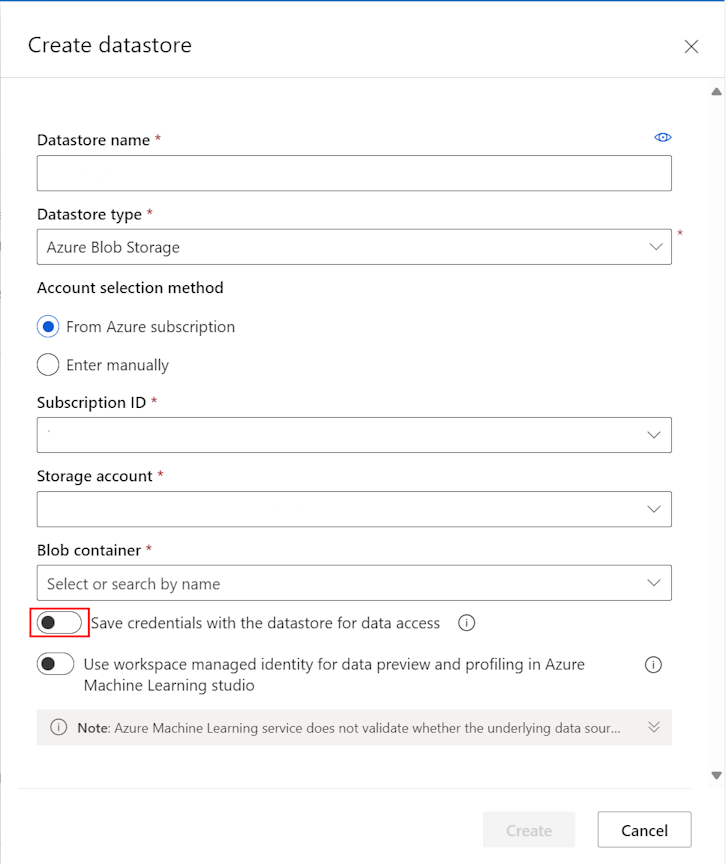
Erstellen von Datenressourcen
Nachdem Sie einen Datenspeicher erstellt haben, erstellen Sie ein Dataset, um mit Ihren Daten zu interagieren. Datasets packen Ihre Daten in ein selten ausgewertetes nutzbares Objekt für Aufgaben des maschinellen Lernens wie z. B. das Training. Weitere Informationen zu Datasets finden Sie unter Erstellen von Azure Machine Learning-Datasets.
Es gibt zwei Typen von Datasets: FileDataset und TabularDataset. FileDatasets erstellen Verweise auf mindestens eine Datei oder auf öffentliche URLs. TabularDatasets stellen Ihre Daten in einem Tabellenformat dar. Sie können TabularDatasets aus
- .csv
- .tsv
- .parquet
- .json Dateien und aus SQL-Abfrageergebnissen erstellen.
In den folgenden Schritten wird beschrieben, wie ein Dataset im Azure Machine Learning Studio erstellt wird.
Hinweis
Datasets, die über Azure Machine Learning Studio erstellt werden, werden automatisch beim Arbeitsbereich registriert.
Navigieren Sie zu Azure Machine Learning Studio.
Wählen Sie unter Ressourcen im linken Navigationsbereich die Option Daten aus. Wählen Sie auf der Registerkarte „Datenressourcen“ die Option „Erstellen“ aus.

Geben Sie der Datenressource einen Namen, und fügen Sie optional eine Beschreibung hinzu. Wählen Sie dann unter Typ einen Datasettyp aus, entweder Datei oder Tabellarisch.

Der Bereich Datenquelle wird als Nächstes geöffnet, wie in diesem Screenshot gezeigt:


Sie haben unterschiedliche Optionen für Ihre Datenquelle. Wenn Ihre Daten bereits in Azure gespeichert sind, wählen Sie „Aus Azure-Speicher“ aus. Um Daten von Ihrem lokalen Laufwerk hochzuladen, wählen Sie „Aus lokalen Dateien“ aus. Wenn Ihre Daten in einem öffentlichen Webspeicherort gespeichert sind, wählen Sie „Aus Webdateien“ aus. Sie können auch eine Datenressource aus einer SQL-Datenbank oder aus Azure Open Datasets erstellen.
Wählen Sie im Dateiauswahlschritt den Speicherort aus, in dem Azure Ihre Daten speichern soll, und wählen Sie die Datendateien aus, die Sie verwenden möchten.
- Aktivieren Sie das Überspringen der Überprüfung, wenn sich Ihre Daten in einem virtuellen Netzwerk befinden. Weitere Informationen finden Sie unter Isolierung virtueller Netzwerke und Datenschutz.
Befolgen Sie die Schritte, um die Datenanalyseeinstellungen und das Schema für Ihre Datenressource festzulegen. Die Einstellungen werden basierend auf dem Dateityp vorausgefüllt, und Sie können Ihre Einstellungen vor der Datenressourcenerstellung weiter konfigurieren.
Wenn Sie den Schritt „Überprüfen“ erreichen, wählen Sie auf der letzten Seite auf „Erstellen“ aus.
Datenvorschau und Profil
Nachdem Sie das Dataset erstellt haben, überprüfen Sie, ob Sie die Vorschau und das Profil in Studio anzeigen können:
- Melden Sie sich bei Azure Machine Learning Studio an.
- Wählen Sie unter Ressourcen im linken Navigationsbereich die Option Daten aus.

- Wählen Sie den Namen des Datasets aus, das Sie anzeigen möchten.
- Wählen Sie die Registerkarte Explore (Untersuchen).
- Wählen Sie die Registerkarte Vorschau aus.

- Wählen Sie die Registerkarte Profil aus.

Sie können die Zusammenfassungsstatistiken zu Ihrem Dataset verwenden, um zu überprüfen, ob Ihr Dataset für ML bereit ist. Bei nicht numerischen Spalten umfassen diese Statistiken nur grundlegende Statistiken, z. B. Min., Max. und Fehleranzahl. Numerische Spalten bieten statistische Momente und geschätzte Quantile.
Das Datenprofil des Azure Machine Learning-Datasets enthält Folgendes:
Hinweis
Leere Einträge werden für Features mit irrelevanten Typen angezeigt.
| Statistik | BESCHREIBUNG |
|---|---|
| Funktion | Den zusammengefassten Spaltenname |
| Profil | Eine Inlinevisualisierung basierend auf dem abgeleiteten Typ. Zeichenfolgen, boolesche Werte und Datumsangaben weisen eine Werteanzahl auf. Dezimalwerte (numerische Werte) haben angenähert Histogramme. Diese Visualisierungen bieten ein schnelles Verständnis der Datenverteilung. |
| Typverteilung | Eine Inlinewertanzahl von Typen in einer Spalte. NULL-Werte sind eigene Typen, sodass diese Visualisierung ungewöhnliche oder fehlende Werte erkennen kann. |
| type | Abgeleiteter Spaltentyp. Mögliche Werte: Zeichenfolgen, boolesche Werte, Datumsangaben und Dezimalwerte |
| Min | Der Mindestwert der Spalte. Leere Einträge werden für Features angezeigt, deren Typ keine inhärente Reihenfolge aufweist (z. B. boolesche Werte). |
| Max | Der Höchstwert der Spalte. |
| Anzahl | Die Gesamtanzahl der fehlenden und nicht fehlenden Einträge in der Spalte |
| Fehlt nicht (Anzahl) | Die Anzahl der nicht fehlenden Einträge in der Spalte. Leere Zeichenfolgen und Fehler werden als Werte behandelt, sodass sie nicht zur „Anzahl nicht fehlender“ beitragen. |
| Quantile | Die geschätzten Werte in jedem Quantil, um einen Eindruck von der Datenverteilung bereitzustellen |
| Mean | Das arithmetische Mittel oder der Mittelwert der Spalte |
| Standardabweichung | Das Maß der Verteilung oder Abweichung der Daten dieser Spalte |
| Abweichung | Das Maß dafür, wie weit sich die Daten dieser Spalte vom Mittelwert verteilen |
| Schiefe | Misst den Unterschied zwischen den Daten dieser Spalte und einer normalen Verteilung |
| Kurtosis | Misst den Grad der „Spitzigkeit“ der Daten dieser Spalte im Vergleich zu einer Normalverteilung. |
Speicherzugriff und Berechtigungen
Um sicherzustellen, dass eine sichere Verbindung mit Ihrem Azure-Speicherdienst hergestellt wird, erfordert Azure Machine Learning, dass Sie über die Berechtigung zum Zugreifen auf den entsprechenden Datenspeicher verfügen. Dieser Zugriff ist von den Anmeldeinformationen für die Authentifizierung abhängig, die zum Registrieren des Datenspeichers verwendet werden.
Virtuelles Netzwerk
Wenn sich Ihr Datenspeicherkonto in einem virtuellen Netzwerk befindet, sind zusätzliche Konfigurationsschritte erforderlich, um sicherzustellen, dass Azure Machine Learning auf Ihre Daten zugreifen kann. Stellen Sie wie unter Verwenden von Azure Machine Learning Studio in einem virtuellen Netzwerk beschrieben sicher, dass die erforderlichen Konfigurationsschritte ausgeführt werden, wenn Sie Ihren Datenspeicher erstellen und registrieren.
Zugriffsüberprüfung
Warnung
Mandantenübergreifender Zugriff auf Speicherkonten wird nicht unterstützt. Wenn Ihr Szenario mandantenübergreifenden Zugriff benötigt, wenden Sie sich an den Alias des Azure Machine Learning-Datensupportteams amldatasupport@microsoft.com, um Unterstützung bei einer benutzerdefinierten Codelösung zu erhalten.
Im Rahmen des ersten Erstellungs- und Registrierungsvorgangs des Datenspeichers überprüft Azure Machine Learning automatisch, ob der zugrunde liegende Speicherdienst vorhanden ist und ob der vom Benutzer bereitgestellte Prinzipal (Benutzername, Dienstprinzipal oder SAS-Token) Zugriff auf den angegebenen Speicher besitzt.
Nach dem Erstellen des Datenspeichers wird diese Überprüfung nur noch für Methoden ausgeführt, die Zugriff auf den zugrunde liegenden Speichercontainer benötigen. Die Überprüfung wird nicht bei jedem Abrufen von Datenspeicherobjekten ausgeführt. Die Überprüfung erfolgt beispielsweise, wenn Sie Dateien aus Ihrem Datenspeicher herunterladen. Wenn Sie den Standarddatenspeicher jedoch ändern möchten, findet die Überprüfung nicht statt.
Um Ihren Zugriff auf den zugrunde liegenden Speicherdienst zu authentifizieren, geben Sie je nach zu erstellendem Datenspeichertyp entweder Ihren Kontoschlüssel, SAS-Token (Shared Access Signatures) oder einen Dienstprinzipal an. In der Speichertypmatrix werden die unterstützten Authentifizierungstypen aufgeführt, die den einzelnen Datenspeichertypen entsprechen.
Informationen zu Kontoschlüssel, SAS-Token und Dienstprinzipal finden Sie im Azure-Portal.
Um einen Kontoschlüssel für die Authentifizierung abzurufen, wählen Sie im linken Bereich Speicherkonten und dann das Speicherkonto aus, das Sie registrieren möchten.
- Die Seite Übersicht enthält Informationen wie den Kontonamen und den Namen des Containers oder der Dateifreigabe.
- Erweitern Sie den Knoten Sicherheit und Netzwerk im linken Navigationsbereich.
- Wählen Sie Zugriffsschlüssel aus.
- Die verfügbaren Schlüsselwerte dienen als Werte für den Kontoschlüssel.
Um ein SAS-Token für die Authentifizierung abzurufen, wählen Sie im linken Bereich Speicherkonten und dann das gewünschte Speicherkonto aus.
- Um einen Wert für Zugriffsschlüssel zu erhalten, erweitern Sie den Knoten Sicherheit und Netzwerk im linken Navigationsbereich.
- Wählen Sie Shared Access Signature aus.
- Schließen Sie den Prozesses ab, um den SAS-Wert zu generieren.
Um einen Dienstprinzipal für die Authentifizierung zu verwenden, navigieren Sie zu Ihren App-Registrierungen, und wählen Sie die gewünschte App aus.
- Auf der entsprechenden Seite Übersicht werden erforderliche Informationen wie Mandanten-ID und Client-ID angezeigt.
Wichtig
- Um Ihre Zugriffsschlüssel für ein Azure Storage-Konto (Kontoschlüssel oder SAS-Token) zu ändern, stellen Sie sicher, dass die neuen Anmeldeinformationen mit Ihrem Arbeitsbereich und den damit verbundenen Datenspeichern synchronisiert werden. Weitere Informationen finden Sie unter Synchronisieren Ihrer aktualisierten Anmeldeinformationen.
- Wenn Sie die Registrierung eines Datenspeichers aufheben und dann einen Datenspeicher mit dem gleichen Namen erneut registrieren und dabei ein Fehler auftritt, ist bei dem Azure Key Vault für Ihren Arbeitsbereich vorläufiges Löschen möglicherweise nicht aktiviert. Standardmäßig ist vorläufiges Löschen für die Key Vault-Instanz aktiviert, die von Ihrem Arbeitsbereich erstellt wurde. Es ist jedoch möglicherweise nicht aktiviert, wenn Sie einen vorhandenen Schlüsseltresor verwendet haben oder einen Arbeitsbereich vor Oktober 2020 erstellt haben. Weitere Informationen zum Aktivieren des vorläufigen Löschens finden Sie unter Aktivieren des vorläufigen Löschens für einen vorhandenen Schlüsseltresor.
Berechtigungen
Stellen Sie für Azure-Blobcontainer und Azure Data Lake Gen2-Speicher sicher, dass Ihre Anmeldeinformationen für die Authentifizierung über den Zugriff Storage-Blobdatenleser verfügen. Erfahren Sie mehr über Storage-Blobdatenleser. Ein Konto-SAS-Token weist standardmäßig keine Berechtigungen auf.
Für den Lesezugriff auf Daten müssen Ihre Anmeldeinformationen für die Authentifizierung mindestens die Berechtigungen zum Auflisten und Lesen für Container und Objekte besitzen.
Für den Schreibzugriff auf Daten sind auch Berechtigungen zum Schreiben und Hinzufügen erforderlich.
Trainieren mit Datasets
Verwenden Sie Ihre Datasets in Ihren Machine Learning-Experimenten zum Trainieren von ML-Modellen. Erfahren Sie mehr über das Trainieren mit Datasets.
Nächste Schritte
Schrittweises Beispiel für das Training mit TabularDatasets und automatisiertem maschinellen Lernen
Weitere Beispiele zum Trainieren von Datasets finden Sie in den Beispielnotebooks.