Datendrift (Vorschau) wird eingestellt und durch Model Monitor ersetzt
Datendrift (Vorschau) wird am 01.09.2025 eingestellt, und Sie können mit der Verwendung von Model Monitor für Ihre Datendriftaufgaben beginnen. Bitte überprüfen Sie den folgenden Inhalt, um die Ersetzung, die Featurelücken und die manuellen Änderungsschritte zu verstehen.
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
Hier erfahren Sie, wie Sie Datendrift überwachen und Warnungen für starke Drift festlegen.
Hinweis
Die Azure Machine Learning-Modellüberwachung (v2) bietet verbesserte Funktionen bei Datendrift sowie zusätzliche Funktionen für die Überwachung von Signalen und Metriken. Weitere Informationen zu den Funktionen der Modellüberwachung in Azure Machine Learning (v2) finden Sie unter Modellüberwachung mit Azure Machine Learning.
Azure Machine Learning-Datasetmonitore (Vorschau) ermöglichen Folgendes:
- Analysieren der Drift in Ihren Daten, um zu verstehen, wie diese sich im Lauf der Zeit ändern.
- Überwachen von Modelldaten auf Änderungen zwischen Trainings- und Nutzungsdatasets. Beginnen Sie mit dem Sammeln von Daten für Modelle in der Produktion.
- Überwachen von neuen Daten auf Änderungen zwischen Baseline- und Zieldatasets.
- Erstellen von Profilen für Features in Daten, um nachzuverfolgen, wie sich statistische Eigenschaften im Lauf der Zeit ändern.
- Einrichten von Warnungen zur Datendrift, um bei potenziellen Problemen frühzeitig eine Benachrichtigung zu erhalten.
- Erstellen einer neuen Datasetversion , wenn eine zu starke Datenabweichung ermittelt wird.
Für die Erstellung des Monitors wird ein Azure Machine Learning-Dataset verwendet. Das Dataset muss eine Zeitstempelspalte enthalten.
Datendriftmetriken können mit dem Python SDK oder in Azure Machine Learning Studio angezeigt werden. Andere Metriken und Erkenntnisse sind über die Ressource Azure Application Insights verfügbar, die mit dem Azure Machine Learning-Arbeitsbereich verknüpft ist.
Wichtig
Die Datendrifterkennung für Datasets befindet sich derzeit in der öffentlichen Vorschauphase. Die Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Voraussetzungen
Um Datasetmonitore zu erstellen und zu nutzen, benötigen Sie Folgendes:
- Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning noch heute aus.
- Ein Azure Machine Learning-Arbeitsbereich.
- Eine Installation des Azure Machine Learning-SDK für Python, in dem das Paket „azureml-datasets“ enthalten ist.
- Strukturierte (tabellarische) Daten mit einem Zeitstempel im Dateipfad, im Dateinamen oder in einer Spalte in den Daten.
Voraussetzungen (Migrieren zu Model Monitor)
Wenn Sie zu Model Monitor migrieren, überprüfen Sie die im Artikel Voraussetzungen für die Überwachung des Azure Machine Learning-Modells erwähnten Voraussetzungen.
Was sind Datenabweichungen?
Die Modellgenauigkeit verringert sich im Laufe der Zeit, was hauptsächlich auf den Datendrift zurückzuführen ist. Für Machine Learning-Modelle ist Datendrift die Veränderung von Modelleingabedaten, die eine Verschlechterung der Modellleistung zur Folge hat. Die Datendriftüberwachung trägt zur Erkennung solcher Modellleistungsprobleme bei.
Folgende Aspekte zählen zu den Gründen für Datendrift:
- Vorgelagerte Prozessänderungen, z. B. durch einen ausgetauschten Sensor, der die Maßeinheiten von Zoll zu Zentimeter ändert.
- Probleme mit der Datenqualität, z. B. durch einen defekten Sensor, der immer den Messwert 0 liefert.
- Natürliche Abweichungen in den Daten, z. B. durch Änderungen der mittleren Temperatur in den Jahreszeiten.
- Änderungen in der Beziehung zwischen Features oder Kovariantenabweichungen.
Azure Machine Learning vereinfacht die Drifterkennung durch die Berechnung einer einzelnen Metrik und die Abstrahierung der Komplexität der verglichenen Datasets. Diese Datasets können hunderte Features und mehrere zehntausend Zeilen umfassen. Wurde eine Drift erkannt, können Sie mittels Drilldown ermitteln, auf welche Features sie zurückzuführen ist. Anschließend können Sie Metriken auf der Featureebene untersuchen, um die Grundursache für die Drift zu debuggen und zu isolieren.
Dieser Top-Down-Ansatz ermöglicht im Gegensatz zu herkömmlichen regelbasierten Techniken eine unkomplizierte Datenüberwachung. Regelbasierte Techniken wie zulässige Datenbereiche oder zulässige eindeutige Werte können zeitaufwändig und fehleranfällig sein.
In Azure Machine Learning werden Datasetmonitore zur Erkennung von Datendrift sowie zur Ausgabe entsprechender Warnungen verwendet.
Datasetmonitore
Ein Datasetmonitor ermöglicht Folgendes:
- Erkennen von Datendrift bei neuen Daten in einem Dataset und Ausgeben entsprechender Warnungen
- Analysieren historischer Daten auf Drift
- Erstellen eines Profils für neue Daten im Zeitverlauf
Der Datendriftalgorithmus misst Änderungen von Daten allgemein und bietet Hinweise darauf, welche Features die Ursache sind, damit diese genauer untersucht werden können. Datasetüberwachungen generieren zahlreiche weitere Metriken, indem Profile für neue Daten im timeseries-Dataset erstellt werden.
Über Azure Application Insights können benutzerdefinierte Warnungen für alle vom Monitor generierten Metriken eingerichtet werden. Datasetmonitore können verwendet werden, um Datenprobleme schnell zu erfassen und den Zeitraum bis zum Beheben des Problems zu verkürzen, indem wahrscheinliche Ursachen ermittelt werden.
Aus konzeptioneller Sicht gibt es drei primäre Szenarien für die Einrichtung von Datasetmonitoren in Azure Machine Learning.
| Szenario | BESCHREIBUNG |
|---|---|
| Überwachen der Nutzungsdaten eines Modells auf Drift gegenüber den Trainingsdaten | Angesichts der Tatsache, dass die Modellgenauigkeit abnimmt, wenn die Nutzungsdaten von den Trainingsdaten abweichen, können die Ergebnisse dieses Szenarios als Überwachung eines Proxys für die Modellgenauigkeit interpretiert werden. |
| Überwachen eines Zeitreihendatasets auf Drift gegenüber einem vorherigen Zeitraum | Dieses Szenario ist allgemeiner und kann zum Überwachen von Datasets verwendet werden, die an Prozessen vor oder nach der Modellerstellung beteiligt sind. Das Zieldataset muss über eine Zeitstempelspalte verfügen. Das Baselinedataset kann ein beliebiges tabellarische Dataset sein, das über gemeinsame Features mit dem Zieldataset verfügt. |
| Analysieren älterer Daten | Dieses Szenario hilft dabei, frühere Daten zu verstehen und fundierte Entscheidungen für die Einstellungen von Datasetmonitoren zu treffen. |
Datasetmonitore sind von folgenden Azure-Diensten abhängig:
| Azure-Dienst | Beschreibung |
|---|---|
| Dataset | Drift verwendet Machine Learning-Datasets, um Trainingsdaten abzurufen und Daten für das Modelltraining zu vergleichen. Die Datenprofilgenerierung wird verwendet, um einige der gemeldeten Metriken (Mindestwerte, Maximalwerte, unterschiedliche Werte, Anzahl unterschiedlicher Werte) zu generieren. |
| Azure Machine Learning-Pipeline und -Compute | Der Driftberechnungsauftrag wird in einer Azure Machine Learning-Pipeline gehostet. Der Auftrag wird bei Bedarf oder zeitplangesteuert ausgelöst und auf einer Computeressource ausgeführt, die bei der Erstellung der Driftüberwachung konfiguriert wurde. |
| Application Insights | Drift gibt Metriken an Application Insights aus, die zum Machine Learning-Arbeitsbereich gehören. |
| Azure Blob Storage | Drift gibt Metriken im JSON-Format an Azure Blob Storage aus. |
Baseline- und Zieldatasets
Sie überwachen Azure Machine Learning-Datasets auf Datendrift. Wenn Sie eine Datasetüberwachung erstellen, verweisen Sie auf Folgendes:
- Baselinedataset – normalerweise das Trainingsdataset für ein Modell
- Zieldataset – in der Regel Modelleingabedaten – wird im Lauf der Zeit mit dem Baselinedataset verglichen Dieser Vergleich bedeutet, dass im Zieldataset eine Zeitstempelspalte angegeben sein muss.
Die Überprüfung vergleicht Baseline- und Zieldatasets.
Migrieren zu Model Monitor
In Model Monitor finden Sie die entsprechenden Konzepte wie folgt. Weitere Details sind im Artikel Einrichten der Modellüberwachung durch Bereitstellen Ihrer Produktionsdaten in Azure Machine Learning enthalten:
- Referenzdatensatz: Ähnlich wie ihr Basisdatensatz für die Datendrifterkennung wird es als das letzte Produktionsrückschluss-Dataset festgelegt.
- Produktionsrückschlussdaten: Ähnlich wie ihr Zieldatenset bei der Datendrifterkennung können die Produktionsrückschlussdaten automatisch aus Modellen gesammelt werden, die in der Produktion bereitgestellt werden. Sie können auch Daten ableiten, die Sie speichern.
Erstellen des Zieldatasets
Für das Zieldataset muss das Merkmal timeseriesfestgelegt sein. Hierzu muss die Zeitstempelspalte angegeben werden – entweder auf der Grundlage einer Spalte in den Daten oder auf der Grundlage einer aus dem Pfadmuster der Dateien abgeleiteten virtuellen Spalte. Erstellen Sie das Dataset mit einem Zeitstempel per Python SDK oder in Azure Machine Learning Studio. Eine Spalte, die einen Zeitstempel darstellt, muss angegeben werden, um dem Dataset das Merkmal timeseries hinzuzufügen. Wenn Ihre Daten in einer Ordnerstruktur mit Zeitinformationen partitioniert sind (beispielsweise {yyyy/MM/dd}), können Sie über die Einstellung für das Pfadmuster eine virtuelle Spalte erstellen und als Partitionszeitstempel festlegen, um die API-Funktion für Zeitreihen zu aktivieren.
GILT FÜR:Python SDK azureml v1
Die Methode with_timestamp_columns() der Klasse Dataset dient zum Definieren der Zeitstempelspalte für das Dataset.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Tipp
Ein vollständiges Beispiel für die Verwendung des timeseries-Merkmals von Datasets finden Sie im Beispiel-Notebook oder in der Dokumentation zum SDK für das Dataset.

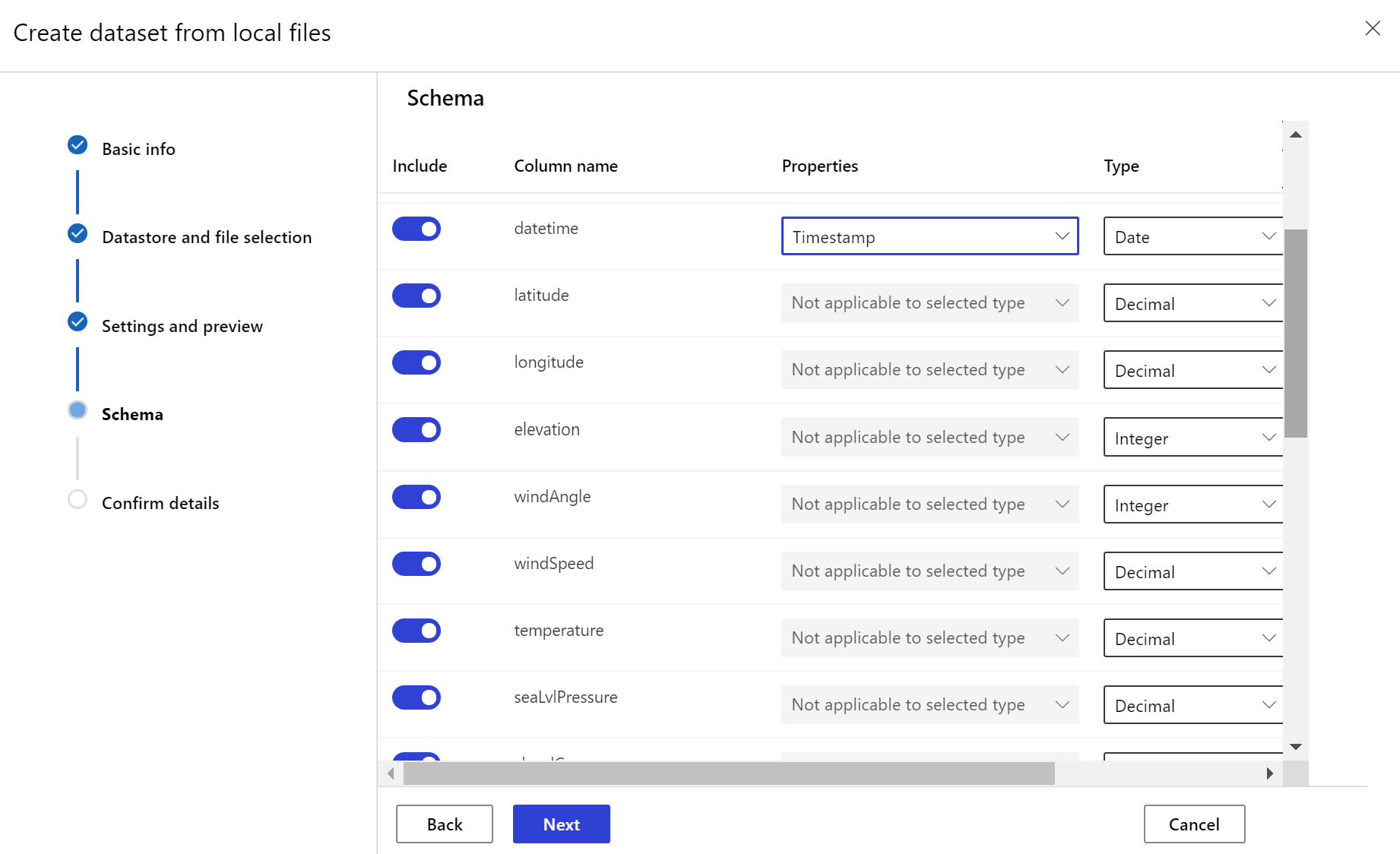
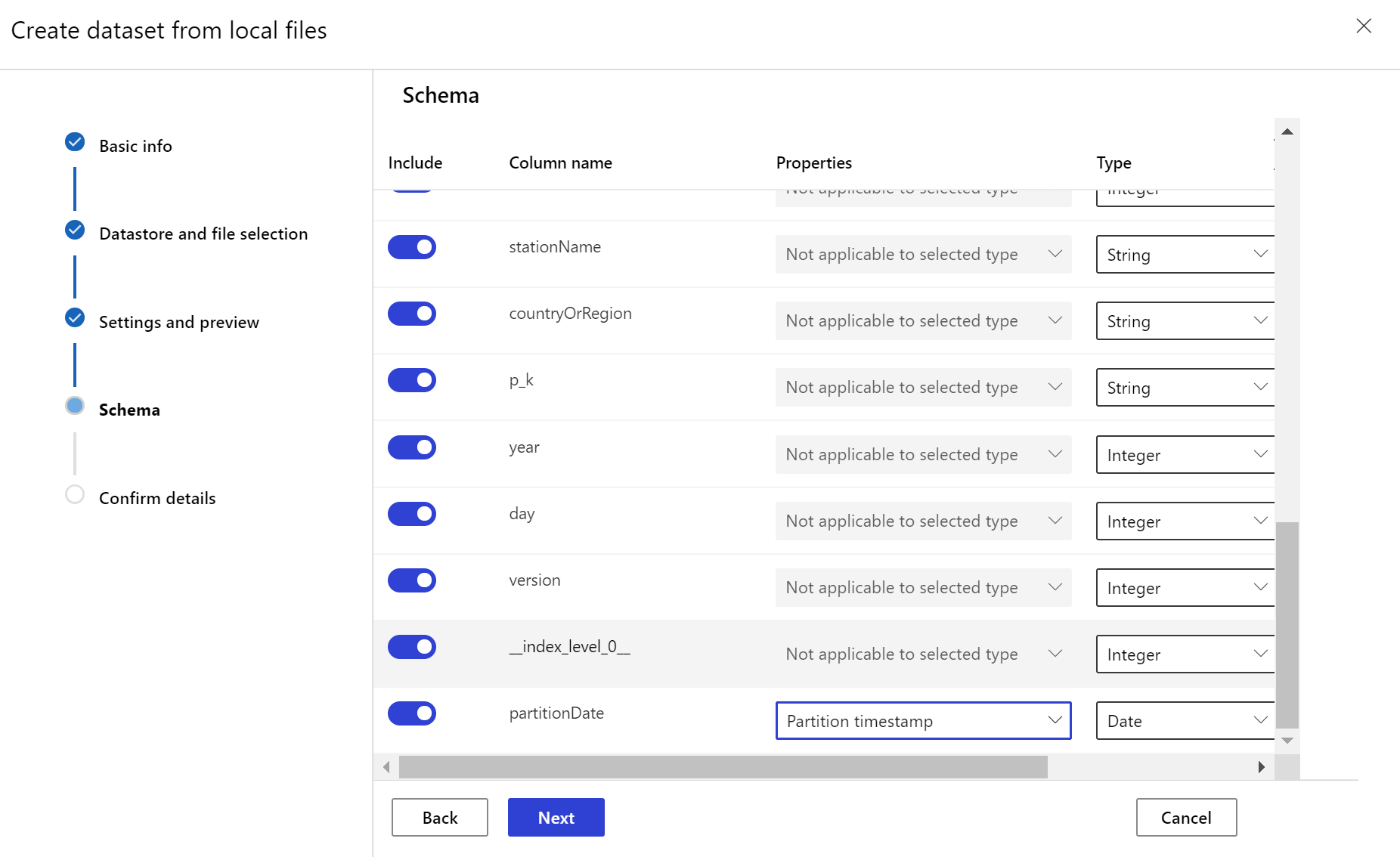
Erstellen eines Datasetmonitors
Erstellen Sie einen Datasetmonitor, um Datendrift bei einem neuen Dataset zu erkennen und eine entsprechende Warnung auszugeben. Verwenden Sie entweder das Python SDK oder Azure Machine Learning Studio.
Wie später beschrieben, werden Datasetüberwachungen in festgelegten Intervallen (täglich, wöchentlich, monatlich) ausgeführt. Die Überwachung analysiert neue Daten, die seit der letzten Ausführung im Zieldataset verfügbar sind. In manchen Fällen reicht eine solche Analyse der neuesten Daten möglicherweise nicht aus:
- Die neuen Daten aus der Upstream-Quelle wurden aufgrund einer fehlerhaften Datenpipeline verzögert, und diese neuen Daten waren nicht verfügbar, als die Datasetüberwachung ausgeführt wurde.
- Ein Zeitreihendataset enthielt nur Verlaufsdaten, und Sie möchten Driftmuster im Dataset im Laufe der Zeit analysieren. Beispiel: Vergleich des Datenverkehrs, der sowohl in der Winter- als auch in der Sommersaison zu einer Website fließt, um saisonale Muster zu identifizieren.
- Sie sind Neuling in der Verwendung von Datasetüberwachungen. Sie möchten bewerten, wie das Feature mit Ihren vorhandenen Daten funktioniert, bevor Sie es für die Überwachung zukünftiger Zeiträume einrichten. In solchen Szenarien können Sie eine bedarfsgesteuerte Ausführung mit einem bestimmten Zieldatensatz und einem bestimmten Datumsbereich durchführen, um ihn mit dem Basisdatensatz zu vergleichen.
Die backfill-Funktion führt einen Nachfüllauftrag für einen angegebenen Start- und Enddatumsbereich aus. Ein Nachfüllauftrag füllt erwartete fehlende Datenpunkte in einem Dataset auf, um die Genauigkeit und Vollständigkeit der Daten zu gewährleisten.
Hinweis
Die Azure Machine Learning-Modellüberwachung unterstützt keine manuelle Backfill-Funktion, wenn Sie den Model Monitor für einen bestimmten Zeitraum wiederholen möchten, können Sie einen anderen Model Monitor für diesen bestimmten Zeitraum erstellen.
GILT FÜR:Python SDK azureml v1
Vollständige Informationen finden Sie in der Python SDK-Referenzdokumentation zur Datendrift.
Im folgenden Beispiel wird gezeigt, wie ein Datasetmonitor mit dem Python SDK erstellt wird:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Tipp
Ein vollständiges Beispiel für die Einrichtung eines timeseries-Datasets und einer Datendrifterkennung finden Sie in unserem Beispiel-Notebook.
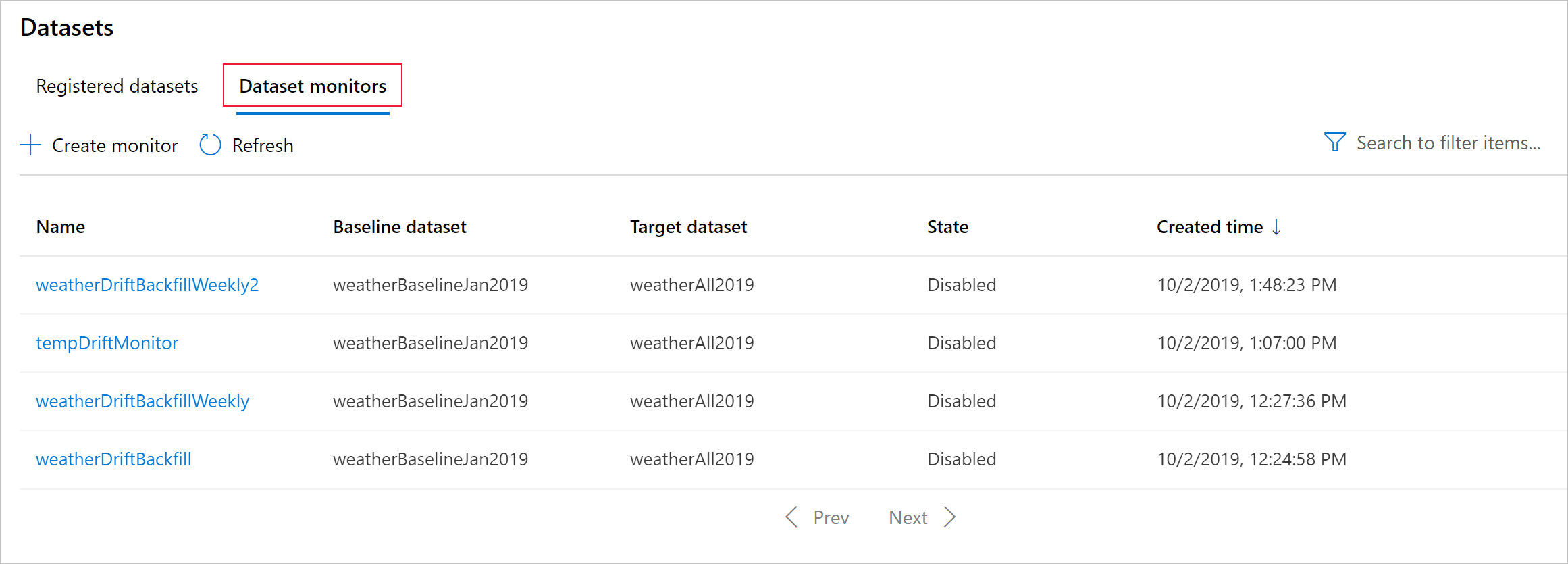

Erstellen von Model Monitor (Migrieren zum Model Monitor)
Wenn Sie zu Model Monitor migrieren, wenn Sie Ihr Modell für die Produktion in einem Azure Machine Learning-Onlineendpunkt bereitgestellt und Datensammlung zur Bereitstellungszeit aktiviert haben, sammelt Azure Machine Learning Produktionsrückschlussdaten und speichert sie automatisch in Microsoft Azure Blob Storage. Anschließend können Sie die Überwachung des Azure Machine Learning-Modells verwenden, um diese Produktionsrückschlussdaten kontinuierlich zu überwachen, und Sie können das Modell direkt auswählen, um Zieldaten zu erstellen (Produktionsrückschlussdaten i Model Monitor).
Wenn Sie zu Model Monitor migrieren, wenn Sie Ihr Modell nicht für die Produktion in einem Azure Machine Learning-Onlineendpunkt bereitgestellt haben oder Datensammlung nicht verwenden möchten, können Sie auch die Modellüberwachung mit benutzerdefinierten Signalen und Metriken einrichten.
Die folgenden Abschnitte enthalten weitere Details zum Migrieren zu Model Monitor.
Erstellen von Model Monitor über automatisch gesammelte Produktionsdaten (Migrieren zu Model Monitor)
Sie haben Ihr Modell für die Produktion in einem Azure Machine Learning-Onlineendpunkt bereitgestellt und die Datensammlung zur Bereitstellungszeit aktiviert.
Sie können den folgenden Code verwenden, um die sofort einsatzbereite Modellüberwachung einzurichten:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Erstellen von Model Monitor über benutzerdefinierte Datenvorverarbeitungskomponente (Migrieren zu Model Monitor)
Wenn Sie zu Model Monitor migrieren, wenn Sie Ihr Modell nicht für die Produktion in einem Azure Machine Learning-Onlineendpunkt bereitgestellt haben oder Datensammlung nicht verwenden möchten, können Sie auch die Modellüberwachung mit benutzerdefinierten Signalen und Metriken einrichten.
Wenn Sie nicht über eine Bereitstellung, aber über Produktionsdaten verfügen, können Sie die Daten verwenden, um eine kontinuierliche Modellüberwachung durchzuführen. Um diese Modelle zu überwachen, müssen Sie folgende Möglichkeiten haben:
- Sammeln Sie Produktionsinferenzdaten aus Modellen, die in der Produktionsumgebung bereitgestellt werden.
- Registrieren Sie die Produktionsinferenzdaten als Azure Machine Learning-Datenressource, und stellen Sie eine kontinuierliche Aktualisierungen der Daten sicher.
- Stellen Sie eine Datenvorverarbeitungskomponente bereit und registrieren Sie sie als Azure Machine Learning-Komponente.
Sie müssen eine benutzerdefinierte Datenvorverarbeitungskomponente bereitstellen, wenn Ihre Daten nicht mit dem Datensammler gesammelt werden. Ohne diese benutzerdefinierte Datenvorverarbeitungskomponente weiß das Azure Machine Learning-Modellüberwachungssystem nicht, wie Sie Ihre Daten in tabellarischem Format verarbeiten, wobei zeitfensterlich unterstützt wird.
Ihre benutzerdefinierte Vorverarbeitungskomponente muss über diese Eingabe- und Ausgabesignaturen verfügen:
| Eingabe/Ausgabe | Signaturname | type | Beschreibung | Beispielswert |
|---|---|---|---|---|
| input | data_window_start |
Literal, Zeichenfolge | Startzeit des Datenfensters im ISO8601-Format. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
Literal, Zeichenfolge | Endzeit des Datenfensters im ISO8601-Format. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Die gesammelten Produktionsinferenzdaten, die als Azure Machine Learning-Datenobjekt registriert werden. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Ein Tabellendataset, das einer Teilmenge des Referenzdatenschemas entspricht. |
Ein Beispiel für eine benutzerdefinierte Datenvorverarbeitungskomponente finden Sie unter custom_preprocessing im GitHub-Repository „azuremml-examples“.
Verstehen der Datendriftergebnisse
In diesem Abschnitt finden Sie die Ergebnisse der Überwachung eines Datasets, die in Azure Studio unter Datasets / Dataset-Monitore bereitgestellt werden. Auf dieser Seite können Sie die Einstellungen aktualisieren und bereits vorhandene Daten für einen bestimmten Zeitraum analysieren.
Beginnen Sie mit den ersten Erkenntnissen hinsichtlich der Größenordnung der Datendrift und einer Übersicht über die wichtigsten Features, die weiter untersucht werden sollten.
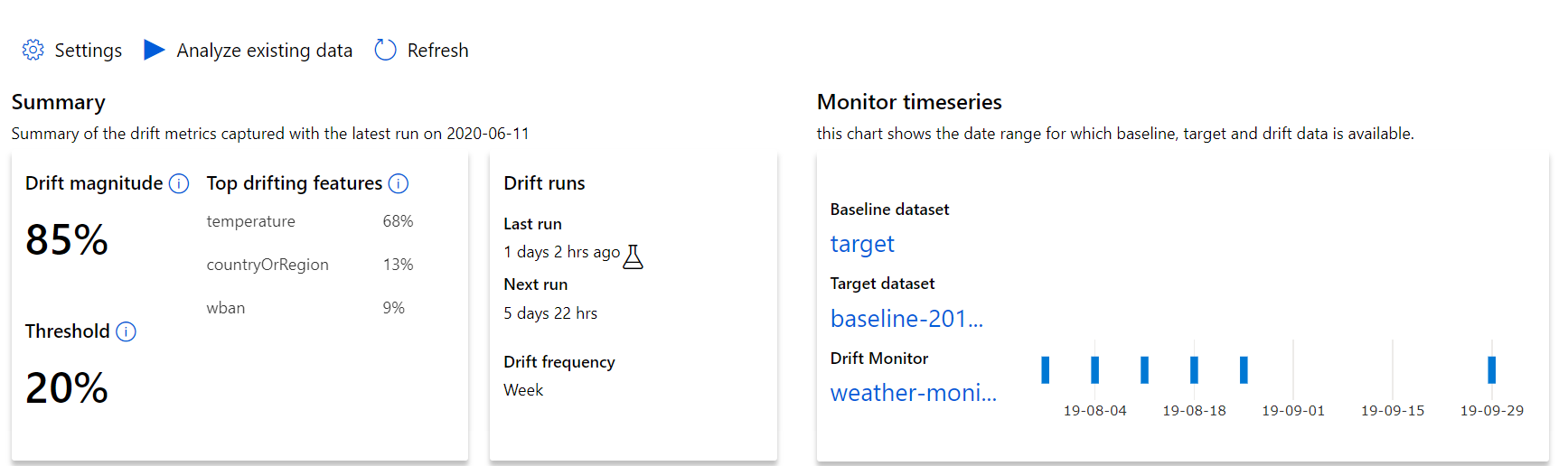
| Metrik | Beschreibung |
|---|---|
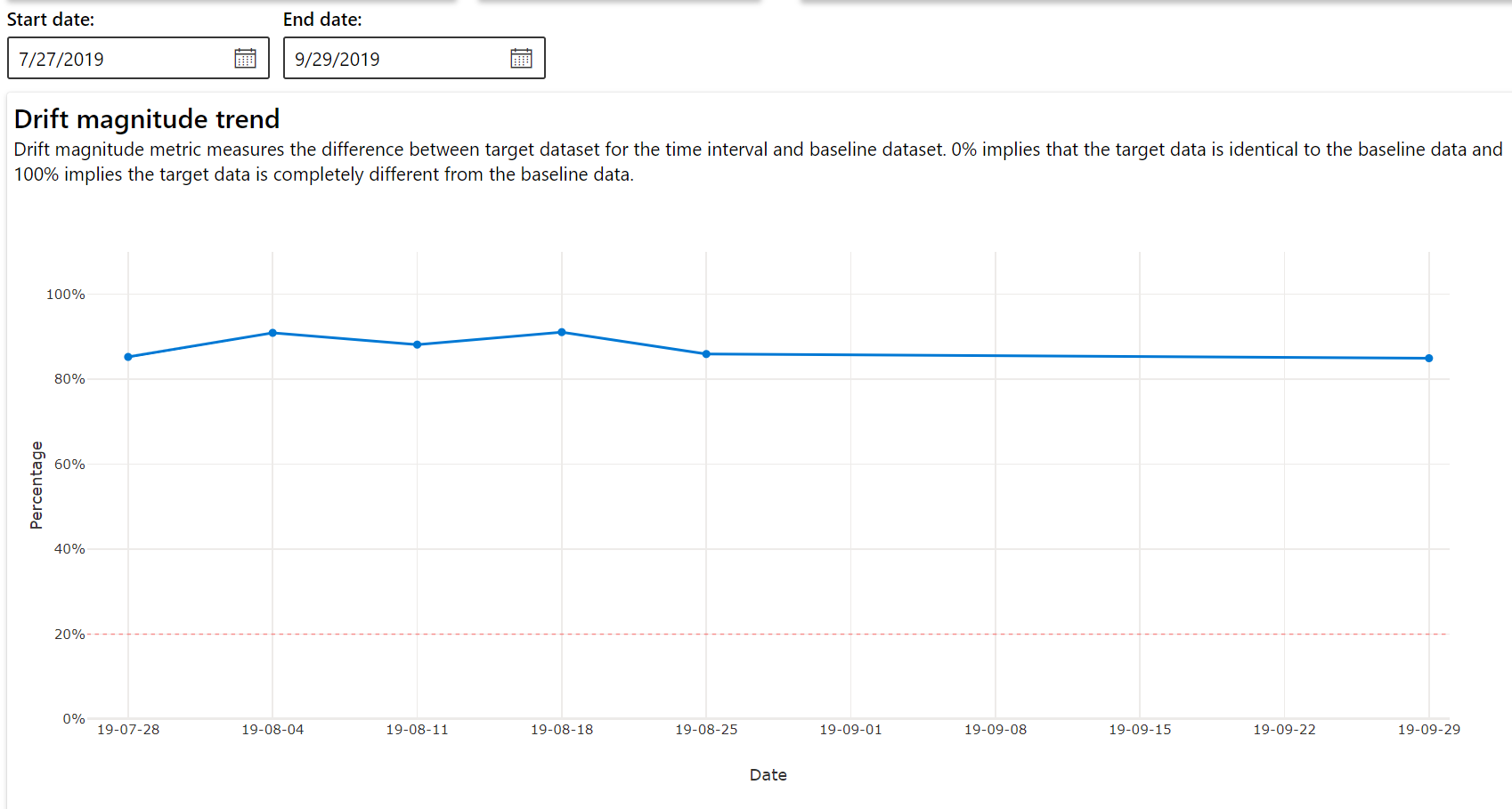
| Größenordnung der Datendrift | Ein Driftprozentsatz zwischen Baseline- und Zieldataset im Zeitverlauf. Dieser Prozentwert liegt zwischen 0 und 100, wobei 0 für identische Datasets steht und 100 bedeutet, dass die beiden Datasets durch das Datendriftmodell von Azure Machine Learning vollständig voneinander unterschieden werden können. Aufgrund der Machine Learning-Techniken, die zum Generieren dieser Größenordnung verwenden werden, ist ein gewisses Maß an Ungenauigkeit beim gemessenen Prozentsatz zu erwarten. |
| Wichtigste Features mit Drift | Zeigt die Features aus dem Dataset an, die den größten Driftumfang aufweisen und daher am meisten zur Driftumfangsmetrik beitragen. Aufgrund von Kovariantenabweichungen muss sich die zugrunde liegende Verteilung eines Features nicht unbedingt ändern, um eine relativ hohe Featurerelevanz aufzuweisen. |
| Schwellenwert | Wenn die Datendriftgröße den festgelegten Schwellenwert übersteigt, werden Warnungen ausgelöst. Konfigurieren Sie den Schwellenwert in den Überwachungseinstellungen. |
Trend des Driftumfangs
Hier sehen Sie, wie sehr sich das Dataset im angegebenen Zeitraum vom Zieldataset unterscheidet. Je näher der Wert bei 100 Prozent liegt, desto stärker unterscheiden sich die beiden Datasets.
Driftausmaß nach Features
Dieser Abschnitt enthält Erkenntnisse auf Featureebene zu Änderungen an der Verteilung des ausgewählten Features und weitere statistische Daten im Zeitverlauf.
Für das Zieldataset wird auch ein Profil im Zeitverlauf erstellt. Der statistische Abstand zwischen der Baselineverteilung der einzelnen Features wird mit dem zeitlichen Verlauf des Zieldatasets verglichen. Dies ähnelt konzeptionell der Datendriftgröße. Der statistische Abstand gilt jedoch für ein einzelnes Feature, nicht für alle Features. Mindest-, Maximal- und Mittelwerte sind ebenfalls verfügbar.
Wählen Sie in Azure Machine Learning Studio einen Balken des Diagramms aus, um die Details auf der Funktions-Ebene für das entsprechende Datum anzuzeigen. Standardmäßig werden die Verteilung des Baselinedatasets und die Verteilung des letzten Auftrags für dieses Feature angezeigt.
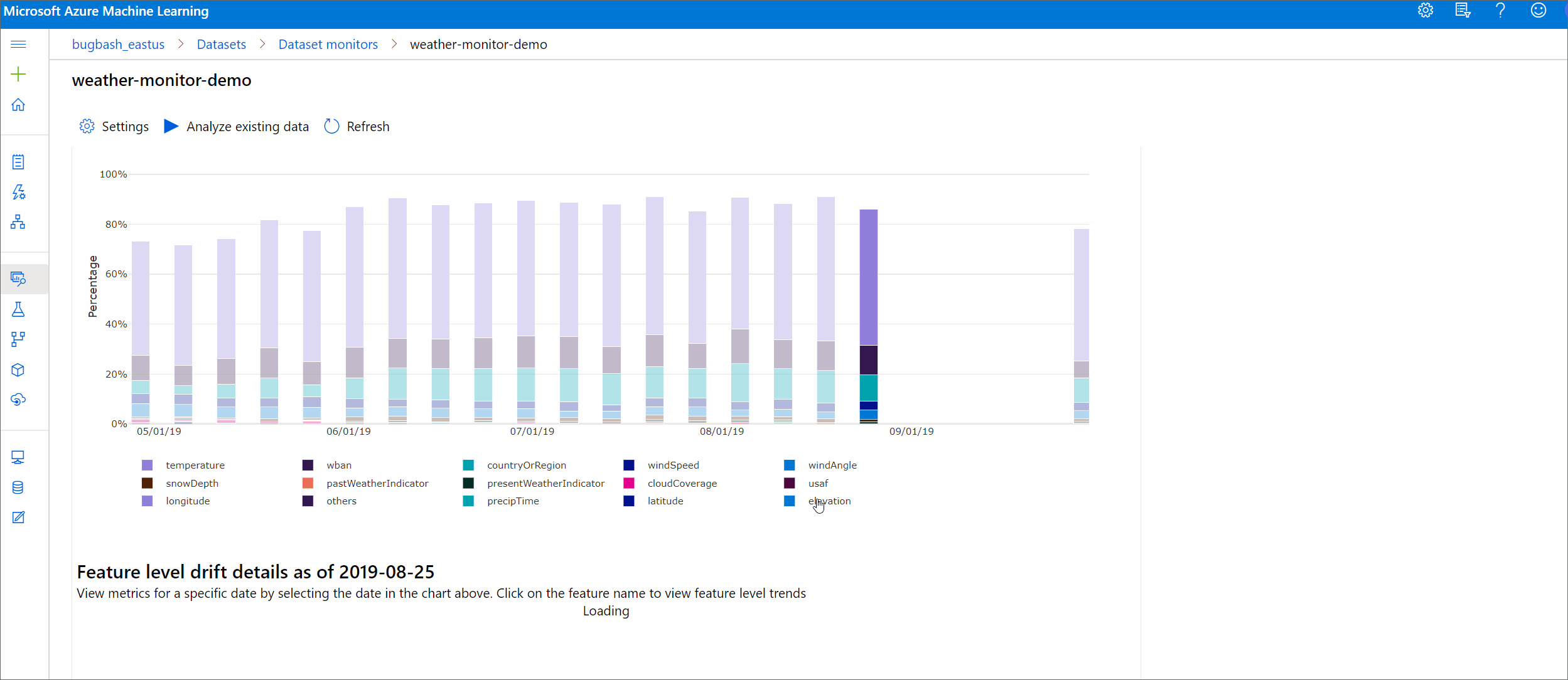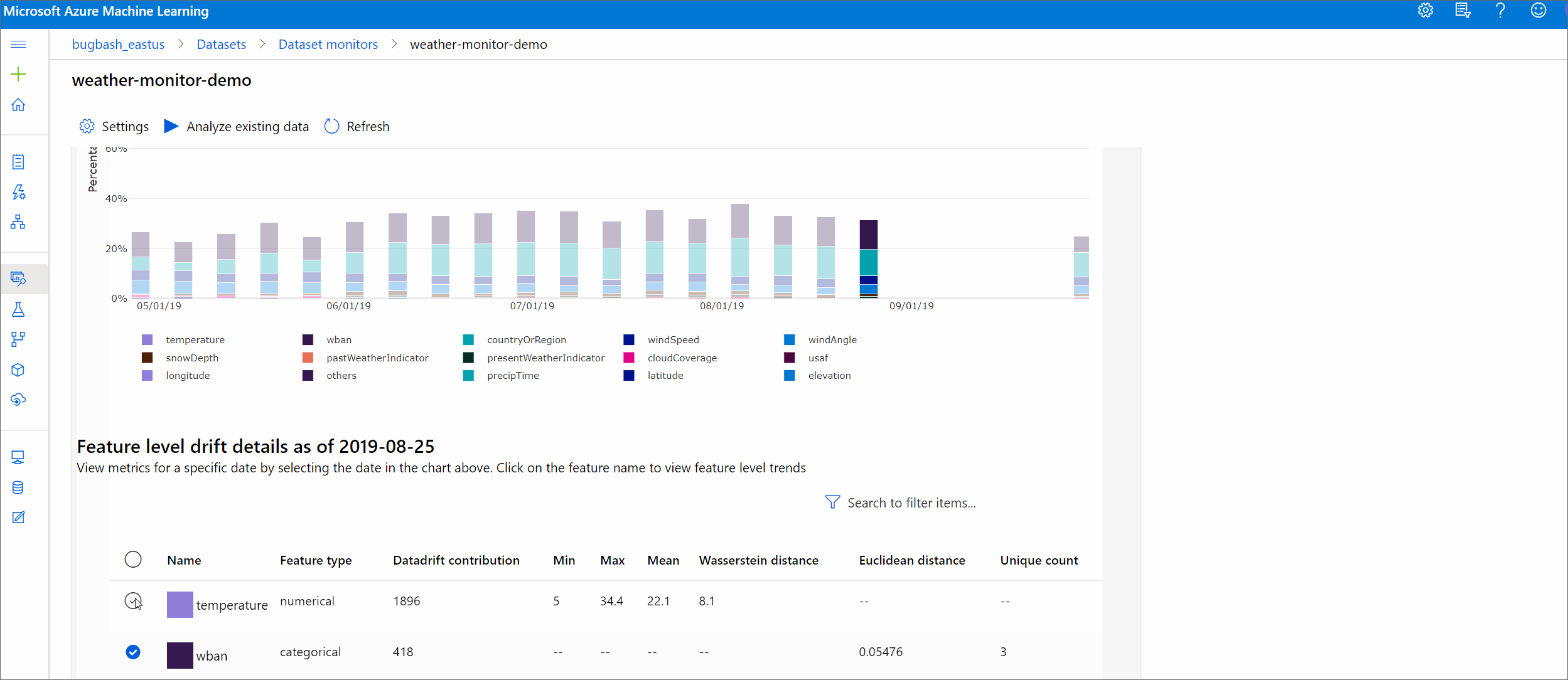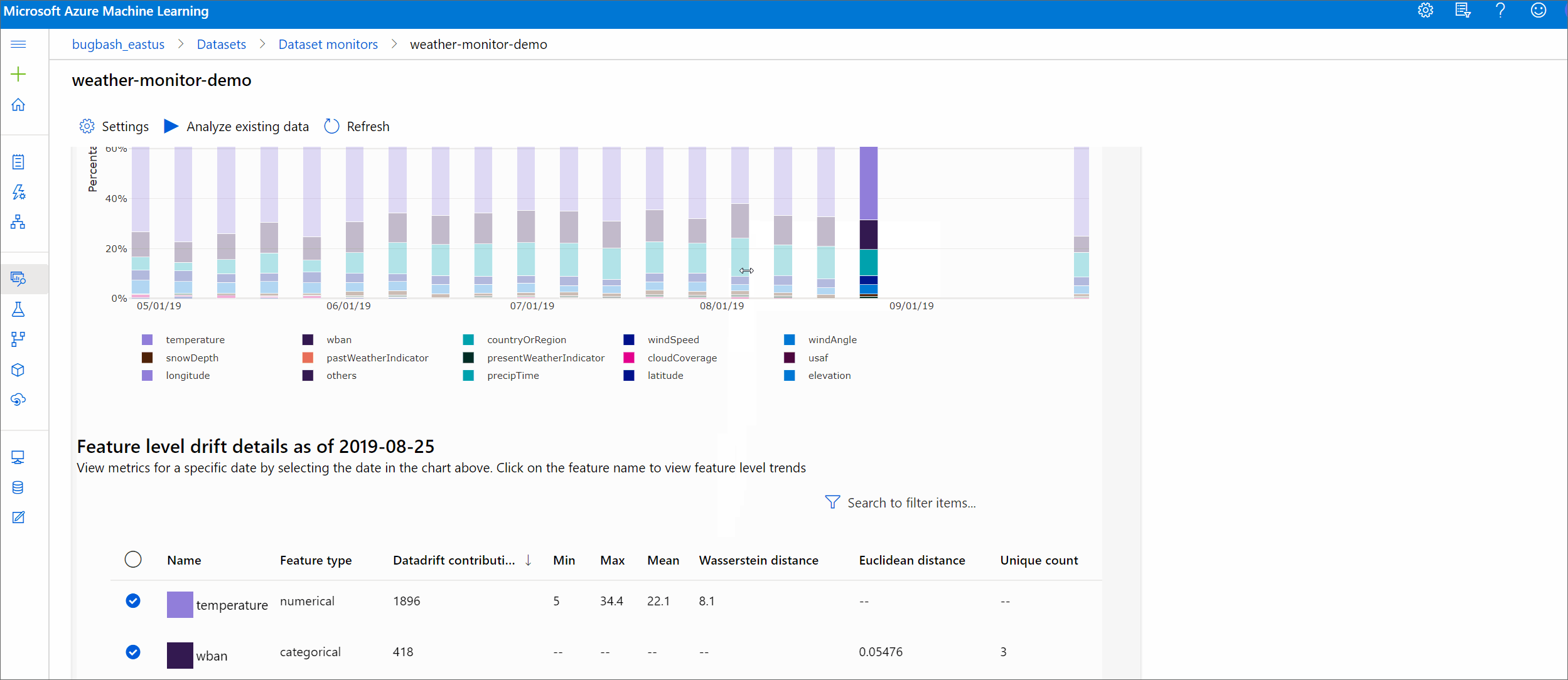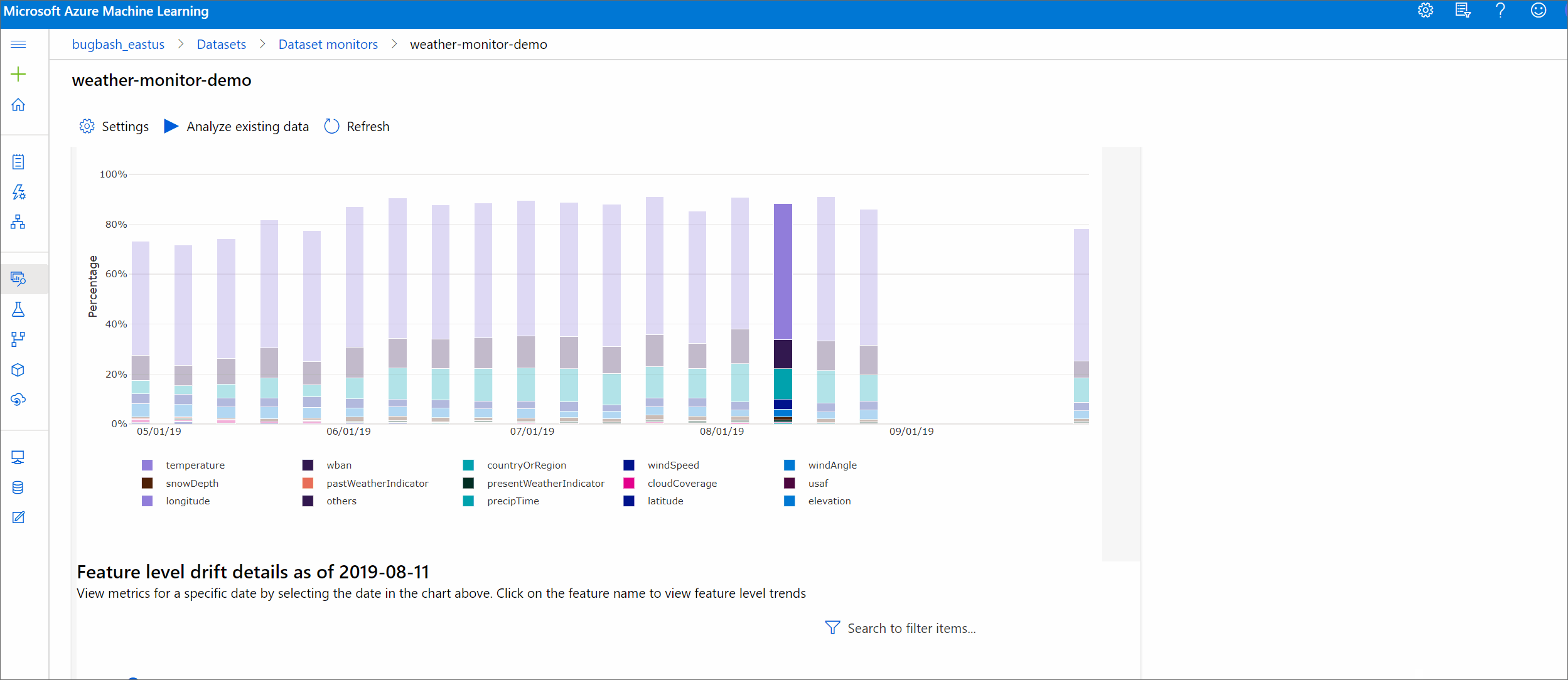
Diese Metriken können auch im Python SDK mithilfe der get_metrics()-Methode in einem DataDriftDetector-Objekt abgerufen werden.
Featuredetails
Scrollen Sie abschließend nach unten, um Details zu den einzelnen Features anzuzeigen. Verwenden Sie die Dropdownlisten über dem Diagramm, um das Feature auszuwählen, und wählen Sie außerdem die Metrik aus, die Sie anzeigen möchten.
Die Metriken im Diagramm hängen von der Art des Features ab.
Numerische Features
Metrik BESCHREIBUNG Wasserstein-Distanz Der Mindestarbeitsaufwand, der für die Transformation der Baselineverteilung in die Zielverteilung erforderlich ist. Mittelwert Durchschnittlicher Wert des Features. Mindestwert Minimaler Wert des Features. Maximalwert Maximaler Wert des Features. Kategorische Features
Metrik BESCHREIBUNG Euklidischer Abstand Berechnet für Kategoriespalten. Der euklidische Abstand wird für zwei Vektoren berechnet, die auf der Grundlage der empirischen Verteilung der gleichen Kategoriespalte aus zwei Datasets generiert wurden. „0“ gibt an, dass sich die empirischen Verteilungen nicht unterscheiden. Je weiter der Wert von „0“ entfernt ist, desto stärker ist der Drift der Spalte. Trends können anhand eines Zeitreihendiagramm dieser Metrik ermittelt werden und bei der Identifizierung eines Features mit Drift hilfreich sein. Eindeutige Werte Anzahl eindeutiger Werte (Kardinalität) des Features.
Wählen Sie in diesem Diagramm ein einzelnes Datum aus, um die Featureverteilung zwischen dem Ziel und diesem Datum für das angezeigte Feature zu vergleichen. Für numerische Features werden zwei Wahrscheinlichkeitsverteilungen angezeigt. Ist das Feature numerisch, wird ein Balkendiagramm angezeigt.

Metriken, Warnungen und Ereignisse
Metriken können in der Azure Application Insights-Ressource abgefragt werden, die Ihrem Machine Learning-Arbeitsbereich zugeordnet ist. Sie haben Zugriff auf alle Features von Application Insights, z. B. auch zur Einrichtung von benutzerdefinierten Warnungsregeln und Aktionsgruppen zum Auslösen einer Aktion wie E-Mail/SMS/Pushübertragung/Sprachnachricht oder einer Azure-Funktion. Ausführlichere Informationen hierzu finden Sie in der vollständigen Application Insights-Dokumentation.
Navigieren Sie zunächst zum Azure-Portal, und wählen Sie die Seite Übersicht Ihres Arbeitsbereichs aus. Die zugeordnete Application Insights-Ressource befindet sich ganz rechts:

Wählen Sie im linken Bereich unter „Überwachung“ die Option „Protokolle (Analytics)“ aus:

Die Metriken der Datasetüberwachung werden als customMetrics gespeichert. Sie können eine Abfrage schreiben und ausführen, nachdem Sie eine Überwachung per Datasetmonitor eingerichtet haben, um die Metriken anzuzeigen:

Erstellen Sie eine neue Warnungsregel, nachdem Sie die Metriken für die Einrichtung von Warnungsregeln identifiziert haben:
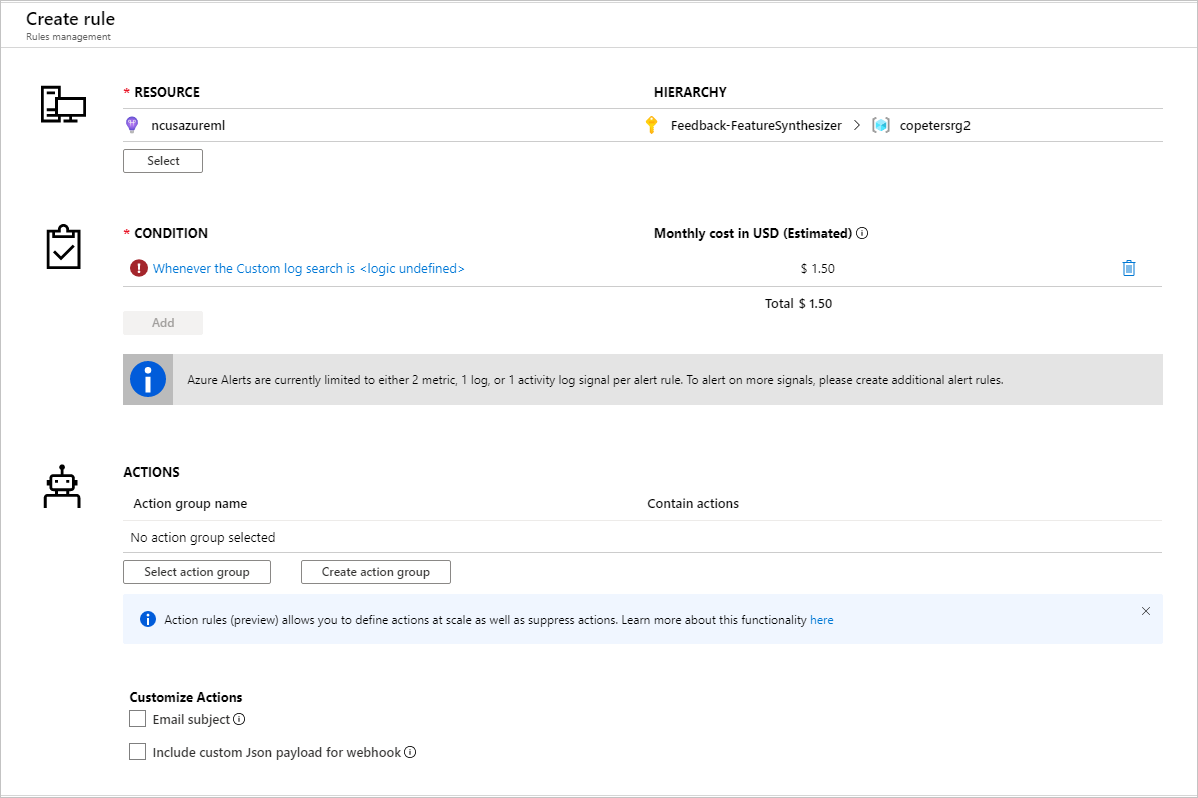
Sie können eine vorhandene oder eine neue Aktionsgruppe verwenden, um die Aktion zu definieren, die durchgeführt werden soll, wenn die festgelegten Bedingungen erfüllt sind:
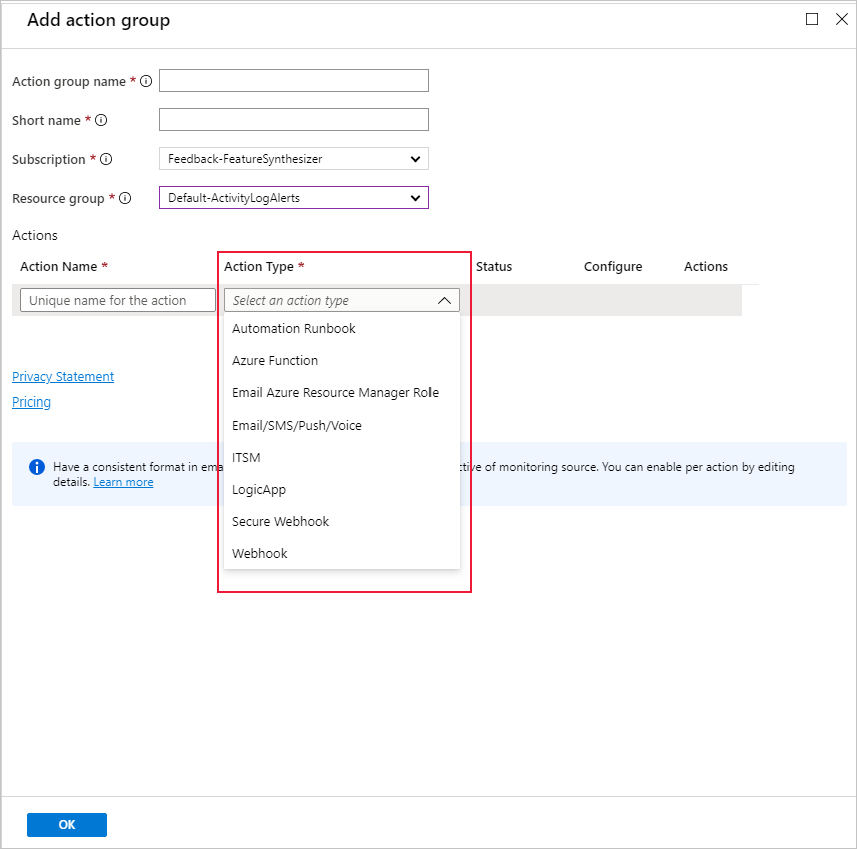
Problembehandlung
Einschränkungen und bekannte Probleme bei Datendriftüberwachungen:
Der Zeitbereich für die Analyse von Verlaufsdaten ist auf 31 Intervalle der Häufigkeitseinstellung für die Überwachung beschränkt.
Es besteht eine Beschränkung auf 200 Features, es sei denn, es wurde keine Featureliste angegeben (alle Features werden verwendet).
Die Computegröße muss ausreichend sein, um die Daten zu verarbeiten.
Stellen Sie sicher, dass Ihr Dataset über Daten innerhalb des Zeitraums verfügt, der durch das Start- und Enddatum für den jeweiligen Auftrag der Überwachung festgelegt ist.
Datasetüberwachungen funktionieren nur mit Datensätzen, die mindestens 50 Zeilen enthalten.
Spalten bzw. Features im Dataset werden basierend auf den Bedingungen in der unten angegebenen Tabelle als kategorisch oder numerisch klassifiziert. Wenn ein Feature diese Bedingungen nicht erfüllt, beispielsweise bei einer Spalte vom Typ „string“ mit mehr >100 eindeutigen Werten, wird es aus dem Datendriftalgorithmus entfernt. In die Profilerstellung wird es aber einbezogen.
Featuretyp Datentyp Bedingung Einschränkungen Kategorisch Zeichenfolge Die Anzahl von eindeutigen Werten im Feature ist kleiner als 100 und geringer als 5 % der Anzahl von Zeilen. NULL wird als eigene Kategorie behandelt. Numerisch int, float Die Werte im Feature weisen einen numerischen Datentyp auf und erfüllen nicht die Bedingung für ein kategorisches Feature. Das Feature wird entfernt, wenn >15 % der Werte NULL sind. Wenn Sie eine Datendriftüberwachung erstellt haben, aber die Daten auf der Seite Datasetüberwachungen in Azure Machine Learning Studio nicht angezeigt werden, versuchen Sie Folgendes.
- Überprüfen Sie, ob Sie oben auf der Seite den richtigen Datumsbereich ausgewählt haben.
- Wählen Sie auf der Registerkarte Datasetüberwachungen den Experimentlink aus, um den Auftragsstatus zu prüfen. Dieser Link befindet sich ganz rechts in der Tabelle.
- Wenn der Auftrag erfolgreich abgeschlossen wurde, überprüfen Sie in den Treiberprotokollen, wie viele Metriken generiert wurden oder ob Warnmeldungen vorhanden sind. Die Treiberprotokolle finden Sie nach der Auswahl eines Experiments auf der Registerkarte Ausgabe + Protokolle.
Wenn die SDK-Funktion
backfill()nicht die erwartete Ausgabe generiert, ist dies möglicherweise auf ein Authentifizierungsproblem zurückzuführen. Sie dürfen beim Erstellen der Computeressource, die an diese Funktion übergeben wird, nichtRun.get_context().experiment.workspace.compute_targetsverwenden. Verwenden Sie stattdessen ServicePrincipalAuthentication, wie hier zu sehen, um das Computeziel zu erstellen, das Sie an die Funktionbackfill()übergeben:
Hinweis
Programmieren Sie das Dienstprinzipalkennwort nicht fest in Ihren Code ein. Rufen Sie es stattdessen aus der Python-Umgebung, dem Schlüsselspeicher oder mit einer anderen sicheren Zugriffsmethode auf Geheimnisse ab.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Es kann bis zu 10 Minuten dauern, bis Daten aus dem Modelldatensammler in Ihrem Blobspeicherkonto eintreffen. Es dauert jedoch in der Regel nicht so lange. Warten Sie bei einem Skript oder Notebook 10 Minuten, damit die folgenden Zellen ausgeführt werden können.
import time time.sleep(600)
Nächste Schritte
- Fahren Sie mit dem Azure Machine Learning-Studio oder dem Python-Notebook fort, um einen Datasetmonitor zu erstellen.
- Informieren Sie sich, wie Sie die Datendrift für in Azure Kubernetes Service bereitgestellte Modelle einrichten.
- Richten Sie Dataset-Drift-Monitore mit Azure Event Grid ein.