Interaktive R-Entwicklung
GILT FÜR: Azure CLI-ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie, wie Sie R in Azure Machine Learning Studio auf einer Compute-Instanz verwenden, die einen R-Kernel in einem Jupyter-Notebook ausführt.
Die beliebte RStudio-IDE funktioniert ebenfalls. Sie können RStudio oder Posit Workbench in einem benutzerdefinierten Container in einer Compute-Instanz installieren. Es gibt jedoch Einschränkungen hinsichtlich Lese- und Schreibvorgängen in Ihrem Azure Machine Learning-Arbeitsbereich.
Wichtig
Der in diesem Artikel gezeigte Code kann in einer Azure Machine Learning-Compute-Instanz verwendet werden. Die Compute-Instanz verfügt über eine Umgebung und über eine Konfigurationsdatei, die erforderlich sind, um den Code erfolgreich ausführen zu können.
Voraussetzungen
- Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning noch heute aus.
- Ein Azure Machine Learning-Arbeitsbereich und eine Compute-Instanz
- Grundkenntnisse im Zusammenhang mit der Verwendung von Jupyter Notebook-Instanzen im Azure Machine Learning Studio. Weitere Informationen finden Sie in der Ressource Modellentwicklung auf einer Cloudarbeitsstation.
Ausführen von R in einem Notebook im Studio
Sie verwenden ein Notebook in Ihrem Azure Machine Learning-Arbeitsbereich in einer Computeinstanz.
Melden Sie sich bei Azure Machine Learning Studio an.
Öffnen Sie Ihren Arbeitsbereich, sofern er noch nicht geöffnet ist.
Wählen Sie im Navigationsbereich auf der linken Seite die Option Notebooks aus.
Erstellen Sie ein neues Notebook mit dem Namen RunR.ipynb.
Tipp
Wenn Sie nicht sicher sind, wie Sie Notebooks im Studio erstellen und verwenden, helfen Ihnen die Informationen unter Ausführen von Jupyter Notebook-Instanzen auf Ihrer Arbeitsstation weiter.
Wählen Sie das Notebook aus.
Vergewissern Sie sich auf der Symbolleiste des Notebooks, dass Ihre Compute-Instanz ausgeführt wird. Falls nicht, starten Sie sie jetzt.
Legen Sie auf der Symbolleiste des Notebooks den Kernel auf R fest.
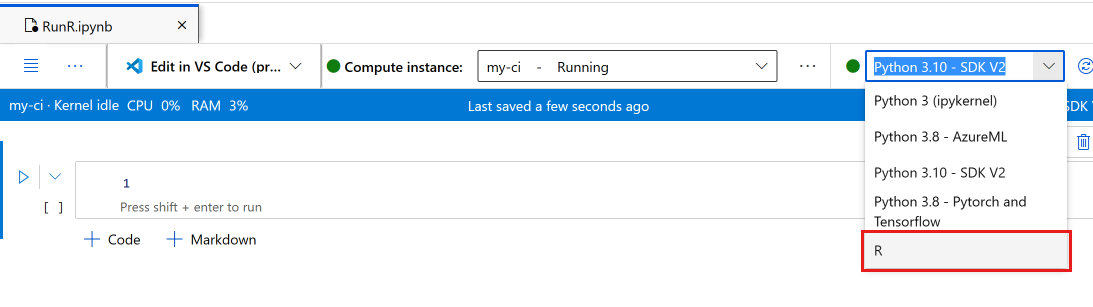

Ihr Notebook ist jetzt für die Ausführung von R-Befehlen bereit.
Zugreifen auf Daten
Sie können Dateien in Ihre Dateispeicherressource Ihres Arbeitsbereichs hochladen und in R auf diese Dateien zugreifen. Doch für gespeicherte Dateien in Azure-Datenressourcen oder Daten aus Datenspeichern müssen zunächst einige Pakete installiert werden.
In diesem Abschnitt wird beschrieben, wie Sie Python und das Paket reticulate verwenden, um Ihre Datenressourcen und Datenspeicher aus einer interaktiven Sitzung in R zu laden. Tabellendaten werden mithilfe des Python-Pakets azureml-fsspec und des R-Pakets reticulate als Pandas-Datenrahmen (DataFrames) gelesen. Dieser Abschnitt enthält auch ein Beispiel für das Lesen von Datenressourcen und Datenspeichern in einen R data.frame.
Installieren Sie diese Pakete wie folgt:
Erstellen Sie in der Compute-Instanz eine neue Datei namens setup.sh.
Kopieren Sie diesen Code in die Datei:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFWählen Sie Skript speichern und im Terminal ausführen aus, um das Skript auszuführen.
Das Installationsskript führt die folgenden Schritte aus:
pipinstalliertazureml-fsspecin der Conda-Standardumgebung für die Compute-Instanz.- Bei Bedarf wird mindestens die Version 1.26 des R-Pakets
reticulateinstalliert.
Lesen von Tabellendaten aus registrierten Datenressourcen oder Datenspeichern
Für Daten, die in einer in Azure Machine Learning erstellten Datenressource gespeichert werden, verwenden Sie die folgenden Schritte, um die tabellarische Datei in einen Pandas DataFrame oder einen R-data.frame zu lesen:
Hinweis
Das Lesen einer Datei mit reticulate funktioniert nur mit Tabellendaten.
Vergewissern Sie sich, dass Sie die korrekte Version von
reticulateverwenden. Ist die Version niedriger als 1.26, verwenden Sie nach Möglichkeit eine neuere Compute-Instanz.packageVersion("reticulate")Laden Sie
reticulate, und legen Sie die Conda-Umgebung fest, in derazureml-fsspecinstalliert wurde.library(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Ermitteln Sie den URI-Pfad zur Datendatei.
Rufen Sie als Erstes ein Handle für Ihren Arbeitsbereich ab.
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Verwenden Sie den folgenden Code, um die Ressource abzurufen. Ersetzen Sie
<MY_NAME>und<MY_VERSION>durch den Namen und die Nummer Ihrer Datenressource.Tipp
Wählen Sie im Studio im linken Navigationsbereich die Option Daten aus, um den Namen und die Versionsnummer Ihrer Datenressource zu ermitteln.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"Führen Sie den Code aus, um den URI abzurufen.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Verwenden Sie Pandas-Lesefunktionen, um die Datei(en) in die R-Umgebung einzulesen.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
Sie können auch einen Datenspeicher-URI verwenden, um auf verschiedene Dateien in einem registrierten Datenspeicher zuzugreifen und diese Ressourcen in einen R-data.frame zu lesen.
Erstellen Sie in diesem Format einen Datenspeicher-URI mit Ihren eigenen Werten:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Tipp
Anstatt sich das Format des Datenspeicher-URI zu merken, können Sie den Datenspeicher-URI von der Studio-Benutzeroberfläche kopieren und einfügen, wenn Sie den Datenspeicher kennen, in dem sich Ihre Datei befindet:
- Navigieren Sie zu der Datei/dem Ordner, die/den Sie in R einlesen möchten
- Wählen Sie die Auslassungspunkte (...) daneben aus.
- Wählen Sie im Menü URI kopieren eine Option aus.
- Wählen Sie den Datenspeicher-URI aus, der in Ihr Notebook/Skript kopiert werden soll.
Beachten Sie, dass Sie eine Variable für
<path>im Code erstellen müssen.
Erstellen Sie ein Dateispeicherobjekt mithilfe des oben genannten URI:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- In einen R-
data.framelesen:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
Installieren von R-Paketen
Eine Compute-Instanz verfügt über viele vorinstallierte R-Pakete.
Um weitere Pakete zu installieren, müssen Sie den Speicherort und die Abhängigkeiten explizit angeben.
Tipp
Wenn Sie eine andere Compute-Instanz erstellen oder verwenden, müssen Sie alle von Ihnen installierten Pakete erneut installieren.
Gehen Sie beispielsweise wie folgt vor, um das Paket tsibble zu installieren:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Hinweis
Wenn Sie Pakete innerhalb einer R-Sitzung installieren, die in einer Jupyter Notebook-Instanz ausgeführt wird, ist dependencies = TRUE erforderlich. Andernfalls werden abhängige Pakete nicht automatisch installiert. Der Speicherort „lib“ ist ebenfalls erforderlich, damit die Installation am richtigen Speicherort der Compute-Instanz durchgeführt wird.
Laden von R-Bibliotheken
Fügen Sie dem R-Bibliothekspfad /home/azureuser hinzu.
.libPaths("/home/azureuser")
Tipp
Sie müssen .libPaths in jedem interaktiven R-Skript aktualisieren, um auf von Benutzern installierte Bibliotheken zuzugreifen. Fügen Sie diesen Code am Anfang jedes interaktiven R-Skripts oder Notebooks hinzu.
Nach dem Aktualisieren von „libPath“ können Bibliotheken wie gewohnt geladen werden.
library('tsibble')
Verwenden von R im Notebook
Abgesehen von den oben beschriebenen Problemen können Sie R wie in jeder anderen Umgebung verwenden, einschließlich Ihres lokalen Arbeitsplatzes. In Ihrem Notebook oder Skript können Sie Lese- und Schreibvorgänge für den Pfad ausführen, an dem das Notebook bzw. Skript gespeichert ist.
Hinweis
- Im Rahmen einer interaktiven R-Sitzung können nur Daten in das Dateisystem des Arbeitsbereichs geschrieben werden.
- In einer interaktiven R-Sitzung können Sie nicht mit MLflow interagieren, um beispielsweise ein Modell zu protokollieren oder die Registrierung abzufragen.