Einrichten von MLOps mit Azure DevOps
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure Machine Learning ermöglicht Ihnen die Integration in die Azure DevOps-Pipeline, um den Machine Learning-Lebenszyklus zu automatisieren. Einige der Vorgänge, die Sie automatisieren können, sind:
- Bereitstellung einer Azure Machine Learning-Infrastruktur
- Datenvorbereitung (Extrahieren, Transformieren, Ladenvorgänge)
- Training von ML-Modellen mit bedarfsgerechter horizontaler und vertikaler Skalierung
- Bereitstellung von Machine Learning-Modellen als öffentliche oder private Webdienste
- Überwachen bereitgestellter ML-Modelle (z. B. für die Leistungsanalyse)
In diesem Artikel erfahren Sie mehr über die Einrichtung einer End-to-End-MLOps-Pipeline mit Azure Machine Learning, wobei die Pipeline eine lineare Regression ausführt, um Taxitarife in NYC vorherzusagen. Sie besteht aus Komponenten, die jeweils verschiedenen Funktionen dienen. Diese können mit dem Arbeitsbereich registriert, versioniert und mit verschiedenen Eingaben und Ausgaben wiederverwendet werden. Sie verwenden die empfohlene Azure-Architektur für MLOps und den Solution Accelerator für Azure MLOps (v2), um schnell ein MLOps-Projekt in Azure Machine Learning einzurichten.
Tipp
Es wird empfohlen, sich mit einigen der empfohlenen Azure-Architekturen für MLOps vertraut zu machen, bevor Sie eine Lösung implementieren. Sie müssen die beste Architektur für Ihr vorliegendes Machine Learning-Projekt auswählen.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
- Ein Azure Machine Learning-Arbeitsbereich.
- Git wird auf Ihrem lokalen Computer ausgeführt.
- Eine Organisation in Azure DevOps
- Azure DevOps-Projekt, das die Quellrepositorys und Pipelines hostet
- Die Terraform-Erweiterung für Azure DevOps, wenn Sie Azure DevOps + Terraform zum Einrichten der Infrastruktur verwenden
Hinweis
Es wird mindestens die Git-Version 2.27 benötigt. Weitere Informationen zum Installieren des Git-Befehls finden Sie unter https://git-scm.com/downloads. Wählen Sie hier Ihr Betriebssystem aus.
Wichtig
Die CLI-Befehle in diesem Artikel wurden mithilfe von Bash getestet. Wenn Sie eine andere Shell verwenden, können Fehler auftreten.
Einrichten der Authentifizierung mit Azure und DevOps
Bevor Sie ein MLOps-Projekt mit Azure Machine Learning einrichten können, müssen Sie die Authentifizierung für Azure DevOps einrichten.
Erstellen eines Dienstprinzipals
Für die Verwendung der Demo müssen ein oder zwei Dienstprinzipale erstellt werden, je nachdem, an wie vielen Umgebungen Sie arbeiten möchten (Entwicklungsumgebung, Produktionsumgebung oder beide). Diese Prinzipale können mit einer der folgenden Methoden erstellt werden:
Starten Sie Azure Cloud Shell.
Tipp
Wenn Sie die Cloud Shell zum ersten Mal gestartet haben, werden Sie aufgefordert, ein Speicherkonto für die Cloud Shell zu erstellen.
Wenn Sie dazu aufgefordert werden, wählen Sie Bash als Umgebung aus, die in der Cloud Shell verwendet wird. Sie können die Umgebungen auch in der Dropdownliste auf der oberen Navigationsleiste ändern.

Kopieren Sie die folgenden Bash-Befehle auf Ihren Computer, und aktualisieren Sie die Variablen projectName, subscriptionId und environment mit den Werten für Ihr Projekt. Wenn Sie sowohl eine Entwicklungs- als auch eine Produktionsumgebung erstellen, müssen Sie dieses Skript einmal für jede Umgebung ausführen und für jede Umgebung einen Dienstprinzipal erstellen. Mit diesem Befehl wird dem Dienstprinzipal im bereitgestellten Abonnement auch die Rolle Mitwirkender zugewiesen. Dies ist erforderlich, damit Azure DevOps Ressourcen in diesem Abonnement ordnungsgemäß verwenden kann.
projectName="<your project name>" roleName="Contributor" subscriptionId="<subscription Id>" environment="<Dev|Prod>" #First letter should be capitalized servicePrincipalName="Azure-ARM-${environment}-${projectName}" # Verify the ID of the active subscription echo "Using subscription ID $subscriptionID" echo "Creating SP for RBAC with name $servicePrincipalName, with role $roleName and in scopes /subscriptions/$subscriptionId" az ad sp create-for-rbac --name $servicePrincipalName --role $roleName --scopes /subscriptions/$subscriptionId echo "Please ensure that the information created here is properly save for future use."Kopieren Sie die bearbeiteten Befehle in die Azure Shell, und führen Sie sie aus (STRG + UMSCHALT + v).
Nachdem Sie diese Befehle ausgeführt haben, werden Informationen zum Dienstprinzipal angezeigt. Speichern Sie diese Informationen an einem sicheren Speicherort. Sie werden später in der Demo zum Konfigurieren von Azure DevOps verwendet.
{ "appId": "<application id>", "displayName": "Azure-ARM-dev-Sample_Project_Name", "password": "<password>", "tenant": "<tenant id>" }Wiederholen Sie Schritt 3, wenn Sie Dienstprinzipale für Entwicklungs- und Produktionsumgebungen erstellen. Für diese Demo werden wir nur eine Umgebung erstellen, nämlich die Produktionsumgebung.
Schließen Sie die Cloud Shell, nachdem die Dienstprinzipale erstellt wurden.



Einrichten von Azure DevOps
Navigieren Sie zu Azure DevOps.
Wählen Sie Neues Projekt erstellen aus (geben Sie dem Projekt für dieses Tutorial den Namen
mlopsv2).
Wählen Sie im Projekt unter Projekteinstellungen (unten links auf der Projektseite) die Option Dienstverbindungen aus.
Wählen Sie Dienstverbindung erstellen aus.

Wählen Sie Azure Resource Manager, Weiter, Dienstprinzipal (manuell) und Weiter, und anschließend das Abonnement auf Bereichsebene aus.
- Abonnementname : Verwenden Sie den Namen des Abonnements, in dem Ihr Dienstprinzipal gespeichert ist.
- Abonnement-ID: Verwenden Sie die
subscriptionId, die Sie bei der Eingabe in Schritt 1 verwendet haben, als Abonnement-ID. - Dienstprinzipal-ID: Verwenden Sie die
appIdaus der Ausgabe von Schritt 1 als Dienstprinzipal-ID. - Dienstprinzipalschlüssel: Verwenden Sie das
passwordaus der Ausgabe von Schritt 1 als Dienstprinzipalschlüssel. - Mandanten-ID: Verwenden Sie den
tenantaus der Ausgabe von Schritt 1 als Mandanten-ID.
Nennen Sie die Dienstverbindung Azure-ARM-Prod.
Wählen Sie Allen Pipelines die Zugriffsberechtigung gewähren und dann Überprüfen und speichern aus.
Die Einrichtung von Azure DevOps wurde erfolgreich abgeschlossen.
Einrichten des Quellrepositorys mit Azure DevOps
Öffnen Sie das Projekt, das Sie in Azure DevOps erstellt haben.
Öffnen Sie den Abschnitt „Repositorys“, und wählen Sie Repository importieren aus.

Geben Sie https://github.com/Azure/mlops-v2-ado-demo in das Feld „URL klonen“ ein. Wählen Sie unten auf der Seite die Option „Importieren“ aus.

Öffnen Sie die Projekteinstellungen unten im linken Navigationsbereich.
Wählen Sie im Abschnitt „Repositorys“ die Option Repositorys aus. Wählen Sie das Repository aus, das Sie das im vorherigen Schritt erstellt haben. Wählen Sie die Registerkarte Sicherheit aus.
Wählen Sie im Abschnitt „Benutzerberechtigungen“ den Benutzer mlopsv2 Build Service aus. Ändern Sie die Berechtigung Mitwirken in Zulassen und die Berechtigung Branch erstellen in Zulassen.

Öffnen Sie den Abschnitt Pipelines im linken Navigationsbereich, und wählen Sie die drei vertikalen Punkte neben der Schaltfläche Pipelines erstellen aus. Wählen Sie Sicherheit verwalten aus.

Wählen Sie im Abschnitt „Benutzer“ das Konto mlopsv2 Build Service für Ihr Projekt aus. Ändern Sie die Berechtigung Buildpipeline bearbeiten in Zulassen.

Hinweis
Dadurch wird der Abschnitt „Voraussetzung“ abgeschlossen, und die Bereitstellung des Solution Accelerator kann entsprechend erfolgen.
Bereitstellen der Infrastruktur über Azure DevOps
In diesem Schritt wird die Trainingspipeline in dem Azure Machine Learning-Arbeitsbereich bereitgestellt, der in den vorherigen Schritten erstellt wurde.
Tipp
Stellen Sie sicher, dass Sie die Architekturmuster des Solution Accelerator kennen, bevor Sie das MLOps v2-Repository auschecken und die Infrastruktur bereitstellen. In den Beispielen verwenden Sie den klassischen ML-Projekttyp.
Ausführen der Azure-Infrastrukturpipeline
Wechseln Sie zu Ihrem Repository,
mlops-v2-ado-demo, und wählen Sie die Datei config-infra-prod.yml aus.Wichtig
Stellen Sie sicher, dass Sie den Mainbranch des Repositorys ausgewählt haben.

Diese Konfigurationsdatei verwendet die Namespace- und Postfixwerte sowie die Namen der Artefakte, um die Eindeutigkeit sicherzustellen. Aktualisieren Sie den folgenden Abschnitt in der Konfiguration nach Ihren Wünschen.
namespace: [5 max random new letters] postfix: [4 max random new digits] location: eastusHinweis
Wenn Sie einen Deep Learning-Workload wie CV oder NLP ausführen, müssen Sie sicherstellen, dass Ihre GPU-Computeressource in Ihrer Bereitstellungszone verfügbar ist.
Wählen Sie „Commit and push code“ (Code committen und pushen) aus, um diese Werte in die Pipeline einzufügen.
Wechseln Sie zum Abschnitt „Pipelines“.

Wählen Sie Pipeline erstellen aus.
Wählen sie Azure Repos Git aus.

Wählen Sie das Repository aus, das Sie im vorherigen Abschnitt geklont haben.
mlops-v2-ado-demoWählen Sie die Option Vorhandene Azure Pipelines-YAML-Datei aus.
Wählen Sie den
main-Branch, dannmlops/devops-pipelines/cli-ado-deploy-infra.ymlund anschließend Weiter aus.Führen Sie die Pipeline aus. Es dauert einige Minuten, bis der Vorgang abgeschlossen ist. Die Pipeline sollte die folgenden Artefakte erstellen:
- Ressourcengruppe für Ihren Arbeitsbereich, darunter Speicherkonto, Container Registry, Application Insights, Keyvault und der Azure Machine Learning-Arbeitsbereich selbst.
- Im Arbeitsbereich wird auch ein Computecluster erstellt.
Nun ist die Infrastruktur für Ihr MLOps-Projekt bereitgestellt.

Hinweis
Warnungen mit dem Inhalt Unable move and reuse existing repository to required location (Vorhandenes Repository kann nicht an den gewünschten Ort verschoben und wiederverwendet werden) können ignoriert werden.
Beispielszenario für Training und Bereitstellung
Der Solution Accelerator enthält Code und Daten für eine umfassende Machine Learning-Beispielpipeline, die eine lineare Regression ausführt, um Taxitarife in NYC vorherzusagen. Sie besteht aus Komponenten, die jeweils verschiedenen Funktionen dienen. Diese können mit dem Arbeitsbereich registriert, versioniert und mit verschiedenen Eingaben und Ausgaben wiederverwendet werden. Beispielpipelines und Workflows für maschinelles Sehen und NLP umfassen unterschiedliche (Bereitstellungs-)Schritte.
Diese Trainingspipeline umfasst folgende Schritte:
Daten vorbereiten
- Diese Komponente verwendet mehrere Taxidatasets (gelb und grün), führt die Daten zusammen und filtert sie. Anschließend werden die Trainings-/Validierungs- und Auswertungsdatasets vorbereitet.
- Eingabe: Lokale Daten unter ./data/ (mehrere CSV-Dateien)
- Ausgabe: Einzelnes vorbereitetes Dataset (.csv) und Trainings-/Validierungs-/Testdatasets.
Train Model (Modell trainieren)
- Diese Komponente trainiert einen linearen Regressor mit dem Trainingssatz.
- Eingabe: Trainingsdataset
- Ausgabe: Trainiertes Modell (Pickle-Format)
Auswertungsmodell
- Diese Komponente verwendet das trainierte Modell, um Taxitarife für den Testsatz vorherzusagen.
- Eingabe: ML-Modell und Testdataset
- Ausgabe: Leistung des Modells und ein Bereitstellungsflag, das angibt, ob bereitgestellt werden soll oder nicht.
- Diese Komponente vergleicht die Leistung des Modells mit allen vorherigen bereitgestellten Modellen im neuen Testdataset und entscheidet, ob das Modell in die Produktion heraufgestuft werden soll oder nicht. Zum Höherstufen des Modells in die Produktion wird das Modell im AML-Arbeitsbereich registriert.
Modell registrieren
- Diese Komponente bewertet das Modell basierend darauf, wie genau die Vorhersagen im Testsatz sind.
- Eingabe: Trainiertes Modell und das Bereitstellungsflag.
- Ausgabe: Registriertes Modell in Azure Machine Learning.
Bereitstellen einer Modelltrainingspipeline
Wechseln Sie zu „Pipelines“ in ADO.
Wählen Sie Neue Pipeline aus.

Wählen sie Azure Repos Git aus.
Wählen Sie das Repository aus, das Sie im vorherigen Abschnitt geklont haben.
mlopsv2Wählen Sie die Option Vorhandene Azure Pipelines-YAML-Datei aus.
Wählen Sie
mainals Branch aus, und wählen Sie/mlops/devops-pipelines/deploy-model-training-pipeline.ymlund anschließend Weiter aus.Speichern Sie die Pipeline, und führen Sie sie aus.
Hinweis
An diesem Punkt wird die Infrastruktur konfiguriert, und die Prototypenschleife der MLOps-Architektur wird bereitgestellt. Sie sind bereit, zu unserem trainierten Modell in die Produktion zu wechseln.
Bereitstellen des trainierten Modells
Dieses Szenario umfasst vordefinierte Workflows für zwei Ansätze zur Bereitstellung eines trainierten Modells: Batchbewertung oder Bereitstellung eines Modells auf einem Endpunkt für Echtzeitbewertungen. Sie können einen dieser Workflows oder auch beide ausführen, um die Leistung des Modells in Ihrem Azure Machine Learning-Arbeitsbereich zu testen. In diesem Beispiel wird die Echtzeitbewertung verwendet.
Bereitstellen des ML-Modellendpunkts
Wechseln Sie zu „Pipelines“ in ADO.
Wählen Sie Neue Pipeline aus.
Wählen sie Azure Repos Git aus.
Wählen Sie das Repository aus, das Sie im vorherigen Abschnitt geklont haben.
mlopsv2Wählen Sie die Option Vorhandene Azure Pipelines-YAML-Datei aus.
Wählen Sie
mainals Branch, dann „Verwalteter Onlineendpunkt“/mlops/devops-pipelines/deploy-online-endpoint-pipeline.ymlund anschließend Weiter aus.Namen von Onlineendpunkten müssen eindeutig sein. Ändern Sie
taxi-online-$(namespace)$(postfix)$(environment)daher in einen anderen eindeutigen Namen, und wählen Sie dann Ausführen aus. Es ist nicht erforderlich, den Standardwert zu ändern, wenn kein Fehler auftritt.
Wichtig
Wenn die Ausführung aufgrund eines bereits vorhandenen Namens für den Onlineendpunkt fehlschlägt, müssen Sie die Pipeline wie zuvor beschrieben neu erstellen und [Ihren Endpunktnamen] in [Ihren Endpunktnamen (Zufallszahl)] ändern.
Wenn die Ausführung abgeschlossen ist, wird eine Ausgabe ähnlich der folgenden Abbildung angezeigt:
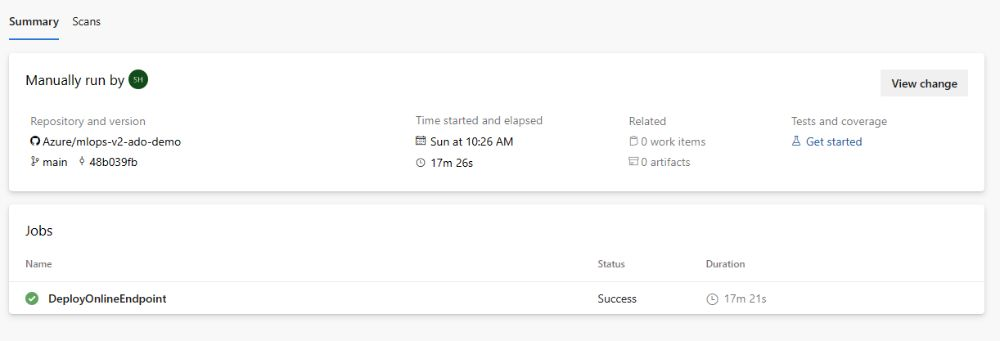
Navigieren Sie zum Testen dieser Bereitstellung in Ihrem Azure Machine Learning-Arbeitsbereich zur Registerkarte Endpunkte, wählen Sie den Endpunkt aus, und klicken Sie auf die Registerkarte Testen. Sie können die Beispieleingabedaten im geklonten Repository unter
/data/taxi-request.jsonverwenden, um den Endpunkt zu testen.
Bereinigen von Ressourcen
- Wenn Sie Ihre Pipeline nicht weiterhin verwenden möchten, löschen Sie Ihr Azure DevOps-Projekt.
- Löschen Sie im Azure-Portal Ihre Ressourcengruppe und Azure Machine Learning-Instanz.
Nächste Schritte
- Installieren und Einrichten des Python SDK v2
- Installieren und Einrichten der Python-CLI v2
- Azure MLOps (v2) Solution Accelerator auf GitHub
- Trainingskurs zu MLOps mit Machine Learning
- Weitere Informationen zu Azure Pipelines mit Azure Machine Learning
- Weitere Informationen zu GitHub Actions mit Azure Machine Learning
- Bereitstellen von MLOps in Azure in weniger als einer Stunde – Video zur MLOps V2 Accelerator-Community