Nachverfolgen von Azure Synapse Analytics-ML-Experimenten mit MLflow und Azure Machine Learning
In diesem Artikel erfahren Sie, wie Sie MLflow aktivieren, um eine Verbindung mit Azure Machine Learning herzustellen, während Sie in einem Azure Synapse Analytics-Arbeitsbereich arbeiten. Sie können diese Konfiguration für die Nachverfolgung, Modellverwaltung und Modellimplementierung nutzen.
MLflow ist eine Open-Source-Bibliothek zum Verwalten des Lebenszyklus Ihrer Machine Learning-Experimente. MLflow Tracking ist eine Komponente von MLflow, die Metriken zu Trainingsausführungen und Modellartefakte protokolliert und nachverfolgt. Weitere Informationen zu MLflow.
Informationen zum Trainieren eines MLflow-Projekts mit Azure Machine Learning finden Sie unter Trainieren von ML-Modellen mit MLflow-Projekten und Azure Machine Learning (Vorschau).
Voraussetzungen
Installieren von Bibliotheken
So installieren Sie Bibliotheken auf Ihrem dedizierten Cluster in Azure Synapse Analytics:
Erstellen Sie eine
requirements.txt-Datei mit den Paketen, die Ihre Experimente benötigen, stellen Sie jedoch sicher, dass sie auch die folgenden Pakete enthält:requirements.txt
mlflow azureml-mlflow azure-ai-mlNavigieren Sie zum Azure Analytics-Arbeitsbereichsportal.
Navigieren Sie zur Registerkarte Verwalten, und wählen Sie Apache Spark-Pools aus.
Klicken Sie auf die drei Punkte neben dem Clusternamen, und wählen Sie Pakete aus.

Klicken Sie im Abschnitt Anforderungsdateien auf Hochladen.
Laden Sie die
requirements.txt-Datei hoch.Warten Sie, bis Ihr Cluster neu gestartet wird.
Nachverfolgen von Experimenten mit MLflow
Azure Synapse Analytics kann so konfiguriert werden, dass Experimente mithilfe von MLflow im Azure Machine Learning-Arbeitsbereich nachverfolgt werden. Azure Machine Learning bietet ein zentrales Repository zum Verwalten des gesamten Lebenszyklus von Experimenten, Modellen und Bereitstellungen. Es hat auch den Vorteil, dass es einen einfacheren Weg zur Bereitstellung mithilfe der Azure Machine Learning-Bereitstellungsoptionen ermöglicht.
Konfigurieren Ihrer Notebooks für die Verwendung von mit Azure Machine Learning verbundenem MLflow
Um Azure Machine Learning als zentrales Repository für Experimente zu verwenden, können Sie MLflow nutzen. In jedem Notebook, an dem Sie arbeiten, müssen Sie den Nachverfolgungs-URI so konfigurieren, dass er auf den Arbeitsbereich verweist, den Sie verwenden. Im folgenden Beispiel wird gezeigt, wie dies ablaufen kann:
Konfigurieren des Nachverfolgungs-URI
Rufen Sie den Nachverfolgungs-URI für Ihren Arbeitsbereich ab:
GILT FÜR
 Azure CLI-ML-Erweiterung v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)Anmelden und Konfigurieren des Arbeitsbereichs:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Sie können den Nachverfolgungs-URI mithilfe des Befehls
az ml workspaceabrufen:az ml workspace show --query mlflow_tracking_uri
Konfigurieren des Nachverfolgungs-URI:
Anschließend verweist die Methode
set_tracking_uri()den MLflow-Nachverfolgungs-URI auf diesen URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Tipp
Beim Arbeiten in gemeinsam genutzten Umgebungen, wie z. B. einem Azure Databricks-Cluster, Azure Synapse Analytics-Cluster o. ä., ist es sinnvoll, die Umgebungsvariable
MLFLOW_TRACKING_URIauf Clusterebene so festzulegen, dass der Nachverfolgungs-URI von MLflow automatisch so konfiguriert wird, dass er für alle im Cluster ausgeführten Sitzungen auf Azure Machine Learning verweist, anstatt dies auf sitzungsbezogen zu tun.
Konfigurieren der Authentifizierung
Sobald die Nachverfolgung konfiguriert ist, müssen Sie auch konfigurieren, wie die Authentifizierung für den zugeordneten Arbeitsbereich erfolgen soll. Standardmäßig führt das Azure Machine Learning-Plug-In für MLflow eine interaktive Authentifizierung durch, indem es den Standardbrowser öffnet und Anmeldeinformationen anfordert. Weitere Informationen zu zusätzlichen Möglichkeiten zum Konfigurieren der Authentifizierung für MLflow in Azure Machine Learning-Arbeitsbereichen finden Sie unter Konfigurieren von MLflow für Azure Machine Learning: Konfigurieren der Authentifizierung.
Bei interaktiven Aufträgen, bei denen ein Benutzer mit der Sitzung verbunden ist, können Sie sich auf die interaktive Authentifizierung verlassen, sodass keine weiteren Maßnahmen erforderlich sind.
Warnung
Die interaktive Browserauthentifizierung blockiert die Codeausführung, wenn zur Eingabe von Anmeldeinformationen aufgefordert wird. Dieser Ansatz eignet sich nicht für die Authentifizierung in unbeaufsichtigten Umgebungen wie Trainingsaufträgen. Es wird empfohlen, einen anderen Authentifizierungsmodus zu konfigurieren.
In Szenarien, in denen eine unbeaufsichtigte Ausführung erforderlich ist, müssen Sie einen Dienstprinzipal für die Kommunikation mit Azure Machine Learning konfigurieren.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Tipp
Für die Arbeit in gemeinsam genutzten Umgebungen wird empfohlen, diese Umgebungsvariablen auf Computeebene zu konfigurieren. Als bewährte Methode empfiehlt es sich, diese als Geheimnisse in einer Azure Key Vault-Instanz zu verwalten.
In Azure Databricks können Sie beispielsweise Geheimnisse in Umgebungsvariablen wie folgt in der Clusterkonfiguration verwenden: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Weitere Informationen zum Implementieren dieses Ansatzes in Azure Databricks finden Sie unter Verweisen auf ein Geheimnis in einer Umgebungsvariablen oder in der Dokumentation für Ihre Plattform.
Namen des Experiments in Azure Machine Learning
Standardmäßig verfolgt Azure Machine Learning Ausführungen in einem Standardexperiment namens Default nach. Normalerweise sollten Sie das Experiment festlegen, an dem Sie arbeiten werden. Legen Sie mit folgender Syntax den Namen des Experiments fest:
mlflow.set_experiment(experiment_name="experiment-name")
Nachverfolgen von Parametern, Metriken und Artefakten
Sie können dann MLflow in Azure Synapse Analytics so verwenden, wie Sie es gewohnt sind. Ausführliche Informationen finden Sie unter Protokollieren und Anzeigen von Metriken und Protokolldateien.
Registrieren von Modellen in der Registrierung mit MLflow
Modelle können im Azure Machine Learning-Arbeitsbereich registriert werden, der ein zentrales Repository zum Verwalten des Lebenszyklus bietet. Im folgenden Beispiel wird ein mit Spark MLLib trainiertes Modell protokolliert und auch in der Registrierung registriert.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Falls kein registriertes Modell mit dem angegebenen Namen vorhanden ist, registriert die Methode ein neues Modell, erstellt die Version 1 und gibt das MLflow-Objekt „ModelVersion“ zurück.
Wenn bereits ein registriertes Modell mit dem Namen vorhanden ist, erstellt die Methode eine neue Modellversion und gibt das Versionsobjekt zurück.
Sie können in Azure Machine Learning registrierte Modelle mit MLflow verwalten. Unter Verwalten von Modellregistrierungen in Azure Machine Learning mit MLflow erhalten Sie weitere Informationen.
Bereitstellen und Verwenden von in Azure Machine Learning registrierten Modellen
Modelle, die in Azure Machine Learning Service mit MLflow registriert sind, können wie folgt genutzt werden:
Ein Azure Machine Learning-Endpunkt (Echtzeit und Batch): Mit dieser Bereitstellung können Sie die Bereitstellungsfunktionen von Azure Machine Learning sowohl für Echtzeit- als auch für Batchrückschlüsse in Azure Container Instances (ACI), Azure Kubernetes (AKS) oder unseren verwalteten Endpunkten nutzen.
MLFlow-Modellobjekte oder Pandas-UDFs, die in Azure Synapse Analytics-Notebooks in Streaming- oder Batchpipelines verwendet werden können.
Bereitstellen von Modellen für Azure Machine Learning-Endpunkte
Sie können das azureml-mlflow-Plug-In nutzen, um ein Modell in Ihrem Azure Machine Learning-Arbeitsbereich bereitzustellen. Auf der Seite Bereitstellen von MLflow-Modellen finden Sie ausführliche Informationen darüber, wie Modelle auf den verschiedenen Zielen bereitgestellt werden.
Wichtig
Modelle müssen in der Azure Machine Learning-Registrierung registriert werden, um sie bereitstellen zu können. Die Bereitstellung nicht registrierter Modelle wird in Azure Machine Learning nicht unterstützt.
Bereitstellen von Modellen für die Batchbewertung mit UDFs
Sie können Azure Synapse Analytics-Cluster zur Batchbewertung auswählen. Das MLflow-Modell wird geladen und als Spark Pandas-UDF verwendet, um neue Daten zu bewerten.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Bereinigen von Ressourcen
Wenn Sie Ihren Azure Synapse Analytics-Arbeitsbereich beibehalten möchten, aber den Azure Machine Learning-Arbeitsbereich nicht mehr benötigen, können Sie Letzteren löschen. Falls Sie nicht planen, die protokollierten Metriken und Artefakte in Ihrem Arbeitsbereich zu verwenden, beachten Sie, dass das Löschen einzelner Einträge derzeit nicht möglich ist. Löschen Sie stattdessen die Ressourcengruppe, die das Speicherkonto und den Arbeitsbereich enthält, damit hierfür keine Gebühren anfallen:
Wählen Sie ganz links im Azure-Portal Ressourcengruppen aus.
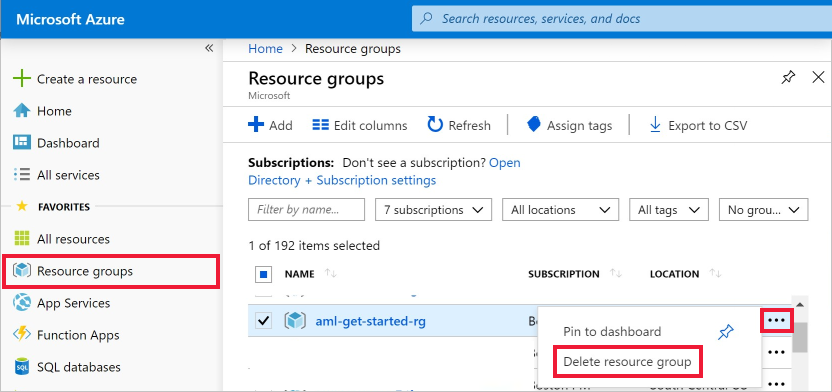
Wählen Sie in der Liste die Ressourcengruppe aus, die Sie erstellt haben.
Wählen Sie die Option Ressourcengruppe löschen.
Geben Sie den Ressourcengruppennamen ein. Wählen Sie anschließend die Option Löschen.