Tutorial: Trainieren eines TensorFlow-Modells für die Bildklassifizierung mit der Azure Machine Learning-Erweiterung für Visual Studio Code (Vorschau)
GILT FÜR  Azure CLI-ML-Erweiterung v2 (aktuell)
Azure CLI-ML-Erweiterung v2 (aktuell)
Hier erfahren Sie, wie Sie mit TensorFlow und der Azure Machine Learning-Erweiterung für Visual Studio Code ein Bildklassifizierungsmodell für die Erkennung handgeschriebener Ziffern trainieren.
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Tutorial lernen Sie Folgendes:
- Grundlegendes zum Code
- Erstellen eines Arbeitsbereichs
- Trainieren eines Modells
Voraussetzungen
- Azure-Abonnement. Wenn Sie keins besitzen, können Sie sich für die kostenlose oder kostenpflichtige Version von Azure Machine Learning registrieren. Wenn Sie das kostenlose Abonnement verwenden, werden nur CPU-Cluster unterstützt.
- Installieren Sie Visual Studio Code. Hierbei handelt es sich um einen einfachen plattformübergreifenden Code-Editor.
- Azure Machine Learning Studio-Erweiterung für Visual Studio Code Eine Installationsanleitung finden Sie in der Anleitung zum Einrichten der Azure Machine Learning-Erweiterung für Visual Studio Code.
- CLI (v2). Eine Anleitung zur Installation finden Sie unter Installieren, Einrichten und Verwenden der CLI (v2).
- Klonen des Communityrepositorys
git clone https://github.com/Azure/azureml-examples.git
Grundlegendes zum Code
Der Code für dieses Tutorial verwendet TensorFlow zum Trainieren eines Machine Learning-Modells für die Bildklassifizierung, das handgeschriebene Ziffern von 0 bis 9 kategorisiert. Dazu wird ein neuronales Netzwerk erstellt, das die Pixelwerte eines Bilds mit 28 px × 28 px als Eingabe verwendet und eine Liste mit zehn Wahrscheinlichkeiten ausgibt, eine für jede der zu klassifizierenden Ziffern. Dies ist ein Beispiel dafür, wie die Daten aussehen.

Erstellen eines Arbeitsbereichs
Als Erstes müssen Sie einen Arbeitsbereich erstellen, damit Sie eine Anwendung in Azure Machine Learning erstellen können. Ein Arbeitsbereich enthält die Ressourcen zum Trainieren von Modellen sowie die trainierten Modelle selbst. Weitere Informationen finden Sie unter Was ist ein Arbeitsbereich?.
Öffnen Sie das Verzeichnis azureml-examples/cli/jobs/single-step/tensorflow/mnist im Communityrepository in Visual Studio Code.
Wählen Sie auf der Aktivitätsleiste von Visual Studio Code das Azure-Symbol aus, um die Azure Machine Learning-Ansicht zu öffnen.
Klicken Sie in der Azure Machine Learning-Ansicht mit der rechten Maustaste auf Ihren Abonnementknoten, und wählen Sie Arbeitsbereich erstellen aus.
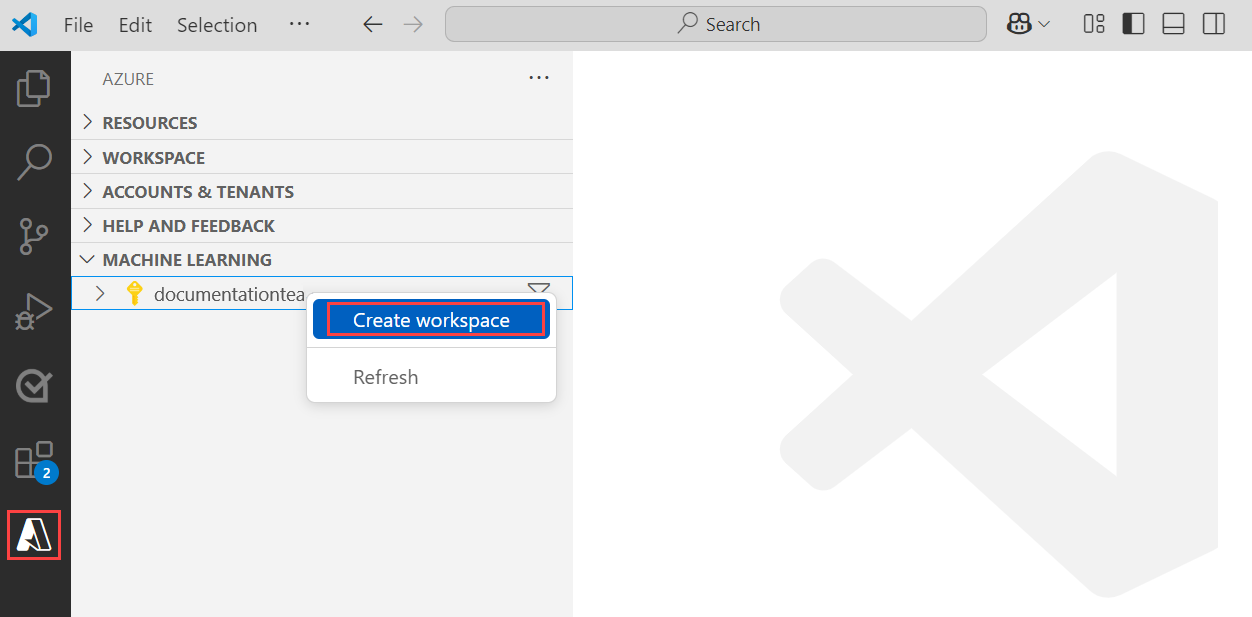
Eine Spezifikationsdatei wird angezeigt. Konfigurieren Sie die Spezifikationsdatei mit den folgenden Optionen.
$schema: https://azuremlschemas.azureedge.net/latest/workspace.schema.json name: TeamWorkspace location: WestUS2 display_name: team-ml-workspace description: A workspace for training machine learning models tags: purpose: training team: ml-teamDie Spezifikationsdatei erstellt einen Arbeitsbereich namens
TeamWorkspacein der RegionWestUS2. Mit den restlichen Optionen, die in der Spezifikationsdatei definiert sind, werden benutzerfreundliche Namen, Beschreibungen und Tags für den Arbeitsbereich angegeben.Klicken Sie mit der rechten Maustaste auf die Spezifikationsdatei, und wählen Sie AzureML: YAML ausführen aus. Beim Erstellen einer Ressource werden die Konfigurationsoptionen verwendet, die in der YAML-Spezifikationsdatei definiert sind, und über die CLI (v2) wird ein Auftrag übermittelt. An diesem Punkt wird eine Anforderung zum Erstellen eines neuen Arbeitsbereichs und der abhängigen Ressourcen in Ihrem Konto an Azure gesendet. Nach einigen Minuten wird der neue Arbeitsbereich in Ihrem Abonnementknoten angezeigt.
Wählen Sie
TeamWorkspaceals Standardarbeitsbereich aus. Die von Ihnen erstellten Ressourcen und Aufträge werden dann standardmäßig im Arbeitsbereich platziert. Wählen Sie in der Visual Studio Code-Statusleiste die Schaltfläche Azure Machine Learning-Arbeitsbereich festlegen aus, und befolgen Sie die Anweisungen zum Festlegen vonTeamWorkspaceals Standardarbeitsbereich.
Weitere Informationen zu Arbeitsbereichen finden Sie im Artikel zum Verwalten von Ressourcen in VS Code.
Trainieren des Modells
Während des Trainingsprozesses wird ein TensorFlow-Modell trainiert, indem die darin eingebetteten Trainingsdaten und Lernmuster für die einzelnen zu klassifizierenden Ziffern verarbeitet werden.
Trainingsaufträge werden mit Ressourcenvorlagen definiert, wie dies auch bei Arbeitsbereichen und Computezielen der Fall ist. Bei diesem Beispiel wird die Spezifikation in der Datei job.yml definiert, die wie folgt aussieht:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >
python train.py
environment: azureml:AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu:48
resources:
instance_type: Standard_NC12
instance_count: 3
experiment_name: tensorflow-mnist-example
description: Train a basic neural network with TensorFlow on the MNIST dataset.
Mit dieser Spezifikationsdatei wird ein Trainingsauftrag mit dem Namen tensorflow-mnist-example an das vor Kurzem erstellte Computeziel gpu-cluster übermittelt, das den Code im Python-Skript train.py ausführt. Hierbei wird eine der zusammengestellten Umgebungen verwendet, die von Azure Machine Learning bereitgestellt werden. Sie enthält TensorFlow und andere Softwareabhängigkeiten, die zum Ausführen des Trainingsskripts erforderlich sind. Weitere Informationen zu zusammengestellten Umgebungen finden Sie unter Azure Machine Learning – Zusammengestellte Umgebungen.
Übermitteln Sie den Trainingsauftrag wie folgt:
- Öffnen Sie die Datei job.yml.
- Klicken Sie im Text-Editor mit der rechten Maustaste auf die Datei, und wählen Sie AzureML: YAML ausführen aus.
Jetzt wird eine Anforderung zum Ausführen Ihres Experiments auf dem ausgewählten Computeziel in Ihrem Arbeitsbereich an Azure gesendet. Dieser Vorgang dauert einige Minuten. Die Zeitspanne für die Ausführung des Trainingsauftrags ist von mehreren Faktoren abhängig, wie z. B. dem Computetyp und der Größe der Trainingsdaten. Wenn Sie den Status des Experiments nachverfolgen möchten, klicken Sie mit der rechten Maustaste auf den aktuellen Ausführungsknoten, und wählen Sie Auftrag im Azure-Portal anzeigen aus.
Wenn das Dialogfeld mit der Anforderung zum Öffnen einer externen Website angezeigt wird, wählen Sie Öffnen aus.
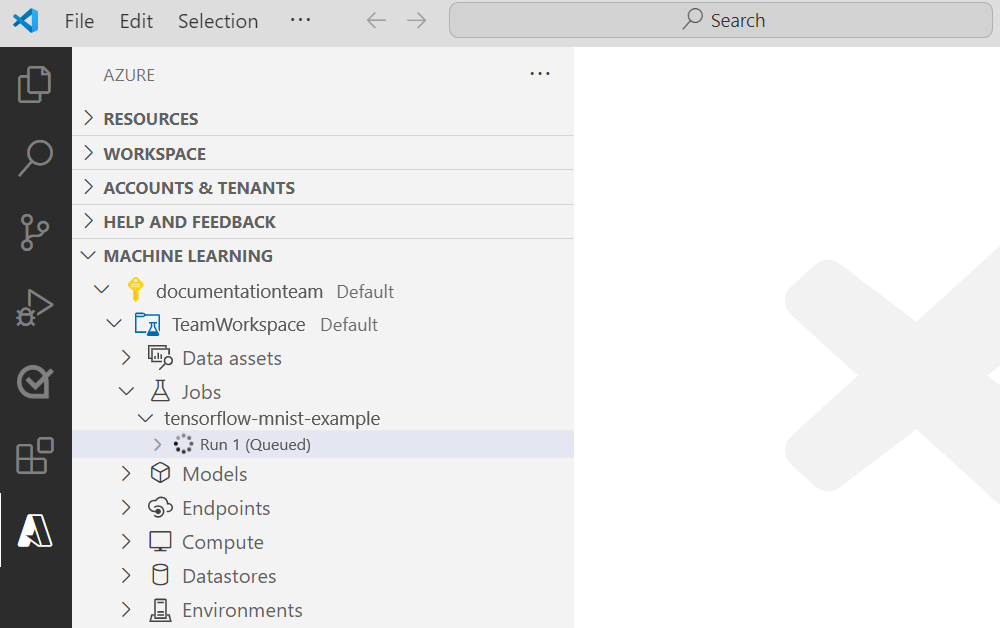
Wenn das Modell mit dem Training fertig ist, wird die Statusbezeichnung neben dem Ausführungsknoten in „Abgeschlossen“ geändert.
Nächste Schritte
- Starten von in Azure Machine Learning integriertem Visual Studio Code (Vorschau)
- Eine exemplarische Vorgehensweise zum lokalen Bearbeiten, Ausführen und Debuggen von Code finden Sie im Python-Hello World-Tutorial.
- Ausführen von Jupyter Notebooks in Visual Studio Code über einen Jupyter-Remoteserver
- Eine exemplarische Vorgehensweise zum Trainieren mit Azure Machine Learning außerhalb von Visual Studio Code finden Sie unter Tutorial: Trainieren und Bereitstellen eines Modells mit Azure Machine Learning.