Blockerstellung für große Dokumente für Vektorsuchlösungen in Azure KI Search
Die Partitionierung großer Dokumente in kleinere Blöcke kann Ihnen helfen, unter den maximalen Tokeneingabegrenzwerten von Einbettungsmodellen zu bleiben. Die maximale Länge des Eingabetexts für das Azure OpenAI-Modell text-embedding-ada-002 liegt beispielsweise bei 8191 Token. Da bei gängigen OpenAI-Modellen jedes Token ca. vier Zeichen Text umfasst, entspricht diese Obergrenze etwa 6.000 Wörtern. Wenn Sie diese Modelle zum Generieren von Einbettungen verwenden, ist es wichtig, dass der Eingabetext den Grenzwert nicht übersteigt. Durch die Partitionierung Ihrer Inhalte in Blöcke wird sichergestellt, dass Ihre Daten von den Einbettungsmodellen verarbeitet werden können und dass Sie aufgrund des Abschneidens keine Informationen verlieren.
Wir empfehlen die integrierte Vektorisierung für integrierte Datenblöcke und Einbettungen. Integrierte Vektorisierung hat eine Abhängigkeit von Indexierern, Skillsets, der Textteilungsfähigkeit und einer Einbettungsfähigkeit wie der Azure OpenAI-Einbettungsfähigkeit. Wenn Sie die integrierte Vektorisierung nicht verwenden können, beschreibt dieser Artikel einige Ansätze für die Blockerstellung Ihrer Inhalte.
Gängige Blockerstellungstechniken
Die Segmentierung ist nur erforderlich, wenn die Quelldokumente für die von Modellen vorgegebene maximale Eingabegröße zu groß sind.
Hier sind einige gängige Blockerstellungstechniken, beginnend mit der am häufigsten verwendeten Methode:
Blöcke mit fester Größe: Definieren Sie eine feste Größe, die für semantisch aussagekräftige Absätze (z. B. 200 Wörter) ausreicht und eine gewisse Überschneidung ermöglicht (z. B. 10–15 Prozent des Inhalts), um geeignete Blöcke als Eingabe für Generatoren von Einbettungsvektoren zu erzeugen.
Blöcke mit variabler Größe basierend auf dem Inhalt: Partitionieren Sie Ihre Daten basierend auf Inhaltsmerkmalen wie Satzzeichen am Satzende oder Zeilenende-Markierungen oder unter Verwendung von Features aus den NLP-Bibliotheken (Natural Language Processing, linguistische Datenverarbeitung). Auch die Markdown-Sprachstruktur kann zum Aufteilen der Daten verwendet werden.
Passen Sie eine der oben genannten Techniken an, oder durchlaufen Sie sie. Wenn Sie z. B. mit großen Dokumenten arbeiten, können Sie Blöcke mit variabler Größe verwenden, aber auch den Dokumenttitel an Blöcke aus der Mitte des Dokuments anfügen, um zu verhindern, dass der Kontext verloren geht.
Überlegungen zu Inhaltsüberschneidungen
Wenn Sie Datenblöcke erstellen, können Überschneidungen kleiner Textmengen zwischen Blöcken dazu beitragen, den Kontext zu bewahren. Es wird empfohlen, mit einer Überschneidung von ca. zehn Prozent zu beginnen. Bei einer festen Blockgröße von 256 Token können Sie zu Testzwecken beispielsweise mit einer Überschneidung von 25 Token beginnen. Die tatsächliche Überschneidung variiert je nach Anwendungsfall und Art der Daten. Nach unserer Erfahrung sind jedoch 10–15 Prozent ein guter Wert für viele Szenarien.
Faktoren für die Datenblockerstellung
Berücksichtigen Sie bei der Datenblockerstellung die folgenden Faktoren:
Form und Dichte Ihrer Dokumente. Wenn Sie vollständigen Text oder vollständige Passagen benötigen, können größere Blöcke und variable Blöcke, die die Satzstruktur bewahren, bessere Ergebnisse liefern.
Benutzerabfragen: Größere Blöcke und Überschneidungsstrategien tragen dazu bei, den Kontext und die semantische Vielfalt für Abfragen zu bewahren, die auf bestimmte Informationen abzielen.
Große Sprachmodelle (Large Language Models, LLMs) verfügen über Leistungsrichtlinien für die Blockgröße. Sie müssen eine Blockgröße festlegen, die für alle von Ihnen verwendeten Modelle bestmöglich geeignet ist. Wenn Sie beispielsweise Modelle für Zusammenfassungen und Einbettungen verwenden, wählen Sie eine optimale Blockgröße aus, die für beides funktioniert.
Platzierung der Blockerstellung im Workflow
Wenn Sie über große Dokumente verfügen, müssen Sie einen Schritt zur Blockerstellung in die Indizierungs- und Abfrageworkflows einfügen, der großen Text aufteilt. Bei Verwendung der integrierten Vektorisierung wird eine Standardstrategie zur Blockerstellung mit dem Textaufteilungsskill angewendet. Sie können auch eine benutzerdefinierte Strategie zur Blockerstellung mit einem benutzerdefinierten Skill anwenden. Hier finden Sie einige Bibliotheken, die Blockerstellung bereitstellen:
Die meisten Bibliotheken bieten allgemeine Blockerstellungstechniken für feste Größe, variable Größe oder eine Kombination aus beidem. Sie können auch eine Überlappung angeben, die eine geringe Menge an Inhalten in jedem Block dupliziert, damit der Kontext erhalten bleibt.
Beispiele für die Blockerstellung
Die folgenden Beispiele zeigen, wie Strategien zur Blockerstellung auf die PDF-Datei E-Book „Earth at Night“ der NASA angewendet werden:
Beispiel für den Textaufteilungsskill
Die integrierte Datenblockerstellung durch den Textaufteilungsskill befindet sich in der öffentlichen Vorschau.
In diesem Abschnitt werden die integrierten Datenblockerstellung mithilfe eines skillgesteuerten Ansatzes und Parameter für die Textaufteilung beschrieben.
Ein Beispiel-Notebook für dieses Beispiel finden Sie im Repository azure-search-vector-samples.
Legen Sie textSplitMode fest, um Inhalte in kleinere Blöcke aufzuteilen:
pages(Standardwert). Blöcke bestehen aus mehreren Sätzen.sentences. Blöcke bestehen aus einzelnen Sätzen. Was ein „Satz“ ist, hängt von der Sprache ab. Im Englischen werden standardmäßig Satzschlusszeichen wie.oder!verwendet. Die Sprache wird mit dem ParameterdefaultLanguageCodegesteuert.
Der Parameter pages fügt zusätzliche Parameter hinzu:
maximumPageLengthdefiniert die maximale Anzahl von Zeichen1 oder Token 2 in jedem Block. Bei der Textaufteilung wird das Aufteilen von Sätzen vermieden, sodass die tatsächliche Zeichenanzahl vom Inhalt abhängt.pageOverlapLengthdefiniert, wie viele Zeichen vom Ende der vorherigen Seite am Anfang der nächsten Seite stehen. Wird dieser Wert festgelegt, muss er kleiner als die Hälfte der maximalen Seitenlänge sein.maximumPagesToTakedefiniert, wie viele Seiten/Blöcke aus einem Dokument entnommen werden sollen. Der Standardwert ist 0. Das bedeutet, dass alle Seiten oder Blöcke aus dem Dokument genommen werden.
1 Zeichen entsprechen nicht der Definition eines Tokens. Die vom LLM gemessene Anzahl von Token kann sich von der Zeichengröße unterscheiden, die vom Textaufteilungsskill gemessen wird.
2 Tokensegmentierung ist in der Vorschauversion 2024-09-01-preview verfügbar und enthält zusätzliche Parameter zum Angeben eines Tokenizers und aller Token, die während der Segmentierung nicht aufgeteilt werden sollten.
In der folgenden Tabelle wird gezeigt, wie sich die Auswahl von Parametern auf die Gesamtanzahl der Blöcke aus dem E-Book „Earth at Night“ auswirkt:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Gesamtanzahl der Blöcke |
|---|---|---|---|
pages |
1.000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
– | – | 13.361 |
Die Verwendung von pages für textSplitMode führt dazu, dass der Großteil der Blöcke eine Gesamtzeichenanzahl von etwa maximumPageLength hat. Die Zeichenanzahl der Blöcke variiert aufgrund von Unterschieden dahingehend, ob Satzgrenzen in den Block fallen. Die Länge des Blocktokens variiert aufgrund von Unterschieden im Inhalt des Blocks.
Die folgenden Histogramme zeigen die Verteilung der Blockzeichenlänge im Vergleich zu einer Blocktokenlänge für gpt-35-turbo, wenn im E-Book „Earth at Night“ folgende Werte festgelegt werden: pages für textSplitMode, 2.000 für maximumPageLength und 500 für pageOverlapLength:
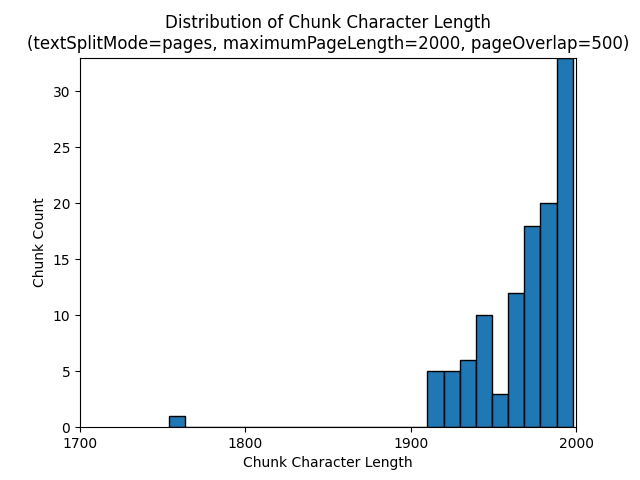

Die Verwendung von sentences für textSplitMode führt zu einer großen Anzahl von Blöcken, die aus einzelnen Sätzen bestehen. Diese Blöcke sind deutlich kleiner als die von pages erzeugten, und die Tokenanzahl der Blöcke entspricht eher der Zeichenanzahl.
Die folgenden Histogramme zeigen die Verteilung der Blockzeichenlänge im Vergleich mit der Blocktokenlänge für gpt-35-turbo, wenn im E-Book „Earth at Night“ sentences für textSplitMode verwendet wird.


Die optimale Auswahl der Parameter hängt davon ab, wie die Blöcke verwendet werden. Für die meisten Anwendungen wird empfohlen, mit den folgenden Standardparametern zu beginnen:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Beispiel für langChain-Datenblockerstellung
LangChain stellt Dokumentladeprogramme und Textaufteilungen bereit. In diesem Beispiel wird gezeigt, wie Sie eine PDF-Datei laden, die Tokenanzahl abrufen und eine Textaufteilung einrichten. Das Abrufen der Tokenanzahl hilft Ihnen, eine fundierte Entscheidung über die Dimensionierung von Datenblöcken zu treffen.
Ein Beispiel-Notebook für dieses Beispiel finden Sie im Repository azure-search-vector-samples.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
Die Ausgabe gibt 200 Dokumente oder Seiten in der PDF an.
Verwenden Sie TikToken, um eine geschätzte Tokenanzahl für diese Seiten zu erhalten.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
Die Ausgabe zeigt, dass keine Seite null Token hat, die durchschnittliche Tokenlänge pro Seite 189 Token ist und die maximale Tokenanzahl einer beliebigen Seite 1.583 beträgt.
Die Kenntnis der durchschnittlichen und maximalen Tokengröße gibt Ihnen Aufschluss über die Einstellung der Blockgröße. Obwohl Sie die Standardempfehlung von 2.000 Zeichen mit einer Überlappung von 500 Zeichen verwenden können, ist es in diesem Fall sinnvoll, angesichts der Tokenanzahl des Beispieldokuments einen niedrigeren Wert zu verwenden. Tatsächlich kann das Festlegen eines zu hohen Überlappungswerts dazu führen, dass überhaupt keine Überlappung erfolgt.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
Die Ausgabe für zwei aufeinanderfolgende Blöcke zeigt den Text aus dem ersten Block, der sich mit dem zweiten Block überlappt. Die Ausgabe wurde zur besseren Lesbarkeit bearbeitet.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Benutzerdefinierter Skill
Ein Beispiel für Blöcke mit fester Größe und die Generierung von Einbettungen veranschaulicht sowohl die Blockerstellung als auch die Generierung von Vektoreinbettungen mit Einbettungsmodellen von Azure OpenAI. In diesem Beispiel wird ein benutzerdefinierter Skill der Azure KI-Suche im Power Skills-Repository verwendet, um den Blockerstellungsschritt zu umschließen.