Bereitstellen eines verwalteten Service Fabric-Clusters über Verfügbarkeitszonen hinweg
Verfügbarkeitszonen in Azure sind ein Hochverfügbarkeitsangebot, das Anwendungen und Daten vor Ausfällen von Rechenzentren schützt. Eine Verfügbarkeitszone ist ein eindeutiger physischer Standort, der mit unabhängiger Stromversorgung, Kühlung und Netzwerk innerhalb einer Azure-Region ausgestattet ist.
Ein verwalteter Service Fabric-Cluster unterstützt Bereitstellungen, die sich über mehrere Verfügbarkeitszonen erstrecken, um Zonenresilienz bereitzustellen. Durch diese Konfiguration wird Hochverfügbarkeit der kritischen Systemdienste und Ihrer Anwendungen sichergestellt, um vor Single Points of Failure zu schützen. Azure-Verfügbarkeitszonen sind nur in ausgewählten Regionen verfügbar. Weitere Informationen finden Sie unter Übersicht über Azure-Verfügbarkeitszonen.
Hinweis
Die verfügbarkeitszonenübergreifende Funktion ist nur in Standard-SKU-Clustern verfügbar.
Es sind Beispielvorlagen verfügbar: Verfügbarkeitszonenübergreifende Service Fabric-Vorlage
Topologie für zonenresiliente verwaltete Azure Service Fabric-Cluster
Hinweis
Der Vorteil, den primären Knotentyp über die Verfügbarkeitszonen hinweg zu verteilen, zeigt sich eigentlich nur bei drei Zonen und nicht bei zwei Zonen.
Ein Service Fabric-Cluster, der über die Verfügbarkeitszonen verteilt ist, stellt die Hochverfügbarkeit des Clusterzustands sicher.
Die empfohlene Topologie für verwaltete Cluster erfordert die folgenden Ressourcen:
- Die Cluster-SKU muss Standard sein.
- Der primäre Knotentyp sollte mindestens neun Knoten (drei in jeder Verfügbarkeitszone) für optimale Resilienz aufweisen, unterstützt werden jedoch mindestens sechs Knoten (zwei in jeder Verfügbarkeitszone).
- Die sekundären Knotentypen sollten mindestens sechs Knoten für optimale Resilienz aufweisen, unterstützt werden jedoch mindestens drei Knoten.
Hinweis
Es werden nur drei Bereitstellungen von Verfügbarkeitszonen unterstützt.
Hinweis
Es ist nicht möglich, die Skalierungssätze für virtuelle Maschinen in einem verwalteten Cluster von einem nichtzonenübergreifenden Cluster zu einem zonenübergreifenden Cluster zu ändern.
Diagramm, das die Azure Service Fabric Verfügbarkeitszonenarchitektur zeigt 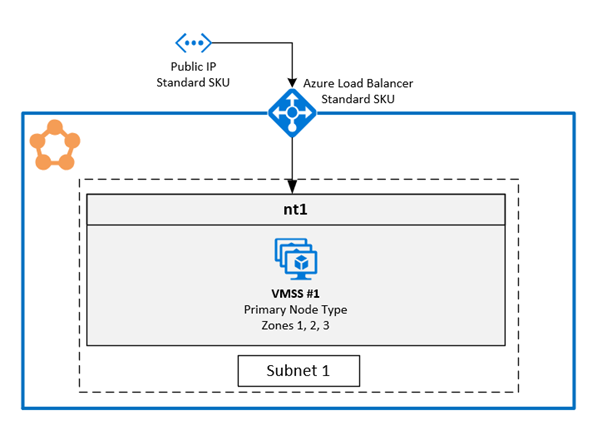
Beispiel Knotenliste mit FD/UD-Formaten in einer zonenübergreifenden VM-Skalierungsgruppe

Zonenübergreifende Verteilung von Dienstreplikaten: Wenn ein Dienst auf den zonenübergreifenden Knotentypen bereitgestellt wird, werden die Replikate so platziert, dass sichergestellt ist, dass sie in separaten Zonen angeordnet werden. Diese Trennung wird sichergestellt, da die Fehlerdomänen auf den Knoten, die in jedem dieser Knotentypen vorhanden sind, mit den Zoneninformationen konfiguriert sind (d. h. FD = fd:/zone1/1 etc.). Beispiel: Für fünf Replikate oder Instanzen eines Diensts lautet die Verteilung 2-2-1, und die Runtime versucht, eine gleichmäßige Verteilung über Verfügbarkeitszonen hinweg sicherzustellen.
Replikatkonfigurationfür den Benutzerdienst: Zustandsbehaftete Benutzerdienste, die auf den Knotentypen für zonenübergreifende Verfügbarkeit bereitgestellt werden, müssen mit dieser Konfiguration konfiguriert werden: Replikatanzahl mit Ziel = 9, min = 5. Diese Konfiguration unterstützt den Dienst auch dann, wenn eine Zone ausfällt, da in den anderen beiden Zonen weiterhin sechs Replikate in Betrieb sind. Auch ein Anwendungsupgrade wird in einem solchen Szenario durchlaufen.
Szenario bei Zonenausfall: Wenn eine Zone ausfällt, werden alle Knoten in dieser Zone als ausgefallen angezeigt. Auch die Dienstreplikate auf diesen Knoten sind ausgefallen. Da in den anderen Zonen Replikate vorhanden sind, reagiert der Dienst weiterhin mit einem Failover der primären Replikate auf die Zonen, die funktionsfähig sind. Die Dienste werden mit dem Status „Warnung“ angezeigt, da die Anzahl der Zielreplikate nicht erreicht wurde und die VM-Anzahl immer noch über der definierten minimalen Zielreplikatgröße liegt. Daher startet der Service Fabric-Lastenausgleich in den Arbeitszonen so viele Replikate, dass die Anzahl der konfigurierten Zielreplikatanzahl entspricht. An diesem Punkt sollten die Dienste fehlerfrei erscheinen. Wenn die ausgefallene Zone wieder verfügbar ist, verteilt der Lastenausgleich alle Dienstreplikate gleichmäßig auf alle Zonen.
Netzwerkkonfiguration
Weitere Informationen finden Sie unter Konfigurieren von Netzwerkeinstellungen für verwaltete Service Fabric-Cluster.
Aktivieren eines zonenresilienten verwalteten Azure Service Fabric-Clusters
Um einen zonenresilienten verwalteten Azure Service Fabric-Cluster zu aktivieren, müssen Sie die folgende ZonalResiliency-Eigenschaft einschließen, die angibt, ob der Cluster zonenresilient ist oder nicht:
{
"apiVersion": "2021-05-01",
"type": "Microsoft.ServiceFabric/managedclusters",
"properties": {
...
"zonalResiliency": "true",
...
}
}
Migrieren eines vorhandenen nicht zonenresilienten Clusters zu Zonenresilient
Vorhandene verwaltete Service Fabric-Cluster, die nicht über Verfügbarkeitszonen verteilt sind, können jetzt direkt zu Verfügbarkeitszonen migriert werden. Unterstützte Szenarien umfassen Cluster, die in Regionen mit drei Verfügbarkeitszonen sowie Clustern in Regionen erstellt wurden, in denen drei Verfügbarkeitszonen nach der Bereitstellung zur Verfügung gestellt werden.
Anforderungen:
- Standard-SKU-Cluster
- Drei Verfügbarkeitszonen in der Region.
Hinweis
Die Migration zu einer zonenresilienten Konfiguration kann zu einem kurzen Verlust der externen Konnektivität durch den Lastenausgleich führen, wirkt sich jedoch nicht auf die Clusterintegrität aus. Dies tritt auf, wenn eine neue öffentliche IP erstellt werden muss, um die Netzwerksicherheit für Zonenfehler zu erzielen. Planen Sie die Migration entsprechend.
Beginnen Sie mit der Bestimmung, ob eine neue IP erforderlich ist und welche Ressourcen migriert werden müssen, um zonenresilient zu werden. Um den aktuellen Resilienzstatus der Verfügbarkeitszone für die Ressourcen des verwalteten Clusters abzurufen, verwenden Sie den folgenden API-Aufruf:
POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName}/getazresiliencystatus?api-version=2022-02-01-previewOder Sie können das Az-Modul wie folgt verwenden:
Select-AzSubscription -SubscriptionId {subscriptionId} Invoke-AzResourceAction -ResourceId /subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName} -Action getazresiliencystatus -ApiVersion 2022-02-01-previewDieser Befehl sollte etwa folgende Antwort zurückgeben:
{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": false }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": false }, { "resourceName": "primary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": false } ], "isClusterZoneResilient": false }Wenn die öffentliche IP-Ressource nicht zonenresilient ist, führt die Migration des Clusters zu einem kurzen Verlust der externen Konnektivität. Dieser Verbindungsabbruch ist darauf zurückzuführen, dass bei der Migration eine neue öffentliche IP eingerichtet und der FQDN (Fully Qualified Domain Name, vollqualifizierter Domänenname) des Clusters auf die neue IP aktualisiert wird. Wenn die öffentliche IP-Ressource zonenresilient ist, ändert die Migration die öffentliche IP-Ressource oder den FQDN nicht, und es gibt keine Auswirkungen auf die externe Konnektivität.
Starten Sie die Konvertierung des zugrunde liegenden Speicherkontos, das für den verwalteten Cluster erstellt wurde, von lokal redundantem Speicher (LRS) zu zonenredundantem Speicher (ZRS) unter Verwendung der vom Kunden initiierten Konvertierung. Die Ressourcengruppe des Speicherkontos, das migriert werden muss, wäre das Formular „SFC_ClusterId“ (Bsp. SFC_9240df2f-71ab-4733-a641-53a84d992d) unter demselben Abonnement wie die verwaltete Clusterressource.
Hinzufügen einer Zoneneigenschaft zu vorhandenen Knotentypen
In diesem Schritt wird die verwaltete VM-Skalierungsgruppe, die dem Knotentyp zugeordnet ist, als zonenresilient konfiguriert, um sicherzustellen, dass alle neuen hinzugefügten VMs über Verfügbarkeitszonen (zonale VMs) bereitgestellt werden. Wenn als Knotentyp „Primär“ angegeben ist, führt der Ressourcenanbieter die Migration der öffentlichen IP zusammen mit einem Cluster-FQDN-DNS-Update durch, falls erforderlich, um zonenresilient zu werden. Verwenden Sie die API
getazresiliencystatus, um die Auswirkungen dieses Schritts zu verstehen.
Verwenden Sie apiVersion 2022-02-01-preview oder höher.
Fügen Sie den auf
["1", "2", "3"]festgelegten Parameterzoneszu vorhandenen Knotentypen hinzu:{ "apiVersion": "2024-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters/nodetypes", "name": "[concat(parameters('clusterName'), '/', parameters('nodeTypeName'))]", "location": "[resourcegroup().location]", "dependsOn": [ "[concat('Microsoft.ServiceFabric/managedclusters/', parameters('clusterName'))]" ], "properties": { ... "isPrimary": true, "zones": ["1", "2", "3"] ... } }, { "apiVersion": "2024-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters/nodetypes", "name": "[concat(parameters('clusterName'), '/', parameters('nodeTypeNameSecondary'))]", "location": "[resourcegroup().location]", "dependsOn": [ "[concat('Microsoft.ServiceFabric/managedclusters/', parameters('clusterName'))]" ], "properties": { ... "isPrimary": false, "zones": ["1", "2", "3"] ... } }
Skalieren Sie Knotentypen zum Hinzufügen zonaler Knoten und Entfernen regionaler Knoten
In dieser Phase wird die VM-Skalierungsgruppe als zonenresilient gekennzeichnet. Beim Hochskalieren werden neu hinzugefügte Knoten also zonal, und beim Herunterskalieren werden regionale Knoten entfernt. Dieser Ansatz bietet die Flexibilität, die Skalierung in jeder beliebigen Reihenfolge vorzunehmen, die Ihren Kapazitätsanforderungen entspricht, indem Sie die
vmInstanceCount-Eigenschaft der Knotentypen anpassen.Wenn beispielsweise der anfängliche Wert für „vmInstanceCount“ auf 6 festgelegt ist (sechs regionale Knoten), können Sie zwei Bereitstellungen ausführen:
- Erste Bereitstellung: Erhöhen Sie „vmInstanceCount“ auf 12, um 6 zonale Knoten hinzuzufügen.
- Zweite Bereitstellung: Verringern Sie „vmInstanceCount“ auf 6, um alle regionalen Knoten zu entfernen.
Während des gesamten Prozesses können Sie die
getazresiliencystatus-API überprüfen, um den Status abzurufen, wie unten dargestellt. Der Vorgang wird als abgeschlossen betrachtet, sobald jeder Knotentyp mindestens 6 Zonenknoten und 0 regionale Knoten aufweist.{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": true }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": true }, { "resourceName": "ntPrimary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": false "details": "Status: InProgress, ZonalNodes: 6, RegionalNodes: 6" }, { "resourceName": "ntSecondary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" } ], "isClusterZoneResilient": false }Hinweis
Der Skalierungsprozess für den primären Knotentyp erfordert zusätzliche Zeit, da jedes Hinzufügen oder Entfernen eines Knotens ein Service Fabric-Clusterupgrade initiiert.
Markieren des Clusters, der für Zonenfehler resilient ist
Dieser Schritt hilft in zukünftigen Bereitstellungen, da alle zukünftigen Bereitstellungen von Knotentypen über Verfügbarkeitszonen hinweg bestehen und damit das Cluster weiterhin tolerant für AZ-Fehler bleibt. Legen Sie
zonalResiliency: truein der Cluster-ARM-Vorlage fest, und führen Sie eine Bereitstellung aus, um Cluster als zonenresilient zu markieren und sicherzustellen, dass alle neuen Knotentypbereitstellungen über Verfügbarkeitszonen verfügen. Dieses Update ist nur zulässig, wenn alle Knotentypen mindestens 6 Zonenknoten und 0 regionale Knoten aufweisen.{ "apiVersion": "2022-02-01-preview", "type": "Microsoft.ServiceFabric/managedclusters", "zonalResiliency": "true" }Sie können den aktualisierten Status auch nach Abschluss im Portal unter Übersicht -> Eigenschaften wie
Zonal resiliency Trueanzeigen.Überprüfen, dass alle Ressourcen zonenresilient sind
Um den Resilienzstatus der Verfügbarkeitszone für die Ressourcen des verwalteten Clusters zu validieren, verwenden Sie den folgenden GET API-Aufruf:
POST https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.ServiceFabric/managedClusters/{clusterName}/getazresiliencystatus?api-version=2022-02-01-previewDieser API-Aufruf sollte etwa folgende Antwort zurückgeben:
{ "baseResourceStatus" :[ { "resourceName": "sfmccluster1" "resourceType": "Microsoft.Storage/storageAccounts" "isZoneResilient": true }, { "resourceName": "PublicIP-sfmccluster1" "resourceType": "Microsoft.Network/publicIPAddresses" "isZoneResilient": true }, { "resourceName": "ntPrimary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" }, { "resourceName": "ntSecondary" "resourceType": "Microsoft.Compute/virutalmachinescalesets" "isZoneResilient": true "details": "Status: Done, ZonalNodes: 6, RegionalNodes: 0" } ], "isClusterZoneResilient": true }Sollten Sie auf Probleme stoßen, wenden Sie sich an den Support, um Hilfe zu erhalten.
Aktivieren von FastZonalUpdate in verwalteten Service Fabric-Clustern
Verwaltete Service Fabric-Cluster unterstützen schnellere Cluster- und Anwendungsupgrades, indem die maximale Anzahl von Upgradedomänen pro Verfügbarkeitszone reduziert wird. Die Standardkonfiguration kann derzeit höchstens 15 Upgradedomänen in mehreren Verfügbarkeitszonen-Knotentypen aufweisen. Diese große Anzahl von Upgradedomänen reduzierte die Upgradegeschwindigkeit. Mit der neuen Konfiguration werden die maximalen Upgradedomänen reduziert, was zu schnelleren Updates führt, ohne dass die Sicherheit der Upgrades beeinträchtigt wird.
Das Update sollte über eine ARM-Vorlage erfolgen, indem Sie die Eigenschaft „zonalUpdateMode“ auf „fast“ festlegen und dann das Knotentypattribut ändern, z. B. durch Hinzufügen eines Knotens zu jedem Knotentyp und anschließendes Entfernen des Knotens (siehe erforderliche Schritte 2 und 3). Die Service Fabric-Version der verwalteten Service Fabric-Clusterressource muss „2022-10-01-preview“ oder höher lauten.
- Ändern Sie die ARM-Vorlage mit der neuen Eigenschaft „zonalUpdateMode“.
"resources": [
{
"type": "Microsoft.ServiceFabric/managedClusters",
"apiVersion": "2022-10-01-preview",
'''
"properties": {
'''
"zonalResiliency": true,
"zonalUpdateMode": "fast",
...
}
}]
Hinzufügen eines Knotens zu einem Cluster mithilfe des „az sf cluster node add“-PowerShell-Befehls.
Entfernen eines Knotens eines Clusters mithilfe des „az sf cluster node remove“-PowerShell-Befehls.