Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Sie können Machine Learning-Modelle als benutzerdefinierte Funktionen (User-Defined Function, UDF) in Ihre Azure Stream Analytics-Aufträge implementieren, um Echtzeitbewertungen und Vorhersagen für Ihre Eingabedatenströme zu erstellen. In Azure Machine Learning können Sie mit beliebten Open-Source-Tools wie TensorFlow, scikit-learn und PyTorch Modelle vorbereiten, trainieren und bereitstellen.
Voraussetzungen
Führen Sie die folgenden Schritte aus, bevor Sie ein Machine Learning-Modell als Funktion zu Ihrem Stream Analytics-Auftrag hinzufügen:
Verwenden Sie Azure Machine Learning, um Ihr Modell als Webdienst bereitzustellen.
Ihrem Machine Learning-Endpunkt muss ein Swagger zugeordnet sein, mit dem Stream Analytics das Schema der Eingabe und Ausgabe verstehen kann. Sie können diese Swagger-Beispieldefinition als Referenz verwenden, um sicherzustellen, dass Sie es ordnungsgemäß eingerichtet haben.
Stellen Sie sicher, dass Ihr Webdienst serialisierte JSON-Daten akzeptiert und zurückgibt.
Stellen Sie Ihr Modell für umfangreiche Produktionsbereitstellungen in Azure Kubernetes Service bereit. Wenn der Webdienst die Menge der von Ihrem Auftrag ausgehenden Anforderungen nicht verarbeiten kann, beeinträchtigt dies die Leistung Ihres Stream Analytics-Auftrags, was sich wiederum auf die Latenz auswirkt. In Azure Container Instances bereitgestellte Modelle werden nur bei Verwendung des Azure-Portals unterstützt.
Hinzufügen eines Machine Learning-Modells zu Ihrem Job
Sie können Azure Machine Learning-Funktionen direkt im Azure-Portal oder in Visual Studio Code zu Ihrem Stream Analytics-Auftrag hinzufügen.
Azure-Portal
Navigieren Sie im Azure-Portal zu Ihrem Stream Analytics-Auftrag, und klicken Sie unter Auftragstopologie auf Funktionen. Wählen Sie dann Azure Machine Learning Service im Dropdownmenü + Hinzufügen aus.
Füllen Sie das Formular Azure Machine Learning Service function (Azure Machine Learning Service-Funktion) mit den folgenden Eigenschaftswerten aus:
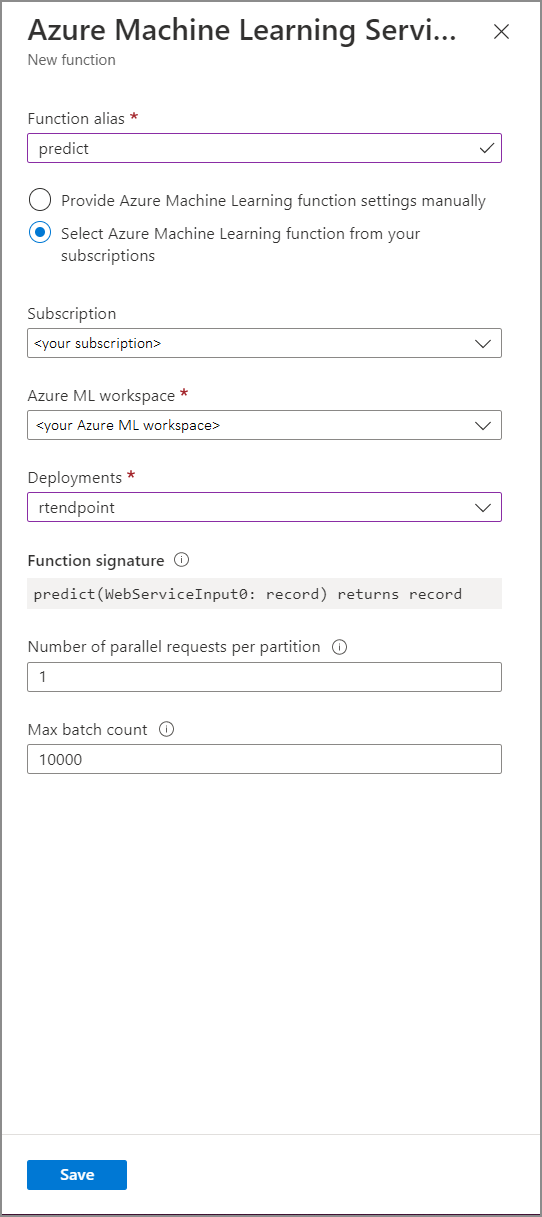
In der folgenden Tabelle werden alle Eigenschaften von Azure Machine Learning Service-Funktionen in Stream Analytics beschrieben.
| Eigenschaft | BESCHREIBUNG |
|---|---|
| Funktionsalias | Geben Sie einen Namen ein, um die Funktion in der Abfrage aufzurufen. |
| Abonnement | Ihr Azure-Abonnement. |
| Azure Machine Learning-Arbeitsbereich | Der Azure Machine Learning-Arbeitsbereich, mit dem Sie Ihr Modell als Webdienst bereitgestellt haben |
| Endpunkt | Der Webdienst, der Ihr Modell hostet |
| Funktionssignatur | Hierbei handelt es sich um die Signatur Ihres Webdiensts, die aus der Schemaspezifikation der API abgeleitet wurde. Wenn beim Laden der Signatur ein Fehler auftritt, überprüfen Sie, ob Sie in Ihrem Bewertungsskript Beispieleingaben und -ausgaben für das automatische Generieren des Schemas bereitgestellt haben. |
| Anzahl paralleler Anfragen pro Partition | Hierbei handelt es sich um eine erweiterte Konfiguration zur Optimierung von umfangreichem Durchsatz. Diese Anzahl steht für die gleichzeitig von jeder Partition Ihres Auftrags an den Webdienst gesendeten Anforderungen. Aufträge mit sechs Streamingeinheiten und weniger verfügen über eine Partition. Aufträge mit 12 Streamingeinheiten verfügen über zwei Partitionen, solche mit 18 Streamingeinheiten über drei Partitionen – und so weiter. Wenn Ihr Auftrag beispielsweise über zwei Partitionen verfügt und Sie für diesen Parameter 4 festlegen, werden acht Anforderungen von Ihrem Auftrag an Ihren Webdienst gleichzeitig ausgeführt. |
| Max Batch Count | Hierbei handelt es sich um eine erweiterte Konfiguration zur Optimierung von umfangreichem Durchsatz. Diese Anzahl steht für die maximale Anzahl von Ereignissen, die in einer einzelnen Anforderung zusammengefasst und an Ihren Webdienst gesendet werden können. |
Aufrufen eines Machine Learning-Endpunkts aus Ihrer Abfrage
Wenn Ihre Stream Analytics-Abfrage eine Azure Machine Learning-UDF aufruft, erstellt der Auftrag eine JSON-serialisierte Anforderung an den Webdienst. Die Anforderung basiert auf einem modellspezifischen Schema, das Stream Analytics vom Swagger des Endpunkts ableitet.
Warnung
Endpunkte für Machine Learning werden nicht aufgerufen, wenn Sie mit dem Abfrageeditor des Azure-Portals testen, da der Auftrag nicht ausgeführt wird. Um den Endpunktaufruf über das Portal zu testen, muss der Stream Analytics-Auftrag ausgeführt werden.
Die folgende Stream Analytics-Abfrage ist ein Beispiel für das Aufrufen einer benutzerdefinierten Azure Machine Learning-Funktion:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Wenn die an die benutzerdefinierte ML-Funktion gesendeten Eingabedaten mit dem erwarteten Schema nicht übereinstimmen, gibt der Endpunkt eine Antwort mit dem Fehlercode 400 zurück, wodurch der Stream Analytics-Auftrag in einen fehlerhaften Zustand versetzt wird. Es wird empfohlen, Ressourcenprotokolle für Ihren Auftrag zu aktivieren, sodass Sie solche Probleme problemlos debuggen und behandeln können. Aus diesem Grund wird Folgendes dringend empfohlen:
- Validieren Sie, dass die Eingabe für Ihre ML-UDF nicht Null ist.
- Überprüfen Sie den Typ jedes Feldes, das eine Eingabe für Ihre ML-UDF ist, um sicherzustellen, dass es den Erwartungen des Endpunkts entspricht.
Hinweis
ML-UDFs werden für jede Zeile eines bestimmten Abfrageschritts ausgewertet, auch wenn sie über einen bedingten Ausdruck (d.h. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END) aufgerufen werden. Verwenden Sie ggf. die WITH-Klausel, um abweichende Pfade zu erstellen, und rufen Sie die benutzerdefinierte ML-Funktion nur bei Bedarf auf, bevor Sie UNION zum erneuten Zusammenführen von Pfaden verwenden.
Übergeben mehrerer Eingabeparameter an die benutzerdefinierte Funktion
Die häufigsten Beispiele für Eingaben bei Machine Learning-Modellen sind NumPy-Arrays und -Datenrahmen. Arrays können Sie mithilfe einer benutzerdefinierten JavaScript-Funktion erstellen und serialisierte JSON-Datenrahmen mit der Klausel WITH.
Erstellen eines Eingabearrays
Sie können eine benutzerdefinierte JavaScript-Funktion erstellen, die N Eingaben akzeptiert und ein Array erstellt, das als Eingabe für Ihre benutzerdefinierte Azure Machine Learning-Funktion verwendet werden kann.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Sobald Sie die JavaScript-UDF zu Ihrem Auftrag hinzugefügt haben, können Sie Ihre Azure Machine Learning-UDF mithilfe der folgenden Abfrage aufrufen.
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Der folgende JSON-Code ist eine Beispielanforderung:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Erstellen eines Pandas- oder PySpark-Datenrahmens
Mit der Klausel WITH können Sie einen serialisierten JSON-Datenrahmen erstellen, der, wie unten gezeigt, als Eingabe an Ihre Azure Machine Learning-Funktion übergeben werden kann.
Mit der folgenden Abfrage wird ein Datenrahmen erstellt, indem die erforderlichen Felder ausgewählt werden. Anschließend wird dieser Datenrahmen als Eingabe für die benutzerdefinierte Azure Machine Learning-Funktion verwendet.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Der folgende JSON-Code ist eine Beispielanforderung für die obige Abfrage:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optimieren der Leistung für benutzerdefinierte Azure Machine Learning-Funktionen
Wenn Sie Ihr Modell in Azure Kubernetes Service bereitstellen, können Sie Ihr Modell profilen, um die Ressourcenverwendung zu ermitteln. Sie können auch AppInsights für Ihre Bereitstellungen aktivieren, um Anforderungsraten, Antwortzeiten und Fehlerraten zu verstehen.
Bei einem Szenario mit hohem Ereignisdurchsatz müssen Sie möglicherweise die folgenden Parameter in Stream Analytics anpassen, um eine optimale Leistung mit geringer End-to-End-Latenz zu erreichen:
- Maximum batch count (Maximal zulässige Batchanzahl)
- Anzahl der parallelen Anfragen pro Partition.
Bestimmen Sie die richtige Batchgröße
Nachdem Sie Ihren Webdienst bereitgestellt haben, senden Sie eine Beispielanforderung mit verschiedenen Batchgrößen. Beginnen Sie dabei mit 50, und erhöhen Sie die Größe dann nach und nach auf mehrere Hundert. Beispielsweise 200, 500, 1000, 2000 und so weiter Sie werden feststellen, dass sich ab einer bestimmten Batchgröße die Latenz der Antwort verlängert. Der Punkt, ab dem sich die Latenz der Antwort verlängert, sollte die maximal zulässige Batchanzahl für Ihren Auftrag sein.
Bestimmen Sie die Anzahl paralleler Anforderungen pro Partition
Bei optimaler Skalierung sollte Ihr Stream Analytics-Auftrag mehrere Anforderungen gleichzeitig an Ihren Webdienst senden und innerhalb weniger Millisekunden eine Antwort erhalten können. Die Latenz der Antwort des Webdiensts kann sich direkt auf die Latenz und Leistung Ihres Stream Analytics-Auftrags auswirken. Wenn der Aufruf des Webdiensts aus Ihrem Auftrag lang dauert, werden Sie vermutlich eine längere Wasserzeichenverzögerung und möglicherweise auch eine höhere Anzahl von Eingabeereignissen im Rückstand feststellen.
Sie können eine geringe Latenz erreichen, indem Sie sicherstellen, dass Ihr AKS-Cluster (Azure Kubernetes Service) mit der richtigen Anzahl von Knoten und Replikaten bereitgestellt wurde. Es ist wichtig, dass Ihr Webdienst hochverfügbar ist und erfolgreiche Antworten zurückgibt. Wenn Ihre Aufgabe einen Fehler empfängt, der wiederholt werden kann, z. B. die Antwort „Dienst nicht verfügbar“ (503), wird der Vorgang automatisch mit exponentiellem Backoff (Rückzug) wiederholt. Wenn Ihr Auftrag einen dieser Fehler als Antwort vom Endpunkt empfängt, wird der Auftrag in einen fehlerhaften Zustand versetzt.
- Ungültige Anforderung (400)
- Konflikt (409)
- Nicht gefunden (404)
- Nicht autorisiert (401)
Begrenzungen
Wenn Sie einen Azure ML-verwalteten Endpunkt-Dienst verwenden, kann Stream Analytics derzeit nur auf Endpunkte zugreifen, die über einen aktivierten öffentlichen Netzwerkzugriff verfügen. Weitere Informationen hierzu finden Sie auf der Seite zu privaten Azure ML-Endpunkten.