Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie mit der ML.NET-CLI automatisch ein ML.NET-Modell und den zugrunde liegenden C#-Code generieren. Sie stellen Ihr Dataset und die Machine Learning-Tasks bereit, die Sie implementieren möchten. Die CLI verwendet die AutoML-Engine, um Quellcode für die Modellgenerierung und Bereitstellung sowie das Klassifizierungsmodell zu erstellen.
In diesem Tutorial führen Sie die folgenden Schritte durch:
- Vorbereiten der Daten für die ausgewählte Machine Learning-Aufgabe
- Ausführen des Befehls „mlnet classification“ über die CLI
- Überprüfen der Ergebnisse der Qualitätsmetriken
- Verstehen des generierten C#-Codes zur Verwendung des Modells in Ihrer Anwendung
- Untersuchen des generierten C#-Codes, der zum Trainieren des Modells verwendet wurde
Hinweis
Dieses Thema bezieht sich auf das ML.NET-CLI-Tools, was derzeit als Vorschau verfügbar ist, und das Material kann jederzeit geändert werden. Weitere Informationen finden Sie auf der Seite ML.NET.
Die ML.NET-CLI ist Teil von ML.NET und das Hauptziel ist es, ML.NET für .NET-Entwickler beim Erlernen von ML.NET zu „demokratisieren“, damit Sie den Code nicht von Grund auf neu schreiben müssen, um loszulegen.
Sie können die ML.NET-CLI über jede Eingabeaufforderung (Windows, Mac oder Linux) ausführen, um qualitativ hochwertige ML.NET-Modelle und Quellcode basierend auf den von Ihnen bereitgestellten Trainingsdatasets zu generieren.
Voraussetzungen
- .NET Core 6 SDK oder höher
- (Optional) Visual Studio
- ML.NET-CLI
Sie können die generierten C#-Codeprojekte entweder über Visual Studio oder mit dotnet run ausführen (.NET-CLI).
Vorbereiten Ihrer Daten
Wir werden ein vorhandenes Dataset verwenden, das für ein Szenario „Standpunktanalyse“ verwendet wird, bei dem es sich um eine Machine Learning-Aufgabe für die binäre Klassifizierung handelt. Sie können Ihr eigenes Dataset auf ähnliche Weise verwenden, und das Modell und der Code werden für Sie generiert.
Laden Sie die Dataset-ZIP-Datei „UCI Sentiment Labeled Sentences“ (siehe Zitate im folgenden Hinweis) herunter, und entzippen Sie sie in einem beliebigen Ordner Ihrer Wahl.
Hinweis
Die in diesem Tutorial verwendeten Datasets stammen aus „From Group to Individual Labels using Deep Features“, Kotzias et al,. KDD 2015, und werden im UCI Machine Learning Repository – Dua, D. und Karra Taniskidou, E. gehostet. (2017). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml ]. Irvine, CA: University of California, School of Information and Computer Science.
Kopieren Sie die
yelp_labelled.txt-Datei in einen vorher von Ihnen erstellten Ordner (wie z.B./cli-test).Öffnen Sie die von Ihnen bevorzugte Eingabeaufforderung, und wechseln Sie in den Ordner, in den Sie die Datasetdatei kopiert haben. Zum Beispiel:
cd /cli-testSie können die Datasetdatei
yelp_labelled.txtmit einem beliebigen Text-Editor wie beispielsweise Visual Studio Code öffnen und durchsuchen. Sie sehen folgende Struktur:Die Datei hat keinen Header. Sie verwenden den Index der Spalte.
Es gibt nur zwei Spalten:
Text (Spaltenindex 0) Bezeichnung (Spaltenindex 1) Toll... Mir hat das Restaurant gefallen. 1 Die Kruste ist nicht gut. 0 Sie hat nicht geschmeckt und die Textur wurde einfach unangenehm. 0 ... VIELE WEITERE TEXTZEILEN... ...(1 oder 0)...
Stellen Sie sicher, dass Sie die Datasetdatei über den Editor schließen.
Jetzt können Sie die CLI für das Szenario „Standpunktanalyse“ verwenden.
Hinweis
Nach Abschluss dieses Tutorials können Sie auch eigene Datasets ausprobieren, sofern sie für die ML-Tasks geeignet sind, die derzeit von der ML.NET-CLI-Vorschauversion unterstützt werden, d. h. „Binäre Klassifizierung“, „Klassifizierung“, „Regression“ und „Empfehlung“ .
Ausführen des Befehls „mlnet classification“
Führen Sie den folgenden ML.NET CLI-Befehl aus:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10Dieser Befehl führt den
mlnet classification-Befehl aus:- für den ML-Task der Klassifizierung
- verwendet die Datasetdatei
yelp_labelled.txtals Trainings- und Testdataset (intern verwendet die CLI entweder eine Kreuzvalidierung oder teilt sie in zwei Datasets, eine für das Training und eine für den Test) - wenn die Objekt-/Zielspalte, die Sie vorhersagen möchten (allgemein Bezeichnung genannt), die Spalte mit dem Index 1 ist (das ist die zweite Spalte, da der Index nullbasiert ist)
- verwendet keinen Dateiheader mit Spaltennamen, da diese spezielle Datasetdatei keinen Header hat
- die angestrebte Untersuchungs-/Trainingszeit für das Experiment beträgt 10 Sekunden
Die CLI-Ausgabe sieht in etwas so aus:
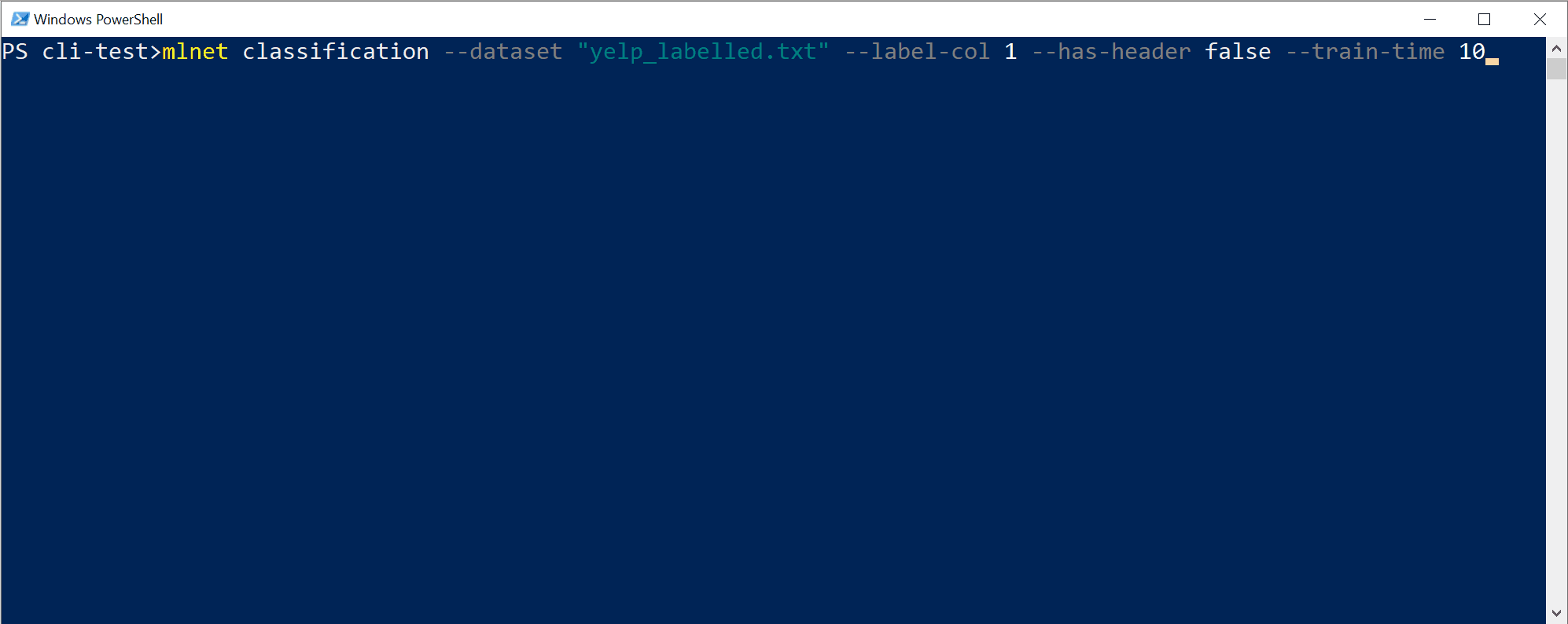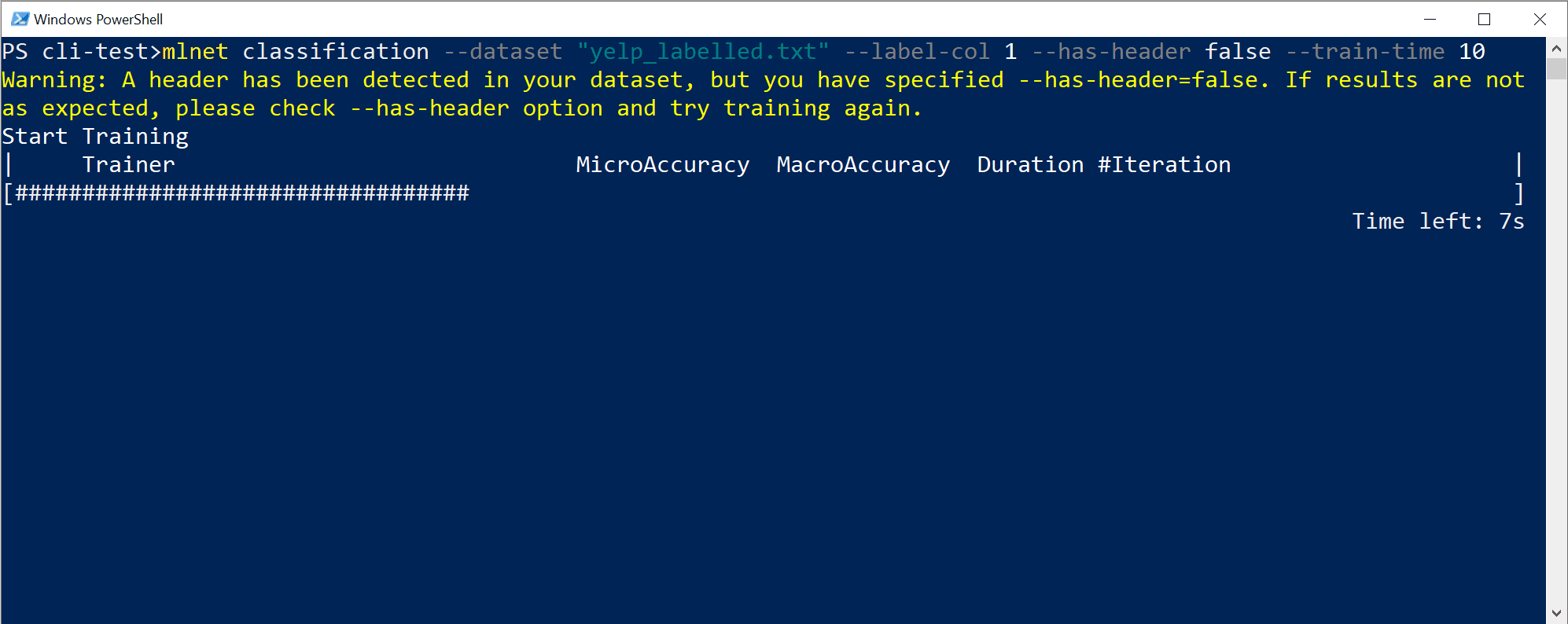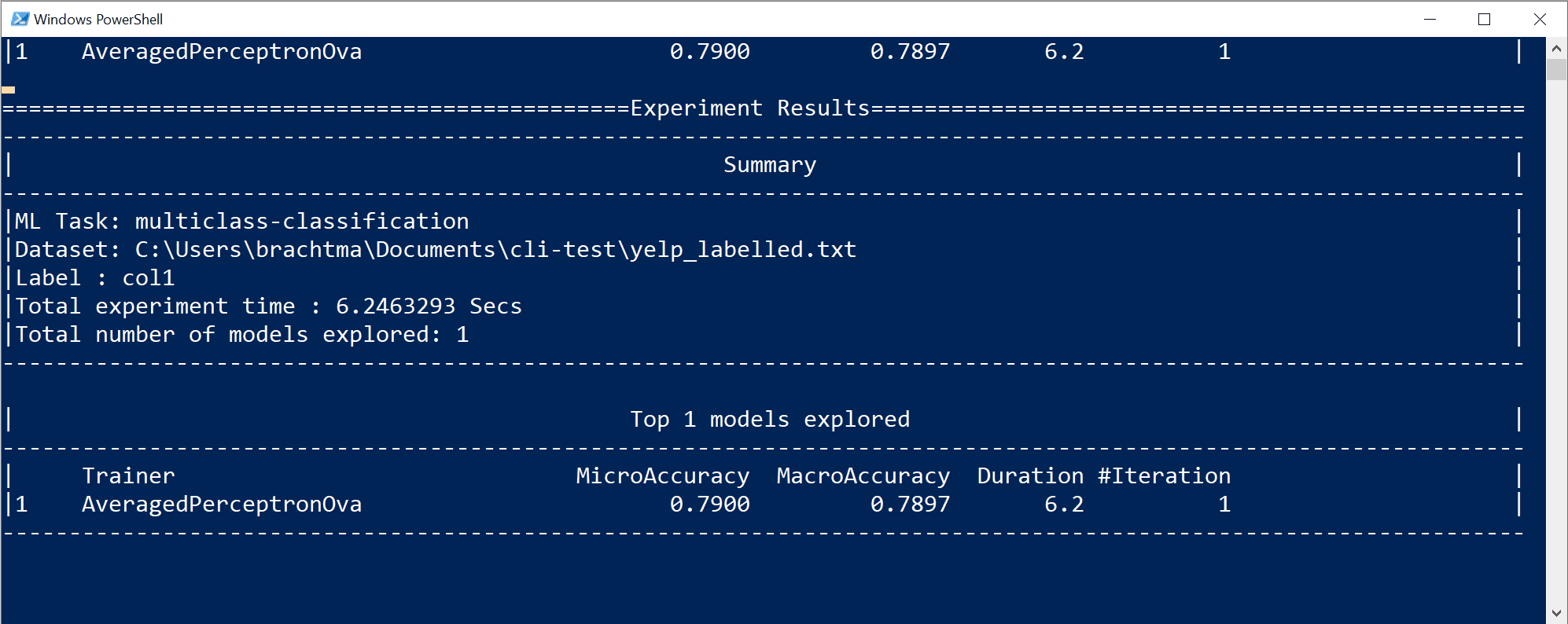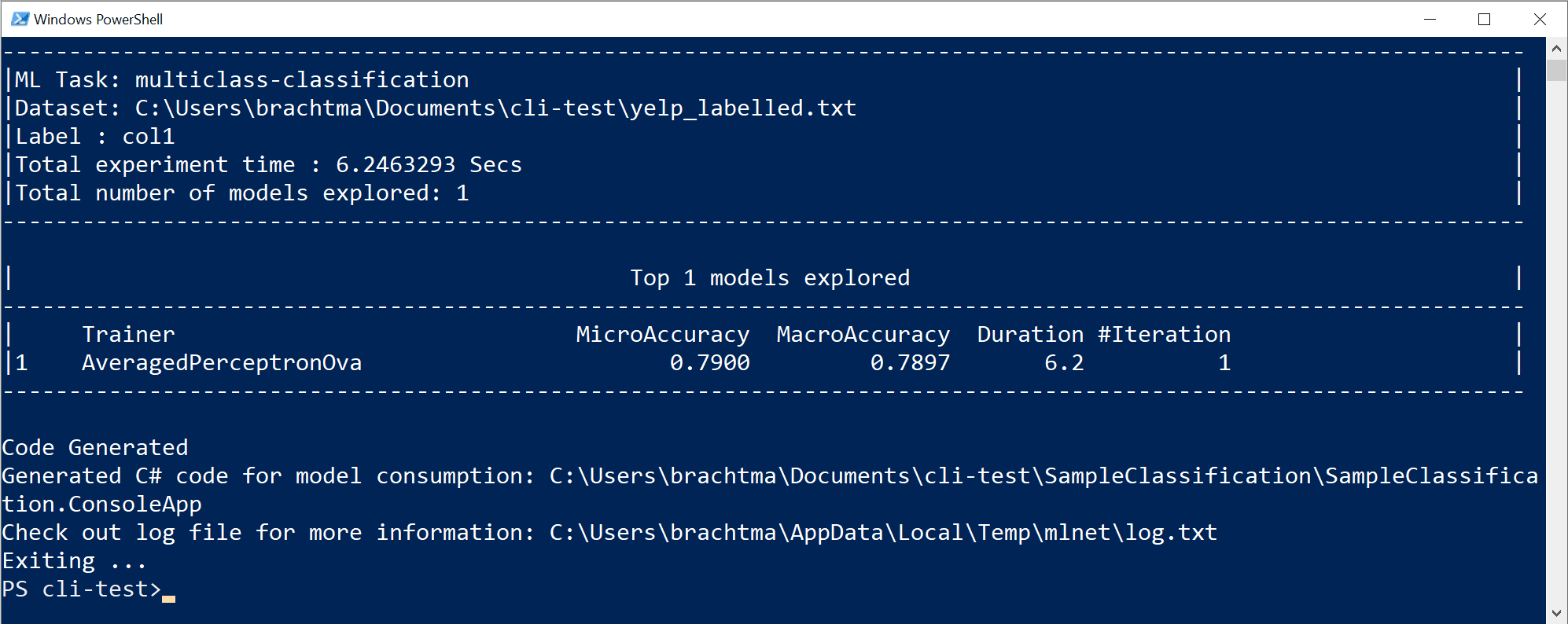
In diesem speziellen Fall konnte das CLI-Tool in nur 10 Sekunden und mit dem bereitgestellten kleinen Dataset eine ganze Reihe von Iterationen durchführen. Das bedeutet, dass das Training basierend auf verschiedenen Kombinationen von Algorithmen/Konfigurationen mit unterschiedlichen internen Datentransformationen und den Hyperparametern des Algorithmus mehrfach durchgeführt wurde.
Schließlich ist das „Modell mit der besten Qualität“, das in 10 Sekunden gefunden wurde, ein Modell, das einen bestimmten Trainer/Algorithmus mit einer bestimmten Konfiguration verwendet. Je nach Explorationszeit kann der Befehl ein anderes Ergebnis liefern. Die Auswahl basiert auf den zahlreichen dargestellten Metriken, wie z.B.
Accuracy.Verstehen der Qualitätsmetriken des Modells
Die erste und einfachste Metrik zur Bewertung eines binären Klassifikationsmodells ist die Genauigkeit. Diese Metrik ist einfach zu verstehen. „Die Genauigkeit ist der Anteil der korrekten Vorhersagen mit einem Testdataset.“ Je näher der Wert an 100 % (1,00) liegt, desto besser.
Es gibt jedoch Fälle, in denen das bloße Messen mit der Metrik „Accuracy“ nicht ausreicht, insbesondere wenn die Bezeichnung (in diesem Fall 0 und 1) im Testdataset unausgewogen ist.
Weitere Metriken und detailliertere Informationen zu den Metriken, etwa zu „Accuracy“. „AUC“, „AUCPR“ und „F1-score“, die zur Auswertung der verschiedenen Modelle verwendet werden, finden Sie unter Verstehen der ML.NET-Metriken.
Hinweis
Sie können genau dieses Dataset ausprobieren und für
--max-exploration-timeein paar Minuten angeben (z.B. für drei Minuten geben Sie 180 Sekunden an). Dadurch wird mit einer anderen Konfiguration der Trainingspipeline für dieses Dataset (das ziemlich klein ist, 1.000 Zeilen) ein besseres „bestes Modell“ für Sie ermittelt.Um für größere Datasets ein einsatzbereites Modell mit „bester/gute Qualität“ zu finden, sollten Sie mit der CLI experimentieren, wobei in der Regel je nach Größe des Datasets viel mehr Explorationszeit angegeben wird. In der Tat kann es in vielen Fällen vorkommen, dass Sie mehrere Stunden Explorationszeit benötigen, insbesondere wenn das Dataset viele Zeilen und Spalten enthält.
Durch die vorherige Befehlsausführung wurden die folgenden Objekte generiert:
- Eine serialisierte ZIP-Datei des Modells („bestes Modell“), die sofort verwendet werden kann.
- C#-Code, um das generierte Modell auszuführen/zu bewerten (um mit diesem Modell Vorhersagen in Ihren Endbenutzer-Apps zu treffen).
- C#-Trainingscode, der zur Erstellung dieses Modells verwendet wird (zu Lernzwecken).
- Eine Protokolldatei mit allen untersuchten Iterationen mit spezifischen Detailinformationen zu jedem Algorithmus, der mit seiner Kombination aus Hyperparametern und Datentransformationen getestet wurde.
Die ersten beiden Objekte (ZIP-Datei des Modells und der C#-Code zur Ausführung des Modells) können direkt in Ihren Endbenutzer-App (ASP.NET Core-Web-App, Dienste, Desktop-App usw.) verwendet werden, um mit dem generierten ML-Modell Vorhersagen zu treffen.
Das dritte Objekt, der Trainingscode, zeigt Ihnen, welchen ML.NET-API-Code die CLI zum Trainieren des generierten Modells verwendet hat, sodass Sie untersuchen können, welchen spezifischen Trainer/Algorithmus und Hyperparameter die CLI ausgewählt hat.
Die aufgezählten Objekte werden in den folgenden Schritten des Tutorials erläutert.
Erkunden des generierten C#-Codes, der für die Ausführung des Modells zum Treffen von Vorhersagen verwendet werden kann
Öffnen Sie in Visual Studio die Projektmappe, die in dem Ordner namens
SampleClassificationin Ihrem ursprünglichen Zielordner generiert wurde. (Im Tutorial wurde der Name/cli-testverwendet.) Die angezeigte Projektmappe sollte ungefähr so aussehen: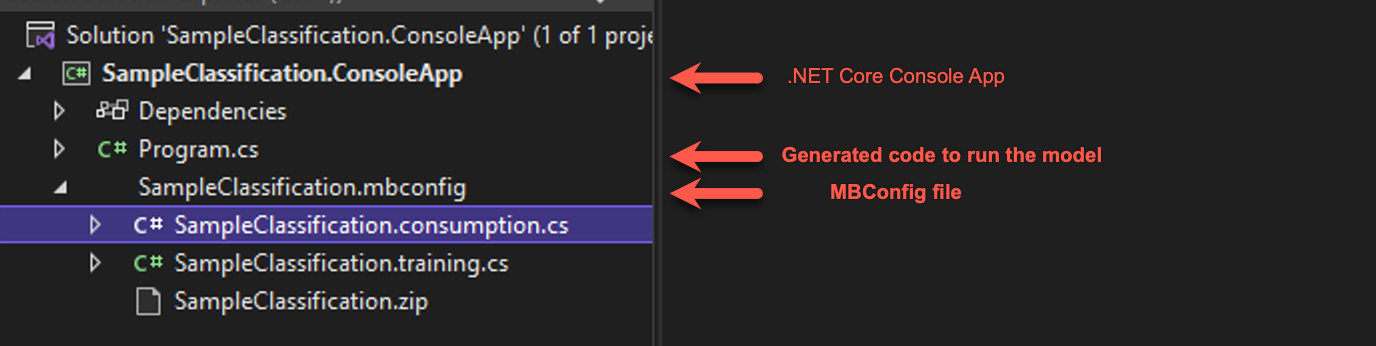
Hinweis
Im Tutorial empfehlen wir die Verwendung von Visual Studio. Sie können aber auch den generierten C#-Code (zwei Projekte) mit einem beliebigen Text-Editor untersuchen und die generierte Konsolen-App mit der
dotnet CLIauf MacOS-, Linux- oder Windows-Computern ausführen.- Die generierte Konsolen-App enthält Ausführungscode, den Sie überprüfen müssen. Dann wird der „Bewertungscode“ (Code, der das ML-Modell ausführt, um Vorhersagen zu treffen) in der Regel wiederverwendet, indem Sie diesen einfachen Code (nur ein paar Zeilen) in Ihre Endbenutzeranwendung verschieben, wo Sie die Vorhersagen machen möchten.
- Die generierte mbconfig-Datei ist eine Konfigurationsdatei, die zum erneuten Trainieren Ihres Modells verwendet werden kann, entweder über die CLI oder über Model Builder. Außerdem sind zwei Codedateien und eine ZIP-Datei zugeordnet.
- Die Trainingsdatei enthält den Code zum Erstellen der Modellpipeline mithilfe der ML.NET-API.
- Die Verbrauchsdatei enthält den Code zur Nutzung des Modells.
- Die ZIP-Datei enthält das von der CLI generierte Modell.
Öffnen Sie die Datei SampleClassification.consumption.cs innerhalb der mbconfig-Datei. Sie werden feststellen, dass Eingabe- und Ausgabeklassen vorhanden sind. Dies sind Datenklassen oder POCO-Klassen, die zum Speichern von Daten verwendet werden. Die Klassen enthalten Codebausteine, die nützlich sind, wenn Ihr Dataset Dutzende oder sogar Hunderte von Spalten enthält.
- Die
ModelInput-Klasse wird beim Auslesen von Daten aus dem Dataset verwendet. - Die
ModelOutput-Klasse wird verwendet, um das Vorhersageergebnis (Vorhersagedaten) abzurufen.
- Die
Öffnen Sie die Datei „Program.cs“, und untersuchen Sie den Code. Mit nur wenigen Zeilen können Sie das Modell ausführen und eine Beispielvorhersage treffen.
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }Die ersten Codezeilen erstellen einzelne Beispieldaten, die in diesem Fall auf der ersten Zeile Ihres Datasets basieren, das für die Vorhersage verwendet werden soll. Sie können auch eigene „hartcodierte“ Daten erstellen, indem Sie den Code aktualisieren:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };In der nächsten Codezeile wird die
SampleClassification.Predict()-Methode für die angegebenen Eingabedaten verwendet, um eine Vorhersage zu treffen und die Ergebnisse (basierend auf dem ModelOutput.cs-Schema) zurückzugeben.In den letzten Codezeilen werden die Eigenschaften der Beispieldaten (in diesem Fall der Kommentar) sowie die Stimmungsvorhersage und die entsprechenden Ergebnisse für positive Stimmungen (1) und negative Stimmungen (2) ausgegeben.
Führen Sie das Projekt entweder mit den ursprünglichen Beispieldaten aus der ersten Zeile des Datasets oder mit Ihren eigenen, hartcodierten Beispieldaten aus. Die Vorhersage sollte ungefähr so aussehen:
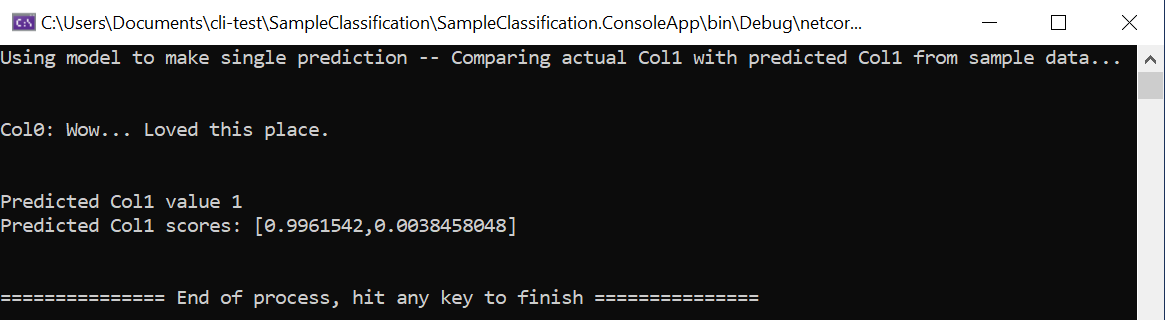
- Versuchen Sie, die hartcodierten Beispieldaten in andere Sätze mit verschiedenen Standpunkten zu ändern, und schauen Sie sich an, wie das Modell positive oder negative Standpunkte vorhersagt.
Ergänzen Ihrer Endbenutzeranwendungen mit ML-Modellvorhersagen
Sie können einen ähnlichen „Bewertungscode für das ML-Modell“ verwenden, um das Modell in Ihrer Endbenutzeranwendung auszuführen und Vorhersagen zu treffen.
Beispielsweise können Sie diesen Code direkt in eine beliebige Windows-Desktop-Anwendung wie WPF und WinForms verschieben und das Modell auf die gleiche Weise ausführen wie in der Konsolen-App.
Die Art und Weise, wie Sie diese Codezeilen zur Ausführung des ML-Modells implementieren, sollte jedoch optimiert werden (d.h. die ZIP-Datei des Modells zwischenspeichern und einmal laden) und Sie sollten Singleton-Objekte verwenden, anstatt sie bei jeder Anforderung zu erstellen, insbesondere wenn Ihre Anwendung skalierbar sein muss, wie beispielsweise eine Webanwendung oder ein verteilter Dienst, wie im folgenden Abschnitt erläutert.
Ausführen von ML.NET Modellen in skalierbaren ASP.NET Core-Web-Apps und -Diensten (Multithread-Apps)
Die Erstellung des Modellobjekts (ITransformer, das aus der ZIP-Datei eines Modells geladen wurde) und des PredictionEngine-Objekts sollte optimiert werden, insbesondere bei der Ausführung auf skalierbaren Web-Apps und verteilten Diensten. Für den ersten Fall, das Modellobjekt (ITransformer), ist die Optimierung einfach. Da das ITransformer-Objekt threadsicher ist, können Sie das Objekt als Singleton-Objekt oder statisches Objekt zwischenspeichern und das Modell einmal laden.
Für das zweite Objekt, das PredictionEngine-Objekt, ist es nicht so einfach, da das PredictionEngine-Objekt nicht threadsicher ist. Daher können Sie dieses Objekt nicht als Singleton- oder statisches Objekt in einer ASP.NET Core-App instanziieren. Dieses Problem der Threadsicherheit und Skalierbarkeit wird in diesem Blogbeitrag ausführlich behandelt.
Allerdings ist die Praxis für Sie heute wesentlich einfacher, als in diesem Blogbeitrag beschrieben. Wir haben für Sie einen einfacheren Ansatz erarbeitet und ein praktisches .NET Core-Integrationspaket erstellt, das Sie problemlos in Ihren ASP.NET Core-Apps und -Diensten verwenden können, indem Sie es in den DI-Diensten (Dependency Injection Services) der Anwendung registrieren und dann direkt über Ihren Code verwenden. Schauen Sie sich dafür das folgende Tutorial und Beispiel an:
- Tutorial: Ausführen von ML.NET-Modellen auf skalierbaren ASP.NET Core-Web-Apps und -Web-APIs
- Beispiel: Skalierbares ML.NET-Modell auf ASP.NET Core-Web-API
Untersuchen des generierten C#-Codes, der zum Trainieren des „Modell mit der besten Qualität“ verwendet wurde
Für weiterführende Lernzwecke können Sie auch den generierten C#-Code untersuchen, der vom CLI-Tool zum Trainieren des generierten Modells verwendet wurde.
Dieser Trainingsmodellcode wird in der Datei SampleClassification.training.cs generiert, sodass Sie diesen Trainingscode untersuchen können.
Noch wichtiger ist, dass Sie diesen generierten Trainingscode in diesem speziellen Szenario (Modell zur Standpunktanalyse) auch mit dem im folgenden Tutorial beschriebenen Code vergleichen können:
- Vergleich: Tutorial: Verwenden von ML.NET in einem Standpunktanalyse-Szenario mit binärer Klassifizierung.
Es ist interessant, den gewählten Algorithmus und die Pipelinekonfiguration im Tutorial mit dem vom CLI-Tool generierten Code zu vergleichen. Je nachdem, wie viel Zeit Sie mit der Iteration und der Suche nach besseren Modellen verbringen, können der ausgewählte Algorithmus, die jeweiligen Hyperparametern und die Pipelinekonfiguration jeweils unterschiedlich sein.
In diesem Tutorial haben Sie gelernt, wie die folgenden Aufgaben ausgeführt werden:
- Vorbereiten der Daten für die ausgewählte ML-Aufgabe (zu lösendes Problem)
- Ausführen des Befehls „mlnet classification“ über das CLI-Tool
- Überprüfen der Ergebnisse der Qualitätsmetriken
- Verstehen des generierten C#-Codes zur Ausführung des Modells (Code zur Verwendung in Ihrer Endbenutzer-App)
- Untersuchen des generierten C#-Codes, der zum Trainieren des Modells mit der besten Qualität verwendet wurde (zu Lernzwecken)
Siehe auch
- Automatisieren des Modelltrainings mit der ML.NET-CLI
- Tutorial: Ausführen von ML.NET-Modellen auf skalierbaren ASP.NET Core-Web-Apps und -Web-APIs
- Beispiel: Skalierbares ML.NET-Modell auf ASP.NET Core-Web-API
- Referenzhandbuch für den „auto-train“-Befehl in der ML.NET-CLI
- Telemetrie in der ML.NET-CLI
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.