Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Mit dem T-SQL-Notebookfeature in Microsoft Fabric können Sie T-SQL-Code in einem Notebook schreiben und ausführen. Sie können T-SQL-Notebooks verwenden, um komplexe Abfragen zu verwalten und eine bessere Markdowndokumentation zu schreiben. Außerdem ermöglichen sie die direkte Ausführung von T-SQL im verbundenen Warehouse oder SQL-Analyseendpunkt. Durch Hinzufügen eines Data Warehouse oder SQL-Analyseendpunkts zu einem Notebook können T-SQL-Entwickler Abfragen direkt auf dem verbundenen Endpunkt ausführen. BI-Analysten können außerdem datenbankübergreifende Abfragen durchführen, um Erkenntnisse aus mehreren Warehouses und SQL-Analyseendpunkten zu sammeln.
Die meisten vorhandenen Notebookfunktionen sind für T-SQL-Notebooks verfügbar. Dazu gehören das Darstellen von Abfrageergebnissen in Diagrammen, Notebooks für die gemeinsame Dokumenterstellung, Planen regelmäßiger Ausführungen und Auslösen der Ausführung in Datenintegrationspipelines.
In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Erstellen eines T-SQL-Notebooks
- Hinzufügen eines Data Warehouse oder SQL-Analyseendpunkts zu einem Notebook
- Erstellen und Ausführen von T-SQL-Code in einem Notebook
- Verwenden der Diagrammfeatures zum grafischen Darstellen von Abfrageergebnissen
- Speichern der Abfrage als Sicht oder Tabelle
- Ausführen von warehouseübergreifenden Abfragen
- Überspringen der Ausführung von Nicht-T-SQL-Code
Erstellen eines T-SQL-Notebooks
Um mit dieser Erfahrung zu beginnen, können Sie ein T-SQL-Notizbuch auf folgende Weise erstellen:
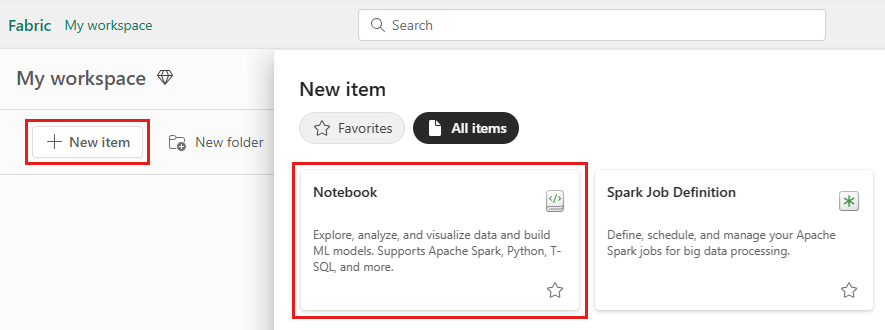
Erstellen Sie ein T-SQL-Notizbuch aus dem Fabric-Arbeitsbereich: Wählen Sie Neues Elementaus, und wählen Sie dann Notizbuch- aus dem daraufhin geöffneten Bereich aus.
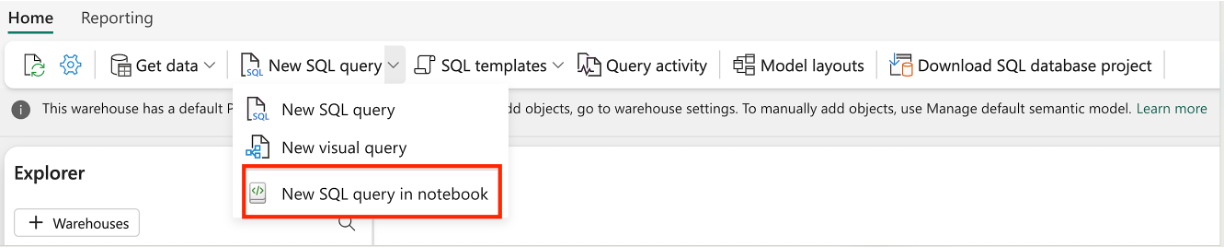
Erstellen Sie ein T-SQL-Notizbuch aus einem vorhandenen Lager-Editor: Navigieren Sie zu einem vorhandenen Lagerhaus, und wählen Sie im oberen Navigationsmenüband Neue SQL-Abfrageaus, und Neues T-SQL-Abfragenotizbuch.


Nachdem das Notebook erstellt wurde, wird T-SQL als Standardsprache festgelegt. Sie können Data Warehouses oder SQL-Analyseendpunkte aus dem aktuellen Arbeitsbereich zu Ihrem Notebook hinzufügen.
Hinzufügen eines Data Warehouse oder SQL-Analyseendpunkts zu einem Notebook
Wenn Sie einem Notebook ein Data Warehouse oder einen SQL-Analyseendpunkt hinzufügen möchten, wählen Sie im Notebook-Editor die Schaltfläche + Datenquellen und dann Warehouses aus. Wählen Sie im Bereich data-hub das Data Warehouse oder den SQL-Analyseendpunkt aus, mit dem Sie eine Verbindung herstellen möchten.

Festlegen eines primären Warehouse
Sie können dem Notebook mehrere Warehouses oder SQL-Analyseendpunkte hinzufügen, wobei einer davon als primär festgelegt ist. Das primäre Warehouse führt den T-SQL-Code aus. Wechseln Sie zum Festlegen zum Objekt-Explorer, wählen Sie ... neben dem Warehouse aus, und wählen Sie Als primär festlegen aus.

Für jeden T-SQL-Befehl, der die dreiteilige Benennung unterstützt, wird das primäre Warehouse als Standardwarehouse verwendet, wenn kein Warehouse angegeben wird.
Erstellen und Ausführen von T-SQL-Code in einem Notebook
Um T-SQL-Code in einem Notebook zu erstellen und auszuführen, fügen Sie eine neue Zelle hinzu, und legen Sie T-SQL als Zellsprache fest.

Sie können T-SQL-Code automatisch mithilfe der Codevorlage aus dem Kontextmenü des Objekt-Explorers generieren. Die folgenden Vorlagen sind für T-SQL-Notebooks verfügbar:
- Top 100 auswählen
- Tabelle erstellen
- Als Auswahl erstellen
- Verwerfen
- DROP und CREATE

Sie können eine T-SQL-Codezelle ausführen, indem Sie die Schaltfläche Ausführen in der Zellensymbolleiste auswählen, oder Sie können alle Zellen ausführen, indem Sie die Schaltfläche Alle ausführen auf der Symbolleiste auswählen.
Hinweis
Jede Codezelle wird in einer separaten Sitzung ausgeführt, sodass die in einer Zelle definierten Variablen in einer anderen Zelle nicht verfügbar sind.
Innerhalb derselben Codezelle können mehrere Codezeilen enthalten sein. Der Benutzer kann einen Teil dieses Codes auswählen und nur die ausgewählten Elemente ausführen. Jede Ausführung generiert ebenfalls eine neue Sitzung.

Erweitern Sie nach dem Ausführen des Codes den Meldungsbereich, um die Ausführungszusammenfassung zu überprüfen.

Auf der Registerkarte Tabelle werden die Datensätze aus dem zurückgegebenen Resultset aufgeführt. Wenn die Ausführung mehrere Resultsets enthält, können Sie über das Dropdownmenü von einem zu einem anderen wechseln.

Verwenden der Diagrammfeatures zum grafischen Darstellen von Abfrageergebnissen
Durch Klicken auf Überprüfen können Sie die Diagramme sehen, die die Datenqualität und -verteilung jeder Spalte darstellen.

Speichern der Abfrage als Sicht oder Tabelle
Sie können das Menü Als Tabelle speichern verwenden, um die Ergebnisse der Abfrage mithilfe des CTAS-Befehls in einer Tabelle zu speichern. Um dieses Menü zu verwenden, wählen Sie den Abfragetext in der Codezelle aus, und wählen Sie das Menü Als Tabelle speichern aus.


Ebenso können Sie eine Ansicht aus dem ausgewählten Abfragetext erstellen, indem Sie das Menü Als Ansicht speichern in der Zellenbefehlsleiste verwenden.


Hinweis
Da die Menüs Als Tabelle speichern und Als Ansicht speichern nur für den ausgewählten Abfragetext verfügbar sind, müssen Sie den Abfragetext auswählen, bevor Sie diese Menüs verwenden.
„Ansicht erstellen“ unterstützt keine dreiteilige Benennung, sodass die Sicht immer im primären Warehouse erstellt wird, indem das Warehouse als primäres Warehouse festgelegt wird.
Warehouseübergreifende Abfrage
Sie können eine warehouseübergreifende Abfrage ausführen, indem Sie dreiteilige Benennungen verwenden. Die dreiteilige Benennung besteht aus dem Datenbanknamen, dem Schemanamen und dem Tabellennamen. Der Datenbankname ist der Name des Warehouse oder SQL-Analyseendpunkts, der Schemaname ist der Name des Schemas, und der Tabellenname ist der Name der Tabelle.

Überspringen der Ausführung von Nicht-T-SQL-Code
Innerhalb desselben Notebooks können Codezellen erstellt werden, die unterschiedliche Sprachen verwenden. Beispielsweise kann eine PySpark-Codezelle einer T-SQL-Codezelle vorausgehen. In diesem Fall kann der Benutzer die Ausführung von PySpark-Code für das T-SQL-Notebook überspringen. Dieses Dialogfeld wird angezeigt, wenn Sie alle Codezellen ausführen, indem Sie auf die Schaltfläche Alle ausführen auf der Symbolleiste klicken.

Überwachen der T-SQL-Notizbuchausführung
Sie können die Ausführung von T-SQL-Notizbüchern auf der Registerkarte "T-SQL " der Ansicht "Zuletzt verwendete Ausführung" überwachen. Sie können die Ansicht 'Letzte Ausführung' finden, indem Sie innerhalb des Notizbuchs das Ausführen-Menü auswählen.

In der T-SQL-Verlaufsausführungsansicht können Sie eine Liste der ausgeführten, erfolgreichen, abgebrochenen und fehlgeschlagenen Abfragen bis zu den letzten 30 Tagen anzeigen.
- Verwenden Sie die Dropdownliste, um nach Status- oder Sendezeit zu filtern.
- Verwenden Sie die Suchleiste, um nach bestimmten Schlüsselwörtern im Abfragetext oder anderen Spalten zu filtern.
Für jede Abfrage werden die folgenden Details bereitgestellt:
| Spaltenname | BESCHREIBUNG |
|---|---|
| Verteilte Anweisungs-ID | Eindeutige ID für jede Abfrage |
| Abfragetext | Text der ausgeführten Abfrage (bis zu 8.000 Zeichen) |
| Sendezeit (UTC) | Zeitstempel, wenn die Anforderung eingetroffen ist |
| Dauer | Zeitaufwand für die Ausführung der Abfrage |
| Status | Abfragestatus (Ausgeführt, erfolgreich, fehlgeschlagen oder abgebrochen) |
| Absender | Name des Benutzers oder Systems, der die Abfrage gesendet hat |
| Sitzungs-ID | ID, die die Abfrage mit einer bestimmten Benutzersitzung verknüpft |
| Standardlager | Name des Lagers, das die übermittelte Abfrage akzeptiert |
Historische Abfragen können bis zu 15 Minuten dauern, bis sie in der Liste angezeigt werden, abhängig von der gleichzeitigen Arbeitsauslastung, die ausgeführt wird.
Aktuelle Einschränkungen
- Die Parameterzelle wird im T-SQL-Notebook noch nicht unterstützt. Der Parameter, der von der Pipeline oder vom Scheduler übergeben wird, kann nicht im T-SQL-Notebook verwendet werden.
- Die Überwachungs-URL in der Pipelineausführung wird im T-SQL-Notebook noch nicht unterstützt.
- Die Momentaufnahmefunktion wird im T-SQL-Notebook noch nicht unterstützt.
Zugehöriger Inhalt
Weitere Informationen zu Fabric-Notebooks finden Sie in den folgenden Artikeln.
- Was ist Data Warehouse in Microsoft Fabric?
- Fragen? Versuchen Sie, die Fabric-Community zu fragen.
- Vorschläge? Tragen Sie Ideen bei, um Fabric zu verbessern.