Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Gilt für:✅ Datentechnik und Data Science in Microsoft Fabric
Erfahren Sie, wie Sie Spark-Sitzungsaufträge mit der Livy-API für Fabric Data Engineering übermitteln.
Voraussetzungen
Fabric Premium- oder Testkapazität mit einem Lakehouse
Ein Remoteclient wie Visual Studio Code mit Jupyter-Notizbüchern, PySpark und der Microsoft Authentication Library (MSAL) für Python
Entweder ein Microsoft Entra-App-Token. Registrieren einer Anwendung bei Microsoft Identity Platform
Oder ein Microsoft Entra SPN-Token. Hinzufügen und Verwalten von Anwendungsanmeldeinformationen in Microsoft Entra
Einige Daten in Ihrem Lakehouse. Dieses Beispiel verwendet NYC Taxi & Limousine Commission (Parquet-Datei „green_tripdata_2022_08“, die in Lakehouse geladen wurde)
Die Livy-API definiert einen einheitlichen Endpunkt für Vorgänge. Ersetzen Sie die Platzhalter {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}, {Fabric_LakehouseID} durch die entsprechenden Werte, wenn Sie den Beispielen in diesem Artikel folgen.
Konfigurieren von Visual Studio Code für Ihre Livy-API-Sitzung
Wählen Sie Lakehouse-Einstellungen in Ihrem Fabric Lakehouse aus.

Navigieren Sie zum Abschnitt Livy-Endpunkt.
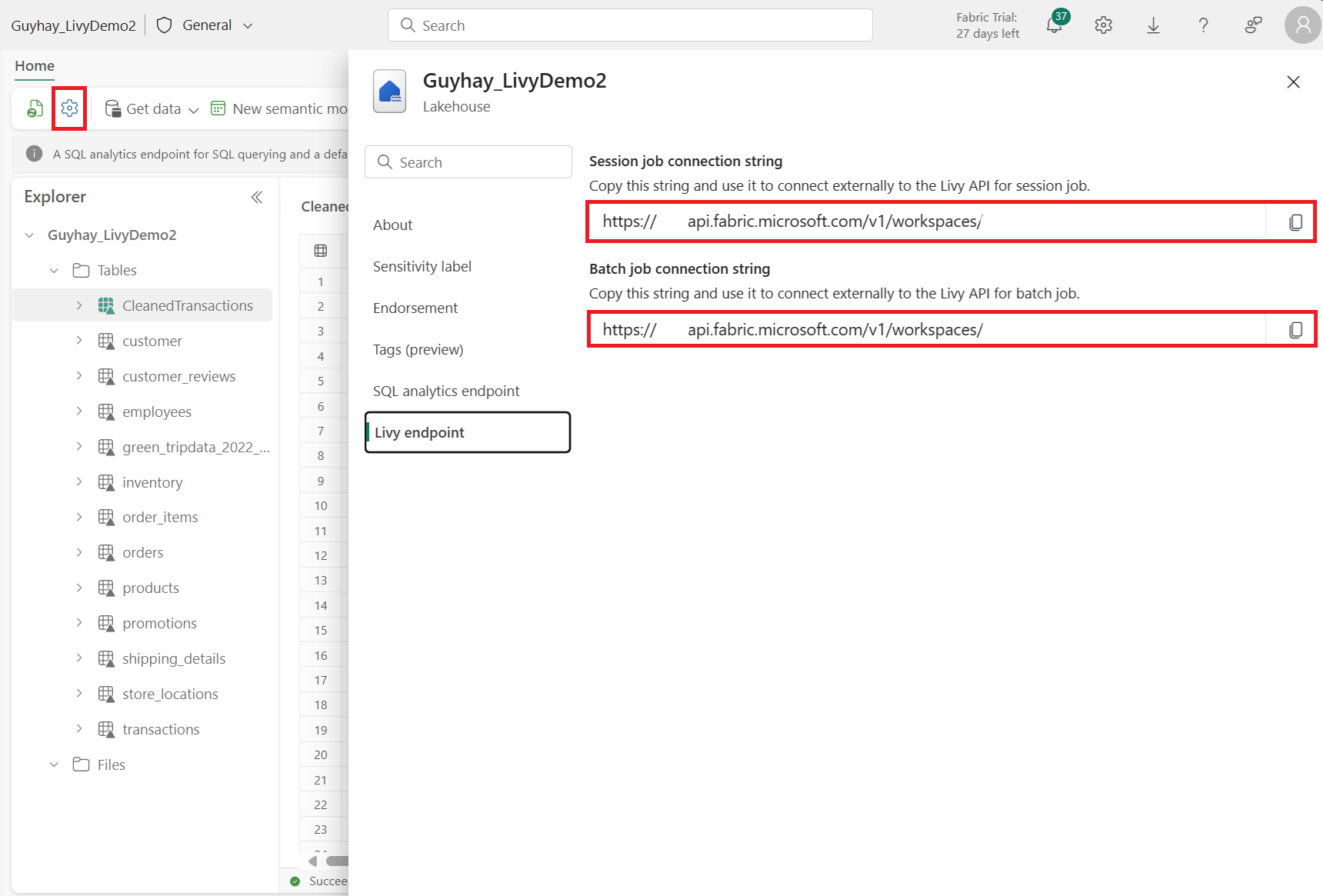
Kopieren Sie die Verbindungszeichenfolge des Sitzungsauftrags (erstes rotes Feld im Bild) in Ihren Code.
Navigieren Sie zum Microsoft Entra Admin Center, und kopieren Sie sowohl die Anwendungs-ID (Client-ID) als auch die Verzeichnis-ID (Mandant) in Ihren Code.
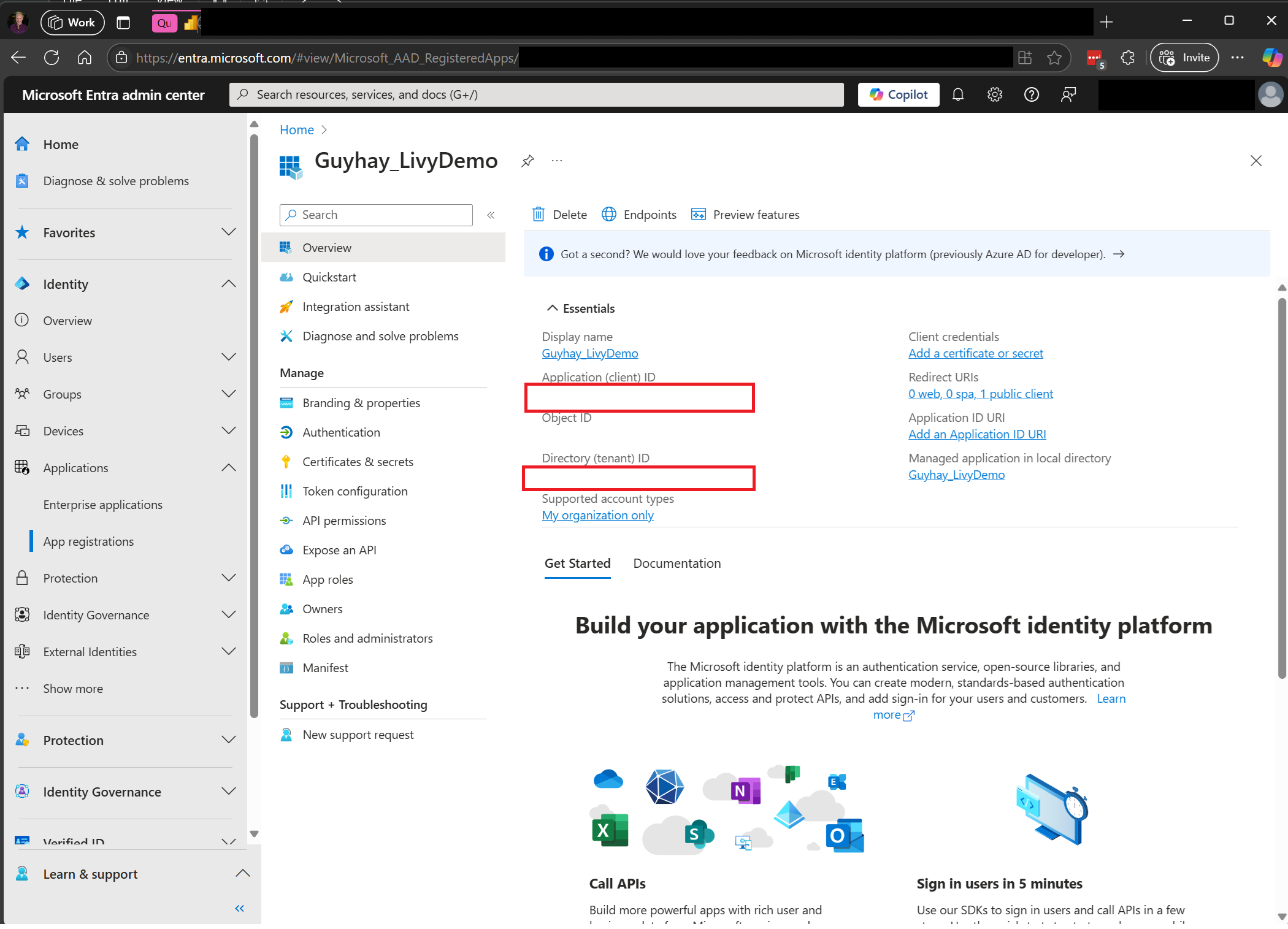



Authentifizieren einer Livy-API Spark-Sitzung mit einem Microsoft Entra-Benutzertoken oder einem Microsoft Entra SPN-Token
Authentifizieren einer Livy-API Spark-Sitzung mit einem Microsoft Entra SPN-Token
Erstellen Sie ein
.ipynb-Notizbuch in Visual Studio Code, und fügen Sie den folgenden Code ein.import sys from msal import ConfidentialClientApplication # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Service Principal Application ID # Certificate paths - Update these paths to your certificate files certificate_path = "PATH_TO_YOUR_CERTIFICATE.pem" # Public certificate file private_key_path = "PATH_TO_YOUR_PRIVATE_KEY.pem" # Private key file certificate_thumbprint = "YOUR_CERTIFICATE_THUMBPRINT" # Certificate thumbprint # OAuth settings audience = "https://analysis.windows.net/powerbi/api/.default" authority = f"https://login.windows.net/{tenant_id}" def get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint=None): """ Get an app-only access token for a Service Principal using OAuth 2.0 client credentials flow. This function uses certificate-based authentication which is more secure than client secrets. Args: client_id (str): The Service Principal's client ID audience (str): The audience for the token (resource scope) authority (str): The OAuth authority URL certificate_path (str): Path to the certificate file (.pem format) private_key_path (str): Path to the private key file (.pem format) certificate_thumbprint (str): Certificate thumbprint (optional but recommended) Returns: str: The access token for API authentication Raises: Exception: If token acquisition fails """ try: # Read the certificate from PEM file with open(certificate_path, "r", encoding="utf-8") as f: certificate_pem = f.read() # Read the private key from PEM file with open(private_key_path, "r", encoding="utf-8") as f: private_key_pem = f.read() # Create the confidential client application app = ConfidentialClientApplication( client_id=client_id, authority=authority, client_credential={ "private_key": private_key_pem, "thumbprint": certificate_thumbprint, "certificate": certificate_pem } ) # Acquire token using client credentials flow token_response = app.acquire_token_for_client(scopes=[audience]) if "access_token" in token_response: print("Successfully acquired access token") return token_response["access_token"] else: raise Exception(f"Failed to retrieve token: {token_response.get('error_description', 'Unknown error')}") except FileNotFoundError as e: print(f"Certificate file not found: {e}") sys.exit(1) except Exception as e: print(f"Error retrieving token: {e}", file=sys.stderr) sys.exit(1) # Get the access token token = get_access_token(client_id, audience, authority, certificate_path, private_key_path, certificate_thumbprint)Führen Sie die Notebook-Zelle aus. Sie sollten sehen, dass das Microsoft Entra-Token zurückgegeben wird.


Authentifizieren einer Livy-API Spark-Sitzung mit einem Microsoft Entra-Benutzertoken
Erstellen Sie ein
.ipynb-Notizbuch in Visual Studio Code, und fügen Sie den folgenden Code ein.from msal import PublicClientApplication import requests import time # Configuration - Replace with your actual values tenant_id = "Entra_TenantID" # Microsoft Entra tenant ID client_id = "Entra_ClientID" # Application ID (can be the same as above or different) # Required scopes for Microsoft Fabric API access scopes = [ "https://api.fabric.microsoft.com/Lakehouse.Execute.All", # Execute operations in lakehouses "https://api.fabric.microsoft.com/Lakehouse.Read.All", # Read lakehouse metadata "https://api.fabric.microsoft.com/Item.ReadWrite.All", # Read/write fabric items "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", # Access workspace operations "https://api.fabric.microsoft.com/Code.AccessStorage.All", # Access storage from code "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", # Access Azure Key Vault "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", # Access Azure Data Explorer "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", # Access Azure Data Lake "https://api.fabric.microsoft.com/Code.AccessFabric.All" # General Fabric access ] def get_access_token(tenant_id, client_id, scopes): """ Get an access token using interactive authentication. This method will open a browser window for user authentication. Args: tenant_id (str): The Microsoft Entra tenant ID client_id (str): The application client ID scopes (list): List of required permission scopes Returns: str: The access token, or None if authentication fails """ app = PublicClientApplication( client_id, authority=f"https://login.microsoftonline.com/{tenant_id}" ) print("Opening browser for interactive authentication...") token_response = app.acquire_token_interactive(scopes=scopes) if "access_token" in token_response: print("Successfully authenticated") return token_response["access_token"] else: print(f"Authentication failed: {token_response.get('error_description', 'Unknown error')}") return None # Uncomment the lines below to use interactive authentication token = get_access_token(tenant_id, client_id, scopes) print("Access token acquired via interactive login")Führen Sie die Notizbuchzelle aus. Das Microsoft Entra-Token sollte zurückgegeben werden.

Erstellen einer Livy-API Spark-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
import json import requests api_base_url = "https://api.fabric.microsoft.com/" # Base URL for Fabric APIs # Fabric Resource IDs - Replace with your workspace and lakehouse IDs workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" # Construct the Livy API session URL # URL pattern: {base_url}/v1/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/livyapi/versions/{api_version}/sessions livy_api_session_url = (f"{api_base_url}v1/workspaces/{workspace_id}/lakehouses/{lakehouse_id}/" f"livyapi/versions/2023-12-01/sessions") # Set up authentication headers headers = {"Authorization": f"Bearer {token}"} print(f"Livy API URL: {livy_api_session_url}") print("Creating Livy session...") try: # Create a new Livy session with default configuration create_livy_session = requests.post(livy_api_session_url, headers=headers, json={}) # Check if the request was successful if create_livy_session.status_code == 200: session_info = create_livy_session.json() print('Livy session creation request submitted successfully') print(f'Session Info: {json.dumps(session_info, indent=2)}') # Extract session ID for future operations livy_session_id = session_info['id'] livy_session_url = f"{livy_api_session_url}/{livy_session_id}" print(f"Session ID: {livy_session_id}") print(f"Session URL: {livy_session_url}") else: print(f"Failed to create session. Status code: {create_livy_session.status_code}") print(f"Response: {create_livy_session.text}") except requests.exceptions.RequestException as e: print(f"Network error occurred: {e}") except json.JSONDecodeError as e: print(f"JSON decode error: {e}") print(f"Response text: {create_livy_session.text}") except Exception as e: print(f"Unexpected error: {e}")Führen Sie die Notebook-Zelle aus. Eine Zeile sollte ausgegeben werden, wenn die Livy-Sitzung erstellt wird.

Sie können überprüfen, ob die Livy-Sitzung erstellt wird, indem Sie die [Anzeigen Ihrer Aufträge im Monitoring Hub](#Anzeigen Ihrer Aufträge im Monitoring Hub) verwenden.

Integration in Fabric-Umgebungen
Diese Livy-API-Sitzung wird standardmäßig für den Standardstartpool für den Arbeitsbereich ausgeführt. Alternativ können Sie Fabric-Umgebungen zum Erstellen, Konfigurieren und Verwenden einer Umgebung in Microsoft Fabric verwenden, um den Spark-Pool anzupassen, den die Livy-API-Sitzung für diese Spark-Aufträge verwendet. Um eine Fabric-Umgebung zu verwenden, aktualisieren Sie die vorherige Notizbuchzelle mit diesem JSON-Payload.
create_livy_session = requests.post(livy_base_url, headers = headers, json = {
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
Übermitteln einer spark.sql-Anweisung mithilfe der Livy-API-Spark-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
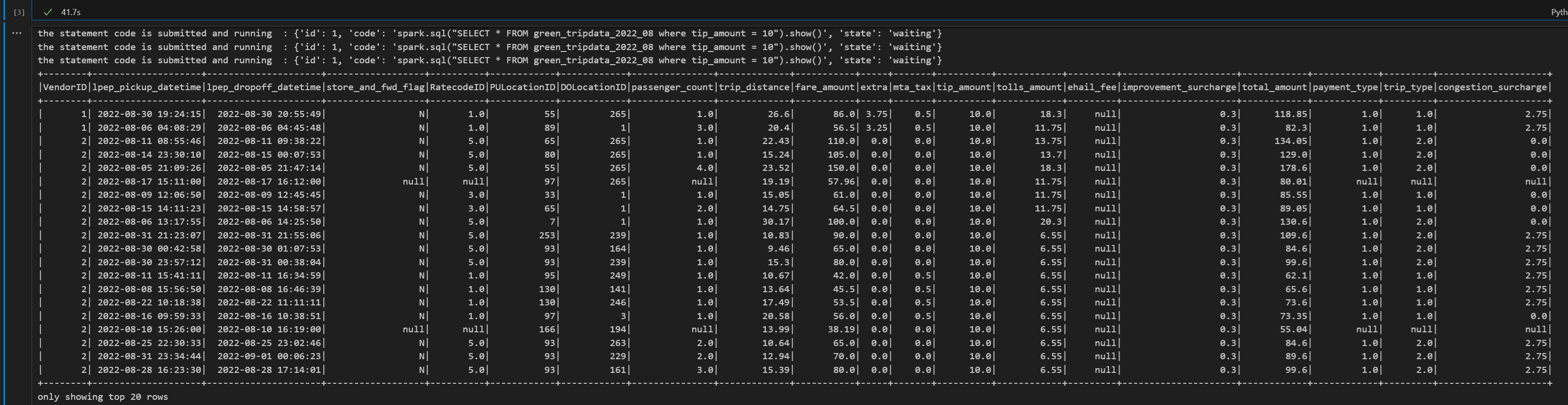
# call get session API import time table_name = "green_tripdata_2022" print("Checking session status...") # Get current session status get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() print(f"Current session state: {session_status['state']}") # Wait for session to become idle (ready to accept statements) print("Waiting for session to become idle...") while session_status["state"] != "idle": print(f" Session state: {session_status['state']} - waiting 5 seconds...") time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() print("Session is now idle and ready to accept statements") # Execute a Spark SQL statement execute_statement_url = f"{livy_session_url}/statements" # Define your Spark SQL query - Replace with your actual table and query payload_data = { "code": "spark.sql(\"SELECT * FROM {table_name} WHERE column_name = 'some_value' LIMIT 10\").show()", "kind": "spark" # Type of code (spark, pyspark, sql, etc.) } print("Submitting Spark SQL statement...") print(f"Query: {payload_data['code']}") try: # Submit the statement for execution execute_statement_response = requests.post(execute_statement_url, headers=headers, json=payload_data) if execute_statement_response.status_code == 200: statement_info = execute_statement_response.json() print('Statement submitted successfully') print(f"Statement Info: {json.dumps(statement_info, indent=2)}") # Get statement ID for monitoring statement_id = str(statement_info['id']) get_statement_url = f"{livy_session_url}/statements/{statement_id}" print(f"Statement ID: {statement_id}") # Monitor statement execution print("Monitoring statement execution...") get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() while statement_status["state"] != "available": print(f" Statement state: {statement_status['state']} - waiting 5 seconds...") time.sleep(5) get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() # Retrieve and display results print("Statement execution completed!") if 'output' in statement_status and 'data' in statement_status['output']: results = statement_status['output']['data']['text/plain'] print("Query Results:") print(results) else: print("No output data available") else: print(f"Failed to submit statement. Status code: {execute_statement_response.status_code}") print(f"Response: {execute_statement_response.text}") except Exception as e: print(f"Error executing statement: {e}")Führen Sie die Notebook-Zelle aus. Sie sollten mehrere inkrementelle Zeilen sehen, die ausgegeben werden, wenn der Auftrag übermittelt wird und die Ergebnisse zurückgegeben werden.
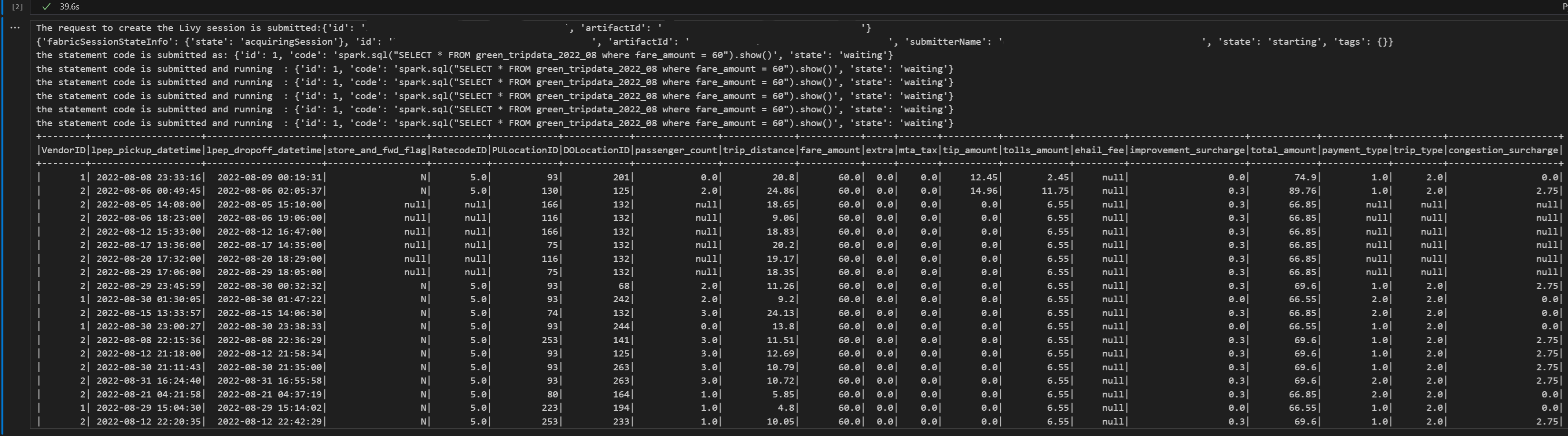

Übermitteln einer zweiten spark.sql-Anweisung mithilfe der Livy-API Spark-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
print("Executing additional Spark SQL statement...") # Wait for session to be idle again get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() while session_status["state"] != "idle": print(f" Waiting for session to be idle... Current state: {session_status['state']}") time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) session_status = get_session_response.json() # Execute another statement - Replace with your actual query payload_data = { "code": f"spark.sql(\"SELECT COUNT(*) as total_records FROM {table_name}\").show()", "kind": "spark" } print(f"Executing query: {payload_data['code']}") try: # Submit the second statement execute_statement_response = requests.post(execute_statement_url, headers=headers, json=payload_data) if execute_statement_response.status_code == 200: statement_info = execute_statement_response.json() print('Second statement submitted successfully') statement_id = str(statement_info['id']) get_statement_url = f"{livy_session_url}/statements/{statement_id}" # Monitor execution print("Monitoring statement execution...") get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() while statement_status["state"] != "available": print(f" Statement state: {statement_status['state']} - waiting 5 seconds...") time.sleep(5) get_statement_response = requests.get(get_statement_url, headers=headers) statement_status = get_statement_response.json() # Display results print("Second statement execution completed!") if 'output' in statement_status and 'data' in statement_status['output']: results = statement_status['output']['data']['text/plain'] print("Query Results:") print(results) else: print("No output data available") else: print(f"Failed to submit second statement. Status code: {execute_statement_response.status_code}") except Exception as e: print(f"Error executing second statement: {e}")Führen Sie die Notebook-Zelle aus. Sie sollten mehrere inkrementelle Zeilen sehen, die ausgegeben werden, wenn der Auftrag übermittelt wird und die Ergebnisse zurückgegeben werden.

Beenden der Livy-Sitzung
Fügen Sie eine weitere Notebookzelle hinzu, und fügen Sie diesen Code ein.
print("Cleaning up Livy session...") try: # Check current session status before deletion get_session_response = requests.get(livy_session_url, headers=headers) if get_session_response.status_code == 200: session_info = get_session_response.json() print(f"Session state before deletion: {session_info.get('state', 'unknown')}") print(f"Deleting session at: {livy_session_url}") # Delete the session delete_response = requests.delete(livy_session_url, headers=headers) if delete_response.status_code == 200: print("Session deleted successfully") elif delete_response.status_code == 404: print("Session was already deleted or not found") else: print(f"Delete request completed with status code: {delete_response.status_code}") print(f"Response: {delete_response.text}") print(f"Delete response details: {delete_response}") except requests.exceptions.RequestException as e: print(f"Network error during session deletion: {e}") except Exception as e: print(f"Error during session cleanup: {e}")
Ihre Aufträge im Überwachungs-Hub anzeigen
Sie können auf den Überwachungshub zugreifen, um verschiedene Apache Spark-Aktivitäten anzuzeigen, indem Sie in den Navigationslinks auf der linken Seite „Überwachen“ auswählen.
Bei laufenden oder abgeschlossenen Sitzungen können Sie den Sitzungsstatus anzeigen, indem Sie zu „Überwachen“ navigieren.
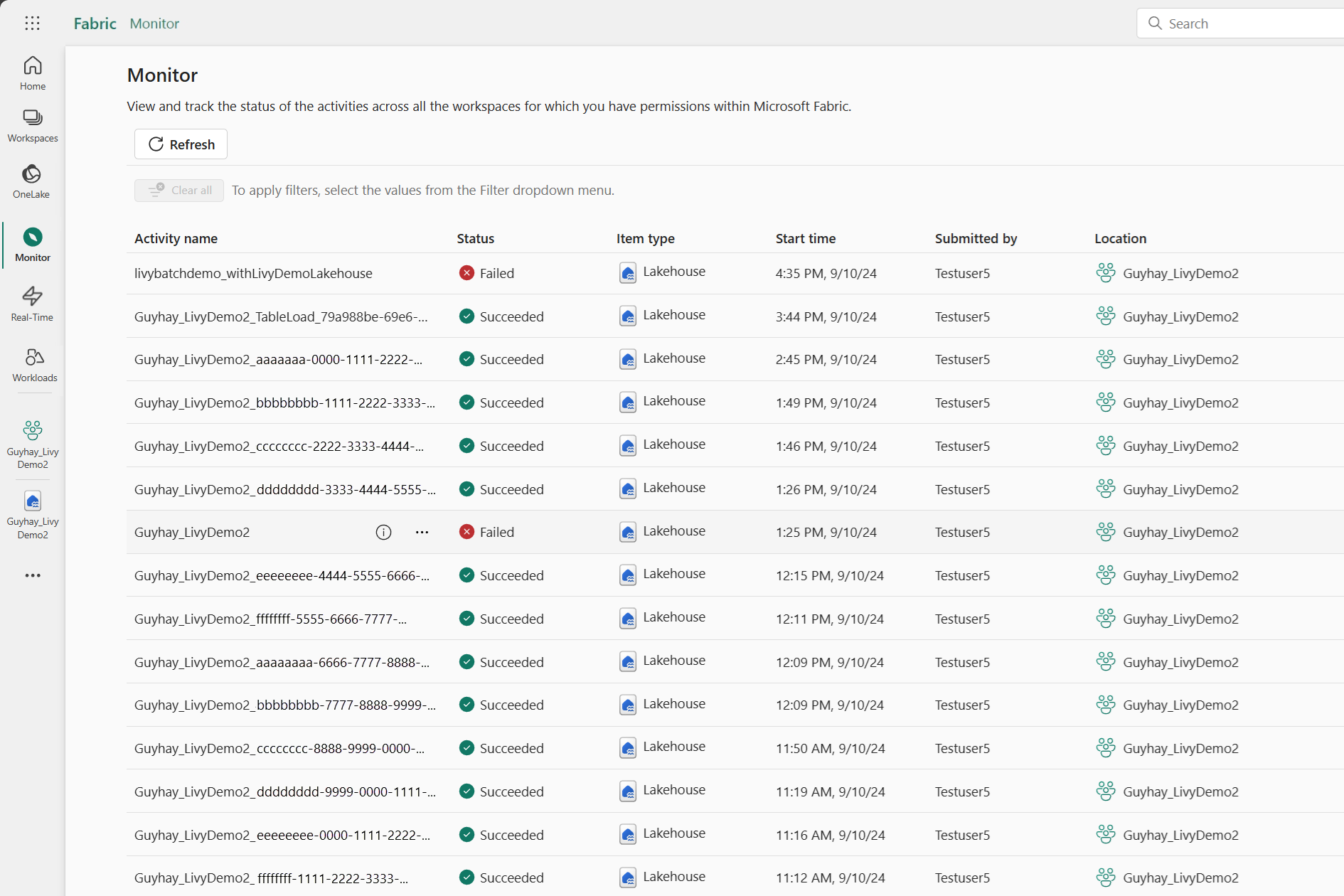
Wählen Sie den Namen der letzten Aktivität aus, und öffnen Sie sie.
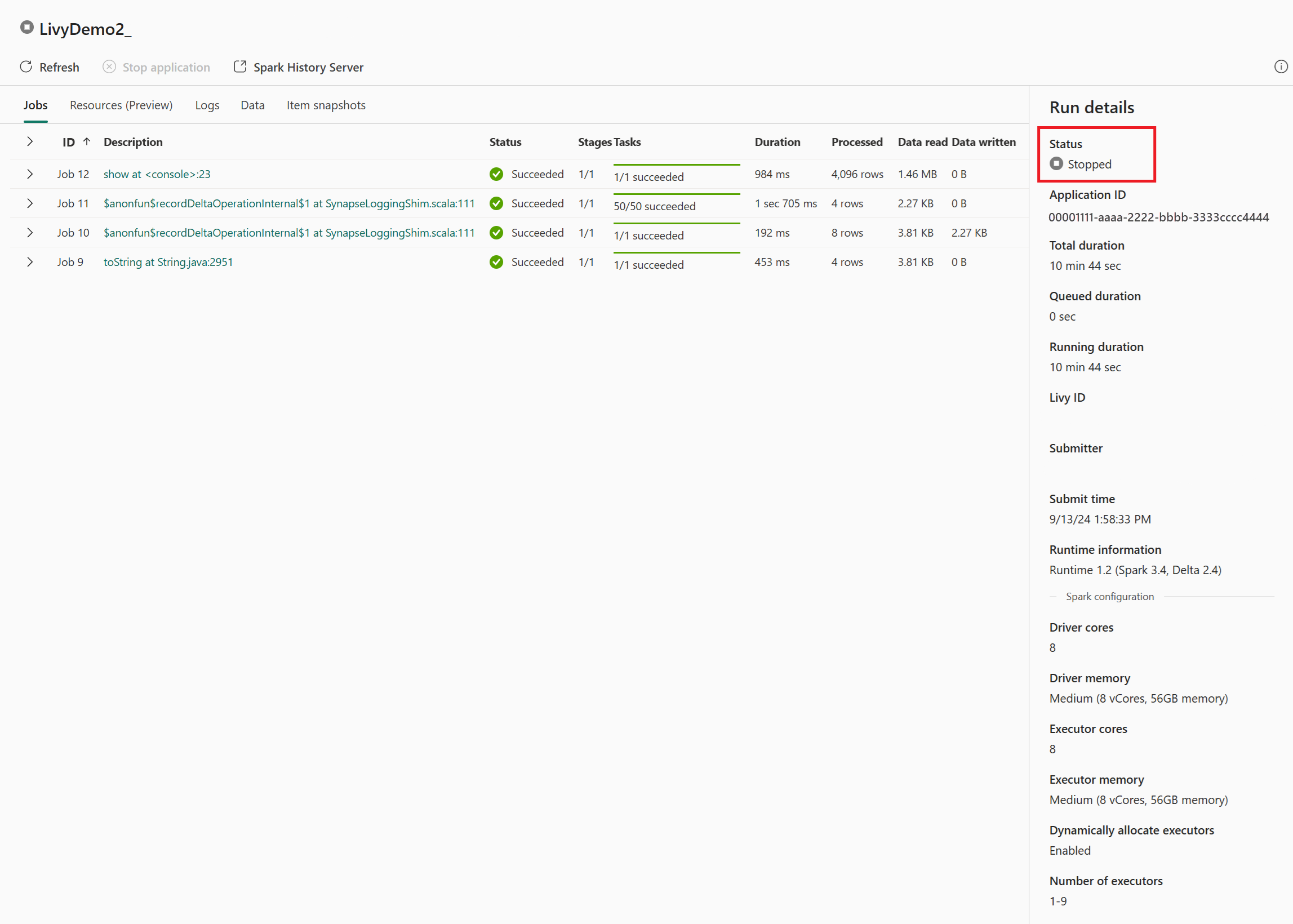
In diesem Livy-API-Sitzungsfall können Sie Ihre vorherigen Sitzungsübermittlungen, Ausführungsdetails, Spark-Versionen und Konfigurationen einsehen. Beachten Sie den Status „Angehalten“ oben rechts.



Um den gesamten Prozess zusammenzufassen, benötigen Sie einen Remote-Client wie Visual Studio Code, ein Microsoft Entra-App/SPN-Token, die Livy-API-Endpunkt-URL, die Authentifizierung gegen Ihr Lakehouse und schließlich eine Session-Livy-API.