Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Die native Ausführungsengine ist eine bahnbrechende Erweiterung für Apache Spark-Auftragsausführungen in Microsoft Fabric. Diese vektorisierte Engine optimiert die Leistung und Effizienz Ihrer Spark-Abfragen, indem sie direkt in Ihrer Lakehouse-Infrastruktur ausgeführt werden. Die nahtlose Integration der Engine bedeutet, dass keine Codeänderungen erforderlich sind und die Anbietereinsperrung vermieden wird. Es unterstützt Apache Spark-APIs und ist mit Runtime 1.3 (Apache Spark 3.5) kompatibel und funktioniert sowohl mit Parquet- als auch mit Delta-Formaten. Unabhängig vom Standort Ihrer Daten in OneLake oder wenn Sie über Verknüpfungen auf Daten zugreifen, maximiert die native Ausführungsengine Effizienz und Leistung.
Die native Ausführungsengine erhöht die Abfrageleistung erheblich und minimiert gleichzeitig die Betriebskosten. Es bietet eine bemerkenswerte Geschwindigkeitsverbesserung und erreicht eine bis zu viermal schnellere Leistung im Vergleich zu herkömmlichen OSS (Open Source Software) Spark, die durch den TPC-DS 1-TB-Benchmark validiert wird. Die Engine verfügt über die Verwaltung einer Vielzahl von Datenverarbeitungsszenarien, von Routinedatenaufnahme, Batchaufträgen und ETL-Aufgaben (Extrahieren, Transformieren, Laden) bis hin zu komplexen Datenanalysen und reaktionsfähigen interaktiven Abfragen. Benutzer profitieren von beschleunigten Verarbeitungszeiten, erhöhter Durchsatz und optimierter Ressourcenverwendung.
Das native Execution Engine basiert auf zwei wichtigen OSS-Komponenten: Velox, einer von Meta eingeführten C++-Datenbankbeschleunigungsbibliothek und Apache Gluten (Inkubating), einer mittleren Ebene, die für das Entladen der Ausführung von JVM-basierten SQL-Engines an systemeigene Engines verantwortlich ist, die von Intel eingeführt wurden.
Wann die native Ausführungsengine verwendet werden soll
Die native Ausführungsengine bietet eine Lösung zum Ausführen von Abfragen auf großen Datasets; Es optimiert die Leistung, indem die nativen Funktionen zugrunde liegender Datenquellen verwendet werden, und der Mehraufwand, der normalerweise mit der Datenverschiebung und Serialisierung in herkömmlichen Spark-Umgebungen verbunden ist, minimiert wird. Die Engine unterstützt verschiedene Operatoren und Datentypen, einschließlich Rolluphashaggregat, übertragener Join geschachtelter Schleifen (BNLJ) und präzise Zeitstempelformate. Um jedoch vollständig von den Funktionen der Engine zu profitieren, sollten Sie die optimalen Anwendungsfälle berücksichtigen:
- Die Engine ist effektiv beim Arbeiten mit Daten in Parquet- und Delta-Formaten, die es nativ und effizient verarbeiten kann.
- Abfragen, die komplexe Transformationen und Aggregationen umfassen, profitieren erheblich von den Spaltenverarbeitungs- und Vektorisierungsfunktionen der Engine.
- Leistungsverbesserungen sind in Szenarien besonders wichtig, in denen die Abfragen den Fallbackmechanismus nicht auslösen, indem nicht unterstützte Features oder Ausdrücke vermieden werden.
- Die Engine eignet sich gut für Abfragen, die rechenintensiv sind, anstatt einfach oder E/A-gebunden.
Informationen zu den Operatoren und Funktionen, die von der nativen Ausführungsengine unterstützt werden, finden Sie in der Apache Gluten-Dokumentation.
Aktivieren der nativen Ausführungsengine
Um die vollständigen Funktionen der nativen Ausführungsengine während der Vorschauphase zu nutzen, sind bestimmte Konfigurationen erforderlich. Die folgenden Verfahren zeigen, wie Sie dieses Feature für Notebooks, Spark-Auftragsdefinitionen und ganze Umgebungen aktivieren.
Wichtig
Das Native Execution Engine unterstützt die neueste allgemein verfügbare Runtime-Version Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Mit der Veröffentlichung des systemeigenen Ausführungsmoduls in Runtime 1.3 wird die Unterstützung für die vorherige Version – Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4) nicht mehr unterstützt. Wir empfehlen allen Kunden, ein Upgrade auf die neueste Runtime 1.3 durchzuführen. Wenn Sie die Native Execution Engine in Runtime 1.2 verwenden, wird die native Beschleunigung deaktiviert.
Aktivieren auf Umgebungsebene
Um eine einheitliche Leistungsverbesserung sicherzustellen, aktivieren Sie die native Ausführungsengine für alle Aufträge und Notebooks, die Ihrer Umgebung zugeordnet sind:
Navigieren Sie zu dem Arbeitsbereich, der Ihre Umgebung enthält, und wählen Sie die Umgebung aus. Wenn Sie keine Umgebung erstellt haben, lesen Sie "Erstellen, Konfigurieren und Verwenden einer Umgebung in Fabric".
Wählen Sie unter "Spark computeAcceleration" die Option "Beschleunigung" aus.
Aktivieren Sie die Option Native Ausführungsengine aktivieren.
Speichern und veröffentlichen Sie die Änderungen.
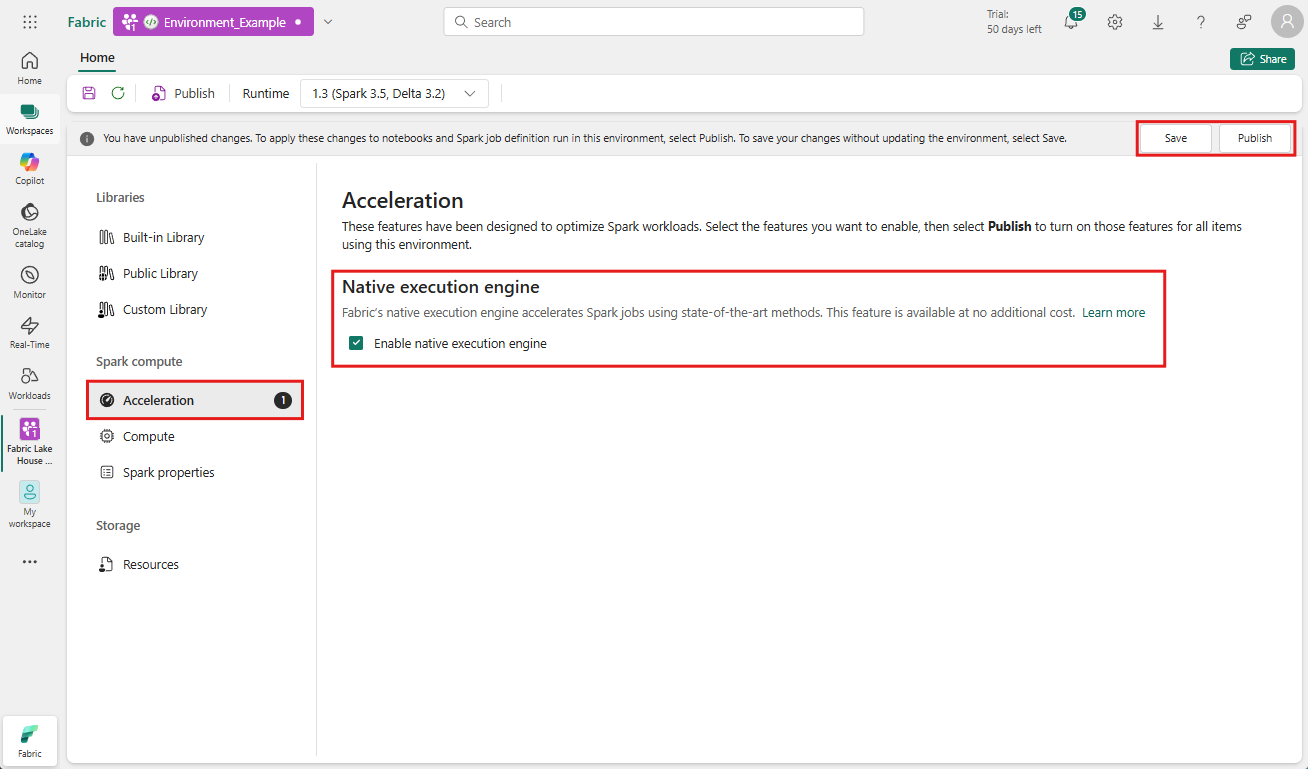

Wenn sie auf Umgebungsebene aktiviert sind, erben alle nachfolgenden Aufträge und Notebooks die Einstellung. Diese Vererbung stellt sicher, dass alle in der Umgebung erstellten neuen Sitzungen oder Ressourcen automatisch von den erweiterten Ausführungsfunktionen profitieren.
Wichtig
Zuvor wurde das systemeigene Ausführungsmodul über Spark-Einstellungen in der Umgebungskonfiguration aktiviert. Das systemeigene Ausführungsmodul kann jetzt einfacher mithilfe eines Umschalters auf der Registerkarte "Beschleunigung " der Umgebungseinstellungen aktiviert werden. Um die Verwendung fortzusetzen, wechseln Sie zur Registerkarte "Beschleunigung ", und aktivieren Sie die Umschaltfläche. Sie können sie auch über Spark-Eigenschaften aktivieren, wenn sie bevorzugt werden.
Für ein Notebook oder eine Spark-Auftragsdefinition aktivieren
Sie können auch das systemeigene Ausführungsmodul für ein einzelnes Notizbuch oder eine Spark-Auftragsdefinition aktivieren, sie müssen die erforderlichen Konfigurationen am Anfang des Ausführungsskripts integrieren:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Fügen Sie für Notebooks die erforderlichen Konfigurationsbefehle in die erste Zelle ein. Fügen Sie für Spark-Auftragsdefinitionen die Konfigurationen in die Frontlinie Ihrer Spark-Auftragsdefinition ein. Die native Ausführungsengine ist in Livepools integriert. Sobald Sie das Feature aktiviert haben, wird es sofort wirksam, ohne dass Sie eine neue Sitzung initiieren müssen.
Steuerelement auf der Abfrageebene
Die Mechanismen zur Aktivierung der nativen Ausführungsengine auf Mandanten-, Arbeitsbereichs- und Umgebungsebenen, die nahtlos in die Benutzeroberfläche integriert sind, befinden sich in der aktiven Entwicklung. Du kannst in der Zwischenzeit die native Ausführungsengine für bestimmte Abfragen deaktivieren, insbesondere, wenn sie Operatoren einbeziehen, die derzeit nicht unterstützt werden (siehe Einschränkungen). Legen Sie zum Deaktivieren die Spark-Konfiguration spark.native.enabled für die bestimmte Zelle, die Ihre Abfrage enthält, auf „false“ fest.
%%sql
SET spark.native.enabled=FALSE;

Nachdem Sie die Abfrage ausgeführt haben, in der die native Ausführungsengine deaktiviert ist, müssen Sie sie für nachfolgende Zellen erneut aktivieren, indem Sie spark.native.enabled auf „true“ festlegen. Dieser Schritt ist erforderlich, da Spark Codezellen sequenziell ausführt.
%%sql
SET spark.native.enabled=TRUE;
Identifizieren von Vorgängen, die von der Engine ausgeführt werden
Es gibt mehrere Methoden, um zu ermitteln, ob ein Operator in Ihrem Apache Spark-Auftrag mithilfe der nativen Ausführungsengine verarbeitet wurde.
Spark-UI- und Spark-Verlaufsserver
Greifen Sie auf die Spark-UI oder den Spark-Verlaufsserver zu, um die Abfrage zu finden, die Sie überprüfen müssen. Um auf die Spark-Web-UI zuzugreifen, navigieren Sie zu Ihrer Spark-Auftragsdefinition, und führen Sie sie aus. Wählen Sie auf der Registerkarte Ausführungen die Auslassungspunkte (...) neben Anwendungsname und dann Spark-Weboberfläche öffnen aus. Sie können auch über die Registerkarte Überwachen im Arbeitsbereich auf die Spark-Benutzeroberfläche zugreifen. Wählen Sie das Notebook oder die Pipeline aus. Die Überwachungsseite enthält einen direkten Link zur Spark-Benutzeroberfläche für aktive Aufträge.

Suchen Sie im Abfrageplan, der auf der Spark-Benutzeroberfläche angezeigt wird, nach Knotennamen, die mit dem Suffix Transformer, *NativeFileScan oder VeloxColumnarToRowExec enden. Das Suffix gibt an, dass die native Ausführungsengine den Vorgang ausgeführt hat. Beispielsweise können Knoten als RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer oder BroadcastNestedLoopJoinExecTransformer bezeichnet werden.

Erläutern von DataFrame
Alternativ können Sie den df.explain()-Befehl in Ihrem Notebook ausführen, um den Ausführungsplan anzuzeigen. Suchen Sie in der Ausgabe nach den gleichen Suffixen Transformer, *NativeFileScan oder VeloxColumnarToRowExec. Diese Methode bietet eine schnelle Möglichkeit, zu überprüfen, ob bestimmte Vorgänge von der nativen Ausführungsengine behandelt werden.

Fallbackmechanismus
In einigen Fällen kann die native Ausführungsengine aufgrund von Gründen wie nicht unterstützten Features möglicherweise keine Abfrage ausführen. In diesen Fällen fällt der Vorgang auf die herkömmliche Spark-Engine zurück. Mit diesem automatischen Fallbackmechanismus wird sichergestellt, dass der Workflow nicht unterbrochen wird.


Überwachen von Abfragen und DataFrames, die von der Engine ausgeführt werden
Um besser zu verstehen, wie die native Ausführungsengine für SQL-Abfragen und DataFrame-Vorgänge angewendet wird, und um einen Drilldown zu den Stage- und Operatorebenen durchzuführen, können Sie den Spark UI- und Spark History-Server verwenden, um ausführlichere Informationen zur nativen Ausführungsengine zu erhalten.
Registerkarte Native Ausführungsengine
Sie können zur neuen Registerkarte „Gluten SQL / DataFrame“ navigieren, um die Gluten-Buildinformationen und Ausführungsdetails zur Abfrage anzuzeigen. Die Tabelle „Abfragen“ bietet Einblicke in die Anzahl der Knoten, die in der nativen Engine ausgeführt werden, und diejenigen, die für jede Abfrage auf die JVM zurückfallen.

Graph zur Abfrageausführung
Sie können auch auf die Beschreibung der Abfrage klicken, um den Apache Spark-Ausführungsplan der Abfrage anzuzeigen. Der Graph bietet Details zur nativen Ausführung über Phasen und deren jeweilige Vorgänge hinweg. Die Hintergrundfarben unterscheiden die Engines: Grün stellt die native Ausführungsengine dar, während hellblau angibt, dass der Vorgang mit der Standard-JVM-Engine ausgeführt wird.

Begrenzungen
Während das Native Execution Engine (NEE) in Microsoft Fabric die Leistung für Apache Spark-Aufträge erheblich erhöht, hat es derzeit die folgenden Einschränkungen:
Vorhandene Einschränkungen
Inkompatible Spark-Features: Das systemeigene Ausführungsmodul unterstützt derzeit keine benutzerdefinierten Funktionen (UDFs), die
array_containsFunktion oder strukturiertes Streaming. Wenn diese Funktionen oder nicht unterstützte Features entweder direkt oder über importierte Bibliotheken verwendet werden, wird Spark auf das Standardmodul zurückgesetzt.Nicht unterstützte Dateiformate: Abfragen gegen
JSON,XMLundCSVFormate werden nicht vom systemeigenen Ausführungsmodul beschleunigt. Fallen standardmäßig auf die reguläre Spark JVM-Engine für die Ausführung zurück.ANSI-Modus wird nicht unterstützt: Das systemeigene Ausführungsmodul unterstützt keinen ANSI SQL-Modus. Wenn diese Option aktiviert ist, fällt die Ausführung auf das Vanilla Spark-Modul zurück.
Unstimmigkeiten des Datumsfiltertyps: Um von der Beschleunigung der nativen Ausführungs-Engine zu profitieren, stellen Sie sicher, dass beide Seiten eines Datumsvergleichs denselben Datentyp haben. Anstatt beispielsweise eine
DATETIMESpalte mit einem String-Literal zu vergleichen, konvertieren Sie diese explizit wie dargestellt.CAST(order_date AS DATE) = '2024-05-20'
Weitere Überlegungen und Einschränkungen
Decimal to Float Casting mismatch: Beim Umwandeln von
DECIMALinFLOATbehält Spark die Genauigkeit bei, indem es in eine Zeichenfolge konvertiert und geparst wird. NEE (via Velox) führt eine direkte Umwandlung aus der internenint128_tDarstellung durch, was zu Rundungsabweichungen führen kann.Konfigurationsfehler in der Zeitzone : Das Festlegen einer nicht erkannten Zeitzone in Spark bewirkt, dass der Auftrag unter NEE fehlschlägt, während Spark JVM sie ordnungsgemäß behandelt. Beispiel:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEInkonsistentes Rundungsverhalten: Die
round()Funktion verhält sich in NEE anders, aufgrund der Abhängigkeit vonstd::round, was die Rundungslogik von Spark nicht repliziert. Dies kann zu numerischen Inkonsistenzen bei Rundungsergebnissen führen.Fehlende Überprüfung auf doppelte Schlüssel in der
map()-Funktion: Wennspark.sql.mapKeyDedupPolicyauf EXCEPTION gesetzt ist, löst Spark einen Fehler für doppelte Schlüssel aus. NEE überspringt diese Überprüfung derzeit und ermöglicht es der Abfrage, fälschlicherweise erfolgreich zu sein.
Beispiel:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Abweichung der Reihenfolge in
collect_list()bei der Sortierung: Bei der Verwendung vonDISTRIBUTE BYundSORT BYbewahrt Spark die Reihenfolge der Elemente incollect_list(). NEE gibt möglicherweise Werte in einer anderen Reihenfolge aufgrund von Shuffle-Unterschieden zurück, was zu nicht übereinstimmenden Erwartungen an die Sortierlogik führen kann.Zwischentypkonflikt für
collect_list()/collect_set(): Spark verwendetBINARYals Zwischentyp für diese Aggregationen, während NEE verwendet.ARRAYDiese Nichtübereinstimmung könnte zu Kompatibilitätsproblemen während der Abfrageplanung oder -ausführung führen.Verwaltete private Endpunkte, die für den Speicherzugriff erforderlich sind: Wenn die Native Execution Engine (NEE) aktiviert ist und Spark-Aufträge versuchen, mithilfe eines verwalteten privaten Endpunkts auf ein Speicherkonto zuzugreifen, müssen Benutzer separate verwaltete private Endpunkte sowohl für den BLOB-Endpunkt (blob.core.windows.net) als auch für den DFS/Dateisystem-Endpunkt (dfs.core.windows.net) konfigurieren, auch wenn sie auf dasselbe Speicherkonto verweisen. Für beides kann kein einzelner Endpunkt wiederverwendet werden. Dies ist eine aktuelle Einschränkung und erfordert möglicherweise eine zusätzliche Netzwerkkonfiguration, wenn das systemeigene Ausführungsmodul in einem Arbeitsbereich aktiviert wird, der private Endpunkte für Speicherkonten verwaltet hat.