Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Gilt für:✅ Warehouse in Microsoft Fabric
Ersatzschlüssel sind Bezeichner, die in Data Warehouse verwendet werden, um Zeilen unabhängig von ihren natürlichen Schlüsseln eindeutig zu unterscheiden. Im Fabric Data Warehouse ermöglichen IDENTITY-Spalten die automatische Generierung dieser Ersatzschlüssel beim Einfügen neuer Zeilen in eine Tabelle. In diesem Artikel wird erläutert, wie Sie Spalten in Fabric Data Warehouse zum effizienten Erstellen und Verwalten von Ersatzschlüsseln verwenden IDENTITY .
Warum eine IDENTITY-Spalte verwenden?
IDENTITY Spalten vermeiden die Notwendigkeit einer manuellen Schlüsselzuweisung, verringern das Risiko von Fehlern und vereinfachen die Erfassung von Daten. Vom System verwaltete eindeutige Werte sind ideal als Ersatzschlüssel und Primärschlüssel. Im Vergleich zu manuellen Ansätzen zur Erstellung von Ersatzschlüsseln bieten Spalten eine bessere Leistung, IDENTITY da eindeutige Schlüssel automatisch ohne zusätzliche Logik für Abfragen generiert werden.
Der bigint-Datentyp , der für IDENTITY Spalten erforderlich ist, kann bis zu 9.223.372.036.854.775.807 positive ganzzahlige Werte speichern und sicherstellen, dass jede Zeile während der gesamten Lebensdauer einer Tabelle einen eindeutigen Wert in der IDENTITY Spalte erhält.
Einen Plan zum Migrieren von Daten mit Ersatzschlüsseln von anderen Datenbankplattformen finden Sie unter Migrieren von IDENTITY-Spalten zu Fabric Data Warehouse.
Syntax
Zum Definieren einer IDENTITY Spalte in Fabric Data Warehouse wird die IDENTITY Eigenschaft mit der gewünschten Spalte verwendet. Die Syntax lautet wie folgt:
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
[column_name] BIGINT IDENTITY,
[ ,... n ]
-- Other columns here
);
Funktionsweise von IDENTITY-Spalten
Innerhalb von Fabric Data Warehouse können Sie keinen benutzerdefinierten Startwert oder einen inkrementellen Wert angeben. das System verwaltet die Werte intern, um die Eindeutigkeit sicherzustellen.
IDENTITY Spalten erzeugen immer positive ganzzahlige Werte. Jede neue Zeile erhält einen neuen Wert, und die Eindeutigkeit wird garantiert, solange die Tabelle vorhanden ist. Sobald ein Wert verwendet wird, nutzt IDENTITY denselben Wert nicht erneut, wodurch sowohl die Schlüsselintegrität als auch die Eindeutigkeit gewahrt bleiben. Lücken können bei den von der IDENTITY-Spalte erzeugten Werten auftreten.
Zuordnung von Werten
Aufgrund der verteilten Architektur der Lagerhaus-Engine garantiert die IDENTITY-Eigenschaft nicht die Zuweisungsreihenfolge der Ersatzwerte. Die IDENTITY Eigenschaft ist so konzipiert, dass sie über Computeknoten skaliert wird, um Parallelität zu maximieren, ohne die Auslastungsleistung zu beeinträchtigen. Daher können Wertebereiche für verschiedene Aufgaben zur Erfassung unterschiedliche Sequenzbereiche aufweisen.
Betrachten Sie das folgende Beispiel, um dieses Verhalten zu veranschaulichen:
-- Create a table with an IDENTITY column
CREATE TABLE dbo.T1(
C1 BIGINT IDENTITY,
C2 VARCHAR(30) NULL
)
-- Ingestion task A
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Ingestion task B
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Reviewing the data
SELECT * FROM dbo.T1;
Beispielergebnis:
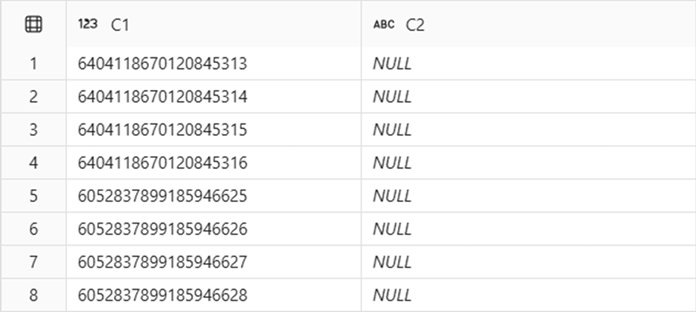
In diesem Beispiel werden Ingestion task A und Ingestion task B sequenziell als unabhängige Aufgaben ausgeführt. Obwohl die Aufgaben hintereinander ausgeführt wurden, weisen die ersten und letzten vier Zeilen unterschiedliche Identitätsschlüsselbereiche in dbo.T1.C1 auf. Darüber hinaus können, wie in diesem Beispiel beobachtet, Lücken zwischen den Bereichen auftreten, die für Vorgang A und Vorgang B zugewiesen sind.
IDENTITY in Fabric Data Warehouse garantiert, dass alle Werte in einer IDENTITY Spalte eindeutig sind, es kann jedoch Lücken in den Bereichen geben, die für eine bestimmte Ingestion-Aufgabe erzeugt werden.
Systemansichten
Die sys.identity_columns Katalogansicht kann zum Auflisten aller Identitätsspalten in einem Lager verwendet werden. Im folgenden Beispiel werden alle Tabellen aufgelistet, die eine IDENTITY Spalte in ihrer Definition enthalten, deren jeweilige Schemaname und der Name der Spalte in dieser IDENTITY Tabelle:
SELECT
s.name AS SchemaName,
t.name AS TableName,
c.name AS IdentityColumnName
FROM
sys.identity_columns AS ic
INNER JOIN
sys.columns AS c ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN
sys.tables AS t ON ic.[object_id] = t.[object_id]
INNER JOIN
sys.schemas AS s ON t.[schema_id] = s.[schema_id]
ORDER BY
s.name, t.name;
Einschränkungen
- Nur der Bigint-Datentyp wird für
IDENTITYSpalten in Fabric Data Warehouse unterstützt. Der Versuch, andere Datentypen zu verwenden, führt zu einem Fehler. -
IDENTITY_INSERTwird in Fabric Data Warehouse nicht unterstützt. Benutzer können Spaltenwerte nicht in Identitätsspalten in Fabric Data Warehouse aktualisieren oder manuell einfügen. - Das Definieren von
seedundincrementwird nicht unterstützt. Daher wird das erneute Senden derIDENTITYSpalte nicht unterstützt. - Das Hinzufügen einer neuen
IDENTITYSpalte zu einer vorhandenen Tabelle mitALTER TABLEwird nicht unterstützt. Erwägen Sie die Verwendung von CREATE TABLE AS SELECT (CTAS) oder SELECT... INTO als Alternativen zum Erstellen einer Kopie einer vorhandenen Tabelle, die der Definition eineIDENTITYSpalte hinzufügt. - Einige Einschränkungen gelten für die Erhaltung von
IDENTITYSpalten beim Erstellen einer neuen Tabelle als Ergebnis einer Auswahl aus einer anderen Tabelle mitCREATE TABLE AS SELECT (CTAS)oderSELECT... INTO. Weitere Informationen finden Sie im Abschnitt "Datentypen" von SELECT - INTO-Klausel (Transact-SQL).
Examples
A. Erstellen einer Tabelle mit einer IDENTITY-Spalte
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Diese Anweisung erstellt eine Tabelle "Employees", in der jede neue Zeile automatisch einen eindeutigen EmployeeID als bigint-Wert erhält.
B. Einfügen in eine Tabelle mit einer Identitätsspalte
Wenn die erste Spalte eine IDENTITY Spalte ist, müssen Sie sie nicht in der Spaltenliste angeben.
INSERT INTO Employees (FirstName, LastName) VALUES ('Ensi','Vasala')
Es ist auch möglich, die Spaltennamen auszublenden, wenn Werte für alle Spalten der Zieltabelle angegeben werden (mit Ausnahme der Identitätsspalte):
INSERT INTO Employees VALUES ('Quarantino', 'Esposito')
C. Erstellen einer neuen Tabelle mit einer IDENTITY-Spalte mithilfe von CREATE TABLE AS SELECT (CTAS)
Betrachten Sie eine einfache Tabelle als Beispiel:
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Wir können CREATE TABLE AS SELECT (CTAS) verwenden, um eine Kopie dieser Tabelle zu erstellen, wobei die IDENTITY Eigenschaft in der Zieltabelle beibehalten wird.
CREATE TABLE RetiredEmployees
AS SELECT * FROM Employees
Die Spalte in der Zieltabelle erbt die IDENTITY Eigenschaft von der Quelltabelle. Eine Liste der Einschränkungen, die für dieses Szenario gelten, finden Sie im Abschnitt Datentypen in der SELECT - INTO Klausel.
D. erstellen einer neuen Tabelle mit einer IDENTITY-Spalte mithilfe von SELECT... INTO
Betrachten Sie eine einfache Tabelle als Beispiel:
CREATE TABLE dbo.Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Retired BIT
);
Wir können SELECT... INTO verwenden, um eine Kopie dieser Tabelle zu erstellen, wobei die IDENTITY Eigenschaft in der Zieltabelle beibehalten wird:
SELECT *
INTO dbo.RetiredEmployees
FROM dbo.Employees
WHERE Retired = 1;
Die Spalte in der Zieltabelle erbt die IDENTITY Eigenschaft von der Quelltabelle. Eine Liste der Einschränkungen, die für dieses Szenario gelten, finden Sie im Abschnitt Datentypen in der SELECT - INTO Klausel.