Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Datenbankspiegelung in Microsoft Fabric ist eine Unternehmens-, cloudbasierte, Zero-ETL-, SaaS-Technologie. Dieser Leitfaden hilft Ihnen bei der Erstellung einer gespiegelten Datenbank aus Azure Databricks, die eine fortlaufend replizierte, schreibgeschützte Kopie Ihrer Azure Databricks-Daten in OneLake erstellt.
Voraussetzungen
- Ein „Fabric“-Arbeitsbereich.
- Aktivieren sie den Zugriff auf externe Daten im Metastore. Weitere Informationen finden Sie unter Aktivieren des Zugriffs auf externe Daten im Metastore.
- Erstellen oder Verwenden eines vorhandenen Azure Databricks-Arbeitsbereichs mit aktiviertem Unity-Katalog.
- Verfügen Sie über die Berechtigung
EXTERNAL USE SCHEMAfür das Schema in Unity Catalog, in dem sich die Tabellen befinden, auf die Fabric zugreift. - Verwenden Sie das Berechtigungsmodell von Fabric, um Zugriffssteuerungen für Kataloge, Schemas und Tabellen in Fabric festzulegen.
Erstellen einer gespiegelten Datenbank aus Azure Databricks
Führen Sie die folgenden Schritte aus, um eine neue gespiegelte Datenbank aus Ihrem Azure Databricks Unity-Katalog zu erstellen.
Wechseln Sie zu Ihrem Arbeitsbereich in Fabric.
Wählen Sie Neues Element>Mirrored Azure Databricks Katalog aus.

Wählen Sie eine vorhandene Verbindung aus, wenn Sie eine konfiguriert haben, oder erstellen Sie eine neue Verbindung.
Zum Erstellen einer Verbindung müssen Sie entweder ein Benutzer oder ein Administrator des Azure Databricks-Arbeitsbereichs sein. Sie können sich bei Ihrem Azure Databricks-Arbeitsbereich mit der Authentifizierung über Organisationskonto oder Dienstprinzipal authentifizieren.
Note
Die hier vorgenommene Authentifizierungsauswahl gilt für die Databricks-Authentifizierung und die Unity-Katalogautorisierung. Wenn Sie auf Azure Data Lake Storage (ADLS) Gen2-Konten hinter einer Firewall zugreifen müssen, führen Sie die Schritte zum Enable Netzwerksicherheitszugriff für Ihr Azure Data Lake Storage Gen2 Konto weiter unten in diesem Artikel aus. Wenn ADLS Gen2 hinter einer Firewall liegt, ist Fabric Workspace Identity für den Speicherfirewallzugriff erforderlich, unabhängig von der für die Databricks-Verbindung ausgewählten Authentifizierungsmethode.
Nachdem Sie eine Verbindung mit einem Azure Databricks-Arbeitsbereich hergestellt haben, wählen Sie auf der Seite Tabellen aus einem Databricks-Katalog auswählen den Katalog, die Schemas und die Tabellen aus, die Sie mithilfe der Einschluss- oder Ausschlussliste hinzufügen und auf die Sie von Fabric aus zugreifen möchten. Wählen Sie den Katalog und die zugehörigen Schemas und Tabellen aus, die Sie ihrem Fabric-Arbeitsbereich hinzufügen möchten.
Sie können nur die Kataloge, Schemas und Tabellen sehen, auf die Sie Zugriff haben. Weitere Informationen finden Sie unter Unity Catalog-Berechtigungen und sicherungsfähige Objekte.
Standardmäßig ist die Option "Zukünftige Katalogänderungen automatisch synchronisieren" für die ausgewählte Schemaoption aktiviert. Weitere Informationen finden Sie unter Mirroring Azure Databricks > Metadata sync.
Klicken Sie auf Weiter, um fortzufahren.
Überprüfen Sie auf der Seite Überprüfen und erstellen die Details, und ändern Sie optional den Namen des gespiegelten Datenbankelements, der in Ihrem Arbeitsbereich eindeutig sein muss. Standardmäßig ist der Name des gespiegelten Elements der Name des Katalogs.
Wählen Sie Erstellen aus, um den Vorgang fortzusetzen.
Ein Databricks-Katalogelement wird erstellt und für jede Tabelle wird auch eine entsprechende Verknüpfung vom Typ Databricks erstellt.
Schemas, die keine Tabellen enthalten, werden nicht angezeigt.
Sie können auch eine Vorschau der Daten anzeigen, wenn Sie auf eine Verknüpfung zugreifen, indem Sie den SQL-Analyseendpunkt auswählen. Öffnen Sie das SQL Analytics-Endpunktelement, um die Seite "Explorer" und den Abfrage-Editor zu starten. Sie können ihre gespiegelten Azure Databricks Tabellen mithilfe von T-SQL im SQL-Editor abfragen.
Erstellen Sie Lakehouse-Verknüpfungen für das Databricks-Katalogelement
Sie können auch Verknüpfungen von Ihrem Lakehouse zu Ihrem Databricks-Katalogelement erstellen, um Ihre Lakehouse-Daten zu verwenden und Spark Notebooks zu verwenden.
- Erstellen Sie zunächst ein Seehaus. Wenn Sie bereits über ein Seehaus in diesem Arbeitsbereich verfügen, können Sie ein vorhandenes Seehaus verwenden.
- Wählen Sie im Navigationsmenü Ihren Arbeitsbereich aus.
- Select + New>Lakehouse.
- Geben Sie im Feld "Name " einen Namen für Ihr Seehaus an, und wählen Sie "Erstellen" aus.
- Wählen Sie in der Explorer-Ansicht Ihres Seehauses im Menü "Daten in Ihrem Seehaus abrufen " unter "Daten laden" in Ihrem Seehaus die Schaltfläche "Neu " aus.
- Wählen Sie Microsoft OneLake aus. Wählen Sie einen Katalog aus. Dies ist das Datenelement, das Sie in den vorherigen Schritten erstellt haben. Wählen Sie dann Weiter aus.
- Wählen Sie Tabellen im Schema aus, und wählen Sie "Weiter" aus.
- Wählen Sie "Erstellen" aus.
- Tastenkombinationen stehen jetzt in Ihrem Lakehouse zur Verfügung, um sie mit Ihren anderen Lakehouse-Daten zu verwenden. Sie können Notizbücher und Spark auch verwenden, um die Datenverarbeitung für diese Katalogtabellen durchzuführen, die Sie aus Ihrem Azure Databricks-Arbeitsbereich hinzugefügt haben.
Ein semantisches Modell erstellen
Sie können ein Power BI semantischen Modell basierend auf Ihrem gespiegelten Element erstellen und Tabellen manuell hinzufügen oder entfernen. Weitere Informationen zum Erstellen und Verwalten von semantischen Modellen finden Sie unter Erstellen eines Power BI-Semantikmodells.
Verwenden Sie den Microsoft Edge Browser für semantische Modellierungsaufgaben, um optimale Ergebnisse zu erzielen.
Verwalten Ihrer semantischen Modellbeziehungen
Nachdem Sie ein neues semantisches Modell basierend auf Ihrer gespiegelten Datenbank erstellt haben, konfigurieren Sie die Beziehungen zwischen Tabellen.
- Wählen Sie im Explorer in Ihrem Arbeitsbereich Modelllayouts aus.
- Nachdem Sie Modelllayouts ausgewählt haben, wird ihnen eine Grafik der Tabellen angezeigt, die als Teil des Semantikmodells enthalten sind.
- Um Beziehungen zwischen Tabellen zu erstellen, ziehen Sie einen Spaltennamen aus einer Tabelle in einen anderen Spaltennamen einer anderen Tabelle. Ein Popupfenster erscheint, um die Beziehung und Kardinalität der Tabellen festzulegen.
Aktivieren des Netzwerksicherheitszugriffs für Ihr Azure Data Lake Storage Gen2-Konto
Konfigurieren Sie die Netzwerksicherheit für Ihr Azure Data Lake Storage(ADLS)-Gen2-Konto, wenn Sie eine Azure Storage Firewall konfiguriert haben. Dieser Abschnitt bezieht sich auf ADLS Gen2-Speicherkonten hinter einer Azure Storage Firewall. Der Arbeitsbereichsspeicher von Azure Databricks hinter einer Firewall von Azure Storage wird nicht unterstützt.
Voraussetzungen
Wenn eine Azure Storage Firewall ADLS Gen2 schützt, verwendet Fabric Workspace Identity, um auf die Firewall zuzugreifen. Auch wenn Sie Service principal für die ADLS-Authentifizierung in der Registerkarte Network Security auswählen, müssen Sie die Arbeitsbereichsidentität in der Azure Storage Kontofirewall zulassen.
Workspace Identity wird für den Speicherfirewallzugriff verwendet. Ein Dienstprinzipal oder OAuth wird für die Authentifizierung bei Databricks und die Autorisierung über Unity Catalog verwendet.
Um den empfohlenen Authentifizierungstyp für die Arbeitsbereichsidentität zu aktivieren, verknüpfen Sie den Fabric-Arbeitsbereich mit einer F-Kapazität. Informationen zum Erstellen einer Arbeitsbereichsidentität finden Sie unter "Authentifizieren mit Arbeitsbereichsidentität".
Sie können einen Katalog nur einem einzelnen Speicherkonto zuordnen.
Aktivieren des Netzwerksicherheitszugriffs
Wenn Sie einen neuen gespiegelten Azure Databricks-Katalog erstellen, wählen Sie im Schritt " Daten auswählen " die Registerkarte "Netzwerksicherheit " aus.
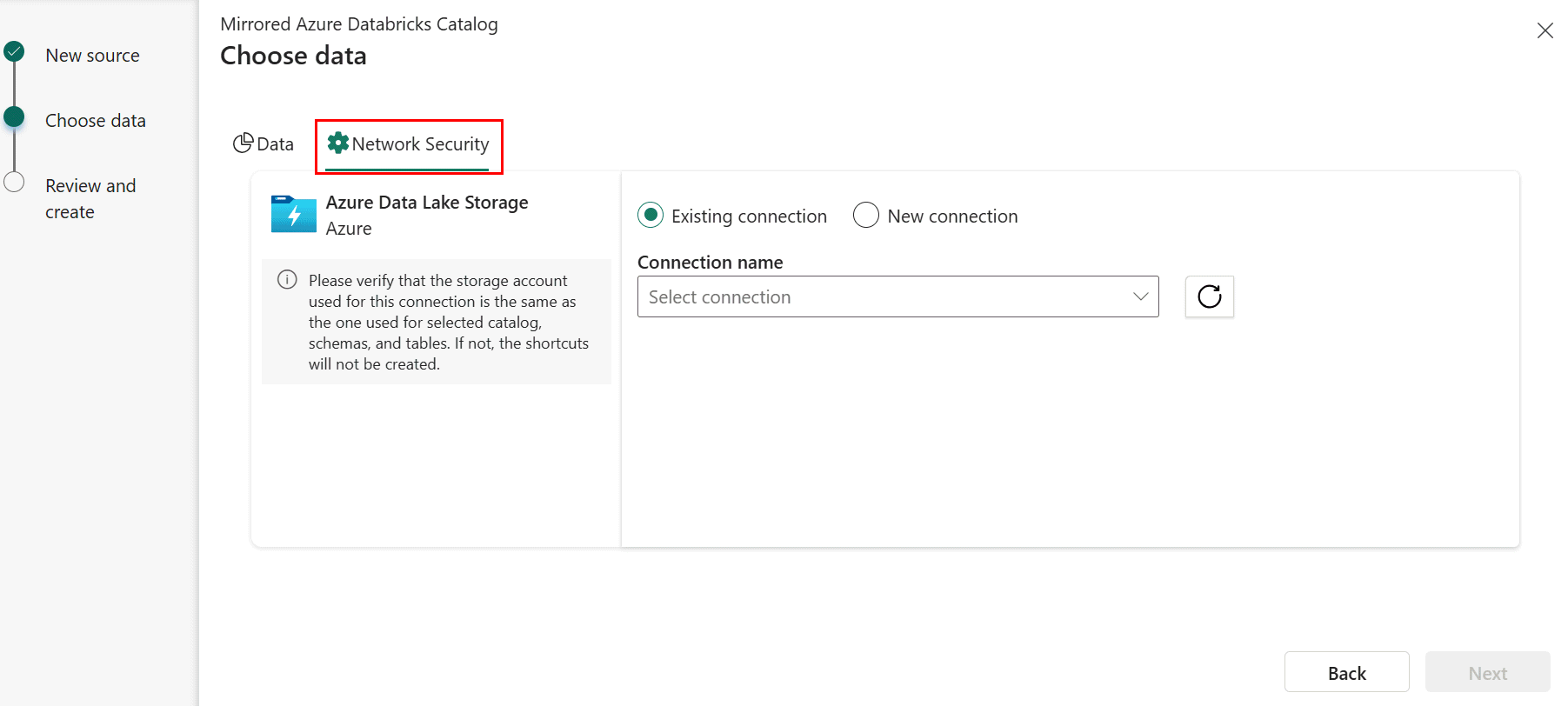
Wählen Sie eine vorhandene Verbindung mit dem Speicherkonto aus, wenn Sie eine konfiguriert haben.
- Wenn Sie über keine ADLS-Verbindung verfügen, erstellen Sie eine neue Verbindung.
- Die URL des Speicherendpunkts ist der Ort, an dem die Daten des ausgewählten Katalogs gespeichert werden. Der Endpunkt sollte der spezifische Ordner sein, in dem die Daten gespeichert werden, anstatt den Endpunkt anzugeben, der auf Speicherkontoebene zu sein soll. Geben Sie
https://<storage account>.dfs.core.windows.net/container1/folder1z. B. anstelle vonhttps://<storage account>.dfs.core.windows.net/. - Geben Sie die Verbindungsanmeldeinformationen an. Die unterstützten Authentifizierungstypen sind Organisationskonto, Dienstprinzipal und Arbeitsbereichsidentität (empfohlen).
Note
Wenn ADLS Gen2 durch eine Azure Storage Firewall geschützt ist, verwendet Fabric Workspace Identity, um die Firewall zu durchlaufen, unabhängig vom hier ausgewählten Authentifizierungstyp. Der Authentifizierungstyp (Dienstprinzipal- oder Organisationskonto) steuert die Databricks-Authentifizierung und die Unity-Katalogautorisierung, während Workspace Identity den vertrauenswürdigen Zugriff über die Speicherfirewall steuert. Die Arbeitsbereichsidentität muss in der Azure Storage Kontofirewall zulässig sein, auch wenn Sie einen anderen Authentifizierungstyp für die ADLS-Verbindung auswählen.
Geben Sie im Azure-Portal Zugriffsrechte für das Speicherkonto basierend auf dem Authentifizierungstyp an, den Sie im vorherigen Schritt ausgewählt haben. Navigieren Sie zum Speicherkonto im Azure-Portal. Wählen Sie Access Control (IAM) aus. Wählen Sie +Hinzufügen und Rollenzuweisung hinzufügen aus. Weitere Informationen finden Sie unter Weisen Sie Azure-Rollen über das Azure-Portal zu.
Weisen Sie eine Rolle basierend auf dem Bereich der Verbindung zu:
- Speicherkonto: Die ausgewählte Authentifizierungsidentität benötigt die Rolle " Storage Blob Data Reader " für das Speicherkonto.
- Container: Die ausgewählte Authentifizierungsidentität benötigt die Rolle " Storage Blob Data Reader " im Container.
- Ordner innerhalb eines Containers (empfohlen): Die ausgewählte Authentifizierungsidentität benötigt Leseberechtigungen (R) und Execute (E) auf Ordnerebene. Wenn Sie Service Principal oder Arbeitsbereichsidentität als Authentifizierungstyp verwenden, erteilen Sie dieser Identität auch die Berechtigung Ausführen für den Stammordner des Containers sowie für jeden Ordner in der Hierarchie, die zu dem angegebenen Ordner führt.
Weitere Informationen und Schritte zum Gewähren des ADLS-Zugriffs finden Sie unter ADLS-Zugriffssteuerung.
Aktivieren Sie Trusted Workspace Access, indem Sie eine Ressourceninstanzregel für Ihren Fabric Arbeitsbereich im Speicherkonto konfigurieren. Ausführliche Schritte finden Sie unter Trusted workspace access and Secure Fabric mirrored databases from Azure Databricks.
Nachdem die Verbindung hergestellt wurde, wird eine Verknüpfung zu Unity-Katalogtabellen für die Tabellen erstellt, deren Speicherkontoname mit dem in der ADLS-Verbindung angegebenen Speicherkonto übereinstimmt. Verknüpfungen werden nicht für Tabellen erstellt, deren Speicherkontoname nicht übereinstimmt.
Von Bedeutung
Wenn Sie die ADLS-Verbindung außerhalb der Szenarien mit gespiegelten Azure-Databricks-Katalogelementen verwenden möchten, müssen Sie dem Speicherkonto auch die Rolle Storage Blob Delegator zuweisen.
Tip
Wenn Sie bei der Databricks-Authentifizierung mit einem Dienstprinzipal für ein durch eine Firewall geschütztes ADLS Gen2-Konto einen 403-Autorisierungsfehler erhalten, überprüfen Sie, ob die Arbeitsbereichsidentität in der Firewall des Azure Storage-Kontos zugelassen ist. Selbst wenn für die Authentifizierung ein Service Principal ausgewählt ist, verwendet Fabric die Arbeitsbereichsidentität, um die Speicherfirewall zu passieren.
OneLake-Sicherheit für das "Gespiegelte Databricks"-Objekt aktivieren.
Ordnen Sie Unity Catalog (UC)-Richtlinien der Microsoft OneLake-Sicherheit zu, wobei Sie die folgenden Schritte ausführen:
- Synchronisieren Sie die Entra-Gruppe, und wenden Sie Berechtigungen im Unity-Katalog an. Verwenden Sie in Azure Databricks die automatische Identitätsverwaltung, um eine Microsoft Entra ID Gruppe zu synchronisieren und ihm die erforderlichen Unity-Katalogberechtigungen (USE, BROWSE und SELECT) für den relevanten Katalog und die entsprechenden Tabellen zu gewähren.
- Weisen Sie eine OneLake-Datenzugriffsrolle zu. Erstellen Sie im Fabric-Arbeitsbereich eine Datenzugriffsrolle für die neu gespiegelten Daten. Fügen Sie dieser Rolle dieselbe Entra-Gruppe hinzu, und gewähren Sie ihm Lesezugriff auf die OneLake-Verknüpfungen, die den Azure Databricks-Tabellen entsprechen. Um mit der Sicherheit auf Tabellenebene zu beginnen, wählen Sie im Menüband die Schaltfläche "OneLake-Sicherheit verwalten " aus. Stellen Sie sicher, dass Die Zugriffskonfigurationen synchronisiert bleiben, wenn Katalogstrukturen und Berechtigungen weiterentwickelt werden. Weitere Informationen finden Sie im OneLake-Datenzugriffssteuerungsmodell (Vorschau).
Verwandte Inhalte
- Sichere Fabric-geklonte Datenbanken aus Azure Databricks
- Blog: Gesicherte Spiegelung von Azure Databricks-Daten in Fabric mit OneLake-Sicherheit
- Einschränkungen in gespiegelten Microsoft Fabric-Datenbanken aus Azure Databricks
- Häufig gestellte Fragen zu gespiegelten Datenbanken aus Azure Databricks in Microsoft Fabric
- Spiegelung des Azure Databricks Unity-Katalogs
- Steuern des externen Zugriffs auf Daten im Unity-Katalog