Herstellen einer Verbindung mit SAP HANA-Datenquellen mithilfe von DirectQuery in Power BI
Sie können eine direkte Verbindung mit SAP HANA-Datenquellen mithilfe von DirectQuery herstellen, was häufig für große Datasets erforderlich ist, die verfügbare Ressourcen überschreiten, um Importmodelle zu unterstützen. Es gibt zwei Ansätze für die Verbindung mit SAP HANA im DirectQuery-Modus, jeweils mit unterschiedlichen Funktionen:
Sap HANA als mehrdimensionale Quelle behandeln (Standard): In diesem Fall ähnelt das Verhalten, wenn Power BI eine Verbindung mit anderen mehrdimensionalen Quellen wie SAP Business Warehouse oder Analysis Services herstellt. Wenn Sie eine Verbindung mit SAP HANA als mehrdimensionale Quelle herstellen, wird eine einzelne Analyse- oder Berechnungsansicht ausgewählt, und alle Maße, Hierarchien und Attribute dieser Ansicht sind in der Feldliste verfügbar. Im semantischen Modell können keine berechneten Spalten oder andere Datenanpassungen hinzugefügt werden. Da visuelle Elemente erstellt werden, werden die Aggregatdaten direkt aus SAP HANA abgerufen. SAP HANA als mehrdimensionale Quelle zu behandeln, ist die Standardeinstellung für neue DirectQuery-Berichte über SAP HANA.
Sap HANA als relationale Quelle behandeln: In diesem Fall behandelt Power BI SAP HANA als relationale Datenquelle. Dieser Ansatz bietet mehr Flexibilität. Unter anderem können Sie berechnete Spalten hinzufügen und Daten aus anderen Quellen einschließen. Es muss jedoch darauf geachtet werden, dass Maßnahmen wie erwartet aggregiert werden. Vermeiden Sie nicht additive Measures. Stellen Sie außerdem sicher, dass Sie einfache Ansichten mit wenigen Spalten und Verknüpfungen verwenden, um Leistungsprobleme zu vermeiden. Erwägen Sie die Neuerstellung von Measures im semantischen Modell, aber denken Sie daran, dass für komplexe Measures möglicherweise kein Folding stattfindet. SAP HANA-Hierarchien sind nicht verfügbar, wenn SAP HANA als relationale Quelle verwendet wird.
Die Verbindungsmethode können Sie durch eine globale Tooloption festlegen. Wählen Sie dazu Datei>Optionen und Einstellungen und anschließend Optionen >DirectQuery aus. Klicken Sie dann wie in der folgenden Abbildung dargestellt auf das Kontrollkästchen neben SAP HANA als relationale Quelle behandeln.
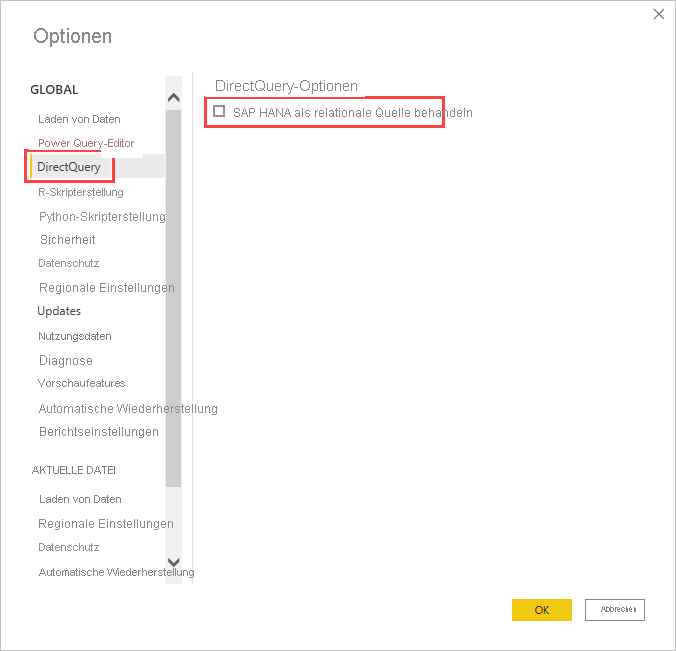
Nachdem Sie angegeben haben, dass SAP HANA als relationale Quelle behandelt werden soll, wird die Verbindungsmethode auf alle neu erstellten Berichte angewendet, die DirectQuery über SAP HANA verwenden. Sie hat keine Auswirkungen auf bestehende SAP HANA-Verbindungen im aktuellen Bericht oder auf Verbindungen in anderen Berichten, die geöffnet werden. Wenn die Option nicht aktiviert ist, wird beim Herstellen einer neuen Verbindung mit SAP HANA über Daten abrufen SAP HANA von dieser Verbindung als mehrdimensionale Quelle behandelt. Wenn jedoch ein anderer Bericht geöffnet wird, der ebenfalls eine Verbindung mit SAP HANA herstellt, wird sich das Verhalten dieses Berichts an der Option orientieren, die zum Zeitpunkt der Erstellung festgelegt wurde. Dies bedeutet, dass alle Berichte, die mit SAP HANA als relationale Quelle verbunden sind, sap HANA weiterhin als relationale Quelle behandeln, auch wenn die Option jetzt deaktiviert ist.
Die beiden SAP HANA-Verbindungsmethoden stellen ein anderes Verhalten dar, und es ist nicht möglich, einen vorhandenen Bericht von einer Verbindungsmethode zur anderen zu wechseln.
Sap HANA als mehrdimensionale Quelle behandeln (Standard)
Alle neuen Verbindungen mit SAP HANA verwenden diese Verbindungsmethode standardmäßig, wobei SAP HANA als mehrdimensionale Quelle behandelt wird. Bei der Verbindung mit SAP HANA als mehrdimensionale Quelle gelten die folgenden Überlegungen:
Im Navigator Daten abrufen kann eine einzelne SAP HANA-Ansicht ausgewählt werden. Es ist nicht möglich, einzelne Maße oder Attribute auszuwählen. Zum Zeitpunkt der Verbindung ist keine Abfrage definiert, was sich von der Vorgehensweise beim Importieren von Daten oder der Verwendung von DirectQuery unterscheidet, wenn SAP HANA als relationale Quelle behandelt wird. Diese Überlegung bedeutet auch, dass es nicht möglich ist, beim Auswählen dieser Verbindungsmethode eine SAP HANA SQL-Abfrage direkt zu verwenden.
Alle Maßnahmen, Hierarchien und Attribute der ausgewählten Ansicht werden in der Feldliste angezeigt.
Wenn ein Measure in einem Visual verwendet wird, wird SAP HANA abgefragt und dabei der Measurewert auf der Ebene der Aggregation abgerufen, die für das Visual erforderlich ist. Beim Umgang mit nicht-additiven Maßeinheiten wie Zählern und Verhältnissen werden alle Aggregationen von SAP HANA durchgeführt, und Power BI führt keine weiteren Aggregationen aus.
Um sicherzustellen, dass die richtigen Aggregatwerte immer aus SAP HANA abgerufen werden können, müssen bestimmte Einschränkungen auferlegt werden. Beispielsweise ist es nicht möglich, berechnete Spalten hinzuzufügen oder Daten aus mehreren SAP HANA-Ansichten innerhalb desselben Berichts zu kombinieren. Es ist auch nicht möglich, Spalten zu löschen oder deren Datentypen zu ändern.
SAP HANA als mehrdimensionale Quelle zu betrachten bietet weniger Flexibilität als den alternativen relationalen Ansatz , jedoch ist es einfacher. Diese Verbindungsmethode stellt beim Umgang mit komplexeren SAP HANA-Measures korrekte Aggregatwerte sicher und führt in der Regel zu einer höheren Leistung.
Die Liste Felder umfasst alle Measures, Attribute und Hierarchien der SAP HANA-Ansicht. Beachten Sie die folgenden Verhaltensweisen, die bei Verwendung dieser Verbindungsmethode angewendet werden:
Jedes Attribut, das in mindestens einer Hierarchie enthalten ist, ist standardmäßig ausgeblendet. Sie können sie sich allerdings bei Bedarf anzeigen lassen, indem Sie aus dem Kontextmenü der Feldliste den Eintrag Ausgeblendete anzeigen auswählen. Aus demselben Kontextmenü können sie ggf. sichtbar gemacht werden.
In SAP HANA kann ein Attribut definiert werden, um ein anderes Attribut als Beschriftung zu verwenden. Beispielsweise könnte ein Feld Produkt (mit den Werten
1,2,3usw.) den Produktnamen (mit den WertenBike,Shirt,Glovesusw.) als Bezeichnung verwenden. In diesem Fall wird ein einzelnes Feld Product in der Feldliste angezeigt, dessen Werte die BezeichnungenBike,Shirt,Glovesusw. sind, das aber nach den Schlüsselwerten1,2,3sortiert und dessen Eindeutigkeit durch diese Werte bestimmt wird. Außerdem wird eine ausgeblendete Spalte Product.Key erstellt, sodass ggf. Zugriff auf die zugrunde liegenden Schlüsselwerte möglich ist.
Alle variablen, die in der zugrunde liegenden SAP HANA-Ansicht definiert sind, werden zum Zeitpunkt der Verbindung angezeigt, und die erforderlichen Werte können eingegeben werden. Sie können diese Werte später ändern, indem Sie im Menüband auf Daten umwandeln klicken und anschließend im Dropdownmenü den Eintrag Parameter bearbeiten auswählen.
Die zulässigen Modellierungsvorgänge sind restriktiver als im allgemeinen Fall bei der Verwendung von DirectQuery, da sichergestellt werden muss, dass korrekte Aggregatdaten immer aus SAP HANA abgerufen werden können. Es ist jedoch weiterhin möglich, einige Ergänzungen und Änderungen vorzunehmen, darunter das Definieren von Measures, das Umbenennen und Ausblenden von Feldern und das Definieren von Anzeigeformaten. Alle diese Änderungen werden bei der Aktualisierung beibehalten, und alle nicht widersprüchlichen Änderungen, die an der SAP HANA-Ansicht vorgenommen wurden, werden angewendet.
Zusätzliche Modellierungseinschränkungen
Beachten Sie zusätzlich zu den oben genannten Einschränkungen die folgenden Modellierungseinschränkungen, wenn Sie eine Verbindung mit SAP HANA als mehrdimensionale Quelle herstellen:
- Keine Unterstützung für berechnete Spalten: Die Möglichkeit zum Erstellen berechneter Spalten ist deaktiviert. Dies bedeutet auch, dass Gruppierung und Clustering, die auf berechneten Spalten basieren, nicht verfügbar sind.
- Zusätzliche Einschränkungen für Measures: Für DAX-Ausdrücke, die in Measures verwendet werden können, gelten zusätzliche Einschränkungen, damit die von SAP HANA bereitgestellte Unterstützung übernommen wird. Beispielsweise ist es nicht möglich, eine Aggregatfunktion über eine Tabelle zu verwenden.
- Keine Unterstützung für die Definition von Beziehungen: Nur eine einzelne Ansicht kann in einem Bericht abgefragt werden, und daher gibt es keine Unterstützung für die Definition von Beziehungen.
- Keine Datenansicht: Die Datenansicht zeigt in der Tabelle normalerweise Daten auf Detailebene an. Angesichts der Art von mehrdimensionalen Quellen ist diese Ansicht nicht verfügbar, wenn SAP HANA als mehrdimensionale Quelle verwendet wird.
- Spalten- und Messdetails sind festgelegt: Die Spalten und Messgrößen in der Feldliste werden von der zugrunde liegenden Quelle bestimmt und können nicht geändert werden. Beispielsweise ist es nicht möglich, eine Spalte zu löschen oder den Datentyp zu ändern. Sie kann jedoch umbenannt werden.
Zusätzliche Visualisierungseinschränkungen
Wenn mit SAP HANA als mehrdimensionaler Quelle eine Verbindung hergestellt wird, sind Einschränkungen bei Visuals zu beachten:
- Keine Spaltenaggregation: Es ist nicht möglich, die Aggregation einer Spalte in einem Visual zu ändern. Sie verfügt immer über den Status Nicht zusammenfassen.
Behandle SAP HANA als relationale Quelle
Um eine Verbindung mit SAP HANA als relationale Quelle herzustellen, müssen Sie Datei>Optionen und Einstellungen und dann Optionen>DirectQueryauswählen und dann die Option SAP HANA als relationale Quelle behandelnauswählen.
Bei der Verwendung von SAP HANA als relationale Quelle stehen einige zusätzliche Flexibilität zur Verfügung. Sie können beispielsweise berechnete Spalten erstellen, Daten aus mehreren SAP HANA-Ansichten einschließen und Beziehungen zwischen den resultierenden Tabellen erstellen. Es gibt jedoch Unterschiede zwischen dem Verhalten beim Herstellen einer Verbindung mit SAP HANA als mehrdimensionaler Quelle, insbesondere dann, wenn die SAP HANA-Sicht nicht additive Measures enthält, z. B. einzelne Anzahlen oder Mittelwerte anstelle einfacher Summen. Nicht-additive Maßnahmen können zu falschen Ergebnissen führen. Die Maßnahmen können auch die Effizienz der Abfrageplanoptimierung in SAP HANA reduzieren und zu schlechter Abfrageleistung und Timeouts führen.
Grundlegendes zu SAP HANA als relationale Quelle
Es ist zunächst sinnvoll, sich mit dem Verhalten einer relationalen Quelle wie SQL Server zu befassen, wenn die Abfrage, die in Daten abrufen oder im Power Query-Editor festgelegt ist, eine Aggregation ausführt. Im folgenden Beispiel gibt eine im Power Query-Editor definierte Abfrage den Durchschnittspreis nach ProductIDaus.
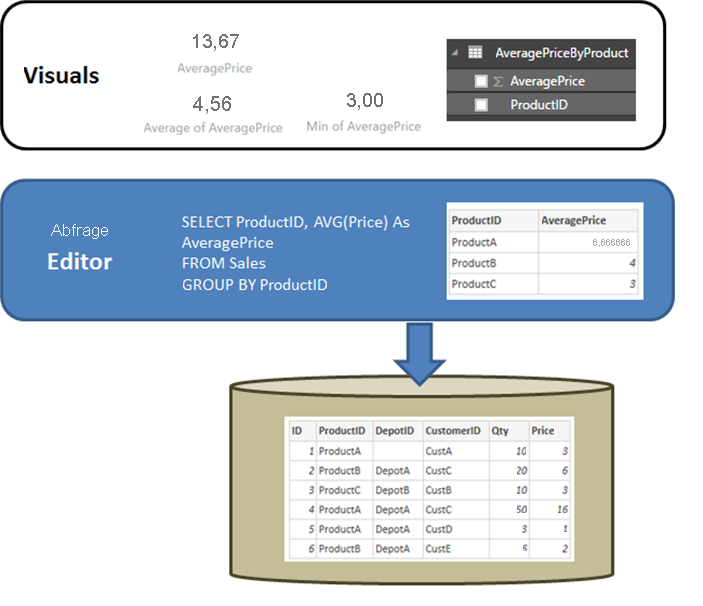
Wenn die Daten in Power BI importiert wurden, anstatt DirectQuery zu nutzen, würde die folgende Situation ergeben:
- Die Daten werden auf der Aggregationsebene importiert, die von der abfrage definiert wird, die im Power Query-Editor erstellt wurde. Beispiel: durchschnittlicher Preis nach Produkt. Diese Tatsache führt zu einer Tabelle mit den beiden Spalten ProductID und AveragePrice, die in Visualisierungen verwendet werden können.
- In einem Visual erfolgt jede nachträgliche Aggregation (z. B. Sum, Average, Min oder andere) über die importierten Daten. Wenn Sie beispielsweise AveragePrice aus einem Visual einbeziehen, wird das Aggregat Sum standardmäßig verwendet. So würde die Summe über den AveragePrice-Wert jeder ProductID zurückgegeben werden. In diesem Beispiel würde sie 13,67 betragen. Das gleiche gilt für andere Aggregatfunktionen (z.B. Min, Average usw.), die im Visual verwendet werden. Average von AveragePrice gibt z. B. den Durchschnitt von 6,66, 4 und 3 zurück, was 4,56 ergibt, und nicht den Durchschnitt von Price in den sechs Datensätzen in der zugrunde liegenden Tabelle, der 5,17 ergibt.
Wenn DirectQuery über dieselbe relationale Quelle anstelle von Import verwendet wird, gelten dieselben Semantiken, und die Ergebnisse sind exakt dieselben.
Aufgrund derselben Abfrage werden logisch genau die gleichen Daten auf der Berichtsebene angezeigt, auch wenn die Daten nicht tatsächlich importiert werden.
In einem Visual werden alle nachfolgenden Aggregationen (wie Sum, Average und Min) noch mal über diese logische Tabelle aus der Abfrage ausgeführt. Und wieder gibt ein Visual, das Average von AveragePrice enthält, das gleiche Ergebnis zurück, nämlich 4,56.
Betrachten Sie SAP HANA, wenn die Verbindung als relationale Quelle behandelt wird. Power BI funktioniert mit analytischen Ansichten und Berechnungsansichten in SAP HANA, die beide Measures enthalten können. Mittlerweile folgt der Ansatz für SAP HANA aber denselben Prinzipien, die weiter oben beschrieben wurden: Die Abfrage, die in Daten abrufen oder im Power Query-Editor definiert wird, legt fest, welche Daten verfügbar sind, und anschließend werden alle nachfolgenden Aggregationen in einem Visual für diese Daten ausgeführt. Das Gleiche gilt sowohl für die Option „Import“ als auch für DirectQuery. Angesichts der Beschaffenheit von SAP HANA ist die im ersten Dialogfeld Daten abrufen oder im Power Query-Editor definierte Abfrage immer eine Aggregatabfrage und enthält in der Regel Measures, bei denen die tatsächlichen Aggregationen, die verwendet werden, durch die SAP HANA-Ansicht definiert sind.
Das Äquivalent des vorherigen SQL Server-Beispiels ist, dass es eine SAP HANA-Ansicht mit ID, ProductID, DepotIDund Kennzahlen einschließlich Durchschnittspreisgibt, der in der Ansicht als Durchschnitt des Preisesdefiniert ist.
Wenn unter Daten abrufen die Auswahl für die Measures ProductID und AveragePrice getroffen wurde, wird dadurch eine Abfrage über die Ansicht definiert, die die Aggregatdaten anfordert. Im vorherigen Beispiel wird der Einfachheit halber Pseudo-SQL verwendet, die nicht mit der genauen Syntax von SAP HANA SQL übereinstimmt. Dann aggregieren alle weiteren Aggregationen, die in einem Visual definiert sind, die Ergebnisse für eine solche Abfrage weiter. Wie zuvor für SQL Server beschrieben, gilt dieses Ergebnis sowohl für den Import- als auch für den DirectQuery-Fall. Im DirectQuery-Fall wird die Abfrage von Daten abrufen oder vom Power Query-Editor in einer untergeordneten SELECT-Anweisung innerhalb einer einzelnen Abfrage verwendet, die an SAP HANA gesendet wird. Daher handelt es sich nicht tatsächlich um den Fall, in dem alle Daten vor dem weiteren Aggregieren gelesen werden.
Alle diese Überlegungen und Verhaltensweisen erfordern die folgenden wichtigen Überlegungen bei der Verwendung von DirectQuery über SAP HANA als relationale Quelle:
Berücksichtigt werden müssen alle weiteren Aggregationen, die in Visuals ausgeführt werden, wenn das Measure in SAP HANA nicht additiv ist (z. B. keine einfache Summe, Min oder Max).
In Daten abrufen oder im Power Query-Editor werden nur die zum Abrufen der Daten erforderlichen Spalten einbezogen. Dies zeigt, dass das Ergebnis eine sinnvolle Abfrage sein muss, die an SAP HANA gesendet werden kann. Wenn z. B. dutzende Spalten ausgewählt wurden, um herauszufinden, ob sie möglicherweise in nachfolgenden Visuals benötigt werden, dann bedeutet ein einfaches Visual selbst für DirectQuery, dass die Aggregatabfrage, die in der untergeordneten Anweisung verwendet wurde, diese dutzende Spalten enthält, was allgemein zu keiner guten Leistung führt und zu Timeouts führen kann.
Wenn Sie im folgenden Beispiel fünf Spalten (CalendarQuarter, Color, LastName, ProductLine und SalesOrderNumber) im Dialogfeld Daten abrufen zusammen mit dem Measure OrderQuantity auswählen, bedeutet dies, dass das Erstellen eines einfachen Visuals, das die Mindestbestellmenge (OrderQuantity) enthält, später zu der folgenden SQL-Abfrage an SAP HANA führt. Der schattierte Bereich ist die untergeordnete SELECT-Anweisung, die die Abfrage von Daten abrufen/vom Power Query-Editor enthält. Wenn aus dieser untergeordneten SELECT-Anweisung ein Ergebnis mit hoher Kardinalität resultiert, führt dies wahrscheinlich zu einer schlechteren SAP HANA-Leistung oder Timeouts. Die Leistungseinbußen sind nicht darauf zurückzuführen, dass Power BI alle Felder in der untergeordneten Anweisung anfordert; die meisten dieser Felder werden von der äußeren Abfrage ausgefiltert. Vielmehr sind die Einbußen auf Measures in der untergeordneten Anweisung zurückzuführen, die die Materialisierung im HANA-Server erzwingen.

Aufgrund dieses Verhaltens empfehlen wir, dass die im Datenabruf oder Power Query-Editor ausgewählten Elemente auf die benötigten Elemente beschränkt werden, um dennoch eine sinnvolle Abfrage für SAP HANA zu gewährleisten. Wenn möglich, erwägen Sie, alle erforderlichen Kennzahlen im semantischen Modell neu zu erstellen und SAP HANA eher wie eine traditionelle relationale Datenquelle zu verwenden.
Bewährte Methoden
Befolgen Sie für beide Methoden zum Herstellen einer Verbindung mit SAP HANA die allgemeinen Empfehlungen für die Verwendung von DirectQuery, insbesondere empfehlungen für eine gute Abfrageleistung. Weitere Informationen finden Sie unter Verwenden von DirectQuery in Power BI.
Überlegungen und Einschränkungen
In der folgenden Liste werden alle SAP HANA-Features beschrieben, die nicht vollständig unterstützt werden, oder Features, die sich bei Verwendung von Power BI anders verhalten.
- Eltern-Kind-Hierarchien: Eltern-Kind-Hierarchien sind in Power BI nicht sichtbar. Dies liegt daran, dass Power BI über die SQL-Schnittstelle auf SAP HANA zugreift. Mit SQL ist ein vollständiger Zugriff auf über-/untergeordnete Hierarchien jedoch nicht möglich.
- Andere Hierarchiemetadaten: Die grundlegende Struktur von Hierarchien wird in Power BI angezeigt, jedoch haben einige Hierarchiemetadaten, z. B. das Steuern des Verhaltens von lückigen Hierarchien, keine Auswirkung. Dies ist wiederum auf Einschränkungen zurückzuführen, die von der SQL-Schnittstelle auferlegt werden.
- Verbindung mit SSL: Sie können mit TLS eine Verbindung herstellen, die Import und mehrdimensionale Quellen verwendet, jedoch keine Verbindung mit SAP HANA-Instanzen, die dafür konfiguriert sind, TLS für die relationale Verbindungsmethode zu verwenden.
- Unterstützung für Attributansichten: Power BI kann eine Verbindung mit den Ansichten „Analyse“ und „Berechnung“ herstellen. Eine direkte Verbindung mit der Ansicht „Attribut“ ist hingegen nicht möglich.
- Unterstützung für Katalogobjekte: Power BI kann keine Verbindung mit Katalogobjekten herstellen.
- Änderungen an Variablen nach der Veröffentlichung: Sie können die Werte für SAP HANA-Variablen nicht direkt über den Power BI-Dienst ändern, nachdem der Bericht veröffentlicht wurde.
Bekannte Probleme
In der folgenden Liste werden alle bekannten Probleme beim Herstellen einer Verbindung mit SAP HANA (DirectQuery) mit Power BI beschrieben.
Problem mit SAP HANA bei Abfragen für Zähler und andere Measures: Falsche Daten werden von SAP HANA zurückgegeben, wenn eine Verbindung mit einer analytischen Ansicht hergestellt wird und ein Zählermeasure sowie ein weiteres Verhältnismeasure in demselben Visual enthalten sind. Dieses Problem wird im SAP-Hinweis 2128928 „Unexpected results when query a Calculated Column and a Counter“ (Unerwartete Ergebnisse beim Abfragen einer berechneten Spalte und eines Zählers) beschrieben. Das Verhältnismaß ist in diesem Fall falsch.
Mehrere Power BI-Spalten aus einer einzelnen SAP HANA-Spalte: Bei einigen Berechnungsansichten, bei denen eine SAP HANA-Spalte in mehr als einer Hierarchie verwendet wird, macht SAP HANA die Spalte als zwei separate Attribute verfügbar. Dieser Ansatz führt dazu, dass in Power BI zwei Spalten erstellt werden. Diese Spalten sind standardmäßig ausgeblendet, jedoch verhalten sich alle Abfragen, die die Hierarchien oder die Spalten direkt betreffen, korrekt.
Verwandte Inhalte
Weitere Informationen zu DirectQuery finden Sie in den folgenden Ressourcen: