Überblick über die Abfrageauswertung und das Query Folding in Power Query
Dieser Artikel gibt einen grundlegenden Überblick darüber, wie M-Abfragen verarbeitet und in Datenquellenanforderungen umgewandelt werden.
Skript Power Query M
Jede Abfrage, ob von Power Query erstellt, von Ihnen manuell im erweiterten Editor geschrieben oder über ein leeres Dokument eingegeben, besteht aus Funktionen und Syntax der Power Query M Formelsprache. Diese Abfrage wird von der Power Query Engine interpretiert und ausgewertet, um die Ergebnisse auszugeben. Das M-Skript dient als Satz von Anweisungen, die zur Auswertung der Abfrage benötigt werden.
Tipp
Sie können sich das M-Skript wie ein Rezept vorstellen, das beschreibt, wie Sie Ihre Daten aufbereiten.
Die gängigste Art, ein M-Skript zu erstellen, ist die Verwendung des Power Query Editors. Wenn Sie z. B. eine Verbindung mit einer Datenquelle herstellen, z. B. eine SQL Server-Datenbank, beachten Sie auf der rechten Seite des Bildschirms, dass ein Abschnitt mit angewendeten Schritten aufgerufen wird. In diesem Abschnitt werden alle Schritte oder Transformationen angezeigt, die in Ihrer Abfrage verwendet werden. In diesem Sinne dient der Power Query-Editor als Schnittstelle, die Sie bei der Erstellung des geeigneten M-Skripts für die gewünschten Transformationen unterstützt und sicherstellt, dass der von Ihnen verwendete Code gültig ist.
Hinweis
Das Skript M wird im Power Query Editor verwendet, um:
- Zeigen Sie die Abfrage als eine Reihe von Schritten an und ermöglichen Sie die Erstellung oder Änderung von neuen Schritten.
- Anzeigen einer Diagrammansicht.

Das vorige Bild hebt den Bereich der angewandten Schritte hervor, der die folgenden Schritte enthält:
- Quelle: Stellt die Verbindung zur Datenquelle her. In diesem Fall handelt es sich um eine Verbindung zu einer SQL Server-Datenbank.
- Navigation: Navigiert zu einer bestimmten Tabelle in der Datenbank.
- Entfernte andere Spalten: Wählt aus, welche Spalten der Tabelle beibehalten werden sollen.
- Sortierte Zeilen: Sortiert die Tabelle anhand einer oder mehrerer Spalten.
- Oberste Zeilen beibehalten: Filtert die Tabelle, um nur einige Zeilen vom Anfang der Tabelle zu behalten.
Dieser Satz von Schrittnamen ist eine benutzerfreundliche Möglichkeit zum Anzeigen des M-Skripts, das Power Query für Sie erstellt hat. Es gibt mehrere Möglichkeiten, das vollständige M-Skript anzuzeigen. In Power Query können Sie Advanced Editor auf der Registerkarte Ansicht auswählen. Sie können auch Advanced Editor aus der Gruppe Query auf der Registerkarte Home auswählen. In einigen Versionen von Power Query können Sie auch die Ansicht der Formelleiste ändern, um das Abfrageskript anzuzeigen, indem Sie auf der Registerkarte Ansicht und in der Gruppe Layout die Option Skriptansicht>Abfrageskriptwählen.

Die meisten Namen, die Sie im Bereich Angewandte Schritte finden, werden auch im M-Skript verwendet. Die Schritte einer Abfrage werden in der Sprache M mit so genannten identifiers benannt. Manchmal werden in M zusätzliche Zeichen um die Schrittnamen gelegt, aber diese Zeichen werden in den angewandten Schritten nicht angezeigt. Ein Beispiel ist #"Kept top rows", das aufgrund dieser zusätzlichen Zeichen als quoted identifier eingestuft wird. Ein Bezeichner in Anführungszeichen kann verwendet werden, um eine beliebige Folge von null oder mehr Unicode-Zeichen als Bezeichner zu verwenden, einschließlich Schlüsselwörter, Leerzeichen, Kommentare, Operatoren und Interpunktionszeichen. Um mehr über Bezeichner in der Sprache M zu erfahren, gehen Sie zu lexikalische Struktur.
Alle Änderungen, die Sie an Ihrer Abfrage über den Power Query-Editor vornehmen, aktualisiert automatisch das M-Skript für Ihre Abfrage. Wenn Sie z. B. das vorherige Bild als Ausgangspunkt verwenden, wird diese Änderung automatisch in der Skriptansicht aktualisiert, wenn Sie den Namen der obersten Zeilen in "Oberste Zeilen" ändern.

Obwohl wir empfehlen, das M-Skript ganz oder größtenteils mit dem Power Query Editor zu erstellen, können Sie Teile Ihres M-Skripts auch manuell hinzufügen oder ändern. Um mehr über die Sprache M zu erfahren, besuchen Sie die offizielle Dokumentseite für die Sprache M.
Hinweis
M-Skript, auch als M-Code bezeichnet, ist ein Begriff, der für jeden Code verwendet wird, der die Power Query M-Sprache verwendet. Im Kontext dieses Artikels bezieht sich M-Skript auch auf den Code, der sich in einer Power Query-Abfrage befindet und über das Fenster des erweiterten Editors oder über die Skriptansicht in der Formelleiste zugänglich ist.
Abfrageauswertung in Power Query
Das folgende Diagramm zeigt den Prozess, der bei der Auswertung einer Abfrage in Power Query abläuft.
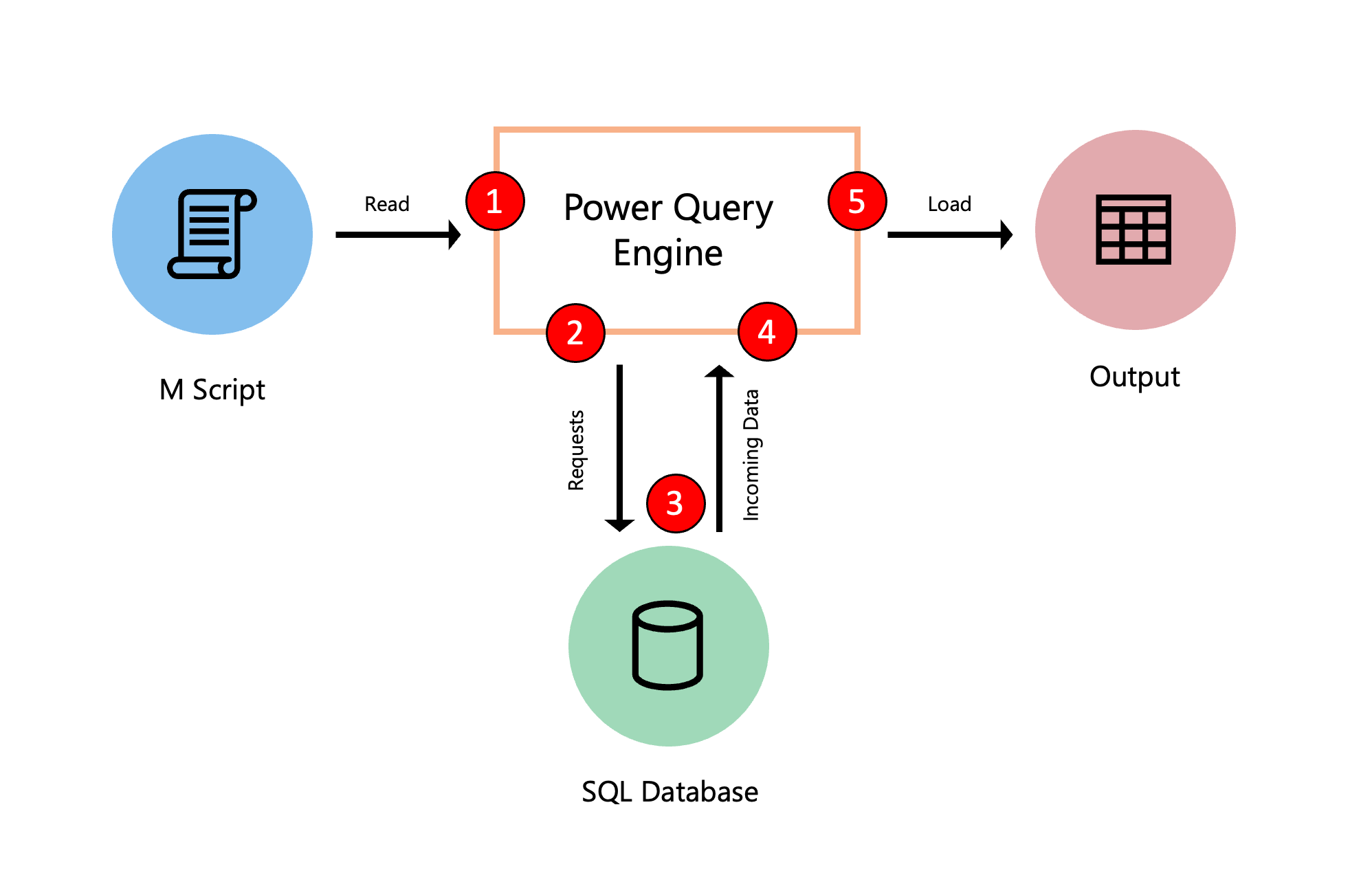
- Das M-Skript, das sich im erweiterten Editor befindet, wird an die Power Query Engine übermittelt. Auch andere wichtige Informationen sind enthalten, z. B. Anmeldedaten und Datenschutzstufen der Datenquelle.
- Power Query bestimmt, welche Daten aus der Datenquelle extrahiert werden müssen, und sendet eine Anfrage an die Datenquelle.
- Die Datenquelle antwortet auf die Anfrage von Power Query, indem sie die angeforderten Daten an Power Query überträgt.
- Power Query empfängt die eingehenden Daten aus der Datenquelle und führt bei Bedarf Transformationen mithilfe der Power Query-Engine durch.
- Die aus dem vorherigen Punkt abgeleiteten Ergebnisse werden in ein Ziel geladen.
Hinweis
Dieses Beispiel zeigt zwar eine Abfrage mit einer SQL-Datenbank als Datenquelle, aber das Konzept gilt für Abfragen mit oder ohne Datenquelle.
Wenn Power Query Ihr M-Skript liest, durchläuft das Skript einen Optimierungsprozess, um Ihre Abfrage effizienter auszuwerten. Dabei wird ermittelt, welche Schritte (Transformationen) aus Ihrer Abfrage in Ihre Datenquelle ausgelagert werden können. Sie bestimmt auch, welche anderen Schritte mit Hilfe der Power Query Engine ausgewertet werden müssen. Dieser Optimierungsprozess wird query foldinggenannt, wobei Power Query versucht, einen möglichst großen Teil der Ausführung auf die Datenquelle zu verlagern, um die Ausführung Ihrer Abfrage zu optimieren.
Wichtig
Alle Regeln der Power Query M Formelsprache (auch bekannt als M-Sprache) werden befolgt. Vor allem lazy evaluation spielt eine wichtige Rolle während des Optimierungsprozesses. In diesem Prozess versteht Power Query, welche spezifischen Transformationen aus Ihrer Abfrage ausgewertet werden müssen. Power Query weiß auch, welche anderen Transformationen nicht ausgewertet werden müssen, weil sie in der Ausgabe Ihrer Abfrage nicht benötigt werden.
Wenn mehrere Quellen beteiligt sind, wird bei der Auswertung der Abfrage außerdem das Datenschutzniveau jeder Datenquelle berücksichtigt. Weitere Informationen: Hinter den Kulissen der Data Privacy Firewall
Das folgende Diagramm veranschaulicht die Schritte, die bei diesem Optimierungsprozess ablaufen.
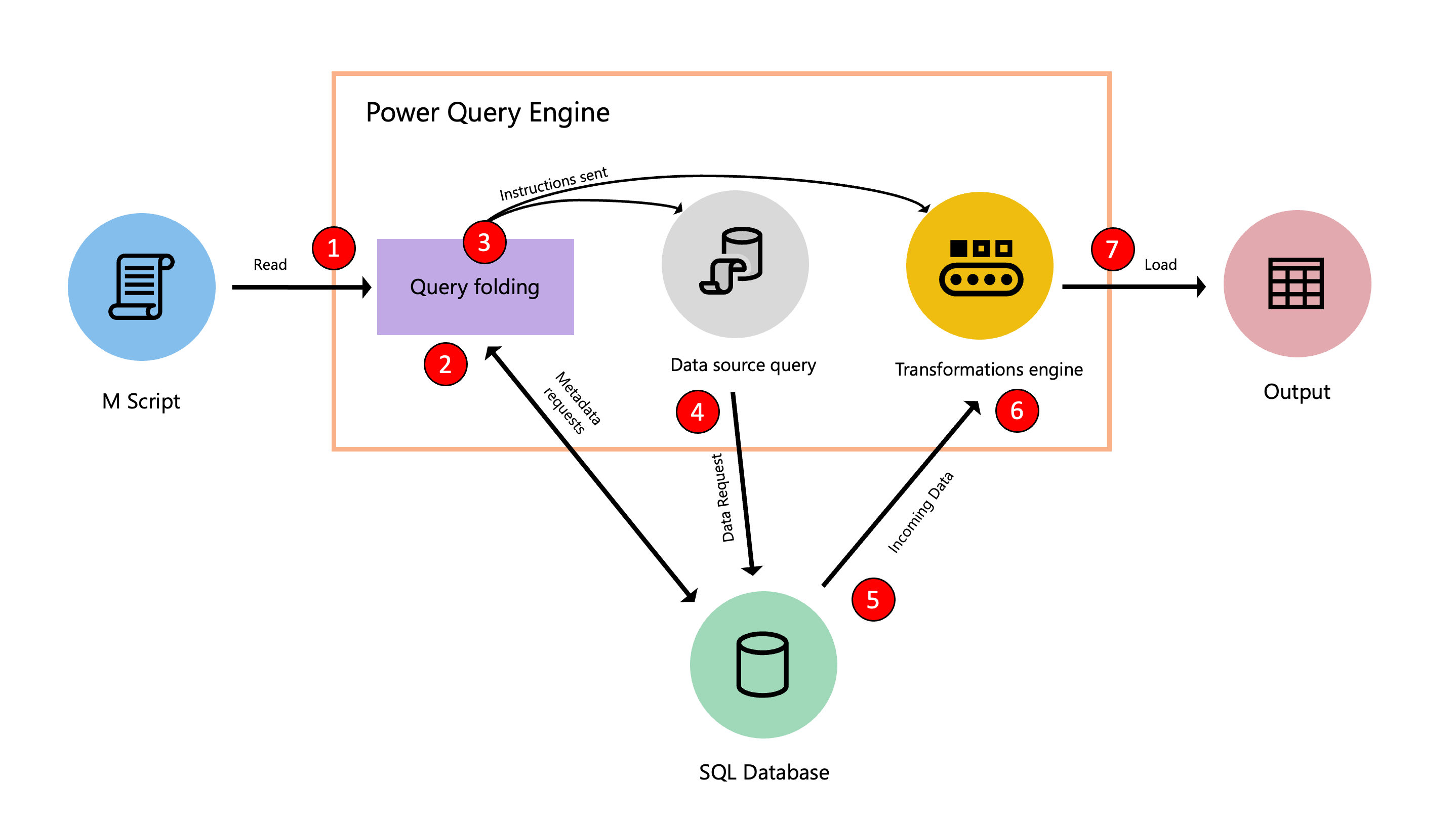
- Das M-Skript, das sich im erweiterten Editor befindet, wird an die Power Query Engine übermittelt. Es werden auch andere wichtige Informationen geliefert, z. B. Anmeldeinformationen und Datenschutzstufen der Datenquelle.
- Der Query Folding-Mechanismus sendet Metadatenanfragen an die Datenquelle, um die Fähigkeiten der Datenquelle, Tabellenschemata, Beziehungen zwischen verschiedenen Tabellen in der Datenquelle und mehr zu ermitteln.
- Auf der Grundlage der empfangenen Metadaten bestimmt der Mechanismus zum Query Folding, welche Informationen aus der Datenquelle zu extrahieren sind und welche Transformationen in der Power Query-Engine vorgenommen werden müssen. Sie sendet die Anweisungen an zwei andere Komponenten, die sich um das Abrufen der Daten aus der Datenquelle und die Umwandlung der eingehenden Daten in der Power Query Engine kümmern, falls erforderlich.
- Sobald die internen Komponenten von Power Query die Anweisungen erhalten, sendet Power Query mithilfe einer Datenquellenabfrage eine Anforderung an die Datenquelle.
- Die Datenquelle empfängt die Anfrage von Power Query und überträgt die Daten an die Power Query Engine.
- Sobald sich die Daten in Power Query befinden, führt die Transformations-Engine in Power Query (auch bekannt als Mashup-Engine) die Transformationen durch, die nicht zurückgefaltet oder in die Datenquelle ausgelagert werden konnten.
- Die aus dem vorherigen Punkt abgeleiteten Ergebnisse werden in ein Ziel geladen.
Hinweis
Abhängig von den Transformationen und datenquellen, die im M-Skript verwendet werden, bestimmt Power Query, ob die eingehenden Daten gestreamt oder gepuffert werden.
Übersicht über die Faltung von Abfragen
Das Ziel des Query Folding ist es, einen möglichst großen Teil der Auswertung einer Abfrage auf eine Datenquelle zu verlagern, die die Transformationen Ihrer Abfrage berechnen kann.
Der Mechanismus zur Abfragezusammenführung erreicht dieses Ziel, indem er Ihr M-Skript in eine Sprache übersetzt, die von Ihrer Datenquelle interpretiert und ausgeführt werden kann. Anschließend wird die Auswertung in Ihre Datenquelle übertragen und das Ergebnis dieser Auswertung an Power Query gesendet.
Dieser Vorgang bietet häufig eine schnellere Abfrageausführung als das Extrahieren aller erforderlichen Daten aus Der Datenquelle und ausführen alle Transformationen, die im Power Query-Modul erforderlich sind.
Wenn Sie die get data experienceverwenden, werden Sie von Power Query durch den Prozess geführt, der Ihnen schließlich eine Verbindung zu Ihrer Datenquelle ermöglicht. Dabei verwendet Power Query eine Reihe von Funktionen in der Sprache M, die als accessing data functionskategorisiert sind. Diese spezifischen Funktionen verwenden Mechanismen und Protokolle, um eine Verbindung zu Ihrer Datenquelle herzustellen, und zwar in einer Sprache, die Ihre Datenquelle verstehen kann.
Die Schritte, die in Ihrer Abfrage folgen, sind jedoch die Schritte oder Transformationen, die der Abfrage-Faltmechanismus zu optimieren versucht. Es wird dann geprüft, ob sie in Ihre Datenquelle ausgelagert werden können, anstatt mit der Power Query Engine verarbeitet zu werden.
Wichtig
Alle Datenquellenfunktionen, die üblicherweise als Source Schritt einer Abfrage angezeigt werden, fragen die Daten in der Datenquelle in ihrer eigenen Sprache ab. Der Mechanismus zum Query Folding wird auf alle Transformationen angewandt, die nach der Datenquellenfunktion auf Ihre Abfrage angewendet werden, sodass sie übersetzt und zu einer einzigen Datenquellenabfrage oder zu vielen Transformationen kombiniert werden können, die in die Datenquelle ausgelagert werden können.
Je nachdem, wie die Abfrage strukturiert ist, kann der Mechanismus zum Query Folding zu drei möglichen Ergebnissen führen:
- Vollständige Abfrage klappbar: Wenn alle Abfragetransformationen an die Datenquelle zurückgegeben werden und nur eine minimale Verarbeitung in der Power Query Engine stattfindet.
- Teilweise Faltung der Abfrage: Wenn nur einige wenige Transformationen in Ihrer Abfrage, aber nicht alle, zurück in die Datenquelle übertragen werden können. In diesem Fall wird nur eine Teilmenge Ihrer Transformationen in Ihrer Datenquelle durchgeführt und der Rest Ihrer Abfragetransformationen erfolgt in der Power Query Engine.
- Kein Query Folding: Wenn die Abfrage Transformationen enthält, die nicht in die native Abfragesprache Ihrer Datenquelle übersetzt werden können, entweder weil die Transformationen nicht unterstützt werden oder weil der Connector das Query Folding nicht unterstützt. In diesem Fall erhält Power Query die Rohdaten aus Ihrer Datenquelle und verwendet die Power Query-Engine, um die gewünschte Ausgabe zu erzielen, indem die erforderlichen Transformationen auf der Ebene der Power Query-Engine verarbeitet werden.
Hinweis
Der Mechanismus zum Query Folding ist hauptsächlich in Connectors für strukturierte Datenquellen verfügbar, wie z. B. Microsoft SQL Server und OData Feed. Während der Optimierungsphase kann es vorkommen, dass die Maschine Schritte in der Abfrage neu anordnet.
Die Nutzung einer Datenquelle, die über mehr Verarbeitungsressourcen verfügt und Abfragen falten kann, kann die Ladezeiten Ihrer Abfragen beschleunigen, da die Verarbeitung in der Datenquelle und nicht in der Power Query-Engine erfolgt.
Zugehöriger Inhalt
Ausführliche Beispiele für die drei möglichen Ergebnisse des Mechanismus zum Query Folding finden Sie unter Query folding examples.
Informationen über Query Folding-Indikatoren im Bereich Angewandte Schritte finden Sie unter Query Foldingsindikatoren