Durchführen von Analysen mit Machine Learning Studio (Classic) unter Verwendung einer SQL Server-Datenbank
GILT FÜR:  Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Unternehmen, die mit lokalen Daten arbeiten, möchten häufig die Vorteile der Skalierung und Flexibilität der Cloud für ihre Machine Learning-Workloads nutzen. Sie möchten jedoch nicht ihre aktuellen Geschäftsprozesse und Workflows durch Verschieben ihrer lokalen Daten in die Cloud unterbrechen. Machine Learning Studio (Classic) unterstützt jetzt das Lesen von Daten aus einer SQL Server-Datenbank und das anschließende Trainieren und Bewerten von Modellen mit diesen Daten. Sie müssen die Daten zwischen der Cloud und dem lokalen Server nicht mehr manuell kopieren und synchronisieren. Stattdessen kann das Modul Daten importieren in Machine Learning Studio (Classic) Daten jetzt direkt aus einer SQL Server-Datenbank für Ihre Trainings- und Bewertungsaufträge lesen.
Dieser Artikel enthält eine Übersicht über das Erfassen von SQL Server-Daten in Machine Learning Studio (Classic). Hierbei wird vorausgesetzt, dass Sie mit Konzepten von Studio (klassisch) wie Arbeitsbereichen, Modulen, Datasets, Experimenten usw. vertraut sind.
Hinweis
Dieses Feature ist nicht für kostenlose Arbeitsbereiche verfügbar. Weitere Informationen zu Machine Learning-Preisen und -Tarifen finden Sie unter Machine Learning Studio (Classic) – Preise.
Installieren der selbstgehosteten Integration Runtime von Azure Data Factory
Wenn Sie in Machine Learning Studio (Classic) auf eine SQL Server-Datenbank zugreifen möchten, müssen Sie die selbstgehostete Integration Runtime von Azure Data Factory (zuvor als Datenverwaltungsgateway bezeichnet) herunterladen und installieren. Beim Konfigurieren der Verbindung in Machine Learning Studio (klassisch) haben Sie die Möglichkeit, die Integration Runtime (IR) im unten beschriebenen Dialogfeld Download and register data gateway herunterzuladen und zu installieren.
Sie können die IR auch im Voraus installieren, indem Sie das MSI-Setup-Paket aus dem Microsoft Download Center herunterladen und ausführen. Der MSI kann auch verwendet werden, um eine bestehende IR auf die neueste Version zu aktualisieren, wobei alle Einstellungen erhalten bleiben.
Für die selbstgehostete Integration Runtime von Azure Data Factory gelten die folgenden Voraussetzungen:
- Die selbstgehostete Integration Runtime von Azure Data Factory erfordert ein 64-Bit-Betriebssystem mit .NET Framework 4.6.1 oder höher.
- Die unterstützten Versionen des Windows-Betriebssystems sind Windows 10, Windows Server 2012, Windows Server 2012 R2 und Windows Server 2016.
- Folgende Konfiguration wird für den Computer mit der IR empfohlen: mindestens 2 GHz, CPU mit 4 Kernen, 8 GB RAM und 80 GB Festplattenspeicher.
- Wenn sich der Hostcomputer im Ruhezustand befindet, reagiert die IR nicht auf Datenanforderungen. Aus diesem Grund sollten Sie vor der Installation der IR einen entsprechenden Energiesparplan auf dem Computer konfigurieren. Wenn der Computer für den Ruhezustand konfiguriert ist, wird bei der IR-Installation eine Meldung angezeigt.
- Weil die Kopieraktivität mit einer bestimmten Häufigkeit ausgeführt wird, folgt auch die Ressourcenverwendung (CPU, Arbeitsspeicher) auf dem Computer dem gleichen Muster mit Spitzen- und Leerlaufzeiten. Die Ressourcenverwendung hängt auch stark von der Datenmenge ab, die verschoben wird. Wenn mehrere Kopieraufträge in Bearbeitung sind, werden Sie feststellen, dass die Ressourcenverwendung während der Spitzenzeiten ansteigt. Zwar ist die oben angegebene minimale Konfiguration technisch ausreichend, doch eine Konfiguration mit mehr Ressourcen ist immer vorteilhaft. Dabei ist Ihre spezifische Auslastung für Datenverschiebungen relevant.
Berücksichtigen Sie beim Einrichten und Verwenden einer selbstgehosteten Integration Runtime von Azure Data Factory Folgendes:
Es darf nur eine Instanz der IR auf einem Computer installiert sein.
Sie können eine einzelne IR für mehrere lokale Datenquellen verwenden.
Sie können mehrere IRs auf verschiedenen Computern mit der gleichen lokalen Datenquelle verbinden.
Sie können eine IR nur für jeweils einen Arbeitsbereich konfigurieren. IRs können zurzeit nicht arbeitsbereichsübergreifend freigegeben werden.
Sie können für einen einzelnen Arbeitsbereich mehrere IRs konfigurieren. Sie möchten z.B. eine IR verwenden, die während der Entwicklung mit Ihren Testdatenquellen verbunden ist, und eine Produktions-IR, wenn Sie bereit sind, den Betrieb aufzunehmen.
Die IR muss sich nicht auf dem gleichen Computer befinden wie die Datenquelle. Durch die Platzierung in der Nähe der Datenquelle verkürzen Sie jedoch die Zeit, die das Gateway benötigt, um eine Verbindung mit der Datenquelle herzustellen. Es wird empfohlen, die IR auf einem anderen Computer als dem Computer zu installieren, auf dem die lokale Datenquelle gehostet wird. So konkurriert das Gateway nicht mit der Datenquelle um Ressourcen.
Wenn Sie bereits eine IR auf dem Computer installiert haben, die Power BI- oder Azure Data Factory-Szenarien unterstützt, installieren Sie eine separate IR für Machine Learning Studio (Classic) auf einem anderen Computer.
Hinweis
Sie können die selbstgehostete Integration Runtime von Azure Data Factory und Power BI Gateway nicht auf dem gleichen Computer ausführen.
Sie müssen die selbstgehostete Integration Runtime von Azure Data Factory auch dann für Machine Learning Studio (Classic) verwenden, wenn Sie für andere Daten Azure ExpressRoute verwenden. Behandeln Sie Ihre Datenquelle wie eine lokale Datenquelle (die sich hinter einer Firewall befindet), selbst wenn Sie ExpressRoute verwenden. Verwenden Sie die selbstgehostete Integration Runtime von Azure Data Factory, um eine Verbindung zwischen Machine Learning und Datenquelle herzustellen.
Ausführliche Informationen zu Installationsvoraussetzungen, Installationsschritten und Tipps zur Problembehandlung finden Sie im Artikel Integration Runtime in Data Factory.
Erfassen von Daten aus einer SQL Server-Datenbank in Machine Learning
In dieser exemplarischen Vorgehensweise richten Sie eine Integration Runtime von Azure Data Factory in einem Azure Machine Learning-Arbeitsbereich ein, konfigurieren sie und lesen dann Daten aus einer SQL Server-Datenbank.
Tipp
Bevor Sie beginnen, deaktivieren Sie den Popupblocker Ihres Browsers für studio.azureml.net. Wenn Sie den Browser Google Chrome verwenden, laden Sie eines der Plug-Ins herunter, die im Google Chrome WebStore unter ClickOnce-App-Erweiterungenverfügbar sind, und installieren Sie es.
Hinweis
Die selbstgehostete Integration Runtime von Azure Data Factory wurde zuvor als Datenverwaltungsgateway bezeichnet. Im Schritt-für-Schritt-Tutorial wird sie weiterhin als Gateway bezeichnet.
Schritt 1: Erstellen eines Gateways
Der erste Schritt besteht im Erstellen und Einrichten des Gateways für den Zugriff auf die SQL-Datenbank.
Melden Sie sich bei Machine Learning Studio (Classic) an, und wählen Sie den Arbeitsbereich aus, in dem Sie arbeiten möchten.
Klicken Sie links auf das Blatt SETTINGS und dann oben auf die Registerkarte DATA GATEWAYS.
Klicken Sie am unteren Bildschirmrand auf NEW DATA GATEWAY .
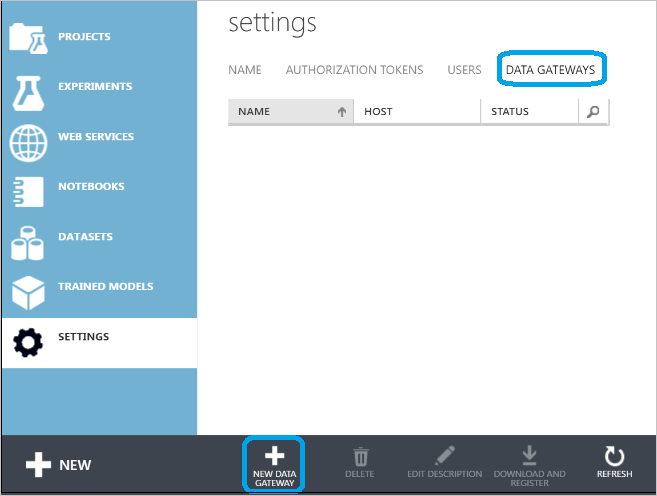
Geben Sie im Dialogfeld New data gateway den Gateway Name ein, und fügen Sie mit Description optional eine Beschreibung hinzu. Klicken Sie auf den Pfeil in der unteren rechten Ecke, um mit dem nächsten Schritt der Konfiguration fortzufahren.
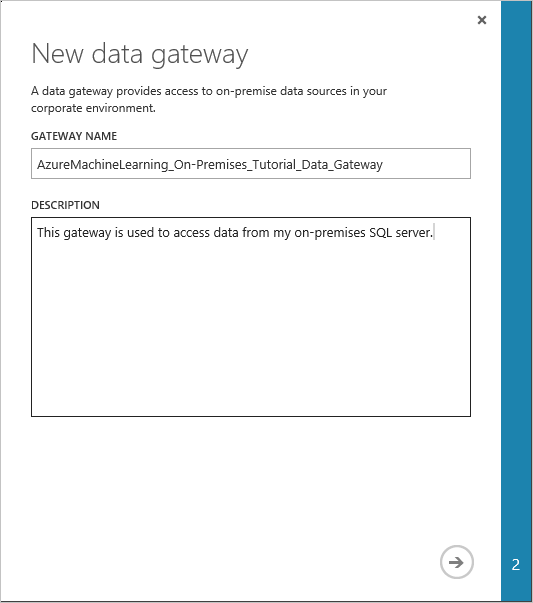
Kopieren Sie im Dialogfeld „Download and register data gateway“ den GATEWAY REGISTRATION KEY in die Zwischenablage.
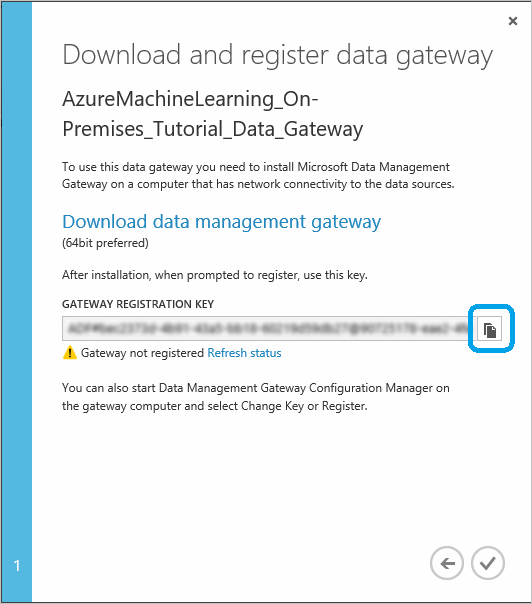
Wenn Sie das Microsoft-Datenverwaltungsgateway noch nicht heruntergeladen und installiert haben, klicken Sie auf Download data management gateway. So gelangen Sie zum Microsoft Download Center, in dem Sie die benötigte Gatewayversion auswählen können, um sie herunterzuladen und zu installieren. Ausführliche Informationen zu Installationsvoraussetzungen, Installationsschritten und Tipps zur Problembehandlung finden Sie in den Anfangsabschnitten des Artikels Verschieben von Daten zwischen lokalen Quellen und der Cloud mit dem Datenverwaltungsgateway.
Nachdem das Gateway installiert ist, wird der Konfigurations-Manager des Datenverwaltungsgateways geöffnet und das Dialogfeld Gateway registrieren angezeigt. Fügen Sie den Gatewayregistrierungsschlüssel ein, den Sie in die Zwischenablage kopiert haben, und klicken Sie auf Registrieren.
Wenn Sie bereits ein Gateway installiert haben, führen Sie den Konfigurations-Manager für Datenverwaltungsgateways aus. Klicken Sie auf Schlüssel ändern, fügen Sie den Gatewayregistrierungsschlüssel ein, den Sie im vorherigen Schritt in die Zwischenablage kopiert haben, und klicken Sie auf OK.
Wenn die Installation abgeschlossen ist, wird das Dialogfeld Gateway registrieren für den Konfigurations-Manager des Microsoft-Datenverwaltungsgateways angezeigt. Fügen Sie den GATEWAYREGISTRIERUNGSSCHLÜSSEL ein, den Sie im vorherigen Schritt in die Zwischenablage kopiert haben, und klicken Sie auf Registrieren.
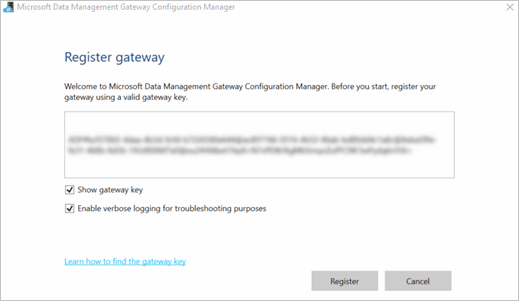
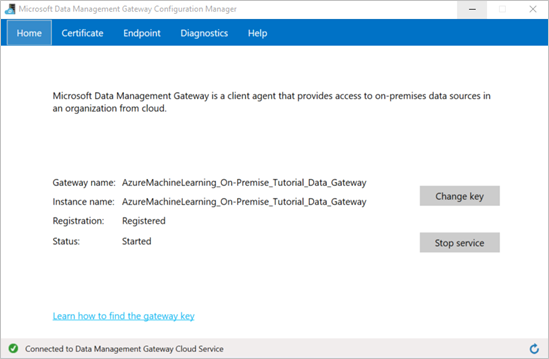
Die Gatewaykonfiguration ist abgeschlossen, wenn die folgenden Werte auf der Registerkarte Startseite des Konfigurations-Managers des Microsoft-Datenverwaltungsgateways festgelegt wurden:
Gatewayname und Instanzname sind auf den Namen des Gateways festgelegt.
Registrierung wird auf Registriert festgelegt.
Status wird auf Gestartet festgelegt.
Die Statusleiste im unteren Bereich zeigt Connected to Data Management Gateway Cloud Service sowie ein grünes Häkchen an.
Machine Learning Studio (Classic) wird bei erfolgreicher Registrierung auch aktualisiert.
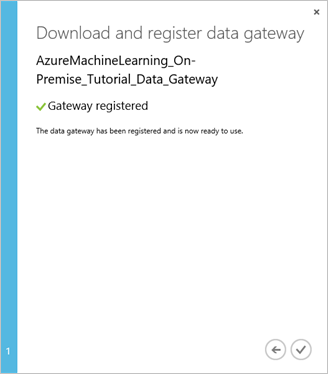
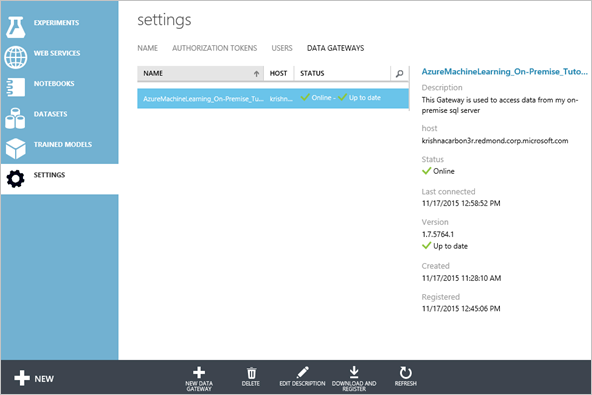
Klicken Sie im Dialogfeld Datengateway herunterladen und registrieren auf das Häkchen, um das Setup abzuschließen. Auf der Seite Einstellungen wird der Gatewaystatus „Online“ angezeigt. Im rechten Bereich finden Sie Status- und andere nützliche Informationen.
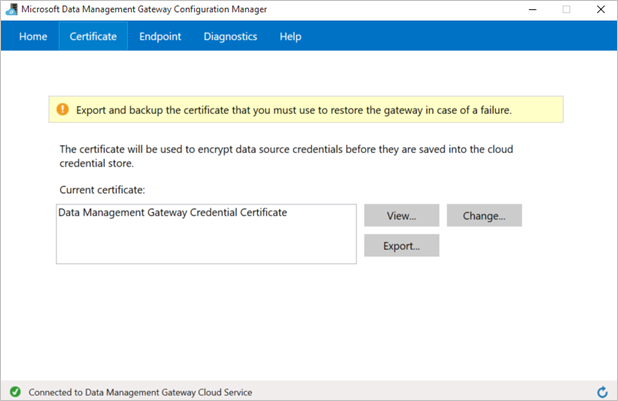
Wechseln Sie im Microsoft Datenverwaltung Gateway Configuration Manager zur Registerkarte "Zertifikat". Das auf dieser Registerkarte angegebene Zertifikat dient zum Verschlüsseln/Entschlüsseln von Anmeldeinformationen für den lokalen Datenspeicher, den Sie im Portal angeben. Dieses Zertifikat ist das Standardzertifikat. Microsoft empfiehlt Ihnen, dies in Ihr persönliches Zertifikat zu ändern, das Sie in Ihrem Zertifikatsverwaltungssystem sichern. Klicken Sie auf Ändern , um Ihr eigenes Zertifikat zu verwenden.
(Optional) Wenn Sie die ausführliche Protokollierung aktivieren möchten, um Probleme mit dem Gateway behandeln zu können, wechseln Sie im Konfigurations-Manager des Microsoft-Datenverwaltungsgateways zur Registerkarte Diagnose, und aktivieren Sie die Option Ausführliche Protokollierung für die Problembehandlung aktivieren. Die Protokollinformationen finden Sie in der Windows-Ereignisanzeige unter dem Knoten Anwendungs- und Dienstprotokolle ->Datenverwaltungsgateway. Sie können die Verbindung mit einer lokalen Datenquelle über das Gateway auch über die Registerkarte Diagnose testen.
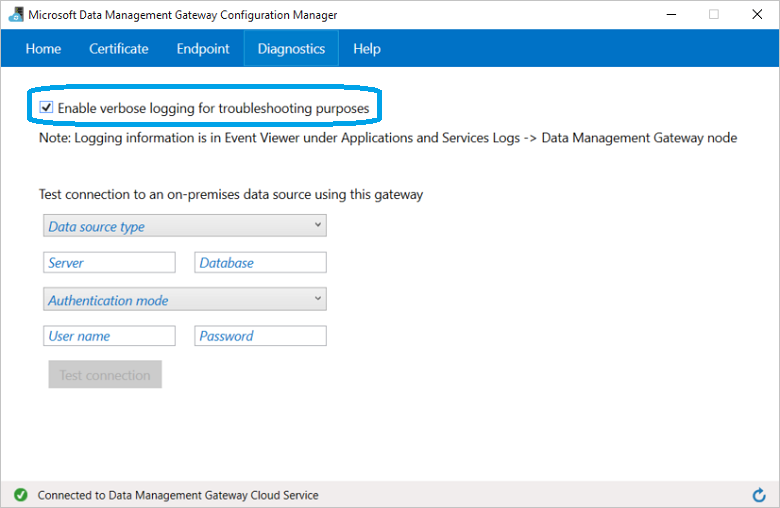
Damit ist die Einrichtung des Gateways in Machine Learning Studio (Classic) abgeschlossen. Nun können Sie Ihre lokalen Daten nutzen.
Sie können in Studio (klassisch) mehrere Gateways für jeden Arbeitsbereich erstellen und einrichten. Nehmen Sie an, Sie haben ein Gateway, das Sie während der Entwicklung mit den Testdatenquellen verbinden möchten, und ein anderes Gateway für Ihre Produktionsdatenquellen. Machine Learning Studio (Classic) bietet Ihnen die Flexibilität, abhängig von Ihrer Unternehmensumgebung mehrere Gateways einzurichten. Derzeit kann ein Gateway nicht in verschiedenen Arbeitsbereichen genutzt werden, und auf einem einzelnen Computer kann nur ein einzelnes Gateway installiert werden. Weitere Informationen finden Sie unter Verschieben von Daten zwischen lokalen Quellen und der Cloud mit dem Datenverwaltungsgateway.
Schritt 2: Verwenden des Gateways zum Lesen von Daten aus einer lokalen Datenquelle
Nachdem Sie das Gateway eingerichtet haben, können Sie einem Experiment, das die Daten aus einer SQL Server-Datenbank eingibt, ein Import Data-Modul hinzufügen.
Wählen Sie in Machine Learning Studio (klassisch) die Registerkarte EXPERIMENTS, klicken Sie in der linken unteren Ecke auf +NEW, und wählen Sie Blank Experiment (oder eines von mehreren verfügbaren Beispielexperimenten).
Suchen Sie das Modul Import Data , und ziehen Sie es in den Experimentbereich.
Klicken Sie unter dem Bereich auf Save as . Geben Sie Machine Learning Studio (classic) On-Premises SQL Server Tutorial als Name des Experiments ein, wählen Sie den Arbeitsbereich aus, und klicken Sie auf das Häkchen.
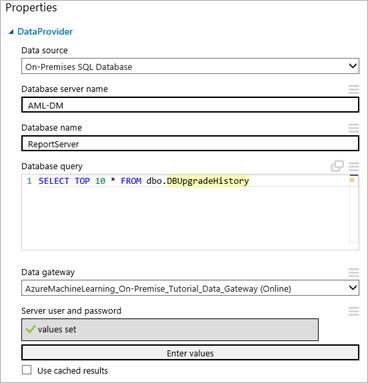
Klicken Sie auf das Import Data-Modul, um es auszuwählen, wählen Sie dann rechts neben dem Bereich in Properties in der Dropdownliste Data source „On-Premises SQL Database“ aus.
Wählen Sie das Data gateway , das sie installiert und registriert haben. Sie können ein weiteres Gateway einrichten, indem Sie „(add new Data Gateway…)“ auswählen.
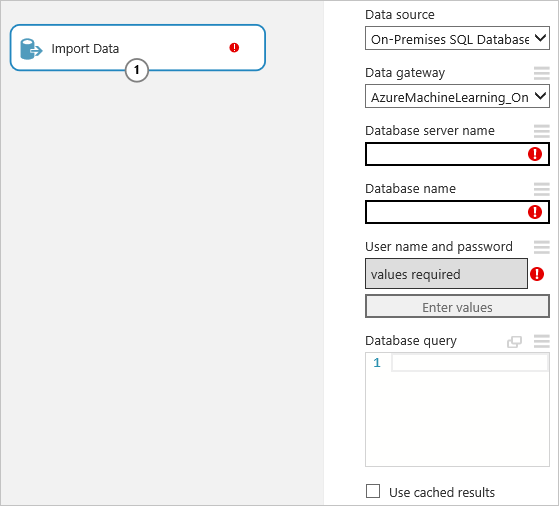
Geben Sie Database server name und Database name der SQL-Datenbank ein, zusammen mit der SQL-Database query, die Sie ausführen möchten.
Klicken Sie unter User name and password auf Enter values, und geben Sie Ihre Datenbank-Anmeldeinformationen ein. Je nach Ihrer SQL Server-Konfiguration können Sie die integrierte Windows-Authentifizierung oder die SQL Server-Authentifizierung verwenden.
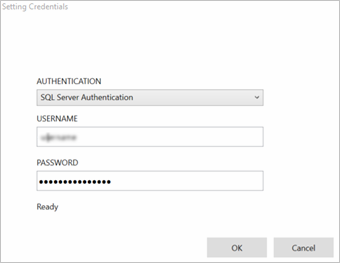
Die Meldung „values required“ ändert sich in „values set“ mit einem grünen Häkchen. Sie müssen die Anmeldeinformationen nur einmal eingeben, solange sich die Datenbankinformationen oder das Kennwort nicht ändern. Machine Learning Studio (Classic) verwendet das Zertifikat, das Sie bei der Installation des Gateways zum Verschlüsseln der Anmeldeinformationen in der Cloud bereitgestellt haben. Azure speichert lokale Anmeldeinformationen nie unverschlüsselt.
Klicken Sie auf RUN , um das Experiment auszuführen.
Nach Abschluss der Ausführung des Experiments können Sie die Daten, die Sie aus der Datenbank importiert haben, durch Klicken auf den Ausgabeport des Import Data-Moduls und Auswählen von Visualize visuell darstellen.
Wenn Sie die Entwicklung des Experiments abgeschlossen haben, können Sie Ihr Modell bereitstellen und in Betrieb nehmen. Mit dem Batchausführungsdienst werden Daten aus der im Import Data-Modul konfigurierten SQL Server-Datenbank gelesen und für die Bewertung verwendet. Sie können zwar den Request Response Service zur Bewertung lokaler Daten verwenden, aber Microsoft empfiehlt stattdessen die Verwendung des Excel-Add-Ins . Derzeit wird das Schreiben in eine SQL Server-Datenbank über Export Data weder in Ihren Experimenten noch in veröffentlichten Webdiensten unterstützt.