Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie Azure Databricks registrieren und wie Sie sich in Microsoft Purview authentifizieren und mit Azure Databricks interagieren. Weitere Informationen zu Microsoft Purview finden Sie im Einführungsartikel.
Unterstützte Funktionen
Scanfunktionen
| Metadatenextraktion | Vollständiger Scan | Inkrementelle Überprüfung | Bereichsbezogene Überprüfung |
|---|---|---|---|
| Ja | Ja | Nein | Ja |
Hinweis
Dieser Connector enthält Metadaten aus dem Hive-Metastore im Arbeitsbereich von Azure Databricks. Informationen zum Überprüfen von Metadaten in Azure Databricks Unity Catalog finden Sie unter Azure Databricks Unity Catalog-Connector.
Beim Überprüfen des Azure Databricks Hive-Metastores unterstützt Microsoft Purview Folgendes:
Extrahieren von technischen Metadaten, einschließlich:
- Azure Databricks-Arbeitsbereich
- Hive-Server
- Datenbanken
- Tabellen, einschließlich der Spalten, Fremdschlüssel, Eindeutigkeitseinschränkungen und Speicherbeschreibung
- Ansichten, einschließlich der Spalten und der Speicherbeschreibung
Abrufen der Beziehung zwischen externen Tabellen und Azure Data Lake Storage Gen2-/Azure-Blobressourcen (externe Speicherorte).
Abrufen der statischen Herkunft zwischen Tabellen und Sichten basierend auf der Ansichtsdefinition.
Beim Einrichten der Überprüfung können Sie den gesamten Hive-Metastore überprüfen oder die Überprüfung auf eine Teilmenge von Schemas festlegen.
Vergleich mit der Überprüfung über einen generischen Hive-Metastore-Connector für den Fall, dass Sie ihn zuvor zum Scannen von Azure Databricks verwenden:
- Sie können die Überprüfung für Azure Databricks-Arbeitsbereiche ohne direkten HMS-Zugriff direkt einrichten. Es verwendet das persönliche Databricks-Zugriffstoken für die Authentifizierung und stellt eine Verbindung mit einem Cluster her, um die Überprüfung durchzuführen.
- Die Databricks-Arbeitsbereichsinformationen werden erfasst.
- Die Beziehung zwischen Tabellen und Speicherressourcen wird erfasst.
Weitere Funktionen
Klassifizierungen, Vertraulichkeitsbezeichnungen, Richtlinien, Datenherkunft und Liveansicht finden Sie in der Liste der unterstützten Funktionen.
Bekannte Einschränkungen
Wenn das Objekt aus der Datenquelle gelöscht wird, wird das entsprechende Objekt in Microsoft Purview bei der nachfolgenden Überprüfung derzeit nicht automatisch entfernt.
Voraussetzungen
Sie müssen über ein Azure-Konto mit einem aktiven Abonnement verfügen. Erstellen Sie kostenlos ein Konto.
Sie müssen über ein aktives Microsoft Purview-Konto verfügen.
Sie benötigen eine Azure-Key Vault und um Microsoft Purview-Berechtigungen für den Zugriff auf Geheimnisse zu erteilen.
Sie benötigen Datenquellenadministrator- und Datenleserberechtigungen, um eine Quelle zu registrieren und im Microsoft Purview-Governanceportal zu verwalten. Weitere Informationen zu Berechtigungen finden Sie unter Zugriffssteuerung in Microsoft Purview.
Richten Sie die neueste selbstgehostete Integration Runtime ein. Weitere Informationen finden Sie unter Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime. Die minimal unterstützte selbstgehostete Integration Runtime Version ist 5.20.8227.2.
Stellen Sie sicher, dass JDK 11 auf dem Computer installiert ist, auf dem die selbstgehostete Integration Runtime installiert ist. Starten Sie den Computer neu, nachdem Sie das JDK neu installiert haben, damit es wirksam wird.
Stellen Sie sicher, dass Visual C++ Redistributable (Version Visual Studio 2012 Update 4 oder höher) auf dem Computer installiert ist, auf dem die selbstgehostete Integration Runtime ausgeführt wird. Wenn Sie dieses Update nicht installiert haben, laden Sie es jetzt herunter.
In Ihrem Azure Databricks-Arbeitsbereich:
Generieren Sie ein persönliches Zugriffstoken, und speichern Sie es als Geheimnis in Azure Key Vault.
Erstellen Sie einen Cluster. Notieren Sie sich die Cluster-ID. Sie finden sie im Azure Databricks-Arbeitsbereich –> Compute –> Ihr Cluster –> Tags –> Automatisch hinzugefügte Tags .>
ClusterIdStellen Sie sicher, dass der Benutzer über die folgenden Berechtigungen verfügt , um eine Verbindung mit dem Azure Databricks-Cluster herzustellen:
- Die Berechtigung kann anfügen , um eine Verbindung mit dem ausgeführten Cluster herzustellen.
- Kann die Berechtigung neustarten , um den Start des Clusters automatisch auszulösen, wenn sein Zustand beim Herstellen einer Verbindung beendet wird.
Registrieren
In diesem Abschnitt wird beschrieben, wie Sie einen Azure Databricks-Arbeitsbereich in Microsoft Purview mithilfe des Microsoft Purview-Governanceportals registrieren.
Wechseln Sie zu Ihrem Microsoft Purview-Konto.
Wählen Sie im linken Bereich Data Map aus.
Wählen Sie Registrieren aus.
Wählen Sie unter Quellen registrieren die Option Azure Databricks>Weiter aus.
Gehen Sie auf dem Bildschirm Quellen registrieren (Azure Databricks) wie folgt vor:
Geben Sie unter Name einen Namen ein, den Microsoft Purview als Datenquelle auflistet.
Wählen Sie unter Name des Azure-Abonnements und Databricks-Arbeitsbereichs in der Dropdownliste das Abonnement und den Arbeitsbereich aus, den Sie überprüfen möchten. Die Databricks-Arbeitsbereichs-URL wird automatisch aufgefüllt.
Wählen Sie eine Sammlung aus der Liste aus.
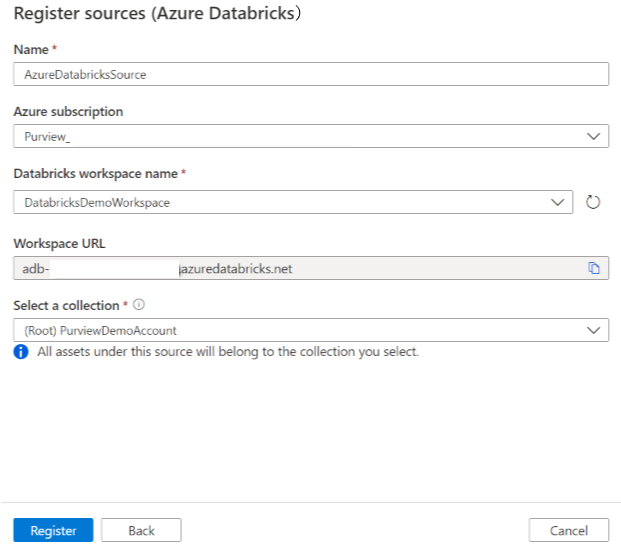
Klicken Sie auf Fertigstellen.
Überprüfung
Tipp
So beheben Sie Probleme mit der Überprüfung:
- Vergewissern Sie sich, dass Sie alle Voraussetzungen erfüllt haben.
- Lesen Sie unsere Dokumentation zur Problembehandlung bei Der Überprüfung.
Führen Sie die folgenden Schritte aus, um Azure Databricks zu überprüfen, um Ressourcen automatisch zu identifizieren. Weitere Informationen zum Scannen im Allgemeinen finden Sie unter Scans und Erfassung in Microsoft Purview.
Wählen Sie im Management Center Integration Runtimes aus. Stellen Sie sicher, dass eine selbstgehostete Integration Runtime eingerichtet ist. Wenn sie nicht eingerichtet ist, führen Sie die Schritte unter Erstellen und Verwalten einer selbstgehosteten Integration Runtime aus.
Wechseln Sie zu Quellen.
Wählen Sie die registrierte Azure Databricks-Instanz aus.
Wählen Sie + Neuer Scan aus.
Geben Sie die folgenden Details an:
Name: Geben Sie einen Namen für die Überprüfung ein.
Extraktionsmethode: Geben Sie an, dass Metadaten aus Hive Metastore oder Unity Catalog extrahiert werden sollen. Wählen Sie Hive-Metastore aus.
Herstellen einer Verbindung über Integration Runtime: Wählen Sie die konfigurierte selbstgehostete Integration Runtime aus.
Anmeldeinformationen: Wählen Sie die Anmeldeinformationen aus, um eine Verbindung mit Ihrer Datenquelle herzustellen. Stellen Sie folgendes sicher:
- Wählen Sie Beim Erstellen von Anmeldeinformationen Zugriffstokenauthentifizierung aus.
- Geben Sie den geheimen Namen des persönlichen Zugriffstokens an, das Sie unter Voraussetzungen im entsprechenden Feld erstellt haben.
Weitere Informationen finden Sie unter Anmeldeinformationen für die Quellauthentifizierung in Microsoft Purview.
Cluster-ID: Geben Sie die Cluster-ID an, mit der Microsoft Purview eine Verbindung herstellt und die Überprüfung unterstützt. Sie finden sie im Azure Databricks-Arbeitsbereich –> Compute –> Ihr Cluster –> Tags –> Automatisch hinzugefügte Tags .>
ClusterIdBereitstellungspunkte: Geben Sie den Bereitstellungspunkt und die Azure Storage-Quellspeicherortzeichenfolge an, wenn Sie externen Speicher manuell in Databricks eingebunden haben. Verwenden Sie das Format
/mnt/<path>=abfss://<container>@<adls_gen2_storage_account>.dfs.core.windows.net/;/mnt/<path>=wasbs://<container>@<blob_storage_account>.blob.core.windows.net. Es wird verwendet, um die Beziehung zwischen Tabellen und den entsprechenden Speicherressourcen in Microsoft Purview zu erfassen. Diese Einstellung ist optional. Wenn sie nicht angegeben ist, wird eine solche Beziehung nicht abgerufen.Sie können die Liste der Bereitstellungspunkte in Ihrem Databricks-Arbeitsbereich abrufen, indem Sie den folgenden Python-Befehl in einem Notebook ausführen:
dbutils.fs.mounts()Alle Bereitstellungspunkte werden wie folgt gedruckt:
[MountInfo(mountPoint='/databricks-datasets', source='databricks-datasets', encryptionType=''), MountInfo(mountPoint='/mnt/ADLS2', source='abfss://samplelocation1@azurestorage1.dfs.core.windows.net/', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-tracking', source='databricks/mlflow-tracking', encryptionType=''), MountInfo(mountPoint='/mnt/Blob', source='wasbs://samplelocation2@azurestorage2.blob.core.windows.net', encryptionType=''), MountInfo(mountPoint='/databricks-results', source='databricks-results', encryptionType=''), MountInfo(mountPoint='/databricks/mlflow-registry', source='databricks/mlflow-registry', encryptionType=''), MountInfo(mountPoint='/', source='DatabricksRoot', encryptionType='')]Geben Sie in diesem Beispiel Folgendes als Bereitstellungspunkte an:
/mnt/ADLS2=abfss://samplelocation1@azurestorage1.dfs.core.windows.net/;/mnt/Blob=wasbs://samplelocation2@azurestorage2.blob.core.windows.netSchema: Die Teilmenge der zu importierenden Schemas, ausgedrückt als durch Semikolons getrennte Liste von Schemas. Beispiel:
schema1;schema2. Alle Benutzerschemas werden importiert, wenn diese Liste leer ist. Alle Systemschemas und -objekte werden standardmäßig ignoriert.Zulässige Schemanamensmuster können statische Namen sein oder Denkplatzhalter %enthalten. Beispiel:
A%;%B;%C%;D- Beginnen Sie mit A oder
- Enden Sie mit B oder
- C oder enthalten
- Gleich D
Die Verwendung von NOT- und Sonderzeichen ist nicht zulässig.
Hinweis
Dieser Schemafilter wird für selbstgehostete Integration Runtime Version 5.32.8597.1 und höher unterstützt.
Maximal verfügbarer Arbeitsspeicher: Maximal verfügbarer Arbeitsspeicher (in Gigabyte) auf dem Computer des Kunden für die Überprüfungsprozesse. Dieser Wert hängt von der Größe von Azure Databricks ab, die gescannt werden soll.
Hinweis
Geben Sie als Faustregel 1 GB Arbeitsspeicher für jeweils 1.000 Tabellen an.
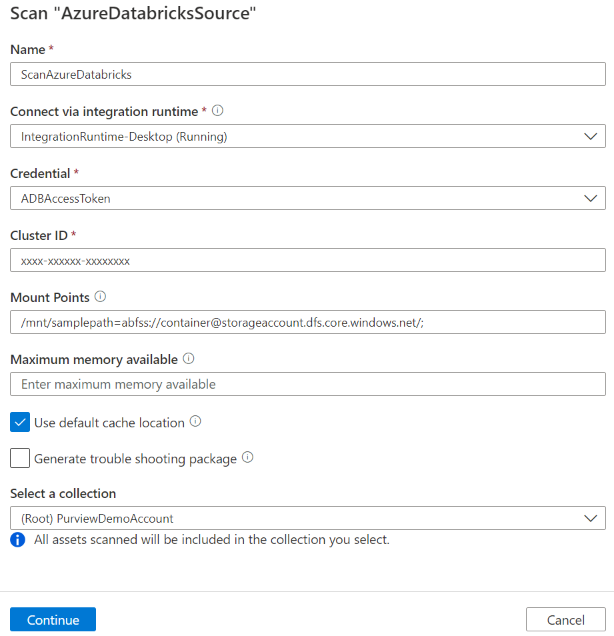
Wählen Sie Weiter.
Wählen Sie für Scantrigger aus, ob Sie einen Zeitplan einrichten oder die Überprüfung einmal ausführen möchten.
Überprüfen Sie Ihre Überprüfung, und wählen Sie Speichern und ausführen aus.
Nachdem die Überprüfung erfolgreich abgeschlossen wurde, erfahren Sie, wie Sie Azure Databricks-Ressourcen durchsuchen und durchsuchen.
Anzeigen Ihrer Überprüfungen und Überprüfungsausführungen
So zeigen Sie vorhandene Überprüfungen an:
- Wechseln Sie zum Microsoft Purview-Portal. Wählen Sie im linken Bereich Data Map aus.
- Wählen Sie die Datenquelle aus. Sie können eine Liste der vorhandenen Überprüfungen für diese Datenquelle unter Zuletzt verwendete Überprüfungen anzeigen, oder Sie können alle Überprüfungen auf der Registerkarte Scans anzeigen.
- Wählen Sie die Überprüfung aus, die Ergebnisse enthält, die Sie anzeigen möchten. Im Bereich werden alle vorherigen Überprüfungsausführungen zusammen mit den status und Metriken für jede Überprüfungsausführung angezeigt.
- Wählen Sie die Ausführungs-ID aus, um die Details der Überprüfungsausführung zu überprüfen.
Verwalten ihrer Überprüfungen
So bearbeiten, abbrechen oder löschen Sie eine Überprüfung:
Wechseln Sie zum Microsoft Purview-Portal. Wählen Sie im linken Bereich Data Map aus.
Wählen Sie die Datenquelle aus. Sie können eine Liste der vorhandenen Überprüfungen für diese Datenquelle unter Zuletzt verwendete Überprüfungen anzeigen, oder Sie können alle Überprüfungen auf der Registerkarte Scans anzeigen.
Wählen Sie die Überprüfung aus, die Sie verwalten möchten. Anschließend können Sie:
- Bearbeiten Sie die Überprüfung, indem Sie Überprüfung bearbeiten auswählen.
- Brechen Sie eine laufende Überprüfung ab, indem Sie Überprüfungsausführung abbrechen auswählen.
- Löschen Sie Ihre Überprüfung, indem Sie Überprüfung löschen auswählen.
Hinweis
- Durch das Löschen Ihrer Überprüfung werden keine Katalogressourcen gelöscht, die aus vorherigen Überprüfungen erstellt wurden.
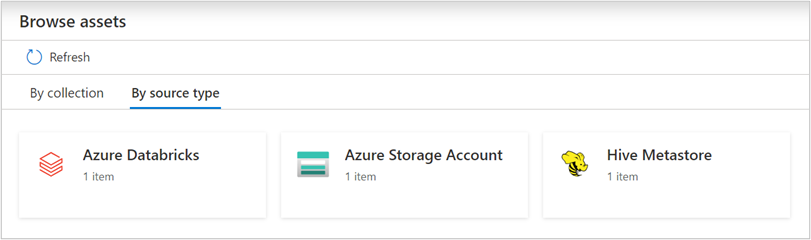
Durchsuchen und Durchsuchen von Ressourcen
Nachdem Sie Ihre Azure Databricks-Instanz überprüft haben, können Sie Unified Catalog durchsuchen oder Unified Catalog suchen, um die Ressourcendetails anzuzeigen.
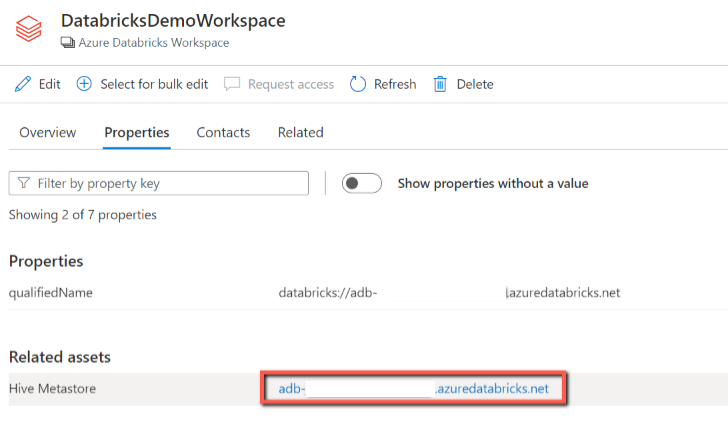
In der Databricks-Arbeitsbereichsressource finden Sie den zugeordneten Hive-Metastore und die Tabellen/Sichten, umgekehrt gilt ebenfalls.
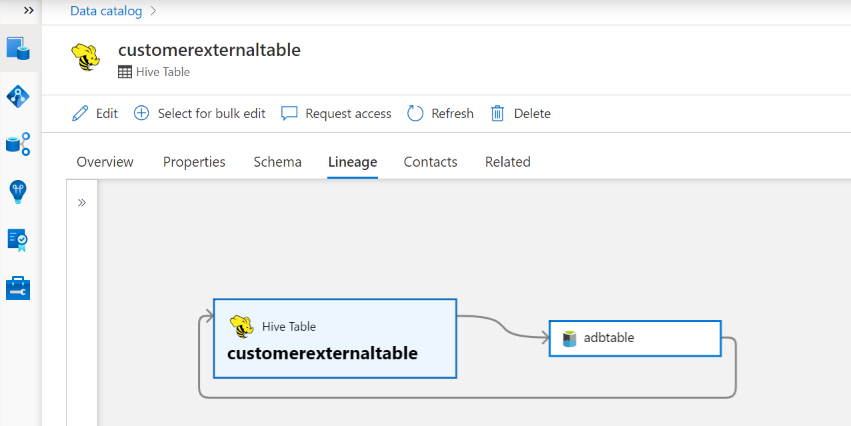
Herkunft
Informationen zu den unterstützten Azure Databricks-Szenarien finden Sie im Abschnitt Unterstützte Funktionen . Weitere Informationen zur Herkunft im Allgemeinen finden Sie im Benutzerhandbuch zur Datenherkunft und -herkunft.
Wechseln Sie zur Registerkarte Hive-Tabelle/Ansichtsobjekt –> Herkunft. Sie können die Ressourcenbeziehung anzeigen, falls zutreffend. Für die Beziehung zwischen Tabellen- und externen Speicherressourcen wird das Hive-Tabellenobjekt angezeigt, und das Speicherasset ist direkt bidirektional verbunden, da sie sich gegenseitig beeinflussen. Wenn Sie den Bereitstellungspunkt in der Create Table-Anweisung verwenden, müssen Sie die Bereitstellungspunktinformationen in den Überprüfungseinstellungen angeben, um eine solche Beziehung zu extrahieren.
Nächste Schritte
Nachdem Sie Ihre Quelle registriert haben, verwenden Sie die folgenden Leitfäden, um mehr über Microsoft Purview und Ihre Daten zu erfahren: