Einführung in die App-Bereitstellung in SQL Server-Big Data-Clustern
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Es handelt sich hierbei um die Bereitstellung von Anwendungen in SQL Server-Big Data-Clustern durch die Bereitstellung von Schnittstellen zum Erstellen, Verwalten und Ausführen von Anwendungen. Anwendungen, die in einem Big Data-Cluster bereitgestellt werden, profitieren von der Rechenleistung des Clusters und können auf die Daten zugreifen, die im Cluster verfügbar sind. Dadurch wird die Skalierbarkeit und Leistung der Anwendungen erhöht, während die Anwendungen, in denen sich die Daten befinden, verwaltet werden. Die unterstützten Anwendungsruntimes für Big Data-Cluster in SQL Server sind R, Python, dtexec und MLeap.
In den folgenden Abschnitten werden die Architektur und die Funktionalität der Anwendungsbereitstellung beschrieben.
Architektur der Anwendungsbereitstellung
Die Anwendungsbereitstellung besteht aus einem Controller und App-Runtime-Handlern. Beim Erstellen einer Anwendung wird eine Spezifikationsdatei (spec.yaml) bereitgestellt. Diese spec.yaml-Datei enthält alles, was der Controller wissen muss, um die Anwendung erfolgreich bereitzustellen. Im Folgenden finden Sie ein Beispiel für den Inhalt für spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
Der Controller überprüft die runtime, die in der spec.yaml-Datei angegeben ist, und ruft den entsprechenden Runtimehandler auf. Der Runtimehandler erstellt die Anwendung. Zuerst wird ein Kubernetes-ReplicaSet erstellt, das einen oder mehrere Pods enthält, von denen jeder die bereitzustellende Anwendung enthält. Die Anzahl von Pods wird durch den replicas-Parametersatz definiert, der in der spec.yaml-Datei für die Anwendung festgelegt ist. Jeder Pod kann über einen von mehreren Pools verfügen. Die Anzahl von Pools wird durch den poolsize-Parametersatz definiert, der in der spec.yaml-Datei festgelegt ist.
Diese Einstellungen bestimmen die Anzahl der Anforderungen, die von der Bereitstellung parallel verarbeitet werden können. Die maximale Anzahl von Anforderungen zu einem bestimmten Zeitpunkt entspricht dem Produkt aus replicas und poolsize. Wenn Sie über 5 Replikate und 2 Pools pro Replikat verfügen, kann die Bereitstellung 10 Anforderungen parallel verarbeiten. Das folgende Bild zeigt eine grafische Darstellung von replicas und poolsize:
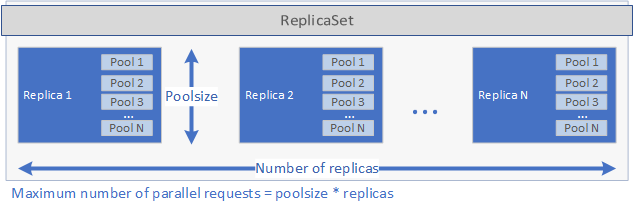
Nachdem das ReplicaSet erstellt und die Pods gestartet wurden, wird ein Cron-Auftrag erstellt, wenn ein schedule in der spec.yaml-Datei festgelegt wurde. Zum Schluss wird ein Kubernetes-Dienst erstellt, der zum Verwalten und Ausführen der Anwendung verwendet werden kann (siehe unten).
Wenn eine Anwendung ausgeführt wird, leitet der Kubernetes-Dienst für die Anwendung die Anforderungen an ein Replikat weiter und gibt die Ergebnisse zurück.
Hinweise für Anwendungsbereitstellungen in OpenShift
SQL Server 2019 CU5 umfasst Unterstützung für die BDC-Bereitstellung in Red Hat OpenShift sowie ein aktualisiertes Sicherheitsmodell für BDC, sodass privilegierte Container nicht mehr erforderlich sind. Zusätzlich zu nicht privilegierten Containern werden Container standardmäßig für alle neuen Bereitstellungen unter Verwendung von SQL Server 2019 CU5 als Nicht-Root-Benutzer ausgeführt.
Zum Zeitpunkt der Veröffentlichung von CU5 wird der Setupschritt der Anwendungen, die mit App Deploy-Schnittstellen bereitgestellt wurden, weiterhin als Root-Benutzer ausgeführt. Dies ist erforderlich, weil während des Setups zusätzliche, von der Anwendung verwendete Pakete installiert werden. Anderer Benutzercode, der als Teil der Anwendung bereitgestellt wird, wird als Benutzer mit niedrigen Berechtigungen ausgeführt.
Außerdem ist die optionale Funktion CAP_AUDIT_WRITE erforderlich, um Zeitpläne für SSIS-Anwendungen (SQL Server Integration Services) mithilfe von Cronjobs zu erstellen. Wenn die YAML-Spezifikationsdatei der Anwendung einen Zeitplan vorgibt, wird die Anwendung über einen Cronjob ausgelöst. Dafür ist diese zusätzliche Funktion erforderlich. Alternativ kann die Anwendung nach Bedarf mit dem Befehl azdata app run über einen Webdienstaufruf ausgelöst werden. Dafür ist die Funktion CAP_AUDIT_WRITE nicht erforderlich. Beachten Sie, dass die Funktion CAP_AUDIT_WRITE für cronjob ab dem Release SQL Server 2019 CU8 nicht mehr benötigt wird.
Hinweis
Die benutzerdefinierte Sicherheitskontexteinschränkung (Security Context Constraint, SCC) im Artikel zur OpenShift-Bereitstellung enthält diese Funktion nicht, da sie für eine Standardbereitstellung von BDC nicht erforderlich ist. Zum Aktivieren dieser Funktion müssen Sie zuerst die benutzerdefinierte SCC-YAML-Datei so aktualisieren, dass sie „CAP_AUDIT_WRITE“ enthält.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Arbeiten mit der App-Bereitstellung in einem Big Data-Cluster
Die zwei Hauptschnittstellen für die Anwendungsbereitstellung lauten wie folgt:
- Befehlszeilenschnittstelle Azure Data CLI (
azdata) - Visual Studio Code und Erweiterung Azure Data Studio
Es ist auch möglich, dass eine Anwendung mit einem RESTful-Webdienst ausgeführt wird. Weitere Informationen finden Sie im Artikel zur Nutzung von Anwendungen in Big Data-Clustern.
Szenarien für die App-Bereitstellung
Die Anwendungsbereitstellung ermöglicht die Bereitstellung von Anwendungen in einem SQL Server-BDC durch die Bereitstellung von Schnittstellen zum Erstellen, Verwalten und Ausführen von Anwendungen.
Dies sind die Zielszenarien für die App-Bereitstellung:
- Bereitstellen von Python- oder R-Webdiensten im Big Data-Cluster zur Ausführung einer Vielzahl von Anwendungsfällen, z. B. Machine Learning-Rückschluss, API-Bereitstellung usw.
- Erstellen eines Endpunkts für Machine Learning-Rückschluss mithilfe der MLeap-Engine.
- Planen und Ausführen von Paketen aus DTSX-Dateien mithilfe des Hilfsprogramms dtexec für Datentransformation und -verschiebung.
Verwenden der Python-Runtime für die App-Bereitstellung
In der App-Bereitstellung ermöglicht die BDC-Python-Runtime der Python-Anwendung im Big Data-Cluster die Ausführung einer Vielzahl von Anwendungsfällen, z. B. Machine Learning-Rückschluss, API-Bereitstellung und mehr.
Die Python-Runtime für die App-Bereitstellung verwendet Python 3.8 für SQL Server-Big Data-Cluster CU10+.
In der App-Bereitstellung stellen Sie die Informationen, die dem Controller zum Bereitstellen Ihrer Anwendung bekannt sein müssen, in spec.yaml zur Verfügung. Die folgenden Felder können angegeben werden:
name: der Anwendungsnameversion: die Anwendungsversion, z. B.v1runtime: die App-Bereitstellungslaufzeit, die Sie so angeben müssen:Pythonsrc: der Pfad zur Python-Anwendungentry point: die Einstiegspunktfunktion im src-Skript, das für diese Python-Anwendung ausgeführt werden soll.
Außerdem müssen Sie die Ein- und Ausgabe Ihrer Python-Anwendung angeben. Dadurch wird eine ähnliche spec.yaml-Datei wie die folgende generiert:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Sie können die grundlegende Ordner- und Dateistruktur erstellen, die zur Bereitstellung einer in Big Data-Clustern ausgeführten Python-App erforderlich ist:
azdata app init --template python --name hello-py --version v1
Die nächsten Schritte finden Sie unter Bereitstellen einer App in einem Big Data-Cluster in SQL Server.
Einschränkungen der Python-Runtime bei der App-Bereitstellung
Die Python-Runtime für die App-Bereitstellung unterstützt kein Planungsszenario. Sobald Python bereitgestellt wurde und im BDC ausgeführt wird, wird ein RESTful-Endpunkt konfiguriert, um auf eingehende Anforderungen zu lauschen.
Verwenden der App-Bereitstellung von R-Runtime
Bei der App-Bereitstellung ermöglicht die BDC-Python-Runtime der R-Anwendung im Big Data-Cluster die Ausführung einer Vielzahl von Anwendungsfällen, z. B. Machine Learning-Rückschluss, API-Bereitstellung und mehr.
Die R-Runtime für die App-Bereitstellung verwendet die Microsoft R Open-Version 3.5.2 (MRO) für SQL Server-Big Data-Cluster CU10+.
Verwendung
In der App-Bereitstellung stellen Sie die Informationen, die dem Controller zum Bereitstellen Ihrer Anwendung bekannt sein müssen, in spec.yaml zur Verfügung. Die folgenden Felder können angegeben werden:
name: der Anwendungsnameversion: die Anwendungsversion, z. B.v1runtime: die App-Bereitstellungslaufzeit, die Sie so angeben müssen:Rsrc: der Pfad zur R-Anwendungentry point: der Einstiegspunkt zum Ausführen dieser R-Anwendung
Außerdem müssen Sie die Ein- und Ausgabe Ihrer R-Anwendung angeben. Dadurch wird eine ähnliche spec.yaml-Datei wie die folgende generiert:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Mit dem folgenden Befehl können Sie die grundlegende Ordner- und Dateistruktur erstellen, die zum Bereitstellen einer neuen R-Anwendung erforderlich ist:
azdata app init --template r --name hello-r --version v1
Die nächsten Schritte finden Sie unter Bereitstellen einer App in einem Big Data-Cluster in SQL Server.
Einschränkungen der R-Runtime
Diese Einschränkungen entsprechen dem Microsoft R-Anwendungsnetzwerk, das am 1. Juli 2023 eingestellt wurde. Weitere Informationen und Problemumgehungen finden Sie unter Einstellung des Microsoft R Application Network.
Verwenden der dtexec-Runtime für die App-Bereitstellung
Bei der App-Bereitstellung wird das in die BDC-Runtime integrierte Hilfsprogramm dtexec aus SSIS unter Linux (mssql-server-is) verwendet. Die App-Bereitstellung verwendet das Hilfsprogramm dtexec zum Laden von Paketen aus *.dtsx-Dateien. Es unterstützt die Ausführung von SSIS-Paketen nach einem Zeitplan im Cron-Stil oder bei Bedarf über Webdienstanforderungen.
Dieses Feature verwendet /opt/ssis/bin/dtexec /FILE von SQL Server 2019 Integration Services für Linux. Es unterstützt das DTSX-Format für SQL Server 2019 Integration Services für Linux (mssql-server-is 15.0.2). Weitere Informationen zum Hilfsprogramm dtexec-finden Sie unter dtexec (Hilfsprogramm).
In der App-Bereitstellung stellen Sie die Informationen, die dem Controller zum Bereitstellen Ihrer Anwendung bekannt sein müssen, in spec.yaml zur Verfügung. Die folgenden Felder können angegeben werden:
name: dernameder Anwendungversion: die Anwendungsversion, z. B.v1runtime: die App-Bereitstellungslaufzeit. Zur Ausführung des Hilfsprogramms dtexec müssen Sie sie so angeben:SSISentrypoint: Geben Sie einen Einstiegspunkt an. Dies ist in unserem Fall normalerweise Ihre DTSX-Datei.options: Geben Sie zusätzliche Optionen für/opt/ssis/bin/dtexec /FILEan, um beispielsweise eine Verbindung mit einer Datenbank mit einer Verbindungszeichenfolge herzustellen. Dabei würde das folgende Muster verwendet:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""Einzelheiten zur Syntax finden Sie unter dtexec (Hilfsprogramm).
schedule: Geben Sie an, wie häufig der Auftrag ausgeführt werden soll. Wenn Sie z. B. einen Cron-Ausdruck verwenden, wird dieser Wert als „*/1 * * * *“ angegeben. Dies bedeutet, dass der Auftrag auf Minutenbasis ausgeführt wird.
Mit dem folgenden Befehl können Sie den grundlegenden Ordner und die Dateistruktur erstellen, die zum Bereitstellen einer neuen SSIS-Anwendung erforderlich sind:
azdata app init --name hello-is –version v1 --template ssis
Dadurch wird eine spec.yaml-Datei wie die folgende generiert:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
Im Beispiel wird außerdem das Beispielpaket hello.dtsx erstellt.
Alle Ihre App-Dateien befinden sich in demselben Verzeichnis wie spec.yaml. spec.yaml muss sich auf der Stammebene Ihres App-Quellcodeverzeichnisses befinden, einschließlich der DTSX-Datei.
Die nächsten Schritte finden Sie unter Bereitstellen einer App in einem Big Data-Cluster in SQL Server.
Einschränkungen der Runtime des dtexec-Hilfsprogramms
Alle Einschränkungen und bekannten Probleme für SQL Server Integration Services (SSIS) unter Linux gelten auch für SQL Server-Big Data-Cluster. Weitere Informationen finden Sie unter Einschränkungen und bekannte Probleme bei SSIS unter Linux.
Verwenden der App-Bereitstellung MLeap-Runtime
Die App-Bereitstellung MLeap-Runtime unterstützt MLeap Serving v0.13.0.
In der App-Bereitstellung stellen Sie die Informationen, die dem Controller zum Bereitstellen Ihrer Anwendung bekannt sein müssen, in spec.yaml zur Verfügung. Die folgenden Felder können angegeben werden:
name: der Anwendungsnameversion: die Anwendungsversion, z. B.v1runtime: die App-Bereitstellungslaufzeit, die Sie so angeben müssen:Mleap
Außerdem müssen Sie den bundleFileName Ihrer MLeap-Anwendung angeben. Dadurch wird eine ähnliche spec.yaml-Datei wie die folgende generiert:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Mit dem folgenden Befehl können Sie den grundlegenden Ordner und die Dateistruktur erstellen, die zum Bereitstellen einer neuen MLeap-Anwendung erforderlich sind:
azdata app init --template mleap --name hello-mleap --version v1
Die nächsten Schritte finden Sie unter Bereitstellen einer App in einem Big Data-Cluster in SQL Server.
Einschränkungen der MLeap-Runtime
Die Einschränkungen entsprechen denen für das Open-Source-Projekt MLeap von Combust auf GitHub.
Nächste Schritte
Weitere Informationen zum Erstellen und Ausführen von Anwendungen in SQL Server-Big Data-Clustern finden Sie hier:
- Bereitstellen von Anwendungen mit „azdata“
- Bereitstellen von Anwendungen mit der Erweiterung „app deploy“ (App-Bereitstellung)
- Nutzen von Anwendungen in Big Data-Clustern
Weitere Informationen zu Big Data-Cluster für SQL Server finden Sie in der folgenden Übersicht: