Tabellen- und Zeilengröße in speicheroptimierten Tabellen
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Vor SQL Server 2016 (13.x) konnte die Größe von Daten in Zeilen einer speicheroptimierten Tabelle nicht größer als 8.060 Bytes sein. Jedoch ist es in SQL Server 2016 (13.x) und Azure SQL-Datenbank möglich, eine speicheroptimierte Tabelle mit mehreren großen Spalten (z. B. mehreren varbinary(8000)-Spalten) und LOB-Spalten (z. B. varbinary(max), varchar(max) und nvarchar(max)) zu erstellen sowie Vorgänge für sie mithilfe nativ kompilierter Transact-SQL(T-SQL)-Module und Tabellentypen auszuführen.
Spalten, die nicht in das Zeilenlimit von 8 060 Bytes passen, werden außerhalb der Zeile in einer separaten internen Tabelle platziert. Jede Spalte außerhalb einer Zeile verfügt über eine entsprechende interne Tabelle, die wiederum über einen einzelnen, nicht gruppierten Index verfügt. Informationen zu diesen internen Tabellen für Spalten außerhalb von Zeilen finden Sie unter sys.memory_optimized_tables_internal_attributes.
Es gibt bestimmte Szenarios, in denen es nützlich ist, die Größe der Zeile und der Tabelle zu berechnen:
Wie viel Arbeitsspeicher eine Tabelle verbraucht.
Der Arbeitsspeicher, der für die Tabelle verwendet wird, kann nicht genau berechnet werden. Viele Faktoren beeinflussen den verwendeten Arbeitsspeicher. Faktoren wie seitenbasierte Speicherbelegung, Ort, Caching und Auffüllung. Darüber hinaus mehrere Versionen von Zeilen, denen entweder aktive Transaktionen zugeordnet sind oder die auf die Garbage Collection warten.
Die minimale Größe, die für die Daten und Indizes in der Tabelle erforderlich ist, wird durch die Berechnung von
<table size>angegeben, wie weiter unten in diesem Artikel beschrieben.Da die Berechnung der Arbeitsspeicherverwendung bestenfalls eine Näherung darstellt, ist es ratsam, auch eine Kapazitätsplanung in den Bereitstellungsplänen vorzusehen.
Die Datengröße einer Zeile und die Frage, ob die maximale Zeilengröße von 8 060 Bytes eingehalten wird. Um diese Fragen zu beantworten, verwenden Sie das Berechnungsergebnis für
<row body size>, das weiter unten in diesem Artikel erläutert wird.
Eine speicheroptimierte Tabelle besteht aus einer Auflistung von Zeilen und Indizes, die Zeiger auf die Zeilen enthalten. Die folgende Abbildung zeigt eine Tabelle mit Indizes und Zeilen, die wiederum Zeilenüberschriften und Text enthalten:
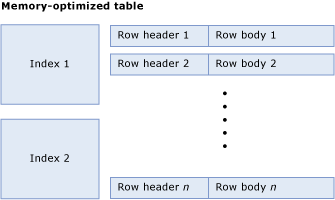
Berechnen der Tabellengröße
Die Größe einer Tabelle im Arbeitsspeicher in Bytes wird wie folgt berechnet:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
Die Größe eines Hashindexes wird bei Erstellung der Tabelle festgelegt und hängt von der tatsächlichen Bucketanzahl ab. Der bucket_count, der mit der Indexdefinition angegeben wird, wird auf die nächste Zweierpotenz aufgerundet, um die tatsächliche Bucketanzahl zu erhalten. Wenn der angegebene bucket_count beispielsweise 100.000 ist, beträgt die tatsächliche Bucketanzahl für den Index 131.072.
<hash index size> = 8 * <actual bucket count>
Die Größe eines nicht gruppierten Index bewegt sich in der Größenordnung von <row count> * <index key size>.
Die Zeilengröße wird berechnet, indem die Überschrift und der Text addiert werden:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Berechnen der Zeilentextgröße
Die Zeilen in einer speicheroptimierten Tabelle verfügen über folgende Komponenten:
Die Zeilenüberschrift enthält den Zeitstempel, der erforderlich ist, um Zeilenversionsverwaltung zu implementieren. Die Zeilenüberschrift enthält auch den Indexzeiger, um die Zeilenverkettung in den Hashbuckets zu implementieren (wie zuvor beschrieben).
Der Zeilentext enthält die tatsächlichen Spaltendaten, darunter einige zusätzliche Informationen wie das NULL-Array für Spalten, die NULL-Werte zulassen, und das Offsetarray für Datentypen variabler Länge.
Die folgende Abbildung veranschaulicht die Zeilenstruktur für eine Tabelle mit zwei Indizes:

Die Zeitstempel für Beginn und Ende geben den Zeitraum an, in dem eine bestimmte Zeilenversion gültig ist. Für Transaktionen, die in diesem Intervall beginnen, ist diese Zeilenversion sichtbar. Weitere Informationen finden Sie unter Transaktionen mit speicheroptimierten Tabellen.
Die Indexzeiger zeigen auf die nächste Zeile in der Kette, die dem Hashbucket angehört. Die folgende Abbildung veranschaulicht die Struktur einer Tabelle mit zwei Spalten (Name, Ort) und mit zwei Indizes: einem für den Spaltennamen und einen für den Spaltenort.
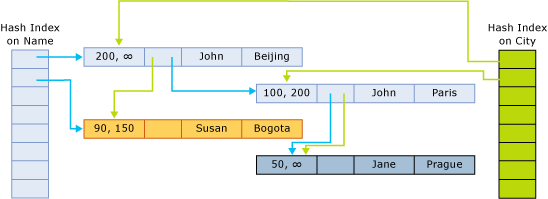
In dieser Abbildung werden die Namen John und Jane zum ersten Hashbucket hinzugefügt. Susan wird dem zweiten Hashbucket hinzugefügt. Die Städte Beijing und Bogota werden dem ersten Hashbucket hinzugefügt. Paris und Prague werden dem zweiten Hashbucket hinzugefügt.
Somit ergeben sie folgende Ketten für den Hashindex für Namen:
- Erster Bucket:
(John, Beijing);(John, Paris);(Jane, Prague) - Zweiter Bucket:
(Susan, Bogota)
Die Ketten für den Index für die Stadt lauten wie folgt:
- Erster Bucket:
(John, Beijing),(Susan, Bogota) - Zweiter Bucket:
(John, Paris),(Jane, Prague)
Ein ∞-Endzeitstempel (unendlich) bedeutet, dass es sich um die derzeit gültige Version der Zeile handelt. Die Zeile wurde nicht aktualisiert oder gelöscht, seitdem diese Zeilenversion geschrieben wurde.
Eine Zeit, die größer als 200 ist, enthält die Tabelle die folgenden Zeilen:
| Name | Ort |
|---|---|
| John | Beijing (Peking) |
| Jane | Prag |
Allerdings wird jeder aktiven Transaktion mit Startzeit 100 die folgende Version der Tabelle angezeigt:
| Name | Ort |
|---|---|
| John | Paris |
| Jane | Prag |
| Susan | Bogota |
Die Berechnung von <row body size> wird in der folgenden Tabelle erläutert.
Es gibt zwei verschiedene Berechnungen für die Zeilentextgröße: die berechnete Größe und die tatsächliche Größe:
Die berechnete Größe, bezeichnet mit computed row body size, wird verwendet, um festzustellen, ob die Zeilengrößeneinschränkung von 8.060 Bytes überschritten wird.
Die tatsächliche Größe, bezeichnet mit actual row body size, ist die tatsächliche Speichergröße des Zeilentexts im Arbeitsspeicher und in den Prüfpunktdateien.
computed row body size und actual row body size werden ähnlich berechnet. Der einzige Unterschied ist die Berechnung der Größe von (n)varchar(i) und varbinary(i)-Spalten, wie unten in der folgenden Tabelle dargestellt. Bei der berechneten Zeilentextgröße wird die deklarierte Größe i als Größe der Spalte verwendet, während für die tatsächliche Zeilentextgröße die tatsächliche Größe der Daten verwendet wird.
Die folgende Tabelle beschreibt die Berechnung der Größe des Zeilentexts, angegeben als <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Abschnitt | Größe | Anmerkungen |
|---|---|---|
| Spalten flacher Typen | SUM(<size of shallow types>). Die Größe (in Bytes) der einzelnen Typen lautet wie folgt:bit: 1tinyint: 1smallint: 2int: 4real: 4smalldatetime: 4smallmoney: 4bigint: 8datetime: 8datetime2: 8float: 8money: 8numeric (Genauigkeit <= 18): 8time: 8numeric(Genauigkeit > 18): 16uniqueidentifier: 16 |
|
| Auffüllung flacher Spalten | Dabei sind folgende Werte möglich:1, wenn Spalten tiefer Typen vorhanden sind und die gesamte Datengröße der flachen Spalten eine ungerade Zahl darstellt.Andernfalls 0 |
Tiefe Typen sind die Typen (var)binary und (n)(var)char. |
| Offsetarray für Spalten tiefer Typen | Dabei sind folgende Werte möglich:0, wenn keine Spalten tiefer Typen vorhanden sindAndernfalls 2 + 2 * <number of deep type columns> |
Tiefe Typen sind die Typen (var)binary und (n)(var)char. |
| Null-Array | <number of nullable columns> / 8 wird auf vollständige Bytes aufgerundet. |
Das Array verfügt über ein Bit pro Spalte, die NULL zulässt. Dies wird auf vollständige Bytes aufgerundet. |
| Null-Arrayauffüllung | Dabei sind folgende Werte möglich:1, wenn Spalten tiefer Typen vorhanden sind und die Größe des NULL-Arrays eine ungerade Anzahl von Bytes darstellt.Andernfalls 0 |
Tiefe Typen sind die Typen (var)binary und (n)(var)char. |
| Auffüllen | Wenn keine Spalten tiefer Typen vorhanden sind: 0Wenn Spalten tiefer Typen vorhanden sind, werden 0–7 Bytes Auffüllung hinzugefügt, basierend auf der größten Ausrichtung, die für eine flache Spalte erforderlich ist. Jede flache Spalte erfordert eine Ausrichtung gleich ihrer Größe, wie zuvor beschrieben. Nur GUID-Spalten erfordern eine Ausrichtung von einem Byte (nicht 16) und numerische Spalten immer eine Ausrichtung von 8 Bytes (nie 16). Die größte Ausrichtungsanforderung unter allen flachen Spalten wird verwendet. 0–7 Bytes Auffüllung werden so hinzugefügt, dass die bisherige Gesamtgröße (ohne die Spalten tiefer Typen) ein Vielfaches der erforderlichen Ausrichtung ergibt. |
Tiefe Typen sind die Typen (var)binary und (n)(var)char. |
| Spalten tiefer Typen mit fester Länge | SUM(<size of fixed length deep type columns>)Die Größe jeder Spalte lautet wie folgt: i für char(i) und binary(i).2 * i für nchar(i) |
Spalten tiefer Typen mit fester Länge sind Spalten des Typs char(i), nchar(i), oder binary(i). |
| Spalten tiefer Typen mit variabler Länge computed size | SUM(<computed size of variable length deep type columns>)Die berechnete Größe jeder Spalte lautet wie folgt: i für varchar(i) und varbinary(i)2 * i für nvarchar(i) |
Diese Zeile wird nur auf computed row body size angewendet. Spalten tiefer Typen mit variabler Länge sind Spalten des Typs varchar(i), nvarchar(i), oder varbinary(i). Die berechnete Größe wird durch die maximale Länge ( i) der Spalte bestimmt. |
| Spalten tiefer Typen mit variabler Länge actual size | SUM(<actual size of variable length deep type columns>)Die tatsächliche Größe jeder Spalte lautet wie folgt: n, wobei n der Anzahl der in der Spalte gespeicherten Zeichen entspricht; für varchar(i).2 * n, wobei n der Anzahl der in der Spalte gespeicherten Zeichen entspricht; für nvarchar(i).n, wobei n der Anzahl der in der Spalte gespeicherten Bytes ist; für varbinary(i). |
Diese Zeile wird nur auf actual row body size angewendet. Die tatsächliche Größe wird durch die Daten bestimmt, die in den Spalten der Zeile gespeichert werden. |
Beispiel: Tabellen- und Zeilengrößenberechnung
Für Hashindizes wird die tatsächliche Bucketanzahl auf die nächste Zweierpotenz aufgerundet. Wenn der angegebene bucket_count beispielsweise 100.000 ist, beträgt die tatsächliche Bucketanzahl für den Index 131.072.
Betrachten Sie eine Orders-Tabelle mit folgender Definition:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Diese Tabelle weist einen Hashindex und einen nicht gruppierten Index (den Primärschlüssel) auf. Darüber hinaus weist sie drei Spalten fester Länge und eine Spalte variabler Länge auf, wobei eine der Spalten NULL-Werte NULLzulässt (OrderDescription). Angenommen, die Tabelle Orders hat 8.379 Zeilen, und die durchschnittliche Länge der Werte in der Spalte OrderDescription ist 78 Zeichen.
Um die Tabellengröße zu ermitteln, ermitteln Sie zuerst die Größe der Indizes. Der bucket_count für beide Indizes wird mit 10000 angegeben. Dieser wird auf die nächste Zweierpotenz aufgerundet: 16384. Daher ergibt sich die Gesamtgröße der Indizes für die Orders-Tabelle wie folgt:
8 * 16384 = 131072 bytes
Was bleibt, ist die Tabellendatengröße:
<row size> * <row count> = <row size> * 8379
(Die Beispieltabelle enthält 8379 Zeilen.) Jetzt haben wir:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
Als Nächstes berechnen wir <actual row body size>:
Spalten flacher Typen:
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16Die Auffüllung flacher Spalten ist 0, da die Gesamtgröße der flachen Spalten einem geraden Wert entspricht.
Offsetarray für Spalten tiefer Typen:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLarray = 1NULL-Arrayauffüllung = 1, da dieNULL-Arraygröße ungerade ist und eine Spalte tiefen Typs vorhanden ist.Auffüllen
- 8 ist die größte Ausrichtungsanforderung
- Die bisherige Größe ist 16 + 0 + 4 + 1 + 1 = 22
- Das nächste Vielfache von 8 ist 24
- Die Gesamtauffüllung beträgt 24 - 22 = 2 Bytes
Es sind keine Spalten tiefer Typen mit fester Länge vorhanden (Spalten tiefer Typen mit fester Länge: 0.).
Die tatsächliche Größe der Spalte tiefen Typs ist 2 * 78 = 156. Die einzelne Spalte tiefen Typs
OrderDescriptionhat den Typnvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Um die Berechnung abzuschließen:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
Die gesamte Tabellengröße im Arbeitsspeicher entspricht daher ungefähr 2 MB. Dies berücksichtigt nicht den möglichen Mehraufwand, der durch die Speicherzuordnung und die für die Transaktionen, die auf diese Tabelle zugreifen, erforderliche Zeilenversionsverwaltung entsteht.
Der tatsächliche Arbeitsspeicher, der dieser Tabelle zugeordnet ist und von ihr und den zugehörigen Indizes verwendet wird, kann über die folgende Abfrage abgerufen werden:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Beschränkungen für eine zeilenüberragende Spalte
Bestimmte Beschränkungen und Vorbehalte bei der Verwendung von zeilenüberragenden Spalten in einer speicheroptimierten Tabelle sind wie folgt aufgeführt:
- Wenn es einen Columnstore-Index für eine speicheroptimierte Tabelle gibt, müssen alle Spalten in Zeilen passen.
- Alle Indexschlüsselspalten müssen innerhalb von Zeilen gespeichert werden. Wenn eine Indexschlüsselspalte nicht innerhalb von Zeilen passt, schlägt das Hinzufügen des Index fehl.
- Vorbehalte für das Ändern einer speicheroptimierten Tabelle mit Spalten außerhalb von Zeilen.
- Für LOBs spiegelt die Größenbeschränkung diejenige datenbasierter Tabellen wider (maximal 2 GB auf LOB-Werten).
- Für eine optimale Leistung empfehlen wir, dass die meisten Spalten innerhalb von 8 060 Bytes liegen sollten.
- Daten außerhalb der Zeilen können eine übermäßige Speicher- und/oder Festplattennutzung verursachen.
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für