Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2016 (13.x) und spätere Versionen
SQL Server 2016 (13.x) und spätere Versionen ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Sie können jedoch Ihre Abfragen über JSON-Dokumente optimieren, indem Sie Standardindizes verwenden.
Note
In SQL Server 2025 (17.x) können Sie die Funktion CREATE JSON INDEX (Transact-SQL) verwenden.
Indizes funktionieren auf die gleiche Weise auf JSON-Daten in varchar/nvarchar oder dem nativen JSON-Datentyp.
Datenbankindizes verbessern die Leistung von Filter- und Sortierungsvorgängen. Ohne Indizes muss SQL Server bei jeder Datenabfrage einen vollständigen Tabellenscan durchführen.
Note
Die JSON-Datentyp:
Indizieren von JSON-Eigenschaften mithilfe von berechneten Spalten
Wenn Sie JSON-Daten in SQL Server speichern, möchten Sie in der Regel Abfrageergebnisse nach einer oder mehreren Eigenschaften der JSON-Dokumente filtern oder sortieren.
Example
In diesem Beispiel wird angenommen, dass die AdventureWorks.SalesOrderHeader-Tabelle über eine Info-Spalte verfügt, die verschiedene Informationen im JSON-Format zu Verkaufsaufträgen enthält. Sie enthält beispielsweise unstrukturierte Daten zu Kunde, Vertriebsmitarbeiter, Versand- und Rechnungsadresse usw. Sie können Werte aus der Info-Spalte verwenden, um Verkaufsaufträge eines Kunden zu filtern.
Standardmäßig ist die verwendete Spalte Info nicht vorhanden, sie kann in der AdventureWorks Datenbank mit dem folgenden Code erstellt werden. Die folgenden Beispiele gelten nicht für die AdventureWorksLT Reihe von Beispieldatenbanken.
IF NOT EXISTS (SELECT *
FROM sys.columns
WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]')
AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader]
ADD [Info] NVARCHAR (MAX) NULL;
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c
ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p
ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Zu optimierende Abfrage
Hier finden Sie ein Beispiel der Art von Abfrage, die Sie optimieren möchten, indem Sie einen Index verwenden.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell';
Beispielindex
Falls Sie Ihre Filter oder die ORDER BY-Klausel in Bezug auf eine Eigenschaft in einem JSON-Dokument beschleunigen möchten, können Sie die gleichen Indizes verwenden, die Sie bereits bei Ihren anderen Spalten verwenden. Sie können jedoch nicht direkt auf Eigenschaften in den JSON-Dokumenten verweisen.
- Erstellen Sie zunächst eine „virtuelle Spalte“, die die Werte zurückgibt, die Sie für die Filterung verwenden möchten.
- Erstellen Sie anschließend einen Index auf dieser virtuellen Spalte.
Im folgenden Beispiel wird eine berechnete Spalte erstellt, die für die Indizierung verwendet werden kann. Anschließend wird ein Index für die neue berechnete Spalte erstellt. In diesem Beispiel wird eine Spalte erstellt, die den Namen des Kunden verfügbar macht, der im Pfad $.Customer.Name in den JSON-Daten gespeichert ist.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info, '$.Customer.Name');
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName);
Diese Anweisung gibt die folgende Warnung aus:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
Die JSON_VALUE Funktion kann Textwerte bis zu 8000 Byte zurückgeben (z. B. als nvarchar(4000)- Typ). Die Werte, die länger als 1700 Byte sind, können jedoch nicht indiziert werden. Wenn Sie versuchen, den Wert in die indizierte berechnete Spalte einzugeben, die länger als 1700 Bytes ist, schlägt die DML-Operation fehl.
Versuchen Sie zur Erzielung einer besseren Leistung, den Wert, den Sie mithilfe der berechneten Spalte verfügbar gemacht haben, in den kleinsten anwendbaren Datentyp umzuwandeln. Verwenden Sie int - und datetime2-Typen anstelle von Zeichenfolgentypen.
Weitere Informationen über die berechnete Spalte
Eine berechnete Spalte ist nicht persistent. Eine berechnete Spalte wird nur berechnet, wenn der Index neu erstellt werden muss. Sie belegt keinen zusätzlichen Platz in der Tabelle.
Es ist wichtig, die berechnete Spalte mit dem gleichen Ausdruck zu erstellen, den Sie in Ihren Abfragen verwenden möchten – in diesem Beispiel handelt es sich dabei um den Ausdruck JSON_VALUE(Info, '$.Customer.Name').
Sie müssen Ihre Abfragen nicht neu schreiben. Falls Sie wie in der vorherigen Beispielabfrage dargestellt Ausdrücke mit der JSON_VALUE-Funktion verwenden, erkennt SQL Server, dass es eine gleichwertig berechnete Spalte mit dem gleichen Ausdruck gibt und wendet dann, falls möglich, einen Index darauf an.
Ausführungsplan für dieses Beispiel
Hier finden Sie den Ausführungsplan für die Abfrage in diesem Beispiel.
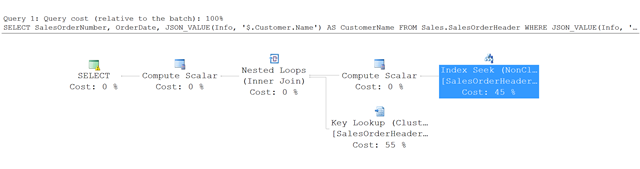
Statt eines vollständigen Tabellenscans verwendet SQL Server eine Indexsuche im nicht gruppierten Index, und findet so die Zeilen, die die angegebenen Bedingungen erfüllen. Dann verwendet es eine Schlüsselsuche in der SalesOrderHeader Tabelle, um die anderen Spalten abzurufen, auf die in der Abfrage verwiesen wird - in diesem Beispiel, SalesOrderNumber und OrderDate.
Weiteres Optimieren des Index mit enthaltenen Spalten
Wenn Sie dem Index erforderliche Spalten hinzufügen, können Sie diese zusätzliche Suche in der Tabelle vermeiden. Sie können diese Spalten als standardmäßig enthaltene Spalten hinzufügen. Dies wird im folgenden Beispiel dargestellt, das eine Erweiterung des vorherigen CREATE INDEX-Beispiels darstellt.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber, OrderDate);
In diesem Fall muss SQL Server keine weiteren Daten aus der SalesOrderHeader Tabelle lesen, da alles, was er benötigt, im nicht gruppierten JSON-Index enthalten ist. Dieser Index ist eine gute Möglichkeit, um JSON- und Spaltendaten in Abfragen zu kombinieren und optimale Indizes für Ihre Arbeitsauslastung zu erstellen.
JSON-Indizes sind Indizes mit Sortierungserkennung
Eine wichtige Funktion von Indizes für JSON-Daten ist, dass die Indizes über eine Sortierungserkennung verfügen. Das Ergebnis der Funktion JSON_VALUE, die Sie beim Erstellen der berechneten Spalte verwenden, ist ein Textwert, der seine Sortierung vom Eingabeausdruck erbt. Die Werte im Index sind daher nach den Sortierungsregeln geordnet, die in den Quellspalten definiert sind.
Im folgenden Beispiel wird eine einfache Sammlungstabelle mit einem Primärschlüssel und JSON-Inhalten erstellt, um zu demonstrieren, dass die Indizes über eine Sortierungserkennung verfügen.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR (MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON] CHECK (ISJSON(json) > 0)
);
Der vorherige Befehl gibt die serbisch-kyrillische Sortierung für die json-Spalte an. Das folgende Beispiel füllt die Tabelle auf und erstellt einen Index auf die Namenseigenschaft.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}');
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json, '$.name');
CREATE INDEX idx_name
ON JsonCollection(vName);
Die vorherigen Befehle erstellen einen Standardindex auf die berechnete Spalte vName, die den Wert der JSON-Eigenschaft $.name darstellt. In der serbisch-kyrillischen Codepage lautet die Reihenfolge der Buchstaben А, Б, В, Г, Д, Ђ, Е usw. Die Reihenfolge der Elemente im Index entspricht den serbisch-kyrillischen Regeln, da das Ergebnis der JSON_VALUE-Funktion seine Sortierung aus der Quellspalte erbt. Im folgenden Beispiel wird diese Auflistung abgefragt und die Ergebnisse nach Namen sortiert.
SELECT JSON_VALUE(json, '$.name'),
*
FROM JsonCollection
ORDER BY JSON_VALUE(json, '$.name');
Wenn Sie sich den tatsächlichen Ausführungsplan ansehen, sehen Sie, dass er die sortierten Werte aus dem nicht gruppierten Index verwendet.

Obwohl die Abfrage eine ORDER BY-Klausel hat, verwendet der Ausführungsplan keinen Sort-Operator. Der JSON-Index ist bereits nach den Regeln für serbisches Kyrillisch geordnet. Daher kann SQL Server den nicht gruppierten Index verwenden, in dem die Ergebnisse bereits sortiert wurden.
Falls Sie jedoch die Sortierung des ORDER BY-Ausdrucks ändern, indem Sie beispielsweise COLLATE French_100_CI_AS_SC an die JSON_VALUE-Funktion anhängen, erhalten Sie einen anderen Ausführungsplan für die Abfrage.

Da die Reihenfolge der Werte im Index nicht mit französischen Sortierregeln kompatibel ist, kann SQL Server den Index nicht verwenden, um Ergebnisse zu sortieren. Daher wird ein Sort-Operator hinzugefügt, der Ergebnisse nach den französischen Sortierungsregeln sortiert.
Microsoft-Videos
Eine visuelle Einführung in die integrierte JSON-Unterstützung finden Sie im folgenden Video: