Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2016 (13.x) und spätere Versionen
SQL Server 2016 (13.x) und spätere Versionen ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL database in Microsoft Fabric
SQL database in Microsoft Fabric
Mit der Datenvirtualisierung können Sie Transact-SQL -Abfragen (T-SQL) über externe Daten ausführen, ohne sie in Ihre Datenbank zu laden. PolyBase ist das Datenbankmodul-Feature, das die Datenvirtualisierung in SQL Server und Azure SQL implementiert. Sie definieren eine externe Datenquelle, ein optionales Dateiformat und eine externe Tabelle und fragen dann die externe Tabelle wie SELECT jede andere Tabelle ab.
Dieser Leitfaden hilft Ihnen bei:
- Verstehen Sie, welche PolyBase-Features Ihre SQL-Plattform und -Version unterstützen.
- Wählen Sie zwischen
OPENROWSET, externen Tabellen undBULK INSERTzum Abfragen oder Aufnehmen von Daten aus. - Folgen Sie schrittweisen Links für allgemeine Szenarien.
- Überprüfen Sie die Leistung, die Fehlerbehebung und die bewährten Verfahren für Produktions-Workloads.
Gängige Anwendungsfälle
In der folgenden Tabelle werden mögliche Nutzungsszenarien beschrieben.
| Szenario | Verwendung |
|---|---|
| Ad-hoc-Dateisuche | OPENROWSET(BULK ...) |
| Wiederverwendbare Dateiabfragen für BI/Berichte | Externe Tabellen über Dateien |
| Datenbankübergreifende Abfrage (SQL Server, Oracle, Teradata, MongoDB, ODBC) | PolyBase-Connectors mit externen Tabellen |
| Exportieren von Abfrageergebnissen in Dateien |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Massenaufnahme in Tabellen |
BULK INSERT oder OPENROWSET(BULK ...) mit INSERT ... SELECT |
Welche Features stehen wo zur Verfügung?
Die folgende Tabelle zeigt, welche grundlegenden PolyBase- und Datenvirtualisierungsfeatures auf jeder SQL-Plattform verfügbar sind. Verwenden Sie diese Tabelle, um zu bestimmen, was Sie auf Ihrer Plattform tun können, bevor Sie die detaillierten Leitfäden verwenden.
| Funktion | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL-Datenbank | Verwaltete Azure SQL-Instanz | SQL-Datenbank in Microsoft Fabric |
|---|---|---|---|---|---|---|
| externe Tabellen | Ja | Ja | Ja | Ja | Ja | Ja |
| OPENROWSET (BULK) | Ja 1 | Ja | Ja | Ja | Ja | Ja |
| CETAS (Export) | No | Ja | Ja | No | Ja | No |
| CSV/durch Trennzeichen getrennte Dateien | Ja 2 | Ja | Ja | Ja | Ja | Ja |
| Parquet-Dateien | No | Ja | Ja | Ja | Ja | Ja |
| Delta Lake-Tabellen | No | Ja | Ja | No | No | No |
| Herstellen einer Verbindung mit einem anderen SQL Server | Ja | Ja | Ja | No | No | No |
| Herstellen einer Verbindung mit azure SQL-Datenbank oder azure SQL Managed Instance | Ja 3 | Ja 3 | Ja 3 | No | No | No |
| Verbinden mit Oracle / Teradata / MongoDB | Ja | Ja | Ja | No | No | No |
| Herstellen einer Verbindung mit Azure Blob Storage | Ja | Ja | Ja | Ja | Ja | No |
| Herstellen einer Verbindung mit ADLS Gen2 | No | Ja | Ja | Ja | Ja | No |
| Herstellen einer Verbindung mit S3-kompatiblem Speicher | No | Ja | Ja | No | No | No |
| Herstellen einer Verbindung mit OneLake (Fabric) | No | No | No | No | No | Ja |
| Pushdownberechnung | Ja | Ja | Ja | No | No | No |
| Authentifzierung mit verwalteten Identitäten | No | No | Ja 4 | Ja | Ja | No |
1 SQL Server 2019 (15.x) unterstützt OPENROWSET(BULK...) lokale und Netzwerkdateipfade. In SQL Server 2022 (16.x) und höheren Versionen OPENROWSET(BULK...) unterstützt auch das Lesen aus dem Cloudspeicher mit FORMAT = 'PARQUET', FORMAT = DELTAund FORMAT = 'CSV'.
2 CSV-Unterstützung in SQL Server 2019 (15.x) erforderte Hadoop. In SQL Server 2022 (16.x) und höheren Versionen wird CSV nativ ohne Hadoop unterstützt.
3 Verwendet den SQL Server-Connector (sqlserver://). Die Datenbank-spezifischen Anmeldeinformationen sind auf den Azure SQL-Endpunkt ausgerichtet, und die Schritte sind die gleichen wie bei der Verbindung zu einem anderen SQL-Server.
4 Die Managed Identity-Authentifizierung wird für die Verbindung mit Azure Blob Storage (ABS) und ADLS Gen2 unterstützt. Sie erfordert Azure Arc-fähige SQL Server oder SQL Server auf einer Azure-VM für lokale SQL Server. Sie ist nativ in Azure SQL-Datenbank und azure SQL Managed Instance verfügbar.
Hinweis
Ab SQL Server 2025 (17.x) ist das Abfragen von Datendateien (CSV, Parquet und Delta) auf Azure Blob Storage, ADLS Gen2 oder S3-kompatiblem Speicher eine native Engine-Funktion, ohne die PolyBase-Dienste installieren oder ausführen zu müssen. RDBMS-Connectors (SQL Server, Oracle, Teradata, MongoDB, ODBC) erfordern weiterhin die Installation und Ausführung von PolyBase-Diensten. SQL Server 2025 (17.x) fügt auch Linux-Unterstützung für diese Connectors hinzu, die zuvor nur unter Windows verfügbar waren.
Abfragen externer Daten
Bevor Sie ein bestimmtes Szenario auswählen, verstehen Sie die drei Möglichkeiten zum Abfragen externer Daten:
| Vorgehensweise | Syntax | Verwenden Sie, wenn | Authentifizierung | PolyBase erforderlich |
|---|---|---|---|---|
| OLE DB-Ad-hoc-Abfragen | OPENROWSET(provider, connection, query) |
Sie möchten eine schnelle einmalige Abfrage ohne persistente Objekte oder die Microsoft Entra ID-Authentifizierung benötigen. | SQL-Authentifizierung, Windows-Authentifizierung, Microsoft Entra ID (MSOLEDBSQL) | No |
| Ad-hoc-Dateiabfragen | OPENROWSET(BULK ...) |
Sie möchten Dateidaten schnell untersuchen oder Schemas testen, bevor Sie eine Tabelle erstellen. | SAS-Token, Zugriffsschlüssel, verwaltete Identität, Microsoft Entra-ID | Ja für Azure SQL-Datenbank und azure SQL Managed Instance Nein für SQL Server-Instanzen |
| Persistente Datenverbindungen |
CREATE EXTERNAL TABLE mit sqlserver://, oracle://, teradata://, usw. |
Sie benötigen wiederholten Zugriff, Governance, Statistiken und Pushdown-Berechnungen für die Produktion. | Nur SQL-Authentifizierung | Ja |
PolyBase-Dienste sind für den Clouddateizugriff in SQL Server 2019 (15.x) und SQL Server 2022 (16.x) erforderlich. SQL Server 2025 (17.x) und höhere Versionen bieten systemeigene Unterstützung für CSV, Parkett und Delta ohne PolyBase.
Leitfaden zur Entscheidungsfindung
| Szenario | Empfehlung |
|---|---|
| Ich benötige die Microsoft Entra ID-Authentifizierung für Remote-SQL oder möchte PolyBase-Dienste vermeiden. | Verwenden OPENROWSET(MSOLEDBSQL, ...) (Ad-hoc, keine persistenten Objekte) |
| Ich benötige dauerhafte Tabellen, Statistiken oder Pushdownberechnungen für Remotedatenbanken. | Verwendung CREATE EXTERNAL TABLE mit PolyBase-Verbindern (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET unterstützt keine Connectoren. |
| Ich erkunde eine neue Datei oder teste ein Schema | Verwenden OPENROWSET(BULK ...) (schnelle Iteration, keine persistenten Objekte) |
| Ich lade Dateien in eine Tabelle und transformiere sie. | Verwenden Sie INSERT ... SELECT von OPENROWSET(BULK ...) |
| Ich benötige Governance oder gemeinsamen Zugriff für viele Benutzer oder Anwendungen | Verwenden Sie CREATE EXTERNAL TABLE, um Berechtigungen und Metadaten zu zentralisieren. |
| Ich arbeite in der SQL-Datenbank in Fabric | Verwenden Sie OPENROWSET(BULK ...) für Ad-hoc-OneLake-Abfragen oder externe Tabellen für wiederverwendbaren Zugriff; für externen Speicher verwenden Sie OneLake-Verknüpfungen. |
Auswählen Ihres Szenarios
Nachdem Sie nun die drei Ansätze verstanden haben, verwenden Sie einen der folgenden Leitfäden, um Ihren spezifischen Anwendungsfall zu implementieren.
Abfragedateien (Parkett, CSV oder Delta)
Wenn Sich Ihre Daten in Parkett-, CSV- oder Delta-Dateien auf Azure Blob Storage, ADLS Gen2, S3-kompatiblem Speicher oder OneLake befinden, folgen Sie einem der folgenden Anleitungen:
| Szenario | Empfohlene Anleitung | Plattformen |
|---|---|---|
| Schnelle Ad-hoc-Abfrage für eine Parkett- oder CSV-Datei | Verwenden Sie OPENROWSET. Keine externe Tabelle erforderlich |
SQL Server 2022 (16.x) und höhere Versionen, Azure SQL-Datenbank, Azure SQL Managed Instance, SQL-Datenbank in Fabric |
| Wiederholte Abfragen von Parkettdateien mit einem persistenten Schema | Erstellen eines externen Tisches über Parkett | SQL Server 2022 (16.x) und höhere Versionen, Azure SQL-Datenbank, Azure SQL Managed Instance, SQL-Datenbank in Fabric |
| Abfragen von CSV-Dateien mit einer externen Tabelle | Erstellen einer externen Tabelle mit einem Dateiformat für durch Trennzeichen getrennten Text | SQL Server 2019 (15.x) und höhere Versionen, Azure SQL-Datenbank, Azure SQL Managed Instance, SQL-Datenbank in Fabric |
| Abfragen von Delta Lake-Tabellen | Erstellen einer externen Tabelle mit FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) und höhere Versionen |
| Exportieren Sie Abfrageergebnisse in Parquet- oder CSV-Dateien (CETAS) |
CREATE EXTERNAL TABLE AS SELECT verwenden |
SQL Server 2022 (16.x) und höhere Versionen, Azure SQL Managed Instance |
Sie können auch eine der folgenden schrittweisen Lernprogramme befolgen:
| Tutorial | Beschreibung |
|---|---|
| Erste Schritte mit PolyBase in SQL Server 2022 | Deckt OPENROWSET mit Parquet und CSV, externen Tabellen und Ordnernavigation ab. |
| Virtualisieren der Parquet-Datei in einem S3-kompatiblen Objektspeicher mit PolyBase | Lernprogramm für SQL Server 2022 (16.x) und höhere Versionen. |
| Virtualisieren der CSV-Datei mit PolyBase | Lernprogramm für SQL Server 2022 (16.x) und höhere Versionen. |
| Virtualisieren der Delta-Tabelle mit PolyBase | Lernprogramm für SQL Server 2022 (16.x) und höhere Versionen. |
| Datenvirtualisierung mit Azure SQL-Datenbank (Vorschau) | Azure SQL-Datenbankhandbuch für Parkett und CSV. |
| Datenvirtualisierung mit Azure SQL Managed Instance | Leitfaden für Azure SQL Managed Instance für Parquet, CSV und CETAS. |
| Datenvirtualisierung in SQL-Datenbank in Fabric | SQL-Datenbank im Fabric-Handbuch für OneLake-Dateien. |
Herstellen einer Verbindung mit einer anderen SQL Server-Instanz, Azure SQL-Datenbank oder SQL Managed Instance
In SQL Server 2019 (15.x) und höheren Versionen kann PolyBase Tabellen in einer anderen SQL Server-Instanz, Azure SQL-Datenbank oder azure SQL Managed Instance abfragen, ohne verknüpfte Server zu verwenden.
Von Bedeutung
Der sqlserver:// Connector wird in der SQL-Datenbank in Fabric nicht unterstützt. PolyBase RDBMS-Connectors verwenden die SQL-Authentifizierung über CREATE DATABASE SCOPED CREDENTIAL und unterstützen keine Microsoft Entra-ID, Managed Identity oder Authentifizierung über Dienstprinzipale. Da die SQL-Datenbank in Fabric die Microsoft Entra-Authentifizierung erfordert, können Sie über PolyBase keine Verbindung zur Datenbank herstellen.
| Schritt | Was zu tun ist |
|---|---|
| 1. Installieren von PolyBase | Installieren von PolyBase unter Windows oder Installieren von PolyBase unter Linux |
| 2. Erstellen von Anmeldedaten |
CREATE DATABASE SCOPED CREDENTIAL mit dem Ziel-Login |
| 3. Erstellen einer externen Datenquelle | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Erstellen einer externen Tabelle | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Abfrage | SELECT * FROM <external_table> |
Tipp
Der SQL Server-Connector (sqlserver://) funktioniert auch für Azure SQL-Datenbank und azure SQL Managed Instance. Führen Sie dieselben Schritte aus, und legen Sie LOCATION auf den Azure SQL-Endpunkt fest (z. B. sqlserver://myserver.database.windows.net).
Eine ausführliche Anleitung finden Sie unter Konfigurieren von PolyBase für den Zugriff auf externe Daten in SQL Server.
Herstellen einer Verbindung mit Oracle, Teradata oder MongoDB
SQL Server 2019 (15.x) und höhere Versionen können Oracle, Teradata, MongoDB und Cosmos DB über PolyBase ODBC-Connectors abfragen.
| Datenquelle | Guide | Anforderungen |
|---|---|---|
| Orakel | Konfigurieren von PolyBase für den Zugriff auf externe Daten in Oracle | SQL Server 2019 (15.x) und höhere Versionen, Oracle-Clienttreiber |
| Teradata | Konfigurieren von PolyBase für den Zugriff auf externe Daten in Teradata | SQL Server 2019 (15.x) und höhere Versionen, Teradata ODBC-Treiber |
| MongoDB / Cosmos DB | Konfigurieren von PolyBase für den Zugriff auf externe Daten in MongoDB | SQL Server 2019 (15.x) und höhere Versionen, MongoDB ODBC-Treiber |
| Jede ODBC-Quelle | Konfigurieren von PolyBase für den Zugriff auf externe Daten mit generischen ODBC-Typen | SQL Server 2019 (15.x) und höhere Versionen (Windows) (Linux ab SQL Server 2025 (17.x)) |
Herstellen einer Verbindung mit Azure Blob Storage oder ADLS Gen2
| SQL-Plattform | Authentifizierungsoptionen | Guide |
|---|---|---|
| SQL Server 2022 (16.x) und höhere Versionen | SAS-Token, Zugriffsschlüssel, verwaltete Identität (beginnend mit SQL Server 2025 (17.x)) | Konfigurieren von PolyBase für den Zugriff auf externe Daten in Azure Blob Storage |
| SQL Server 2019 (15.x) | Zugriffsschlüssel (über Hadoop-Konnektor) | Konfigurieren von PolyBase für den Zugriff auf externe Daten in Azure Blob Storage |
| Azure SQL-Datenbank | SAS-Token, Verwaltete Identität, Microsoft Entra Pass-Through | Datenvirtualisierung mit Azure SQL-Datenbank (Vorschau) |
| Verwaltete Azure SQL-Instanz | SAS-Token, verwaltete Identität | Datenvirtualisierung mit Azure SQL Managed Instance |
In SQL Server 2022 (16.x) wurden die URI-Präfixe geändert. Beim Migrieren von SQL Server 2019 (15.x) oder früheren Versionen:
-
Azure Blob Storage: Ändern
wasb[s]://inabs:// -
ADLS Gen2: Ändern
abfs[s]://inadls://
Weitere Informationen finden Sie unter Configure PolyBase to access external data in Azure Blob Storage.
Herstellen einer Verbindung mit S3-kompatiblem Objektspeicher
SQL Server 2022 (16.x) und höhere Versionen unterstützen S3-kompatiblen Speicher, z. B. Amazon S3, MinIO und Ceph.
Weitere Information erhalten Sie unter Konfigurieren von PolyBase für den Zugriff auf externe Daten im S3-kompatiblen Objektspeicher.
Exportieren von Daten mit CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS exportiert Abfrageergebnisse in externe Dateien (Parquet oder CSV) in Azure Blob Storage, ADLS Gen2 oder S3-kompatible Speicher.
| SQL-Plattform | Unterstützt | Exportformate | Hinweise |
|---|---|---|---|
| SQL Server 2022 (16.x) und höhere Versionen | Ja | Parkett, CSV | Erfordert Serverkonfiguration: Polybase-Export zulassen |
| Verwaltete Azure SQL-Instanz | Ja | Parkett, CSV | Standardmäßig deaktiviert |
| Azure SQL-Datenbank | No | Nichts | Nicht verfügbar |
| SQL-Datenbank in Fabric | No | Nichts | Nicht verfügbar |
Informationen zur Transact-SQL-Referenz finden Sie unter CREATE EXTERNAL TABLE AS SELECT (CETAS).
Schnellstartbeispiele
Beispiel 1: Ad-hoc-Abfrage für eine Parquet-Datei (OPENROWSET)
Es ist keine externe Tabelle erforderlich. Funktioniert unter SQL Server 2022 (16.x) und höheren Versionen, Azure SQL-Datenbank, azure SQL Managed Instance und SQL-Datenbank in Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Beispiel 2: Externe Tabelle über CSV im Azure Blob Storage
Dieses Beispiel funktioniert auf allen SQL-Plattformen, die PolyBase unterstützen.
Schritt 1: Erstellen eines Datenbankmasterschlüssels (DMK). Dieser Schritt ist erforderlich, da die Anmeldeinformationen einen SAS-Tokenschlüssel speichern. Sie können diesen Schritt jedoch ausführen, wenn Sie die verwaltete Identität oder die Microsoft Entra-Authentifizierung verwenden.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Schritt 2: Erstellen Sie einen Berechtigungsnachweis mit einem SAS-Token. Entfernen Sie das führende
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Schritt 3: Erstellen einer externen Datenquelle.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Schritt 4: Erstellen eines Dateiformats für die CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Schritt 5: Erstellen der externen Tabelle.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Schritt 6: Abfragen der externen Tabelle.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Beispiel 3: Abfragen einer Tabelle in einem anderen SQL Server
Dieses Beispiel funktioniert in SQL Server 2019 (15.x) und höheren Versionen.
Schritt 1: Erstellen eines Datenbankmasterschlüssels (erforderlich, da die Anmeldeinformationen ein Kennwort speichern).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Schritt 2: Erstellen sie eine Anmeldeinformation für die SQL Server-Remoteinstanz.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Schritt 3: Erstellen der externen Datenquelle.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Schritt 4: Erstellen der externen Tabelle (dreiteiliger Name in
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Schritt 5: Abfragen über Server hinweg.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Beispiel 4: Ergebnisse mit CETAS nach Parquet exportieren
Funktioniert unter SQL Server 2022 (16.x) und höheren Versionen von Azure SQL Managed Instance.
Schritt 1: Aktivieren von CETAS (nur SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Schritt 2: Erstellen von Anmeldeinformationen und Datenquellen (Wiederverwenden aus früheren Beispielen).
Schritt 3: Erstellen eines Dateiformats für den Parkettexport.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Schritt 4: Exportieren von Abfrageergebnissen.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
T-SQL-Bausteine für PolyBase
Bevor Sie ein Szenario implementieren, verstehen Sie die wichtigsten T-SQL-Objekte, die PolyBase verwendet und wie sie zusammenpassen:
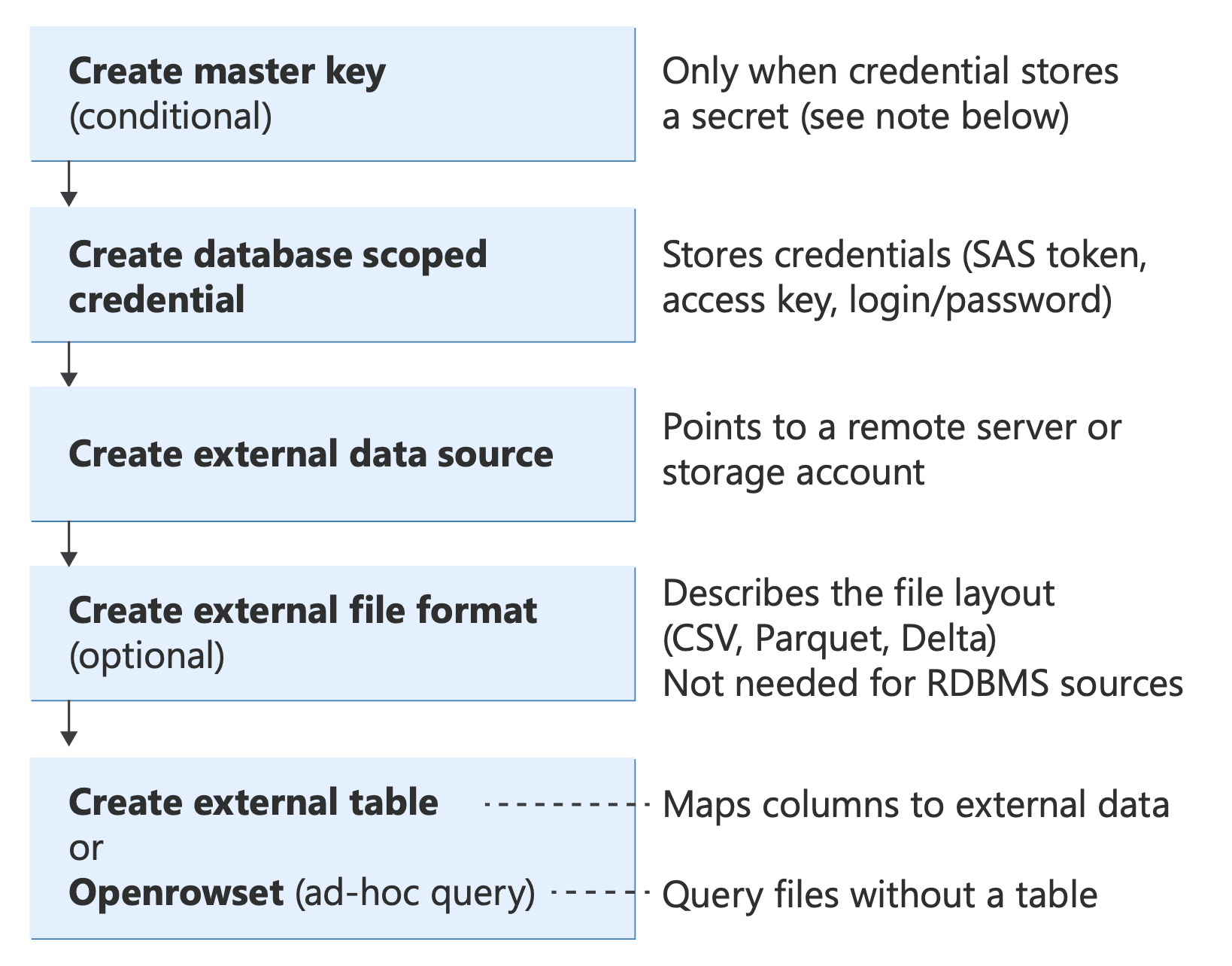
Diagramm mit PolyBase T-SQL-Objekten und deren Beziehungen von der Authentifizierung (Datenbankmasterschlüssel, Anmeldeinformationen) über Datenquellen und Dateiformate bis hin zu Abfragemethoden (Externe Tabelle, OPENROWSET, BULK INSERT, CETAS).
Informationen zu diesen T-SQL-Anweisungen finden Sie unter:
- EXTERNE DATENQUELLE ERSTELLEN
- EXTERNES DATEIFORMAT ERSTELLEN
- EXTERNE TABELLE ERSTELLEN
- OPENROWSET
- EXTERNE TABELLE ALS SELECT ERSTELLEN (CETAS)
Eine vollständige Transact-SQL Referenz für alle Objekte finden Sie unter PolyBase Transact-SQL Referenz.
Von Bedeutung
Überprüfen Sie die Datentypzuordnung für Ihr externes Dateiformat. Wenn Sie ein externes Dateiformat oder Abfragedateien mithilfe OPENROWSETvon PolyBase erstellen, werden Quelldatentypen (Parkett, CSV, Delta, Oracle, Teradata, MongoDB) automatisch SQL Server-Datentypen zugeordnet. Nicht übereinstimmende Typen können zu stillen Abkürzungen, Präzisionsverlust oder Abfragefehlern führen. Zum Beispiel wird ein Parquet DECIMAL(38,18) auf DECIMAL(18,0) abgebildet. Überprüfen Sie die Zuordnungstabellen, bevor Sie externe Tabellenspalten oder eine WITH Klausel definieren. Die vollständige Referenz finden Sie unter Typzuordnung mit PolyBase.
Wann ist CREATE MASTER KEY erforderlich?
Ein Datenbankmasterschlüssel (DMK) wird mithilfe der CREATE MASTER KEY Syntax erstellt. Das DMK verschlüsselt die geheimen Schlüssel, die in datenbankbezogenen Anmeldeinformationen gespeichert sind. Sie ist nur erforderlich, wenn die Anmeldeinformationen einen geheimen Wert enthalten, d. h. wenn sie ein Kennwort, ein Token oder einen Zugriffsschlüssel speichert.
DMK ist erforderlich (Anmeldeinformationen speichern einen geheimen Schlüssel):
Authentifizierungsart IDENTITY-WertHat geheimnis DMK SAS-Token 'SHARED ACCESS SIGNATURE'Ja Erforderlich S3-Zugriffstaste 'S3 ACCESS KEY'Ja Erforderlich SQL-Anmeldung / Standardauthentifizierung '<username>'Ja Erforderlich Zugriffsschlüssel für das Speicherkonto '<storage_account_name>'Ja Erforderlich DMK ist nicht erforderlich (kein geheimer Schlüssel gespeichert):
Authentifizierungsart IDENTITY-WertHat geheimnis DMK Verwaltete Identität 'Managed Identity'No Nicht erforderlich Microsoft Entra ID 'User Identity'oder'Managed Identity'No Nicht erforderlich
Tipp
Wenn es in Ihrer CREATE DATABASE SCOPED CREDENTIAL Erklärung kein Geheimnis gibt, benötigen Sie kein DMK. Verwaltete Identitäten und die Authentifizierung mit Microsoft Entra ID delegieren das Vertrauen an die Plattform. Die Datenbank speichert keine Kennwörter oder Token.
Beispiele:
In dieser Beispielabfrage ist die DMK erforderlich (Anmeldeinformationen speichern ein SAS-Token).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
In dieser Beispielabfrage ist das DMK nicht erforderlich (verwaltete Identität, kein geheimer Schlüssel).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
In dieser Beispielabfrage ist die DMK nicht erforderlich (Microsoft Entra Pass-Through, kein Geheimer Schlüssel).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Remotedatenzugriff mit OPENROWSET und externen Tabellen
SQL Server bietet drei unterschiedliche Ansätze zum Abfragen von Remotedaten. Sie können den richtigen Ansatz auswählen, wenn Sie die Unterschiede zwischen Syntax, Authentifizierung und Architektur verstehen.
| Vorgehensweise | Syntax | Verbindung mit | Authentifizierung | PolyBase-Dienste | Plattformen |
|---|---|---|---|---|---|
| OLE DB-Abfragen | OPENROWSET(provider, connection, query) |
OLE DB-Quelle über MSOLEDBSQL, SQLOLEDB oder andere Anbieter | SQL-Authentifizierung, Windows-Authentifizierung, Microsoft Entra ID (MSOLEDBSQL) | No | SQL Server (alle unterstützten Versionen) |
| Dateiabfragen | OPENROWSET(BULK ...) |
Dateien auf lokalem Datenträger, Netzwerk oder Cloud (Azure Blob, ADLS, S3, OneLake) | SAS-Token, Zugriffsschlüssel, verwaltete Identität, Microsoft Entra-ID | Ja für Cloud*; Nein für lokal | SQL Server 2005; SQL Server 2022 (16.x) und höhere Versionen (Cloud); Azure SQL |
| PolyBase-Connectoren |
CREATE EXTERNAL TABLE mit CREATE EXTERNAL DATA SOURCE unter Verwendung von sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Remote SQL Server, Oracle, Teradata, MongoDB, ODBC-Quellen | Nur SQL-Authentifizierung | Ja | SQL Server 2019 (15.x) und höhere Versionen (Windows); SQL Server 2025 (17.x) und höhere Versionen (Linux) |
PolyBase-Dienste sind für den Clouddateizugriff in SQL Server 2019 (15.x) und SQL Server 2022 (16.x) erforderlich. SQL Server 2025 (17.x) und höhere Versionen verfügen über native Clouddateiunterstützung und erfordern polyBase für CSV, Parkett oder Delta nicht mehr.
Wann jeder Ansatz verwendet werden soll
Verwenden Sie OLE DB OPENROWSET für:
- Schnelle, einmalige Ad-hoc-Abfragen ohne Erstellen dauerhafter Objekte
- Microsoft Entra ID- oder Managed Identity-Authentifizierung (mit MSOLEDBSQL)
- Vermeiden von PolyBase-Dienstabhängigkeiten
- Verbindung zu einer beliebigen Datenquelle mit OLE DB-Anbieter herstellen
Verwenden Sie File OPENROWSET(BULK) für:
- Ad-hoc-Dateisuche und Schemaermittlung
- Schnelle Transformationen und Vorschauen vor der Festlegung einer Tabellendefinition
- Flexible Spaltentransformationen inline (Umwandlung, Filtern, berechnete Spalten)
- Daten, die sich nicht häufig ändern und keine dauerhaften Metadaten benötigen
Verwenden Sie PolyBase-Connectors mit CREATE EXTERNAL TABLE für:
- Dauerhafte, wiederverwendbare Tabellendefinitionen, auf die von mehreren Benutzern oder Anwendungen zugegriffen wird
- Produktionsworkloads, die Statistiken und Abfrageplanoptimierung erfordern
- Pushdownberechnung für Remotequellen (Filter pushen an Oracle, SQL Server usw.)
- Geteilte Governance und Sicherheit (einmal erstellt, benötigen Benutzer nur
SELECTdie Berechtigung) - Wenn die SQL-Authentifizierung für die Remotequelle verfügbar ist
OPENROWSET (OLE DB) – Ad-hoc-Remoteabfragen (keine PolyBase-Dienste erforderlich)
Die OLE DB-Form von OPENROWSET verbindet sich über einen OLE DB-Anbieter mit einer Remotedatenquelle, führt eine Pass-Through-Abfrage aus und gibt die Ergebnisse als Zeilenmenge zurück. Es ist eine einmalige Ad-hoc-Alternative zu einem verknüpften Server. Es werden keine dauerhaften Metadaten erstellt. Diese Syntax erfordert keine PolyBase-Dienste und unterstützt keine Clouddateien oder externen Datenquellen.
Diese Beispielabfrage stellt eine Verbindung mit einem Remote-SQL Server über OLE DB (nicht PolyBase) dar.
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK) – dateibasierte Abfragen (PolyBase)
Die BULK-Form von OPENROWSET liest Daten direkt aus Dateien. In SQL Server 2019 (15.x) und früheren Versionen liest sie aus lokalen oder UNC-Dateipfaden und erfordert eine Formatdatei. In SQL Server 2022 (16.x) und höheren Versionen können Sie mit den Parametern aus dem DATA_SOURCEFORMAT lesen. Dieser Ansatz ist die polyBase-integrierte Version, die für die Datenvirtualisierung verwendet wird.
Im Kontext der PolyBase- und Datenvirtualisierung bedeutet es, wenn in dieser Anleitung auf OPENROWSET verwiesen wird, die OPENROWSET(BULK ...)-Syntax mit einer FORMAT-Klausel zum Abfragen externer Dateien.
Beispiele:
In dieser Beispielabfrage wird eine Parkettdatei aus Azure Blob Storage (SQL Server 2022 und höher) gelesen.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
Diese Beispielabfrage liest eine Parkettdatei mit einem Inlinepfad (Azure SQL-Datenbank, Azure SQL Managed Instance).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Gründe für die Verwendung von OPENROWSET im Vergleich zu externen Tabellen
Mit beiden OPENROWSET(BULK ...) und externen Tabellen können Sie externe Daten mit T-SQL abfragen, sie sind jedoch für unterschiedliche Anwendungsfälle konzipiert. In der folgenden Tabelle sind die wichtigsten Unterschiede zusammengefasst, mit denen Sie entscheiden können, welcher Ansatz zu Ihrem Szenario passt.
| Fähigkeit | OPENROWSET(BULK ...) |
Externe Tabelle |
|---|---|---|
| Purpose | Ad-hoc-Erkundungen und einmalige Abfragen | Persistente, wiederverwendbare Tabellendefinition |
| In der Datenbank gespeicherte Metadaten | Nein. Nach ausführung der Abfrage wird nichts gespeichert. | Ja. Die Tabellendefinition, Datenquelle und das Dateiformat werden als Datenbankobjekte gespeichert. |
| Schemadefinition | Automatisch aus der Datei (Parquet) abgeleitet oder inline mit einer WITH Anweisung angegeben |
Explizit in der CREATE EXTERNAL TABLE Anweisung definiert |
| Erlaubnisse | Erfordert ADMINISTER BULK OPERATIONS oder ADMINISTER DATABASE BULK OPERATIONS |
Nach der Erstellung reicht die Standardberechtigung SELECT für die Tabelle aus. |
| Berechnete Spalten | Ja. Fügen Sie Ausdrücke und berechnete Spalten in der SELECT Liste hinzu. Metadatenfunktionen wie filename() und filepath() sind hier nur verfügbar. |
Nein. Feste Spaltenliste; Durchführen von Transformationen in einer Ansicht oder in der Abfrage, die die externe Tabelle liest |
| Statistik | Azure SQL: manuelle Einzelspaltenstatistiken über sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) und höhere Versionen: Automatisches Erstellen von Statistiken für Prädikate (keine manuellen Statistiken auf SQL Server). Siehe OPENROWSET manual statistics. |
Vollständige CREATE STATISTICS Unterstützung auf allen Plattformen sowie automatisches Erstellen in SQL Server 2022 (16.x) und höheren Versionen. Weitere Informationen finden Sie unter Externe Tabellen: Manuelles Erstellen von Statistiken. |
| Pushdown | Eingeschränkter Support. Der Motor könnte möglicherweise Filter an die Dateiabfrage weiterleiten, aber es gibt keinen Pushdown für Remote-RDBMS-Datenquellen. | Ja. Unterstützt Pushdownberechnung für RDBMS-Connectors (SQL Server, Oracle, Teradata, MongoDB) |
| Am besten geeignet für | Datensuche, Schemaermittlung, Prototypabfragen, einmaliges Laden von Daten, flexible Transformationen | Produktionsworkloads, wiederholte Abfragen, gemeinsamer Zugriff für Benutzer, Dashboards und Berichte |
Verwenden von OPENROWSET, wenn Sie Flexibilität benötigen
Mit OPENROWSET können Sie eine Datei untersuchen, verschiedene Schemas testen oder berechnete Spalten und Transformationen hinzufügen, ohne dauerhafte Objekte zu erstellen. Sie können z. B. den Dateipfad als Spalte extrahieren, Datentypen inline umwandeln oder nach berechneten Ausdrücken in einer einzelnen Abfrage filtern.
Diese Beispielabfrage enthält berechnete Spalten und Transformationen:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Tipp
Die filepath()- und filename()-Funktionen sind in Azure SQL-Datenbank, Azure SQL Managed Instance und SQL Server 2022 (16.x) und späteren Versionen verfügbar. Sie ermöglichen es Ihnen, nach Teilen des Dateipfads (Partitionsausscheidung) zu filtern und den Namen der Quelldatei als Spalte verfügbar zu machen, was mit externen Tabellen nicht direkt möglich ist.
Verwenden externer Tabellen, wenn Sie Persistenz und Governance benötigen
Verwenden Sie externe Tabellen, wenn mehrere Benutzer oder Anwendungen dieselben externen Daten wiederholt abfragen müssen. Sie definieren das Schema, die Datenquelle und die Anmeldeinformationen einmal, und speichern sie in der Datenbank. Verbraucher benötigen nur die Berechtigung SELECT für die Tabelle.
Externe Tabellen unterstützen auch Statistiken, die der Abfrageoptimierer zum Erstellen besserer Ausführungspläne verwendet. Sie können Statistiken manuell erstellen oder das Modul automatisch erstellen lassen (SQL Server 2022 (16.x) und höhere Versionen).
Diese Beispielabfrage erstellt Statistiken für eine externe Tabelle für bessere Abfragepläne.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Weitere Informationen zu Statistiken für beide Ansätze finden Sie unter PolyBase-Leistungsüberlegungen – Statistik.
BULK INSERT vs. OPENROWSET(BULK): Welches sollte ich verwenden?
Sowohl BULK INSERT als auch OPENROWSET(BULK ...) importieren Daten aus Dateien in SQL Server mithilfe des gleichen zugrunde liegenden Bulk-Load-Mechanismus. Sie unterscheiden sich jedoch in Syntax, Flexibilität und was Sie mit den Ergebnissen tun können. In der folgenden Tabelle sind die wichtigsten Unterschiede zusammengefasst:
Hinweis
BULK INSERT ist in der SQL-Datenbank in Fabric nicht verfügbar. Verwenden Sie OPENROWSET(BULK ...) gegen OneLake für Fabric.
| Fähigkeit | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Grundzweck | Lädt Daten aus einer Datei direkt in eine Zieltabelle. | Gibt ein Rowset zurück, das Sie in einer SELECT- oder INSERT ... SELECT-Anweisung verwenden. |
| Verwendungsmuster | Eigenständige Anweisung: BULK INSERT <table> FROM '<file>' |
Muss in einer Abfrage verwendet werden: SELECT * FROM OPENROWSET(BULK ...) oder INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| Erfordert eine Zieltabelle? | Ja. Schreibt immer direkt in eine Tabelle | Nein. Sie können SELECT verwenden, ohne es irgendwo einfügen zu müssen, oder es in eine Tabelle oder temporäre Tabelle einfügen. |
| Spaltentransformationen während des Ladens | Eingeschränkter Support. Die Daten fließen von Datei zu Tabelle as-is (Zuordnung gesteuert durch Formatdatei oder Spaltenreihenfolge) | Vollständiger Support. Sie können Ausdrücke, CASTWHERE Filter, JOIN andere Tabellen und berechnete Spalten in der Umgebung hinzufügen.SELECT |
| Tabellenhinweise | Die WITH Klausel enthält Unterstützung für BATCHSIZE, CHECK_CONSTRAINTS, FIRE_TRIGGERS, KEEPIDENTITY, KEEPNULLS, und TABLOCK mehr |
Unterstützt Tabellenhinweise über die INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) Syntax |
| Import mit einem einzigen Wert (Large-Object, LOB) | Nicht unterstützt | Ja. Unterstützt SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB, um eine gesamte Datei als einen varbinary(max)-, varchar(max)- oder nvarchar(max)-Wert zu importieren. |
| Formatdateien | Ja. Unterstützt über (XML und Nicht-XML) | Ja. Unterstützt (XML und Nicht-XML) |
| Zugriff auf Clouddateien (Azure Blob Storage, ADLS Gen2, S3) | Ja. Unterstützt über DATA_SOURCE Parameter (SQL Server 2017 (14.x) und höhere Versionen, Azure SQL) |
Ja. Unterstützt über DATA_SOURCE Parameter oder Inline-URL mit FORMAT Klausel (SQL Server 2022 (16.x) und höher, Azure SQL) |
| Parquet- oder Delta-Dateien | Nicht unterstützt. Nur CSV-/durch Trennzeichen getrennte Text | Ja. Unterstützt mit FORMAT = 'PARQUET' oder FORMAT = 'DELTA' (SQL Server 2022 (16.x) und höheren Versionen, Azure SQL) |
| Berechtigung erforderlich |
ADMINISTER BULK OPERATIONS oder ADMINISTER DATABASE BULK OPERATIONS, plus INSERT in der Zieltabelle |
ADMINISTER BULK OPERATIONS oder ADMINISTER DATABASE BULK OPERATIONS |
| Minimale Protokollierung | Ja. Unterstützt in einfachen oder massenprotokollierten Wiederherstellungsmodellen mit TABLOCK |
Ja. Unterstützt bei Verwendung mit INSERT ... SELECT und TABLOCK |
Wann wählen Sie "MASSENEINFÜGUNG" aus
Verwenden Sie diese Option BULK INSERT , wenn Sie eine einfache Datei-zu-Tabelle laden und während des Imports keine Daten transformieren, filtern oder verknüpfen müssen. Es verwendet eine einfachere Syntax für CSV- oder andere durch Trennzeichen getrennte Dateien:
Diese Beispielabfrage lädt eine CSV-Datei aus Azure Blob Storage direkt in eine Tabelle.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
Diese Beispielabfrage lädt eine lokale Datei mit einer Formatdatei für die Spaltenzuordnung.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Wann sollte OPENROWSET(BULK) verwendet werden?
Verwenden Sie OPENROWSET(BULK ...), wenn Sie eine oder mehrere der folgenden Voraussetzungen benötigen:
- Abfragen oder Anzeigen einer Vorschau von Dateidaten, ohne zuerst eine Tabelle zu erstellen.
- Transformieren, Filtern oder Verknüpfen von Daten während des Imports.
-
Laden von Parkett- oder Delta-Dateien (unterstützt nur
OPENROWSETdiese Formate). -
Importieren einer gesamten Datei als einzelner LOB-Wert (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
In diesem Beispiel wird eine CSV-Datei aus Azure Blob Storage angezeigt, ohne dass die Daten irgendwo eingefügt werden.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
In diesem Beispiel werden Daten mit Transformation und Filterung eingefügt.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
In dieser Beispielabfrage wird eine Parkettdatei geladen (nicht möglich mit BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
In diesem Beispiel wird eine gesamte XML-Datei als einzelner varbinary(max)-Wert importiert.
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Tipp
Ein Ansatz besteht darin, OPENROWSET(BULK ...) innerhalb einer SELECT zu verwenden, um Dateidaten zu erkunden und zu validieren, und dann zu BULK INSERT für die endgültige Produktionslast zu wechseln, falls Sie keine Transformationen benötigen. Wenn Sie Parquet- oder Delta-Unterstützung oder Inline-Filterung benötigen, bleiben Sie bei OPENROWSET.
Weitere Informationen finden Sie in den folgenden verwandten Leitfäden:
- Verwenden Sie BULK INSERT oder OPENROWSET(BULK...), um Daten in SQL Server zu importieren: Eine ausführliche Anleitung mit Sicherheitsüberlegungen.
-
Massenimport und -export von Daten (SQL Server): Eine Übersicht über alle Massendatenbewegungsmethoden (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): Eine vollständige T-SQL-Referenz.
- OPENROWSET BULK (Transact-SQL): Eine vollständige T-SQL-Referenz.
- Beispiele für den Massenzugriff auf Daten in Azure Blob Storage: Parallele Beispiele mit beiden Methoden mit Azure Storage.
-
Massenimport großer Objektdaten mit OPENROWSET Bulk Rowset Provider (SQL Server):
SINGLE_BLOB, ,SINGLE_CLOBundSINGLE_NCLOBBeispielen. - Verwenden Sie eine Formatdatei zum Massenimport von Daten (SQL Server): Formatieren der Dateiverwendung mit beiden Methoden.
Nützliche Metadatenfunktionen
Wenn Sie externe Dateien mit OPENROWSET oder externen Tabellen abfragen, können Sie mehrere integrierte Funktionen und Prozeduren verwenden, um Dateimetadaten zu prüfen, Schemas zu ermitteln und partitionsfähige Abfragen zu implementieren.
filepath() und filename()
Die Funktionen filepath() und filename() geben Teile des Dateipfads oder des Dateinamens für jede Zeile im Ergebnisdatensatz zurück. Sie sind besonders nützlich für:
Partitionslöschung: Filtern Sie nach Ordnersegmenten (z. B. Jahres-/Monat/Tag-Partitionen), sodass das Modul nur die übereinstimmenden Dateien liest, anstatt alles zu scannen.
Verfügbarmachen von Quellmetadaten: Fügen Sie den ursprünglichen Dateinamen oder Pfad als Spalte in die Abfrageergebnisse ein, was für die Überwachung oder das Debuggen hilfreich ist.
| Funktion | Rückkehr | Beispiel |
|---|---|---|
filename() |
Der Dateiname (einschließlich Erweiterung) der Quelldatei für jede Zeile | sales_2025_01.parquet |
filepath(N) |
Das N-te Ordnersegment vom Platzhalter (*) im Pfad BULK, wobei N bei 1 beginnt |
Für den Pfad sales/2025/01/*.parquet gibt filepath(1)2025 zurück, und filepath(2) gibt 01 zurück. |
Gilt für: Azure SQL-Datenbank, Azure SQL Managed Instance, SQL Server 2022 (16.x) und höhere Versionen, SQL-Datenbank in Fabric.
Dieses Beispielabfrage verwendet filepath() zur Partitionseleminierung und filename() zur Identifizierung von Quelldateien. Er liest nur Dateien unter dem /2025/ Ordner und liest nur Dateien unter dem /06/ Unterordner.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Tipp
Platzieren Sie filepath() Filter in der WHERE Klausel statt in einer Unterabfrage oder CTE. Wenn sich der Filter in der WHERE Klausel befindet, kann die Engine eine Partitionseliminierung auf der Ebene des Dateiscans durchführen, wodurch die E/A erheblich reduziert wird.
sp_describe_first_result_set – OPENROWSET-Spaltentypen ermitteln
Bei der Verwendung von OPENROWSET mit Parquet-Dateien erkennt die Engine die Spaltendatentypen automatisch (Schemaerkennung). Die abgeleiteten Typen können größer als erforderlich sein. Beispielsweise werden Textspalten häufig als varchar(8000) abgeleitet, da die Metadaten von Parquet keine maximale Länge enthalten. Diese Wahl kann die Leistung beeinträchtigen und mehr Arbeitsspeicher verbrauchen.
Verwenden Sie sp_describe_first_result_set, um das abgeleitete Schema zu prüfen, bevor Sie die Abfrage abschließen. Nachdem die abgeleiteten Typen angezeigt wurden, geben Sie schmalere Typen in einer WITH Klausel an, um die Leistung zu verbessern.
Schritt 1: Überprüfen des abgeleiteten Schemas.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';Die Ausgabe zeigt den Namen jeder Spalte, den abgeleiteten Datentyp, die maximale Länge, Genauigkeit und Skalierung der einzelnen Spalten an. Wenn varchar(8000) angezeigt wird, wo eine Varchar(100) ausreicht, überschreiben Sie sie:
Schritt 2: Verwenden Sie explizite Typen, um eine bessere Leistung zu erzielen.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
Schemaerkennung funktioniert nur mit Parquet-Dateien. Geben Sie für CSV-Dateien immer Spaltendefinitionen entweder in einer WITH Klausel (für OPENROWSET) oder in der CREATE EXTERNAL TABLE Anweisung an.
sp_describe_first_result_set ist eine allgemeine SQL Server- und Azure SQL-Prozedur, aber es ist besonders nützlich für OPENROWSET Abfragen. Weitere Informationen finden Sie unter sp_describe_first_result_set.
Leistung, Problembehandlung und bewährte Methoden
Verwenden Sie nach der Implementierung der Datenvirtualisierung diese Leitfäden, um Die Leistung zu optimieren, Probleme zu diagnostizieren und die Produktionsbereitschaft sicherzustellen:
| Fläche | Artikel | Einzelheiten |
|---|---|---|
| PolyBase-Leistung | Leistungsüberlegungen in PolyBase für SQL Server | Statistiken, Pushdown, Parallelität und Speicherverwaltung |
| Pushdownberechnung | Pushdownberechnungen in PolyBase | Gibt an, welche Vorgänge an die Remotequelle übertragen werden. |
| So können Sie feststellen, ob ein Pushdown aufgetreten ist | Wie man feststellt, ob ein externer Pushdown aufgetreten ist | Abfragepläne und DMVs |
| Problembehandlung | Überwachen und Beheben von Problemen mit PolyBase | Häufige Fehler und deren Lösungen |
| Kerberos-Konnektivität | Problembehandlung: PolyBase-Kerberos-Konnektivität | |
| Häufig gestellte Fragen | Häufig gestellte Fragen zu PolyBase | |
| Fehler und Lösungen | PolyBase-Fehler und mögliche Lösungen |