Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Leistungsprobleme mit der Kopieraktivität in Azure Data Factory analysieren und beheben können.
Nachdem Sie eine Kopieraktivität ausgeführt haben, können Sie das Ausführungsergebnis und die Leistungsstatistik in der Ansicht zur Überwachung der Kopieraktivität erfassen. Die folgende Abbildung zeigt ein Beispiel.
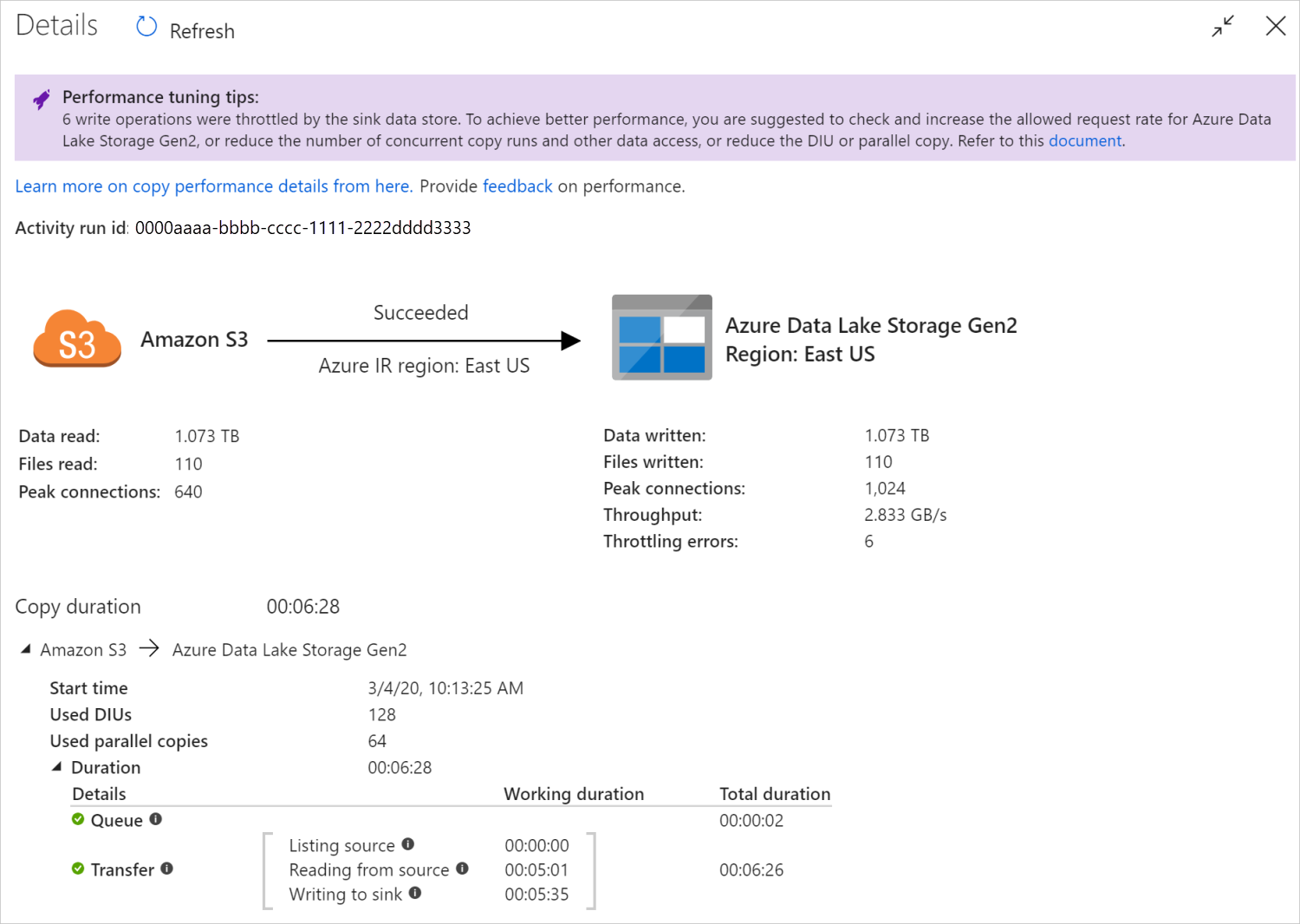
Tipps zur Leistungsoptimierung
In einigen Szenarien werden bei der Ausführung einer Kopieraktivität oben Tipps zur Leistungsoptimierung angezeigt. Dies ist in der obigen Abbildung dargestellt. Die Tipps geben Ihnen Aufschluss über den Engpass, der von dem Dienst für den jeweiligen Kopiervorgang identifiziert wurde. Sie erhalten außerdem Vorschläge, wie der Kopierdurchsatz erhöht werden kann. Versuchen Sie, die empfohlene Änderung vorzunehmen, und führen Sie den Kopiervorgang dann erneut durch.
Als Hilfe ist hier angegeben, für welche Fälle in den Tipps zur Leistungsoptimierung derzeit Vorschläge gemacht werden:
| Kategorie | Tipps zur Leistungsoptimierung |
|---|---|
| Bezogen auf den Datenspeicher | Laden von Daten in Azure Synapse Analytics: Es wird vorgeschlagen, PolyBase oder eine COPY-Anweisung zu verwenden, falls dies nicht bereits genutzt wird. |
| Kopieren von Daten von/zu Azure SQL-Datenbank: Bei hoher DTU-Auslastung wird ein Upgrade auf eine höhere Leistungsstufe vorgeschlagen. | |
| Kopieren von Daten für Azure Cosmos DB: Wenn für die RU eine hohe Auslastung besteht, wird ein Upgrade auf eine höhere RU vorgeschlagen. | |
| Kopieren von Daten aus einer SAP-Tabelle: Es wird vorgeschlagen, beim Kopieren von großen Datenmengen die Partitionsoption des SAP-Connectors zum Aktivieren der parallelen Last und zum Erhöhen der maximalen Partitionsanzahl zu nutzen. | |
| Erfassen von Daten aus Amazon Redshift: Es wird vorgeschlagen, UNLOAD zu verwenden, falls dies nicht bereits genutzt wird. | |
| Drosselung des Datenbankzugriffs | Wenn beim Kopieren durch den Datenspeicher viele Lese-/Schreibvorgänge gedrosselt werden, sollten Sie die zulässige Anforderungsrate für den Datenspeicher überprüfen und erhöhen oder die gleichzeitige Arbeitsauslastung reduzieren. |
| Integrationslaufzeit | Wenn Sie eine selbstgehostete Integration Runtime (IR) nutzen und die Kopieraktivität lange in der Warteschlange verbleibt, bis Ressourcen zur Verfügung stehen, die die IR ausführen kann, sollten Sie ein horizontales oder vertikales Hochskalieren Ihrer IR in Erwägung ziehen. |
| Bei Verwendung einer Azure Integration Runtime, die sich nicht in einer optimalen Region befindet, und einer daraus resultierenden langsamen Durchführung von Lese-/Schreibvorgängen wird vorgeschlagen, die Verwendung einer IR in einer anderen Region zu konfigurieren. | |
| Fehlertoleranz | Wenn Sie die Fehlertoleranz konfigurieren und das Überspringen von inkompatiblen Zeilen zu einer langsamen Leistung führt, lautet der Vorschlag, die Kompatibilität von Quellen- und Senkendaten sicherzustellen. |
| stufenweise Kopieren | Wenn das gestaffelte Kopieren konfiguriert ist, aber für Ihr Quelle-Senke-Paar nicht hilfreich ist, sollten Sie die Entfernung in Erwägung ziehen. |
| Fortfahren | Wenn die Kopieraktivität ab dem letzten Fehlerpunkt fortgesetzt wird und Sie die DIU-Einstellung nach der ursprünglichen Ausführung ändern, sollte Ihnen bewusst sein, dass die neue DIU-Einstellung nicht wirksam wird. |
Verständnis der Ausführungsdetails der Kopieraktivität
In den Details zur Ausführung und Dauer unten in der Ansicht zur Überwachung der Kopieraktivität sind die wichtigen Phasen beschrieben, die Ihre Kopieraktivität durchläuft (siehe Beispiel am Anfang dieses Artikels). Dies ist besonders hilfreich für die Problembehandlung in Bezug auf die Kopierleistung. Der Engpass Ihres Kopierlaufs ist derjenige, der am längsten dauert. Betrachten Sie die folgende Tabelle zur Definition der einzelnen Phasen und erfahren Sie, wie Sie anhand dieser Informationen Probleme bei der Kopieraktivität auf Azure IR und Probleme bei der Kopieraktivität auf selbstgehosteter Integration Runtime beheben können.
| Phase | BESCHREIBUNG |
|---|---|
| Warteschlange | Die bis zum tatsächlichen Start der Kopieraktivität in der Integration Runtime verstrichene Zeit. |
| Kopiervorbereitungsskript | Die Zeit, die zwischen dem Starten der Kopieraktivität in IR und dem Abschließen der Kopieraktivität für die Ausführung des Kopiervorbereitungsskripts im Senkendatenspeicher verstrichen ist. Wird angewendet, wenn Sie das Kopiervorbereitungsskript für Datenbanksenken konfigurieren, z. B. beim Schreiben von Daten in Azure SQL-Datenbank zur Bereinigung vor dem Kopieren neuer Daten. |
| Übertragen | Die verstrichene Zeit zwischen dem Ende des vorherigen Schritts und der Übertragung aller Daten aus der Quelle in die Senke durch das IR-System. Beachten Sie, dass die Teilschritte unter „Übertragen“ parallel ausgeführt werden und dass einige Vorgänge derzeit nicht angezeigt werden, z. B. Analysieren/Generieren des Dateiformats. - Zeit bis zum ersten Byte: Die Zeit vom Ende des vorherigen Schritts bis zu dem Zeitpunkt, zu dem das erste Byte aus dem Quelldatenspeicher von der IR empfangen wird. Wird auf nicht dateibasierte Quellen angewendet. - Quellenauflistung: Die Dauer, die für das Auflisten von Quelldateien oder Datenpartitionen benötigt wird. Letzteres gilt, wenn Sie Partitionsoptionen für Datenbankquellen konfigurieren, z. B. beim Kopieren von Daten aus Datenbanken wie Oracle, SAP HANA, Teradata, Netezza usw. - Lesen von der Quelle: Die Dauer für das Abrufen von Daten aus dem Quelldatenspeicher. - Schreiben in die Senke: Die Dauer für das Schreiben von Daten in den Senkendatenspeicher. Beachten Sie, dass einige Connectors diese Metrik aktuell nicht enthalten, z. B. Azure KI-Suche, Azure Data Explorer, Azure Table Storage, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce und Salesforce Service Cloud. |
Problembehandlung für die Kopieraktivität bei Azure IR
Führen Sie die Schritte zur Optimierung der Leistung aus, um den Leistungstest für Ihr Szenario zu planen und durchzuführen.
Gehen Sie wie folgt vor, falls die Leistung der Kopieraktivität nicht Ihre Erwartungen erfüllt: Wenn Sie die Problembehandlung für eine einzelne ausgeführte Kopieraktivität unter Azure Integration Runtime durchführen möchten und in der Ansicht für die Überwachung des Kopiervorgangs Tipps zur Leistungsoptimierung angezeigt werden, sollten Sie den Vorschlag befolgen und es dann erneut versuchen. Lesen Sie andernfalls den Abschnitt Grundlegendes zur Ausführung der Kopieraktivität, überprüfen Sie, welche Phase am längsten dauert, und befolgen Sie die unten angegebene Anleitung, um die Kopierleistung zu steigern:
Lange Dauer für „Kopiervorbereitungsskript“: Dies bedeutet, dass es lange dauert, bis das in der Senkendatenbank ausgeführte Kopiervorbereitungsskript abgeschlossen ist. Optimieren Sie die Logik des angegebenen Kopiervorbereitungsskripts, um die Leistung zu verbessern. Wenden Sie sich an Ihr Datenbankteam, falls Sie weitere Hilfe zur Verbesserung des Skripts benötigen.
"Übertragung - Zeit bis zum ersten Byte" hat eine lange Arbeitsdauer erlebt: Ihre Quellabfrage benötigt eine lange Zeit, um Daten zurückzugeben. Dies kann bedeuten, dass die Abfrage lange dauert, um von der Quelle verarbeitet zu werden, weil die Quelle mit anderen Aufgaben beschäftigt ist, die Abfrage nicht optimal ist, oder die Daten so gespeichert sind, dass sie lange zur Abrufung benötigen. Überlegen Sie, ob andere Abfragen gleichzeitig auf dieser Quelle ausgeführt werden, oder wenn aktualisierungen vorhanden sind, die Sie an Ihrer Abfrage vornehmen können, damit sie Daten schneller abrufen kann. Wenn es ein Team gibt, das Ihre Datenquelle verwaltet, wenden Sie sich an sie, um Ihre Abfrage zu ändern oder die Quellleistung zu überprüfen.
„Übertragen: Quellenauflistung“ erlebte lange Arbeitsdauer: Dies bedeutet, dass das Auflisten von Quelldateien oder Datenpartitionen der Quelldatenbank langsam erfolgt.
Beachten Sie beim Kopieren von Daten von einer dateibasierten Quelle Folgendes, wenn Sie einen Platzhalterfilter für einen Ordnerpfad oder Dateinamen (
wildcardFolderPathoderwildcardFileName) oder Filter für das letzte Änderungsdatum der Datei (modifiedDatetimeStartodermodifiedDatetimeEnd) verwenden: Diese Filterung führt dazu, dass von der Kopieraktivität alle Dateien des angegebenen Ordners auf der Clientseite aufgelistet werden und anschließend der Filter angewendet wird. Eine solche Auflistung von Dateien kann zu einem Engpass werden. Dies gilt besonders, wenn nur eine geringe Menge von Dateien die Filterregel erfüllt.Überprüfen Sie, ob Sie Dateien basierend auf einem datetime-partitionierten Dateipfad oder Dateinamen kopieren können. Diese Vorgehensweise ist nicht mit einer Belastung für die Quelle bei der Auflistung verbunden.
Überprüfen Sie, ob Sie stattdessen den nativen Filter des Datenspeichers verwenden können, also „prefix“ für Amazon S3/Azure Blob Storage/Azure File und „listAfter/listBefore“ für ADLS Gen1. Diese Filter sind serverseitige Datenspeicherfilter mit einer besseren Leistung.
Erwägen Sie, große Einzeldatensätze in mehrere kleinere Datensätze aufzuteilen, und lassen Sie diese Kopieraufträge gleichzeitig ausführen, die jeweils einen Teil der Daten bearbeiten. Hierfür können Sie „Lookup/GetMetadata + ForEach + Copy“ verwenden. Die Lösungsvorlagen Kopieren von Dateien aus mehreren Containern und Migrieren von Daten aus Amazon S3 zu ADLS Gen2 dienen hier als allgemeine Beispiele.
Überprüfen Sie, ob vom Dienst Drosselungsfehler an der Quelle gemeldet werden oder ob Ihr Datenspeicher sich in einem starken Auslastungszustand befindet. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
Verwenden Sie Azure IR in derselben oder in einer Region, die nicht weit von der Region Ihres Quelldatenspeichers entfernt ist.
„Übertragung - Lesen von der Quelle“ benötigte eine lange Bearbeitungsdauer :
Halten Sie sich an die bewährte Methode für das connectorspezifische Laden von Daten, falls sie für Sie zutrifft. Wenn Sie beispielsweise Daten von Amazon Redshift kopieren, sollten Sie konfigurieren, dass Redshift UNLOAD verwendet wird.
Überprüfen Sie, ob von dem Dienst Drosselungsfehler für die Quelle gemeldet werden oder für Ihren Datenspeicher ein hoher Auslastungszustand besteht. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
Überprüfen Sie Ihre Kopierquelle und das Senkenmuster:
Wenn Ihr Kopiermuster mehr als vier Datenintegrationseinheiten (DIUs) unterstützt, siehe dieser Abschnitt für weitere Details. Generell können Sie versuchen, die Anzahl der DIUs zu erhöhen, um die Leistung zu verbessern.
Erwägen Sie andernfalls, ein großes einzelnes Dataset in mehrere kleinere Datasets zu unterteilen und ermöglichen Sie die gleichzeitige Ausführung dieser Kopieraufträge, die jeweils einen Teil der Daten bearbeiten. Hierfür können Sie „Lookup/GetMetadata + ForEach + Copy“ verwenden. Die Lösungsvorlagen Kopieren von Dateien aus mehreren Containern, Migrieren von Daten aus Amazon S3 zu ADLS Gen2 und Massenkopieren mit Steuertabelle dienen hier als allgemeine Beispiele.
Verwenden Sie Azure IR in derselben oder in einer Region, die nicht weit von der Region Ihres Quelldatenspeichers entfernt ist.
„Übertragen - Schreiben in das Ziel“ dauerte lange
Halten Sie sich an die bewährte Methode für das connectorspezifische Laden von Daten, falls sie für Sie zutrifft. Verwenden Sie beispielsweise beim Kopieren von Daten in Azure Synapse Analytics PolyBase oder die COPY-Anweisung.
Überprüfen Sie, ob der Dienst Drosselungsfehler bei der Senke meldet oder ob Ihr Datenspeicher eine hohe Auslastung aufweist. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
Überprüfen Sie Ihre Kopierquelle und das Senkenmuster:
Wenn Ihr Kopiermuster mehr als vier Datenintegrationseinheiten (DIUs) unterstützt, lesen Sie die Details in diesem Abschnitt. Generell können Sie versuchen, die DIUs zu erhöhen, um eine bessere Leistung zu erzielen.
Optimieren Sie andernfalls schrittweise die parallelen Kopien. Zu viele parallele Kopien können sogar die Leistung beeinträchtigen.
Verwenden Sie Azure IR in derselben oder in einer Region, die nicht weit von der Region Ihres Senkendatenspeichers entfernt ist.
Problembehandlung für die Kopieraktivität bei selbstgehosteter Integration Runtime
Führen Sie die Schritte zur Optimierung der Leistung aus, um den Leistungstest für Ihr Szenario zu planen und durchzuführen.
Gehen Sie wie folgt vor, falls die Kopierleistung nicht Ihre Erwartungen erfüllt: Wenn Sie die Problembehandlung für eine einzelne ausgeführte Kopieraktivität unter Azure Integration Runtime durchführen möchten und in der Ansicht für die Überwachung des Kopiervorgangs Tipps zur Leistungsoptimierung angezeigt werden, sollten Sie den Vorschlag befolgen und es dann erneut versuchen. Lesen Sie andernfalls den Abschnitt Grundlegendes zur Ausführung der Kopieraktivität, überprüfen Sie, welche Phase am längsten dauert, und befolgen Sie die unten angegebene Anleitung, um die Kopierleistung zu steigern:
Lange Wartezeit bei „Warteschlange“: Dies bedeutet, dass die Kopieraktivität lange in der Warteschlange verbleibt, bis Ihre selbstgehostete Integration Runtime über die benötigten Ressourcen zur Ausführung verfügt. Überprüfen Sie die Kapazität und Nutzung für die IR, und führen Sie je nach Workload das horizontale oder vertikale Hochskalieren durch.
Lange Dauer für „Übertragen: Zeit bis zum ersten Byte“ : Dies bedeutet, dass es lange dauert, bis von Ihrer Quellabfrage Daten zurückgegeben werden. Überprüfen und optimieren Sie die Abfrage oder den Server. Wenden Sie sich an Ihr Datenspeicherteam, falls Sie weitere Hilfe benötigen.
„Übertragen: Quellenauflistung“ erlebte lange Arbeitsdauer: Dies bedeutet, dass das Auflisten von Quelldateien oder Datenpartitionen der Quelldatenbank langsam erfolgt.
Überprüfen Sie, ob die selbstgehostete IR-Maschine beim Herstellen der Verbindung zur Datenquelle eine niedrige Latenz aufweist. Wenn sich Ihre Quelle in Azure befindet, können Sie dieses Tool verwenden, um die Latenz zwischen dem Computer mit der selbstgehosteten IR und der Azure-Region zu überprüfen. Je geringer sie ist, desto besser ist es.
Beachten Sie beim Kopieren von Daten von einer dateibasierten Quelle Folgendes, wenn Sie einen Platzhalterfilter für einen Ordnerpfad oder Dateinamen (
wildcardFolderPathoderwildcardFileName) oder Filter für das letzte Änderungsdatum der Datei (modifiedDatetimeStartodermodifiedDatetimeEnd) verwenden: Diese Filterung führt dazu, dass von der Kopieraktivität alle Dateien des angegebenen Ordners auf der Clientseite aufgelistet werden und anschließend der Filter angewendet wird. Eine solche Auflistung von Dateien kann zu einem Engpass werden. Dies gilt besonders, wenn nur eine geringe Menge von Dateien die Filterregel erfüllt.Überprüfen Sie, ob Sie Dateien basierend auf einem datetime-partitionierten Dateipfad oder Dateinamen kopieren können. Diese Vorgehensweise ist nicht mit einer Belastung für die Quelle bei der Auflistung verbunden.
Überprüfen Sie, ob Sie stattdessen den nativen Filter des Datenspeichers verwenden können, also „prefix“ für Amazon S3/Azure Blob Storage/Azure File und „listAfter/listBefore“ für ADLS Gen1. Diese Filter sind serverseitige Datenspeicherfilter mit einer besseren Leistung.
Erwägen Sie, große Einzeldatensätze in mehrere kleinere Datensätze aufzuteilen, und lassen Sie diese Kopieraufträge gleichzeitig ausführen, die jeweils einen Teil der Daten bearbeiten. Hierfür können Sie „Lookup/GetMetadata + ForEach + Copy“ verwenden. Die Lösungsvorlagen Kopieren von Dateien aus mehreren Containern und Migrieren von Daten aus Amazon S3 zu ADLS Gen2 dienen hier als allgemeine Beispiele.
Überprüfen Sie, ob vom Dienst Drosselungsfehler an der Quelle gemeldet werden oder ob Ihr Datenspeicher sich in einem starken Auslastungszustand befindet. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
„Übertragung - Lesen von der Quelle“ benötigte eine lange Bearbeitungsdauer :
Überprüfen Sie, ob die selfgehostete IR-Maschine bei der Verbindung zum Quelldatenspeicher eine geringe Latenz aufweist. Wenn sich Ihre Quelle in Azure befindet, können Sie dieses Tool verwenden, um die Latenz zwischen dem Computer mit der selbstgehosteten IR und den Azure-Regionen zu überprüfen. Je geringer sie ist, desto besser ist es.
Überprüfen Sie, ob der Computer mit der selbstgehosteten IR über genügend Eingangsbandbreite verfügt, um die Daten effizient lesen und übertragen zu können. Wenn sich Ihr Quelldatenspeicher in Azure befindet, können Sie dieses Tool verwenden, um die Downloadgeschwindigkeit zu überprüfen.
Überprüfen Sie den CPU- und Arbeitsspeicher-Nutzungstrend der selbstgehosteten IR im Azure-Portal auf der Übersichtsseite Ihres Data Factory- oder Synapse-Arbeitsbereichs>>. Erwägen Sie, die IR horizontal oder vertikal hochzuskalieren, falls die CPU-Auslastung hoch ist oder nur wenig Arbeitsspeicher verfügbar ist.
Halten Sie sich an die bewährte Methode für das connectorspezifische Laden von Daten, sofern anwendbar. Zum Beispiel:
Aktivieren Sie die Datenpartitionsoptionen zum parallelen Kopieren von Daten, wenn Sie Daten aus Oracle, Netezza, Teradata, SAP HANA, SAP Table und SAP Open Hub kopieren.
Konfigurieren Sie beim Kopieren von Daten aus HDFS die Verwendung von DistCp.
Konfigurieren Sie beim Kopieren von Daten aus Amazon Redshift die Verwendung von Redshift UNLOAD.
Überprüfen Sie, ob von dem Dienst Drosselungsfehler für die Quelle gemeldet werden oder für Ihren Datenspeicher ein hoher Auslastungszustand besteht. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
Überprüfen Sie Ihre Kopierquelle und das Senkenmuster:
Wenn Sie Daten aus Datenspeichern kopieren, für die die Partitionsoption aktiviert ist, sollten Sie die parallelen Kopien schrittweise optimieren. Zu viele parallele Kopien können sogar die Leistung beeinträchtigen.
Erwägen Sie andernfalls, ein großes einzelnes Dataset in mehrere kleinere Datasets zu unterteilen und ermöglichen Sie die gleichzeitige Ausführung dieser Kopieraufträge, die jeweils einen Teil der Daten bearbeiten. Hierfür können Sie „Lookup/GetMetadata + ForEach + Copy“ verwenden. Die Lösungsvorlagen Kopieren von Dateien aus mehreren Containern, Migrieren von Daten aus Amazon S3 zu ADLS Gen2 und Massenkopieren mit Steuertabelle dienen hier als allgemeine Beispiele.
„Übertragen - Schreiben in das Ziel“ dauerte lange
Halten Sie sich an die bewährte Methode für das connectorspezifische Laden von Daten, falls sie für Sie zutrifft. Verwenden Sie beispielsweise beim Kopieren von Daten in Azure Synapse Analytics PolyBase oder die COPY-Anweisung.
Überprüfen Sie, ob der Computer mit der selbstgehosteten IR eine niedrige Latenz bei der Verbindung mit dem Zieldatenspeicher aufweist. Wenn sich Ihre Senke in Azure befindet, können Sie dieses Tool verwenden, um die Latenz zwischen dem selbstgehosteten IR-Computer und der Azure-Region zu überprüfen. Je geringer sie ist, desto besser.
Überprüfen Sie, ob die selbstgehostete IR-Maschine über genügend ausgehende Bandbreite verfügt, um die Daten effizient übertragen und schreiben zu können. Wenn sich Ihr Senkendatenspeicher in Azure befindet, können Sie dieses Tool verwenden, um die Uploadgeschwindigkeit zu überprüfen.
Überprüfen Sie, ob der Nutzungsverlauf von CPU und Arbeitsspeicher der selbstgehosteten IR im Azure-Portal auf der Übersichtsseite –> Ihres Data Factory- oder Synapse-Arbeitsbereichs–> angezeigt wird. Erwägen Sie, die IR horizontal oder vertikal hochzuskalieren, falls die CPU-Auslastung hoch ist oder nur wenig Arbeitsspeicher verfügbar ist.
Überprüfen Sie, ob der Dienst Drosselungsfehler bei der Senke meldet oder ob Ihr Datenspeicher eine hohe Auslastung aufweist. Wenn dies der Fall ist, sollten Sie entweder Ihre Workloads im Datenspeicher verringern, oder Ihren Datenspeicheradministrator darum bitten, das Drosselungslimit oder die verfügbaren Ressourcen zu erhöhen.
Sie könnten auch die parallelen Kopien nach und nach optimieren. Zu viele parallele Kopien können sogar die Leistung beeinträchtigen.
Leistung von Connector und IR
In diesem Abschnitt werden Anleitungen zur Behebung von Leistungsproblemen für bestimmte Connectortypen und Integrationslaufzeitumgebungen (IRs) untersucht.
Ausführungszeit für Aktivitäten variiert zwischen Azure IR und Azure IR für virtuelle Netzwerke
Die Ausführungszeit für Aktivitäten variiert je nachdem, auf welcher Integration Runtime das Dataset basiert.
Symptome: Durch einfaches Umschalten der Dropdownliste „Verknüpfter Dienst“ im Dataset werden dieselben Pipelineaktivitäten ausgeführt, die Laufzeiten unterscheiden sich jedoch stark. Wenn das Dataset auf der Managed Virtual Network Integration Runtime basiert, dauert es im Durchschnitt länger als die Ausführung auf Basis der Standard Integration Runtime.
Ursache: Wenn Sie die Details der Pipelineausführungen überprüfen, können Sie feststellen, dass die langsame Pipeline auf Managed Virtual Network IR ausgeführt wird, während die normale Pipeline auf Azure IR ausgeführt wird. Das Design des verwalteten virtuellen Netzwerks IR führt dazu, dass die Wartezeit in der Warteschlange länger ist als bei Azure IR. Dies liegt daran, dass wir keinen einzelnen Computeknoten pro Dienstinstanz reservieren. Daher gibt es eine Aufwärmphase, bevor jede Kopieraktivität startet, die hauptsächlich beim Beitritt zu einem virtuellen Netzwerk und nicht bei Azure IR auftritt.
Geringe Leistung beim Laden von Daten in Azure SQL-Datenbank
Symptome: Das Kopieren von Daten in die Azure SQL-Datenbank erfolgt langsam.
Ursache: Die Grundursache dieses Problems ist meistens ein Engpass bei der Azure SQL-Datenbank. Folgende Ursachen kommen in Betracht:
Die Azure SQL-Datenbank wird auf einer zu niedrigen Ebene ausgeführt.
Der DTU-Verbrauch der Azure SQL-Datenbank beträgt nahezu 100 %. Sie können die Leistung überwachen und ein Upgrade der Ebene der Azure SQL-Datenbank in Erwägung ziehen.
Die Indizes sind nicht ordnungsgemäß festgelegt. Entfernen Sie vor dem Laden der Daten alle Indizes, und erstellen Sie sie nach Abschluss des Ladevorgangs neu.
WriteBatchSize ist nicht groß genug für die Zeilengröße des Schemas. Versuchen Sie, den Wert der Eigenschaft zu erhöhen, um das Problem zu beheben.
Anstelle einer Masseneinfügung wird eine gespeicherte Prozedur verwendet, bei der eine geringere Leistung zu erwarten ist.
Timeout oder geringe Leistung beim Analysieren einer großen Excel-Datei
Symptome:
Wenn Sie ein Excel-Dataset erstellen und über „Verbindung/Speicher“ ein Schema importieren oder wenn Sie Arbeitsblätter auflisten, aktualisieren oder eine Datenvorschau anzeigen, kann ein Timeoutfehler auftreten, falls die Excel-Datei sehr groß ist.
Wenn Sie die Kopieraktivität zum Kopieren von Daten aus einer großen Excel-Datei (>= 100 MB) in einen anderen Datenspeicher verwenden, wird der Vorgang unter Umständen nur langsam ausgeführt, oder es tritt ein Fehler vom Typ „Nicht genügend Arbeitsspeicher“ auf.
Ursache:
Für Vorgänge wie das Importieren von Schemas, das Anzeigen einer Datenvorschau und das Auflisten von Arbeitsblättern eines Excel-Datasets. Das Timeout beträgt 100 s und ist statisch. Bei sehr umfangreichen Excel-Dateien können diese Vorgänge unter Umständen nicht innerhalb des Timeoutzeitraums abgeschlossen werden.
Die Kopieraktivität liest die gesamte Excel-Datei in den Speicher ein, lokalisiert dann das angegebene Arbeitsblatt und die Zellen, um die Daten auszulesen. Dieses Verhalten basiert auf dem zugrunde liegenden SDK, das von dem Dienst verwendet wird.
Lösung:
Zum Importieren von Schemas können Sie eine kleinere Beispieldatei generieren, bei der es sich um eine Teilmenge der Originaldatei handelt, und anstelle von „Schema aus Verbindung/Speicher importieren“ die Option „Schema aus Beispieldatei importieren“ auswählen.
Zum Auflisten von Arbeitsblättern können Sie in der Dropdownliste „Arbeitsblatt“ die Option „Bearbeiten“ auswählen und stattdessen den Arbeitsblattnamen bzw. den Index eingeben.
Zum Kopieren von großen Excel-Dateien (> 100 MB) in einen anderen Speicher können Sie die Datenfluss-Excel-Quelle verwenden, die Streaming-Lesevorgänge unterstützt und leistungsfähiger ist.
Das OOM-Problem beim Lesen großer JSON-/Excel-/XML-Dateien
Symptome: Wenn Sie große JSON-/Excel-/XML-Dateien lesen, tritt während der Aktivitätsausführung das Problem mit nicht genügend Arbeitsspeicher (OOM) auf.
Ursache:
- Bei großen XML-Dateien: Das OOM-Problem beim Lesen großer XML-Dateien ist beabsichtigt. Die Ursache ist, dass die ganze XML-Datei in den Arbeitsspeicher eingelesen werden muss, da es sich um ein einzelnes Objekt handelt. Dann wird das Schema abgeleitet, und die Daten werden abgerufen.
- Bei großen Excel-Dateien: Das OOM-Problem beim Lesen großer Excel-Dateien ist beabsichtigt. Die Ursache ist, dass das verwendete SDK (POI/NPOI) die ganze Excel-Datei in den Arbeitsspeicher einlesen, dann das Schema ableiten und Daten abrufen muss.
- Bei großen JSON-Dateien: Das OOM-Problem beim Lesen großer JSON-Dateien ist beabsichtigt, wenn die JSON-Datei ein einzelnes Objekt ist.
Empfehlung: Wenden Sie eine der folgenden Optionen an, um Ihr Problem zu lösen.
- Option 1: Registrieren Sie eine online selbstgehostete Integration Runtime mit einem leistungsstarken Computer (große CPU/großer Arbeitsspeicher), um Daten aus Ihrer großen Datei über die Kopieraktivität zu lesen.
- Option 2: Verwenden Sie optimierten Arbeitsspeicher und große Cluster (z. B. 48 Kerne), um Daten aus Ihrer großen Datei über die Zuordnungsdatenfluss-Aktivität zu lesen.
- Option 3: Teilen Sie die große Datei in kleine Dateien auf, und verwenden Sie dann die Kopier- oder Zuordnungsdatenfluss-Aktivität, um den Ordner zu lesen.
- Option 4: Bleibt der Kopiervorgang des XML-/Excel-/JSON-Ordners hängen oder tritt dabei das Problem „Nicht genügend Arbeitsspeicher“ auf, verwenden Sie die ForEach-Aktivität zusammen mit der Kopier-/Zuordnungsdatenfluss-Aktivität in Ihrer Pipeline, um die Dateien oder Unterordner einzeln zu verarbeiten.
-
Option 5: Sonstige:
- Verwenden Sie für XML die Notebook-Aktivität mit arbeitsspeicheroptimiertem Cluster, um Daten aus Dateien zu lesen, wenn jede Datei dasselbe Schema aufweist. Derzeit verfügt Spark über verschiedene Implementierungen für die Verarbeitung von XML.
- Verwenden Sie für JSON unterschiedliche Dokumentformulare (z. B. Einzelnes Dokument, Dokument pro Zeile und Array von Dokumenten) in JSON-Einstellungen unter der Quelle des Zuordnungsdatenflusses. Wenn der Inhalt der JSON-Datei Dokument pro Zeile ist, verbraucht er wenig Arbeitsspeicher.
Andere Referenzen
Hier finden Sie Referenzen zur Leistungsüberwachung und -optimierung für einige der unterstützten Datenspeicher:
- Azure Blob Storage: Skalierbarkeits- und Leistungsziele für Blob Storage und Checkliste zu Leistung und Skalierbarkeit für Blob Storage.
- Azure Table Storage: Skalierbarkeits- und Leistungsziele für Table Storage und Checkliste zu Leistung und Skalierbarkeit für Table Storage.
- Azure SQL-Datenbank: Sie können die Leistung überwachen und den prozentualen Anteil der Datenbanktransaktionseinheit (Database Transaction Unit, DTU) überprüfen.
- Azure Synapse Analytics: Die Funktion wird in DWUs (Data Warehouse-Einheiten) gemessen. Siehe Verwalten von Rechenressourcen in Azure Synapse Analytics (Übersicht).
- Azure Cosmos DB: Leistungsebenen in Azure Cosmos DB
- SQL Server: Überwachen und Optimieren der Leistung.
- Lokaler Dateiserver: Leistungsoptimierung für Dateiserver
Zugehöriger Inhalt
Weitere Informationen finden Sie in den anderen Artikeln zur Kopieraktivität: