Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Inhalt gilt für:![]() Version 4.0 (GA) | Vorherige Versionen:
Version 4.0 (GA) | Vorherige Versionen: ![]() Version 3.1 (GA)
Version 3.1 (GA) ![]() Version 3.0 (GA)
Version 3.0 (GA)
Benutzerdefinierte Klassifizierungsmodelle können jede Seite in einer Eingabedatei klassifizieren, um darin enthaltene Dokumente zu identifizieren. Klassifizierermodelle können auch mehrere Dokumente oder mehrere Instanzen eines einzelnen Dokuments in der Eingabedatei identifizieren. Für den Einstieg erfordern benutzerdefinierte Dokument Intelligenz-Modelle nur fünf Trainingsdokumente pro Dokumentklasse. Um mit dem Trainieren eines benutzerdefinierten Klassifizierungsmodells zu beginnen, benötigen Sie mindestens fünf Dokumente für jede Klasse und zwei Klassen von Dokumenten.
Eingabeanforderungen für benutzerdefinierte Klassifizierungsmodelle
Stellen Sie sicher, dass Ihr Trainingsdataset den Eingabeanforderungen für Dokument Intelligenz entspricht.
Unterstützte Dateiformate:
| Modell | Abbildung: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lesen Sie | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Allgemeines Dokument | ✔ | ✔ | |
| Vordefiniert | ✔ | ✔ | |
| Benutzerdefinierte Extraktion | ✔ | ✔ | |
| Benutzerdefinierte Klassifizierung | ✔ | ✔ | ✔ |
Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-11-30 (GA) beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Tipps zu Trainingsdaten
Befolgen Sie diese Tipps, um Ihr Dataset für das Training weiter zu optimieren:
Verwenden Sie nach Möglichkeit textbasierte PDF-Dokumente anstelle von bildbasierten Dokumenten. Gescannte PDF-Dateien werden als Bilder behandelt.
Wenn Ihre Formularbilder eine mäßige Qualität aufweisen, verwenden Sie ein größeres Dataset (beispielsweise 10–15 Bilder).
Hochladen Ihrer Trainingsdaten
Nachdem Sie die Formulare oder Dokumente, die Sie für das Training verwenden möchten, zusammengestellt haben, müssen Sie sie in einen Azure Blob Storage-Container hochladen. Wenn Sie nicht wissen, wie Sie ein Azure Storage-Konto mit einem Container erstellen, folgen Sie den Anweisungen im Azure Storage-Schnellstart für das Azure-Portal. Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst zu testen, und später für die Produktion auf einen kostenpflichtigen Tarif upgraden. Wenn Ihr Dataset in Ordnern organisiert ist, behalten Sie diese Struktur bei. Das Formularerkennungsstudio kann Ihre Ordnernamen für Bezeichnungen verwenden, um den Bezeichnungsprozess zu vereinfachen.
Erstellen eines Klassifizierungsprojekts in Dokument Intelligenz Studio
Dokument Intelligenz Studio bietet alle API-Aufrufe, die zum Abschließen Ihres Datasets und zum Trainieren Ihres Modells erforderlich sind, und orchestriert sie.
Navigieren Sie zunächst zu Dokument Intelligenz Studio. Bei der ersten Verwendung des Formularerkennungsstudios müssen Sie Ihr Abonnement, Ihre Ressourcengruppe und Ihre Ressource initialisieren. Beachten Sie dann die Voraussetzungen für benutzerdefinierte Projekte, um das Studio für den Zugriff auf Ihr Trainingsdataset zu konfigurieren.
Wählen Sie im Studio im Seitenabschnitt für benutzerdefinierte Modelle die Kachel Benutzerdefinierte Klassifizierungsmodelle und dann die Schaltfläche Projekt erstellen aus.
Geben Sie im Dialogfeld
Create Projecteinen Namen für Ihr Projekt und optional eine Beschreibung an, und wählen Sie „Weiter“ aus.Wählen Sie im nächsten Schritt eine Dokument Intelligenz-Ressource aus, oder erstellen Sie sie, bevor Sie fortfahren.
Wählen Sie als Nächstes das Speicherkonto aus, das Sie zum Hochladen des Trainingsdatasets für Ihr benutzerdefiniertes Modell verwendet haben. Der Ordnerpfad sollte leer sein, wenn sich Ihre Trainingsdokumente im Stammverzeichnis des Containers befinden. Wenn sich Ihre Dokumente in einem Unterordner befinden, geben Sie den relativen Pfad aus dem Containerstamm in das Feld Ordnerpfad ein. Nachdem Ihr Speicherkonto konfiguriert wurde, wählen Sie „Weiter“ aus.
Wichtig
Sie können das Trainingsdataset entweder in Ordnern organisieren (in diesem Fall ist der Ordnername die Bezeichnung bzw. Klasse für Dokumente) oder eine flache Liste von Dokumenten erstellen, denen Sie im Studio eine Bezeichnung zuweisen können.
Zum Trainieren eines benutzerdefinierten Klassifizierers ist die Ausgabe des Layoutmodells für jedes Dokument in Ihrem Dataset erforderlich. Führen Sie vor dem Modelltrainingsprozess das Layoutmodell für alle Dokumente aus.
Überprüfen Sie abschließend Ihre Projekteinstellungen, und wählen Sie Projekt erstellen aus, um ein neues Projekt zu erstellen. Sie sollten sich nun im Bezeichnungsfenster befinden und die Dateien in Ihrem Dataset aufgelistet sehen.
Beschriften Ihrer Daten
In Ihrem Projekt müssen Sie nur jedes Dokument mit der entsprechenden Klassenbezeichnung bezeichnen.
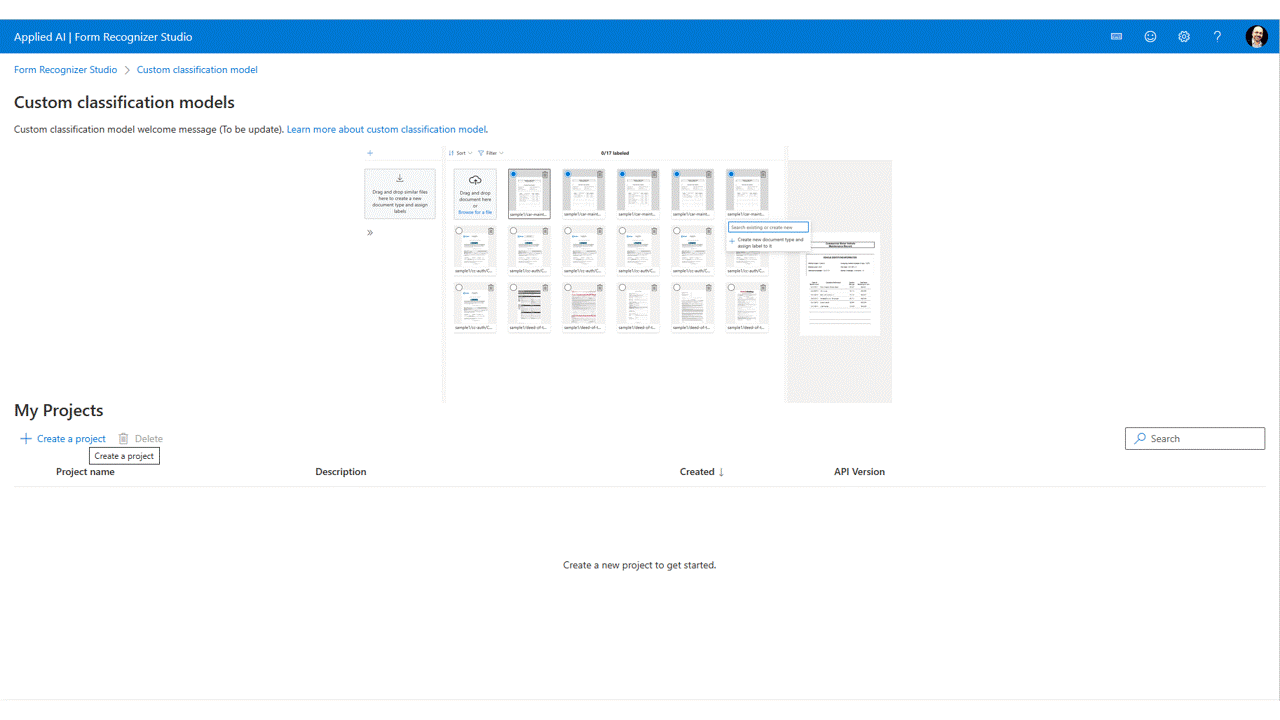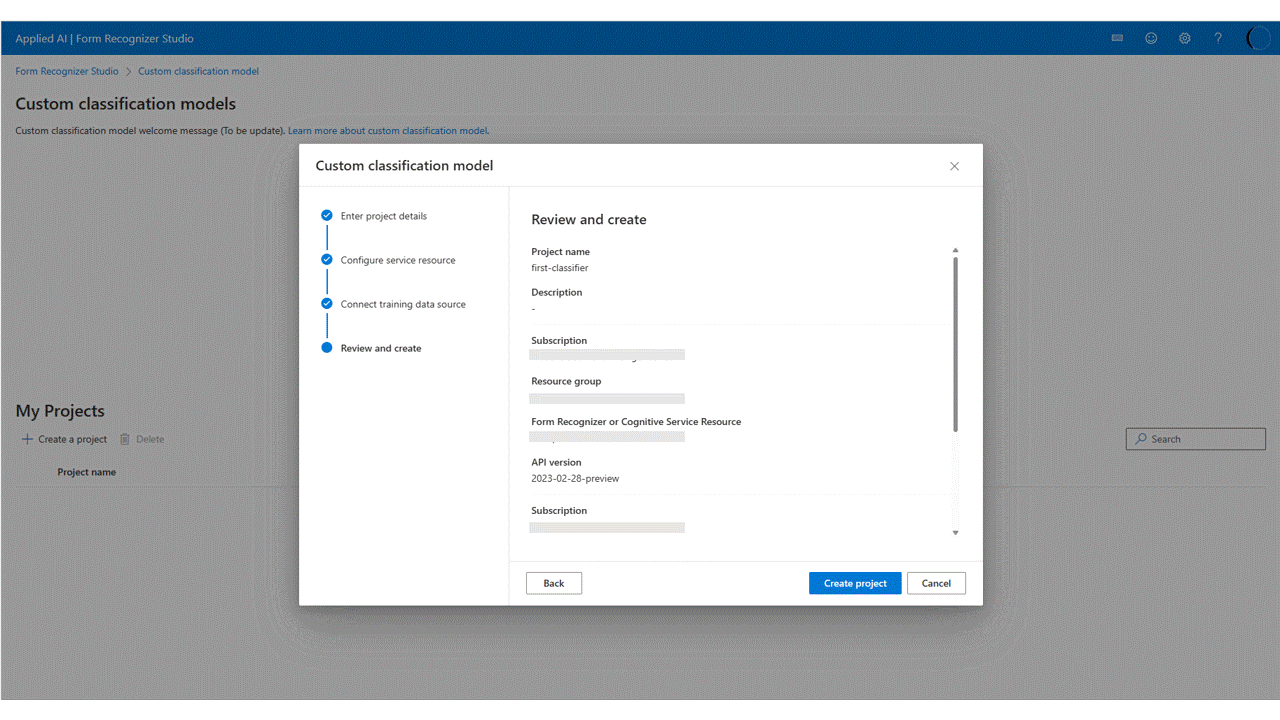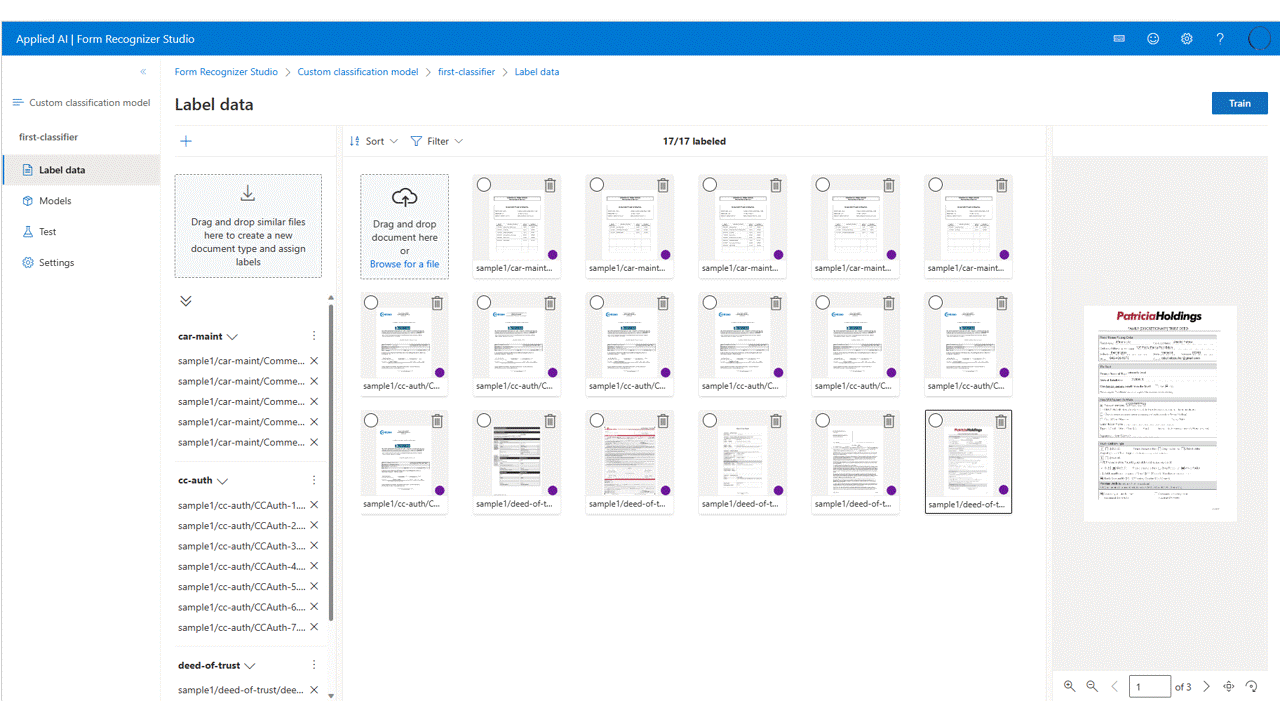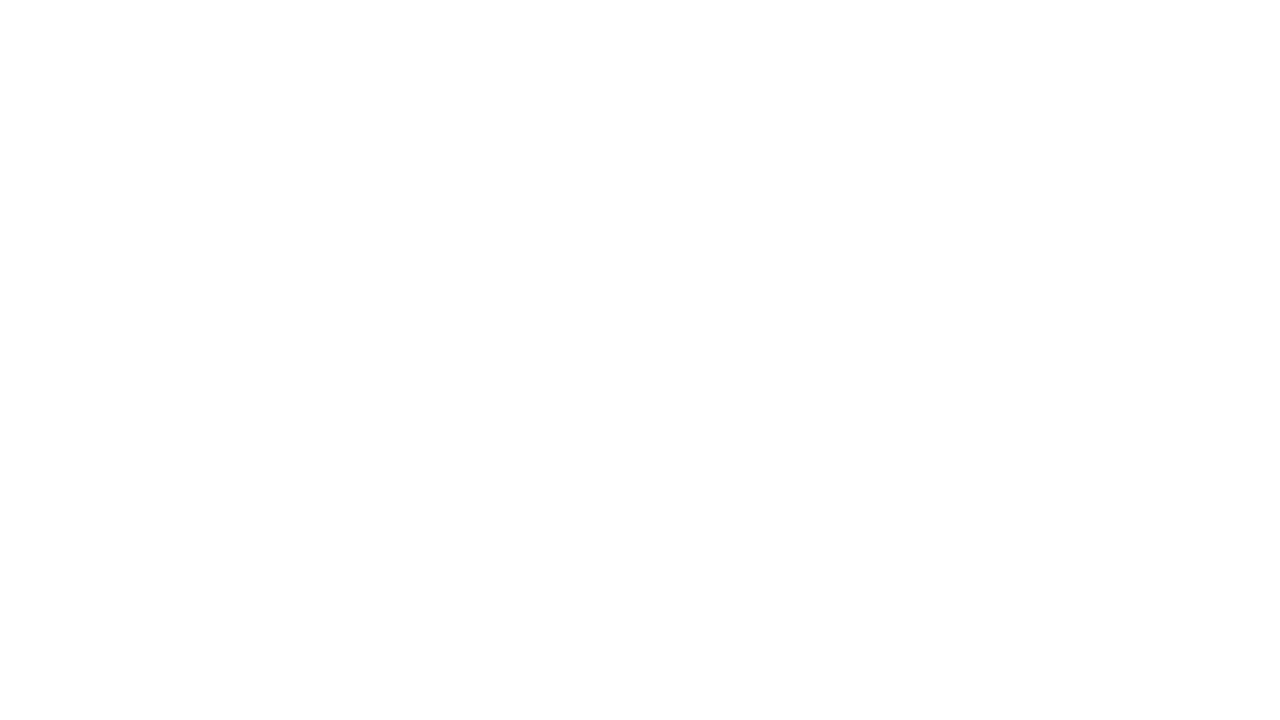
Die Dateien, die Sie hochgeladen haben, werden in der Dateiliste angezeigt und können nun bezeichnet werden. Zum Bezeichnen Ihres Datasets stehen Ihnen mehrere Optionen zur Auswahl.
Wenn die Dokumente in Ordnern organisiert sind, werden Sie im Studio aufgefordert, die Ordnernamen als Bezeichnungen zu verwenden. Dieser Schritt vereinfacht die Bezeichnung, da Sie nur eine einzige Auswahl treffen müssen.
Um einem Dokument eine Bezeichnung zuzuweisen, wählen Sie
add label selection markaus, um eine Bezeichnung zuzuweisen.Drücken Sie die STRG-Taste, um mehrere Dokumente auszuwählen, denen Sie eine Bezeichnung zuweisen möchten.
Jetzt sollten alle Dokumente in Ihrem Dataset mit einer Bezeichnung versehen sein. Im Speicherkonto sehen Sie nun die Dateien .ocr.json, die jedem Dokument in Ihrem Trainingsdataset entsprechen, sowie eine neue Datei class-name.jsonl für jede bezeichnete Klasse. Dieses Trainingsdataset wird zum Trainieren des Modells übermittelt.
Trainieren Ihres Modells
Wenn Ihr Dataset mit der Bezeichnung versehen ist, können Sie Ihr Modell trainieren. Klicken Sie in der oberen rechten Ecke auf die „Trainieren“-Schaltfläche.
Geben Sie im Dialogfeld „Modell trainieren“ eine eindeutige Klassifizierer-ID und optional eine Beschreibung an. Die Klassifizierer-ID akzeptiert einen String-Datentyp.
Wählen Sie Trainieren aus, um den Trainingsprozess zu initiieren.
Das Trainieren von Klassifizierermodellen dauert nur wenige Minuten.
Navigieren Sie zum Menü Modelle, um den Status des Trainingsvorgangs anzuzeigen.
Testen des Modells
Sobald das Modelltraining abgeschlossen ist, können Sie Ihr Modell testen, indem Sie das Modell auf der Seite mit der Modellliste auswählen.
Wählen Sie das Modell und dann die Schaltfläche Testen aus.
Fügen Sie eine neue Datei hinzu, indem Sie nach einer Datei suchen oder eine Datei in der Dokumentauswahl ablegen.
Wählen Sie bei ausgewählter Datei die Schaltfläche Analysieren aus, um das Modell zu testen.
Die Modellergebnisse werden mit der Liste der identifizierten Dokumente, einer Zuverlässigkeitsbewertung für jedes identifizierte Dokument und dem Seitenbereich für jedes der identifizierten Dokumente angezeigt.
Überprüfen Sie Ihr Modell, indem Sie die Ergebnisse für jedes identifizierte Dokument auswerten.
Trainieren eines benutzerdefinierten Klassifizierers mithilfe des SDK oder der API
Das Studio koordiniert die API-Aufrufe, um einen benutzerdefinierten Klassifizierer zu trainieren. Der Trainingsdatensatz für den Klassifizierer erfordert die Ausgabe der Layout-API, die der Version der API für Ihr Trainingsmodell entspricht. Die Verwendung von Layoutergebnissen aus einer älteren API-Version kann zu einem Modell mit geringerer Genauigkeit führen.
Das Studio generiert die Layoutergebnisse für Ihren Trainingsdatensatz, wenn der Datensatz keine Layoutergebnisse enthält. Wenn Sie die API oder das SDK zum Trainieren eines Klassifizierers verwenden, müssen Sie den Ordnern, welche die einzelnen Dokumente enthalten, die Layoutergebnisse hinzufügen. Die Layoutergebnisse sollten beim direkten Aufrufen des Layouts im Format der API-Antwort vorliegen. Das SDK-Objektmodell unterscheidet sich. Stellen Sie sicher, dass es sich bei layout results um die API-Ergebnisse und nicht um SDK response handelt.
Problembehandlung
Das Klassifizierungsmodell benötigt Ergebnisse aus dem Layoutmodell für jedes Trainingsdokument. Wenn Sie die Layoutergebnisse nicht bereitgestellt haben, versucht Studio, vor dem Trainieren des Klassifizierers das Layoutmodell für jedes Dokument auszuführen. Dieser Prozess wird gedrosselt und kann zu einer Antwort vom Typ „429“ führen.
Führen Sie in Studio vor dem Training mit dem Klassifizierungsmodell das Layoutmodell für jedes Dokument aus, und laden Sie es an den Ort hoch, an dem sich auch das ursprüngliche Dokument befindet. Nachdem die Layoutergebnisse hinzugefügt wurden, können Sie das Klassifizierermodell mit Ihren Dokumenten trainieren.