Erstellen und Trainieren eines benutzerdefinierten Extraktionsmodells
Dieser Inhalt gilt für:![]() Version 4.0 (Vorschau) | Vorherige Versionen:
Version 4.0 (Vorschau) | Vorherige Versionen: ![]() Version 3.1 (GA)
Version 3.1 (GA) ![]() Version 3.0 (GA)
Version 3.0 (GA) ![]() Version 2.1
Version 2.1
Wichtig
Benutzerdefiniertes generatives Modelltrainingsverhalten unterscheidet sich von benutzerdefinierten Vorlagen und neuralem Modelltraining. Das folgende Dokument behandelt Training nur für benutzerdefinierte Vorlagen und neurale Modelle. Anleitungen zum benutzerdefinierten generativen Modell finden Sie im benutzerdefinierten generativen Modell
Benutzerdefinierte Document Intelligence-Modelle erfordern eine Handvoll Schulungsdokumente für die ersten Schritte. Wenn Sie über mindestens fünf Dokumente verfügen, können Sie mit dem Trainieren eines benutzerdefinierten Modells beginnen. Sie können entweder ein benutzerdefiniertes Vorlagenmodell (benutzerdefiniertes Formular) oder ein benutzerdefiniertes neurales Modell (benutzerdefiniertes Dokument) oder ein benutzerdefiniertes Vorlagenmodell (benutzerdefiniertes Formular) trainieren. Dieses Dokument führt Sie durch den Prozess der Schulung der benutzerdefinierten Modelle.
Eingabeanforderungen für benutzerdefinierte Modelle
Stellen Sie zunächst sicher, dass Ihr Trainingsdataset den Eingabeanforderungen für Dokument Intelligenz entspricht.
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-07-31-preview und höher beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Tipps zu Trainingsdaten
Befolgen Sie diese Tipps, um Ihr Dataset für das Training weiter zu optimieren:
- Verwenden Sie textbasierte PDF-Dokumente anstelle von bildbasierten Dokumenten. Gescannte PDFs werden als Bilder behandelt.
- Verwenden Sie für Formulare mit Eingabefeldern Beispiele, bei denen alle Felder ausgefüllt sind.
- Verwenden Sie Formulare mit verschiedenen Werten in jedem Feld.
- Verwenden Sie einen größeren Datensatz (10-15 Bilder), wenn Ihre Formularbilder von geringerer Qualität sind.
Hochladen Ihrer Trainingsdaten
Sobald Sie eine Reihe von Formularen oder Dokumenten für die Schulung gesammelt haben, müssen Sie diese in einen Azure Blob-Speichercontainer hochladen. Wenn Sie nicht wissen, wie Sie ein Azure Storage-Konto mit einem Container erstellen, folgen Sie den Anweisungen im Azure Storage-Schnellstart für das Azure-Portal. Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst zu testen, und später für die Produktion auf einen kostenpflichtigen Tarif upgraden.
Video: Trainieren Ihres benutzerdefinierten Modells
- Sobald Sie Ihren Trainingsdatensatz gesammelt und hochgeladen haben, sind Sie bereit, Ihr benutzerdefiniertes Modell zu trainieren. Im folgenden Video wird ein Projekt erstellt, und es werden einige der Grundlagen für erfolgreiches Beschriften und Trainieren eines Modells behandelt.
Erstellen eines Projekts in Dokument Intelligenz Studio
Dokument Intelligenz Studio bietet alle API-Aufrufe, die zum Abschließen Ihres Datasets und zum Trainieren Ihres Modells erforderlich sind, und orchestriert sie.
Navigieren Sie zunächst zu Dokument Intelligenz Studio. Bei der ersten Verwendung des Formularerkennungsstudios müssen Sie Ihr Abonnement, Ihre Ressourcengruppe und Ihre Ressource initialisieren. Beachten Sie dann die Voraussetzungen für benutzerdefinierte Projekte, um das Studio für den Zugriff auf Ihr Trainingsdataset zu konfigurieren.
Wählen Sie im Studio die Kachel Benutzerdefiniertes Extraktionsmodell aus und wählen Sie die Schaltfläche Projekt erstellen aus.
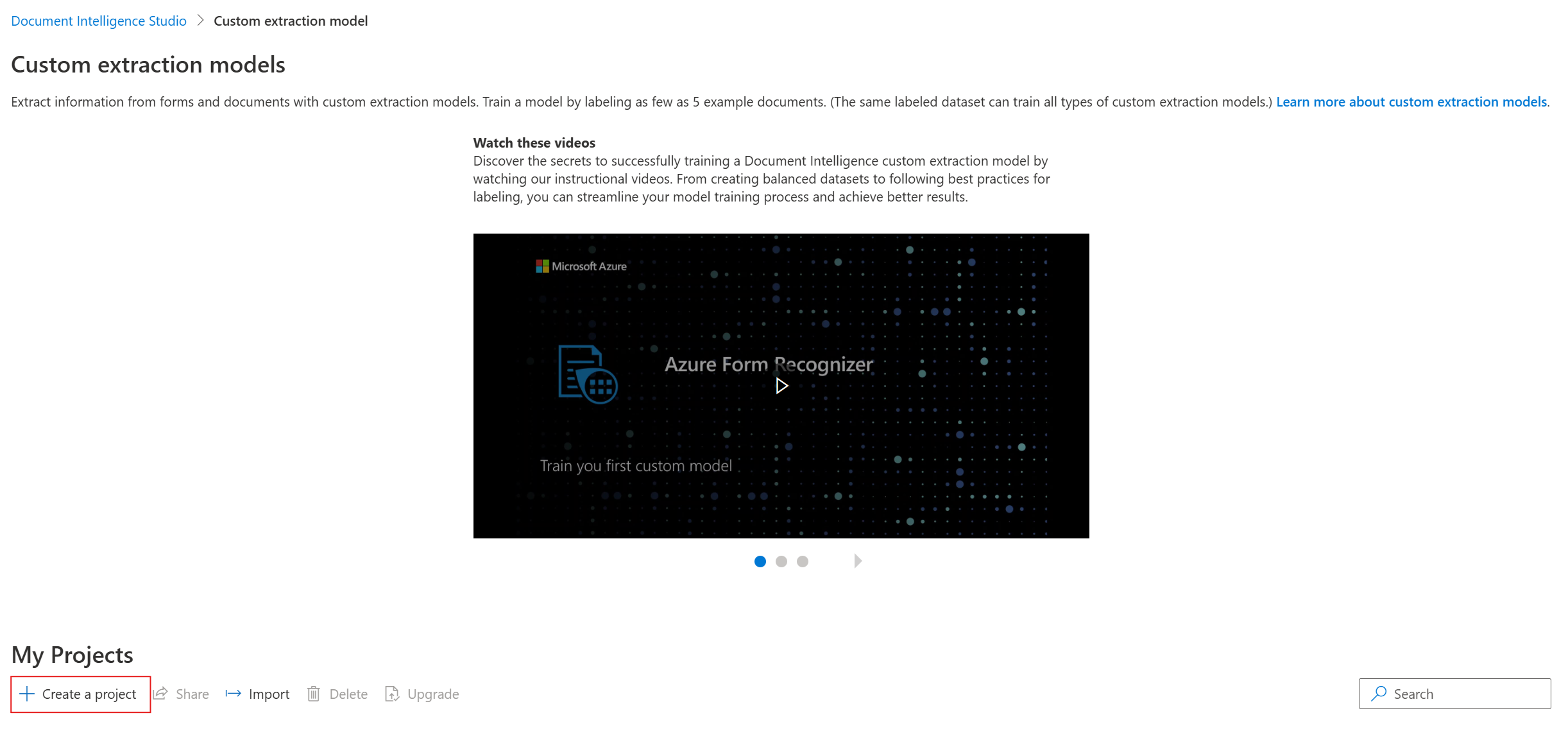
Geben Sie im Dialogfeld
create projecteinen Namen für Ihr Projekt und optional eine Beschreibung an, und wählen Sie „Weiter“ aus.Wählen Sie im nächsten Schritt des Workflows eine Dokument Intelligenz-Ressource aus, oder erstellen Sie sie, bevor Sie „Weiter“ auswählen.
Wichtig
Benutzerdefinierte neuronale Modelle sind nur in wenigen Regionen verfügbar. Wenn Sie ein neuronales Modell trainieren möchten, wählen Sie eine Ressource in einer dieser unterstützten Regionen aus, oder erstellen Sie eine Ressource.
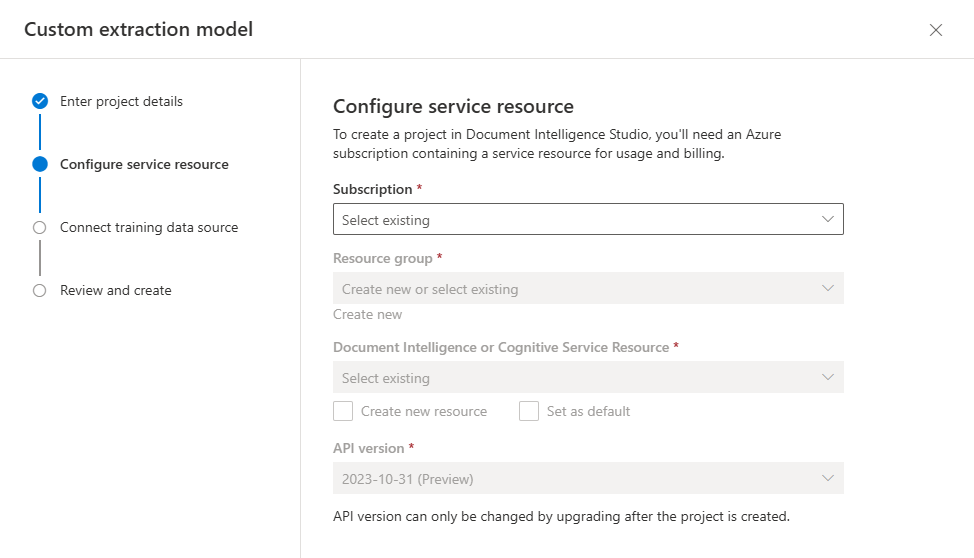
Wählen Sie als Nächstes das Speicherkonto aus, das Sie zum Hochladen des Trainingsdatasets für Ihr benutzerdefiniertes Modell verwendet haben. Der Ordnerpfad sollte leer sein, wenn sich Ihre Trainingsdokumente im Stammverzeichnis des Containers befinden. Wenn sich Ihre Dokumente in einem Unterordner befinden, geben Sie den relativen Pfad aus dem Containerstamm in das Feld Ordnerpfad ein. Nachdem Ihr Speicherkonto konfiguriert wurde, wählen Sie „Weiter“ aus.
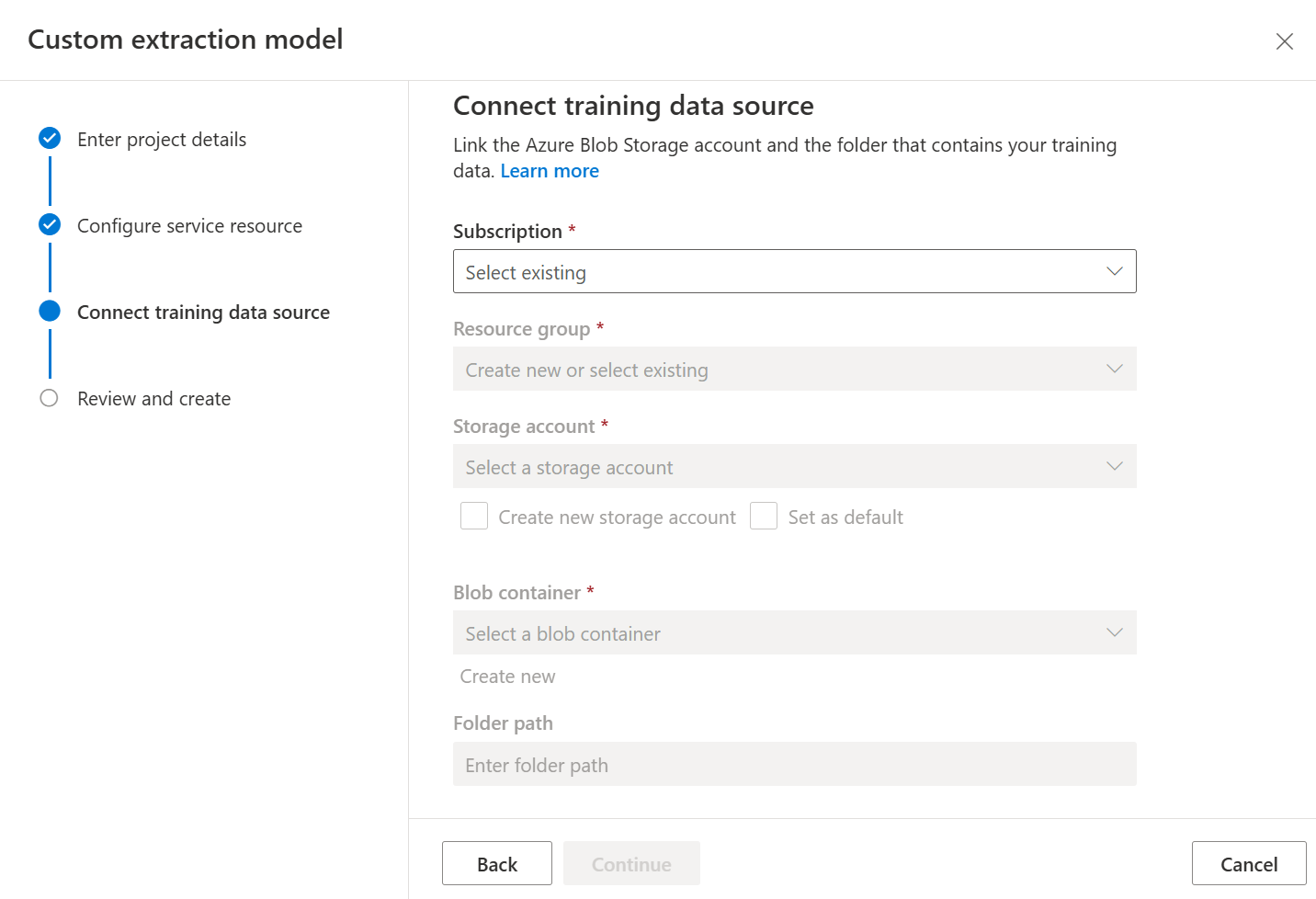
Überprüfen Sie abschließend Ihre Projekteinstellungen, und wählen Sie Projekt erstellen aus, um ein neues Projekt zu erstellen. Sie sollten sich nun im Bezeichnungsfenster befinden und die Dateien in Ihrem Dataset aufgelistet sehen.
Beschriften Ihrer Daten
In Ihrem Projekt besteht Ihre erste Aufgabe darin, Ihr Dataset mit den Feldern zu beschriften, die Sie extrahieren möchten.
Links auf dem Bildschirm werden die Dateien aufgelistet, die Sie in den Speicher hochgeladen haben, wobei die erste Datei beschriftet werden kann.
Beginnen Sie mit der Beschriftung Ihres Datasets und dem Erstellen des ersten Felds, indem Sie oben rechts auf dem Bildschirm die Schaltfläche plus (➕) auswählen.
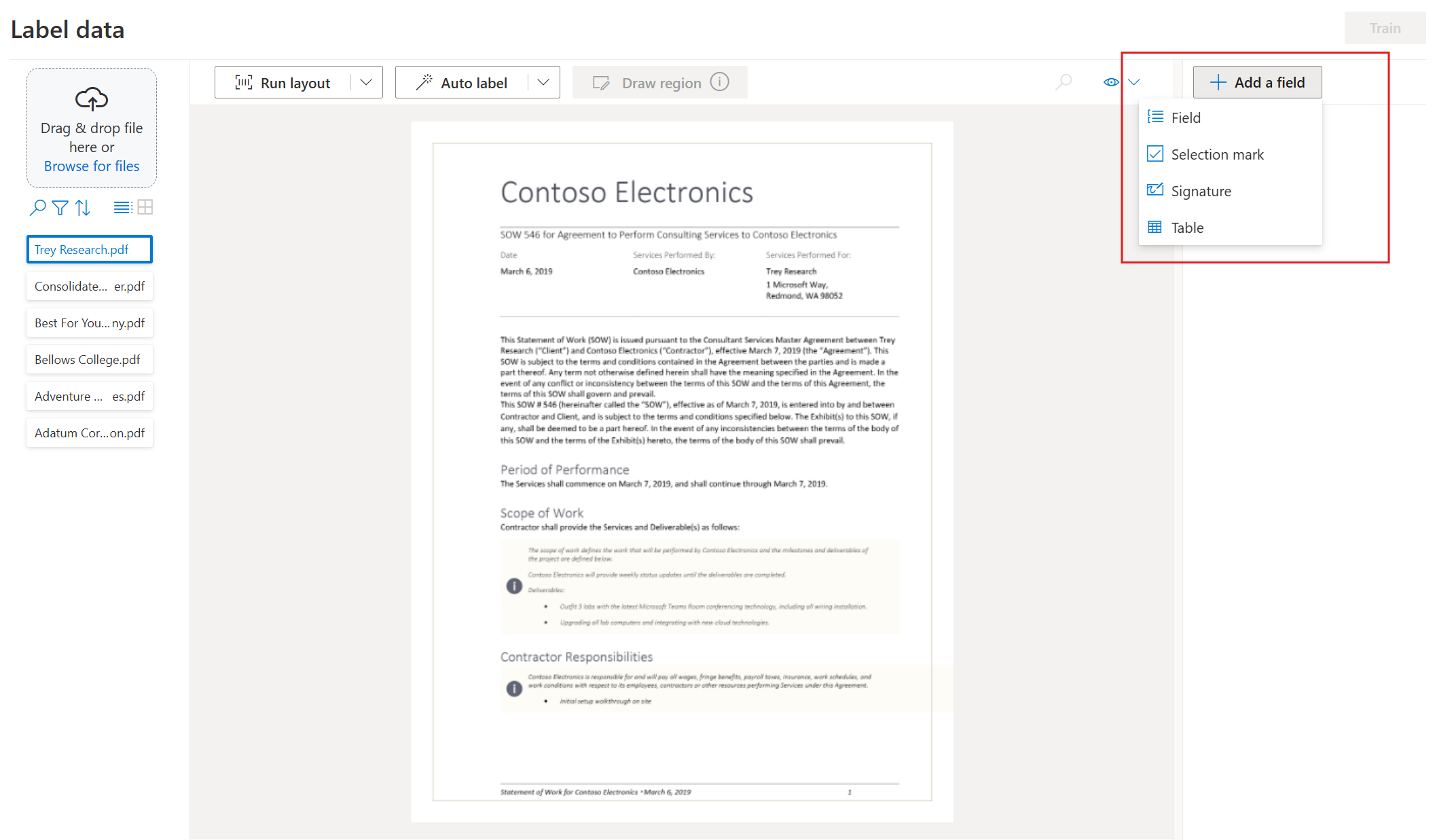
Geben Sie einen Namen für das Feld ein.
Weisen Sie dem Feld einen Wert zu, indem Sie ein Wort oder ein Wort im Dokument auswählen. Wählen Sie das Feld in der Dropdownliste oder in der Feldliste auf der rechten Navigationsleiste aus. Der beschriftete Wert befindet sich unterhalb des Feldnamens in der Liste der Felder.
Wiederholen Sie den Vorgang für alle Felder, die Sie für Ihr Dataset beschriften möchten.
Beschriften Sie die verbleibenden Dokumente in Ihrem Dataset, indem Sie jedes Dokument und den zu bezeichnenden Text auswählen.
Sie haben nun alle Dokumente in Ihrem Dataset mit einer Bezeichnung versehen. Die Dateien .labels.json und .ocr.json entsprechen jedem Dokument in Ihrem Trainingsdataset sowie einer neuen Datei „fields.json“. Dieses Trainingsdataset wird zum Trainieren des Modells übermittelt.
Trainieren Ihres Modells
Wenn Ihr Dataset mit der Bezeichnung versehen ist, können Sie Ihr Modell trainieren. Klicken Sie in der oberen rechten Ecke auf die „Trainieren“-Schaltfläche.
Geben Sie im Dialogfeld „Modell trainieren“ eine eindeutige Modell-ID und optional eine Beschreibung an. Die Modell-ID akzeptiert einen Zeichenfolgendatentyp.
Wählen Sie für den Buildmodus den Modelltyp aus, den Sie trainieren möchten. Lernen Sie mehr über die Modelltypen und -funktionen.
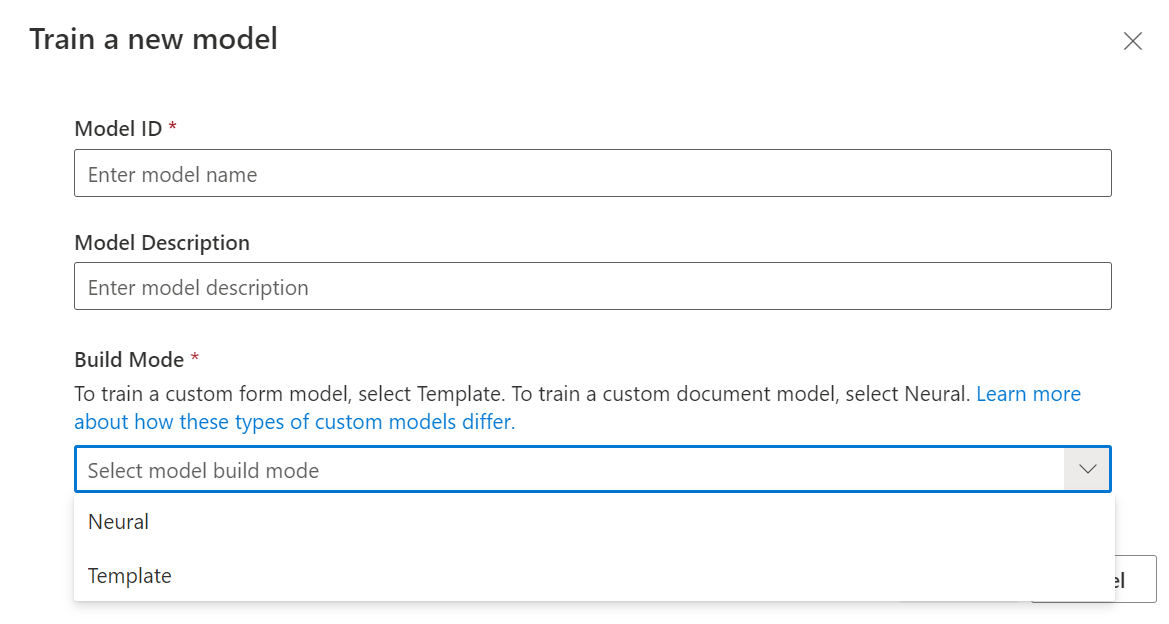
Wählen Sie Trainieren aus, um den Trainingsprozess zu initiieren.
Vorlagenmodelle werden in wenigen Minuten trainiert. Das Trainieren neuronaler Modelle kann bis zu 30 Minuten dauern.
Navigieren Sie zum Menü Modelle, um den Status des Trainingsvorgangs anzuzeigen.
Testen des Modells
Sobald das Modelltraining abgeschlossen ist, können Sie Ihr Modell testen, indem Sie das Modell auf der Seite mit der Modellliste auswählen.
Wählen Sie das Modell und dann die Schaltfläche Testen aus.
Wählen Sie die
+ Add-Schaltfläche aus, um eine Datei zum Testen des Modells auszuwählen.Wählen Sie bei ausgewählter Datei die Schaltfläche Analysieren aus, um das Modell zu testen.
Die Modellergebnisse werden im Hauptfenster angezeigt, und die extrahierten Felder werden in der rechten Navigationsleiste aufgeführt.
Überprüfen Sie Ihr Modell, indem Sie die Ergebnisse für jedes Feld auswerten.
Die rechte Navigationsleiste enthält auch den Beispielcode zum Aufrufen Ihres Modells und der JSON-Ergebnisse aus der API.
Herzlichen Glückwunsch, Sie haben gelernt, ein benutzerdefiniertes Modell im Document Intelligence Studio zu trainieren! Ihr Modell ist für die Verwendung mit der REST-API oder dem SDK zum Analysieren von Dokumenten bereit.
Gilt für: ![]() Version 2.1. Andere Versionen: Version 3.0
Version 2.1. Andere Versionen: Version 3.0
Wenn Sie das benutzerdefinierte Dokument Intelligenz-Modell verwenden, stellen Sie dem Vorgang Benutzerdefiniertes Modell trainieren Ihre eigenen Trainingsdaten bereit, sodass das Modell mit Ihren branchenspezifischen Formularen trainiert werden kann. Folgen Sie diesem Leitfaden, um zu erfahren, wie Daten für ein effektives Training des Modells gesammelt und vorbereitet werden können.
Sie benötigen mindestens fünf ausgefüllte Formulare desselben Typs.
Wenn Sie manuell bezeichnete Trainingsdaten verwenden möchten, müssen Sie mit mindestens fünf ausgefüllten Formularen desselben Typs beginnen. Sie können trotzdem nicht bezeichnete Formulare zusätzlich zum erforderlichen Dataset verwenden.
Eingabeanforderungen für benutzerdefinierte Modelle
Stellen Sie zunächst sicher, dass Ihr Trainingsdataset den Eingabeanforderungen für Dokument Intelligenz entspricht.
Unterstützte Dateiformate:
Modell PDF Abbildung: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLesen Sie ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allgemeines Dokument ✔ ✔ Vordefiniert ✔ ✔ Benutzerdefinierte Extraktion ✔ ✔ Benutzerdefinierte Klassifizierung ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Die besten Ergebnisse erzielen Sie, wenn Sie pro Dokument ein deutliches Foto oder einen hochwertigen Scan bereitstellen.
In den Formaten PDF und TIFF können bis zu 2,000 Seiten verarbeitet werden (bei einem kostenlosen Abonnement werden nur die ersten beiden Seiten verarbeitet).
Die Dateigröße für die Analyse von Dokumenten beträgt 500 MB für den kostenpflichtigen Tarif (S0) und
4MB für den kostenlosen Tarif (F0).Die Bildgröße muss zwischen 50 × 50 Pixel und 10.000 × 10.000 Pixel liegen.
Wenn Ihre PDFs kennwortgeschützt sind, müssen Sie die Sperre vor dem Senden entfernen.
Die Mindesthöhe des zu extrahierenden Texts beträgt 12 Pixel für ein Bild von 1024 × 768 Pixel. Diese Abmessung entspricht etwa einem
8-Punkttext bei 150 Punkten pro Zoll (Dots Per Inch, DPI).Die maximale Anzahl Seiten für Trainingsdaten beträgt beim benutzerdefinierten Modelltraining 500 für das benutzerdefinierte Vorlagenmodell und 50.000 für das benutzerdefinierte neuronale Modell.
Für das Training benutzerdefinierter Extraktionsmodelle beträgt die Gesamtgröße der Trainingsdaten 50 MB für das Vorlagenmodell und
1GB für das neuronale Modell.Für das Training benutzerdefinierter Klassifizierungsmodelle beträgt die Gesamtgröße der Trainingsdaten
1GB bei maximal 10.000 Seiten. Für 2024-07-31-preview und höher beträgt die Gesamtgröße der Trainingsdaten2GB bei maximal 10.000 Seiten.
Tipps zu Trainingsdaten
Befolgen Sie diese Tipps, um Ihr Dataset für das Training weiter zu optimieren.
- Verwenden Sie textbasierte PDF-Dokumente anstelle von bildbasierten Dokumenten. Gescannte PDFs werden als Bilder behandelt.
- Verwenden Sie als ausgefüllte Formulare Exemplare, in denen alle Felder ausgefüllt sind.
- Verwenden Sie Formulare mit verschiedenen Werten in jedem Feld.
- Verwenden Sie einen größeren Datensatz (10-15 Bilder) für ausgefüllte Formulare.
Hochladen Ihrer Trainingsdaten
Wenn Sie die Dokumente, die Sie für das Training verwenden möchten, zusammengestellt haben, müssen Sie sie in einen Azure Blob Storage-Container hochladen. Wenn Sie nicht wissen, wie Sie ein Azure Storage-Konto mit einem Container erstellen, folgen Sie den Anweisungen im Azure Storage-Schnellstart für das Azure-Portal. Verwenden Sie die Standardleistungsstufe.
Wenn Sie manuell bezeichnete Daten verwenden möchten, laden Sie die Dateien .labels.json und .ocr.json hochladen, die Ihren Trainingsdokumenten entsprechen. Sie können das Beispielbeschriftungstool (oder Ihre eigene Benutzeroberfläche) verwenden, um diese Dateien zu generieren.
Organisieren Ihrer Daten in Unterordnern (optional)
Standardmäßig werden von der Train Custom Model-API nur Dokumente verwendet, die sich im Stammverzeichnis Ihres Speichercontainers befinden. Sie können jedoch mit Daten in Unterordnern trainieren, wenn Sie dies im API-Aufruf angeben. Normalerweise hat der Text des Train Custom Model-Aufrufs das folgende Format, wobei <SAS URL> die SAS-URL (Shared Access Signature) des Containers ist:
{
"source":"<SAS URL>"
}
Wenn Sie dem Anforderungstext den folgenden Inhalt hinzufügen, wird die API mit Dokumenten trainiert, die sich in Unterordnern befinden. Das Feld „"prefix"“ ist optional und schränkt das Trainingsdataset auf Dateien ein, deren Pfad mit der angegebenen Zeichenfolge beginnt. So bewirkt beispielsweise der Wert „"Test"“, dass die API nur Dateien oder Ordner berücksichtigt, die mit dem Wort Test beginnen.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Nächste Schritte
Nachdem Sie nun gelernt haben, wie Sie ein Trainingsdataset erstellen, folgen Sie den Anweisungen in einem Schnellstart, um ein benutzerdefiniertes Dokument Intelligenz-Modell zu trainieren und es mit Ihren Formularen zu verwenden.