Kopieren von Daten aus Spark mithilfe von Azure Data Factory oder Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie die Copy-Aktivität in Azure Data Factory- oder Azure Synapse Analytics-Pipelines verwenden, um Daten aus Spark zu kopieren. Er baut auf dem Artikel zur Übersicht über die Kopieraktivität auf, der eine allgemeine Übersicht über die Kopieraktivität enthält.
Unterstützte Funktionen
Für den Spark-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | 1.6 |
| Lookup-Aktivität | 1.6 |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Der Dienst enthält einen integrierten Treiber zum Herstellen der Konnektivität. Daher müssen Sie keinen Treiber manuell installieren, wenn dieser Connector verwendet wird.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts mit Spark über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst mit Spark auf der Azure-Portal Benutzeroberfläche zu erstellen.
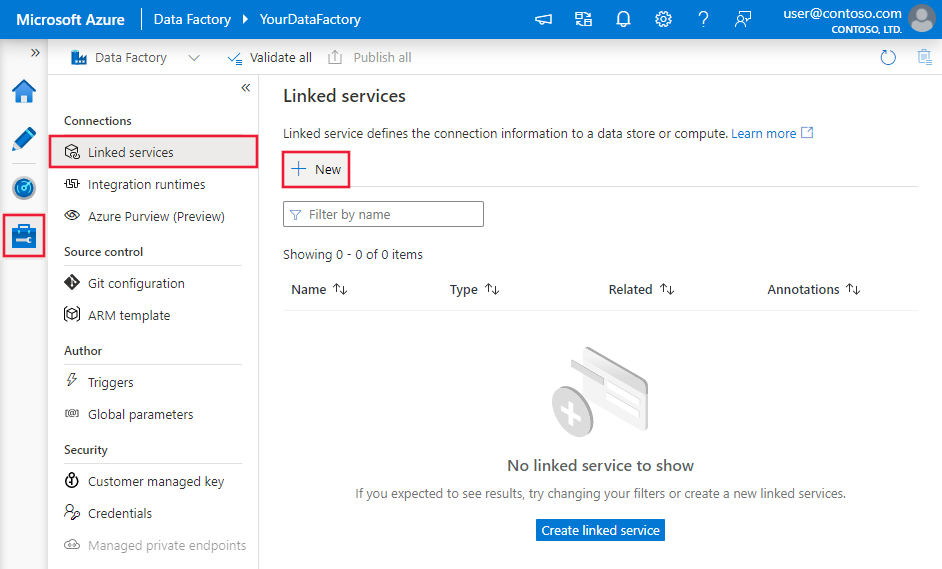
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach Spark, und wählen Sie den Spark-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
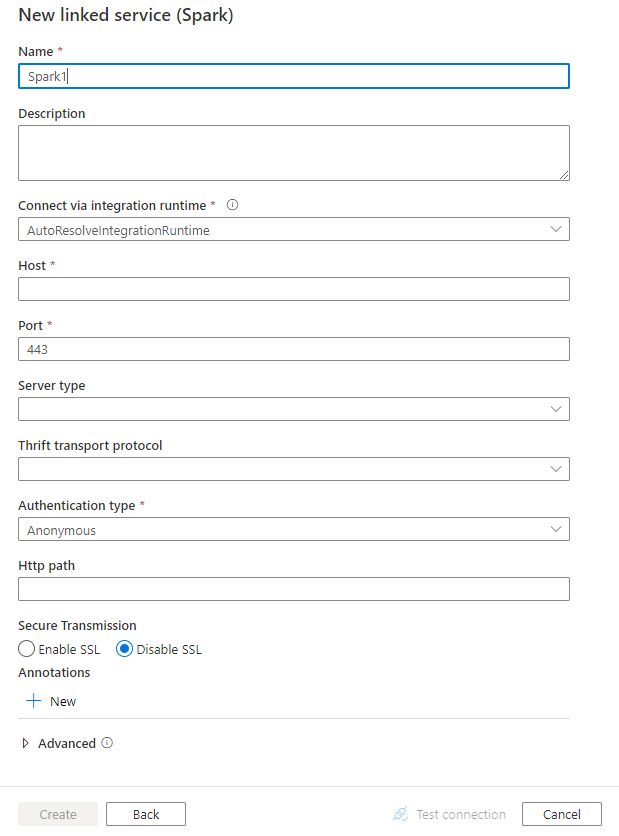
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Data Factory-Entitäten speziell für den Spark-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Folgende Eigenschaften werden für den mit Spark verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf Folgendes festgelegt werden: Spark | Ja |
| host | IP-Adresse oder Hostname des Spark-Servers | Ja |
| port | Der TCP-Port, den der Spark-Server verwendet, um auf Clientverbindungen zu lauschen. Geben Sie beim Herstellen einer Verbindung mit Azure HDInsights als Port 443 an. | Ja |
| serverType | Der Typ des Spark-Servers. Zulässige Werte sind: SharkServer, SharkServer2, SparkThriftServer |
Nein |
| thriftTransportProtocol | Das auf der Thrift-Ebene zu verwendende Transportprotokoll. Zulässige Werte sind: Binary, SASL, HTTP |
Nein |
| authenticationType | Die Authentifizierungsmethode für den Zugriff auf den Spark-Server. Zulässige Werte sind: Anonymous, Username, UsernameAndPassword, WindowsAzureHDInsightService |
Ja |
| username | Der Benutzername für den Zugriff auf den Spark-Server. | Nein |
| password | Das Kennwort für den Benutzer. Markieren Sie dieses Feld als einen „SecureString“, um es sicher zu speichern, oder verweisen Sie auf ein in Azure Key Vault gespeichertes Geheimnis. | Nein |
| httpPath | Die Teil-URL, die dem Spark-Server entspricht. | Nein |
| enableSsl | Gibt an, ob Verbindungen mit dem Server mit TLS verschlüsselt werden. Der Standardwert ist „FALSE“. | Nein |
| trustedCertPath | Der vollständige Pfad der PEM-Datei mit vertrauenswürdigen Zertifizierungsstellenzertifikaten zur Überprüfung des Servers beim Verbindungsaufbau über TLS. Diese Eigenschaft kann nur festgelegt werden, wenn TLS in einer selbstgehosteten IR verwendet wird. Der Standardwert ist die Datei „cacerts.pem“, die mit der IR installiert wird. | Nein |
| useSystemTrustStore | Gibt an, ob ein Zertifizierungsstellenzertifikat aus dem Vertrauensspeicher des Systems oder aus einer angegebenen PEM-Datei verwendet werden soll. Der Standardwert ist „FALSE“. | Nein |
| allowHostNameCNMismatch | Gibt an, ob der Name eines von der Zertifizierungsstelle ausgestellten TLS-/SSL-Zertifikats mit dem Hostnamen des Servers übereinstimmen muss, wenn eine Verbindung über TLS hergestellt wird. Der Standardwert ist „FALSE“. | Nein |
| allowSelfSignedServerCert | Gibt an, ob vom Server selbstsignierte Zertifikate zugelassen werden. Der Standardwert ist „FALSE“. | Nein |
| connectVia | Die Integrationslaufzeit, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden muss. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Beispiel:
{
"name": "SparkLinkedService",
"properties": {
"type": "Spark",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Spark-Dataset unterstützt werden.
Legen Sie zum Kopieren von Daten aus Spark die „type“-Eigenschaft des Datasets auf SparkObject fest. Folgende Eigenschaften werden unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf folgenden Wert festgelegt werden: SparkObject | Ja |
| schema | Name des Schemas. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| table | Der Name der Tabelle. | Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
| tableName | Name der Tabelle mit Schema. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie schema und table für eine neue Workload. |
Nein (wenn „query“ in der Aktivitätsquelle angegeben ist) |
Beispiel
{
"name": "SparkDataset",
"properties": {
"type": "SparkObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Spark linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Spark-Quelle unterstützt werden.
Spark als Quelle
Legen Sie zum Kopieren von Daten aus Spark den Quelltyp in der Kopieraktivität auf SparkSource fest. Folgende Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Folgendes festgelegt werden: SparkSource | Ja |
| Abfrage | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. Beispiel: "SELECT * FROM MyTable". |
Nein (wenn „tableName“ im Dataset angegeben ist) |
Beispiel:
"activities":[
{
"name": "CopyFromSpark",
"type": "Copy",
"inputs": [
{
"referenceName": "<Spark input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SparkSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in der Dokumentation für Unterstützte Datenspeicher.