Schema- und Datentypzuordnung in Kopieraktivität
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie die Kopieraktivität in Azure Data Factory Schemazuordnung und Datentypzuordnung von Quelldaten zu Senkendaten ausführt.
Schemazuordnung
Standardmäßige Zuordnung
Die Kopieraktivität ordnet standardmäßig einer Senke Quelldaten nach Spaltennamen und unter Beachtung der Groß-/Kleinschreibung zu. Wenn beispielsweise beim Schreiben in Dateien keine Senke vorhanden ist, werden die Quellfeldnamen als Senkennamen verwendet. Wenn die Senke bereits vorhanden ist, muss sie alle Spalten enthalten, die aus der Quelle kopiert werden. Bei einer Standardzuordnung dieser Art werden flexible Schemas und Schemaabweichungen von Quelle zu Senke und von Ausführung zu Ausführung unterstützt. Dabei können alle vom Quelldatenspeicher zurückgegebenen Daten in die Senke kopiert werden.
Wenn es sich bei Ihrer Quelle um eine Textdatei ohne Headerzeile handelt, ist eine explizite Zuordnung erforderlich, da die Quelle keine Spaltennamen enthält.
Explizite Zuordnung
Sie können auch eine explizite Zuordnung angeben, um die Spalten-Feld-Zuordnung von der Quelle zur Senke an Ihre Anforderungen anzupassen. Bei der expliziten Zuordnung können Sie Quelldaten nur partiell in die Senke kopieren, Quelldaten mit anderen Namen zur Senke zuordnen oder tabellarische/hierarchische Daten neu strukturieren. Kopieraktivität:
- Lesen von Daten aus der Quelle und Bestimmen des Quellschemas
- Anwenden der definierten Zuordnung
- Schreiben der Daten in die Senke
Weitere Informationen:
- Tabellarische Quelle zu tabellarischer Senke
- Hierarchische Quelle zu tabellarischer Senke
- Tabellarische/hierarchische Quelle zu hierarchischer Senke
Sie können die Zuordnung über die Benutzeroberfläche für die Dokumenterstellung unter –> „Kopieraktivität“ –> Registerkarte „Zuordnung“ konfigurieren oder sie in der Kopieraktivität mithilfe der Eigenschaft –>translator programmgesteuert angeben. Die folgenden Eigenschaften werden im translator –>mappingsArray –>„Objekte“ –>source und sink unterstützt, das auf die jeweilige Spalte bzw. das jeweilige Feld zum Zuordnen von Daten verweist.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| name | Name der Quell- oder Senkenspalte bzw. des Quell- oder Senkenfelds. Für tabellarische Quelle und Senke anwenden. | Ja |
| ordinal | Spaltenindex. Bei 1 beginnen. Anwenden und erforderlich, wenn Text mit Trennzeichen und ohne Kopfzeile verwendet wird. |
Nein |
| path | Der Ausdruck des JSON-Pfads für jedes Feld, das extrahiert oder zugeordnet werden soll. Wird für hierarchische Quelle und Senke (z. B. Azure Cosmos DB-, MongoDB- oder REST-Connectors) angewendet. Der JSON-Pfad für Felder unter dem Stammobjekt beginnt mit dem Stamm „ $“. Für Felder innerhalb des von der collectionReference-Eigenschaften ausgewählten Arrays beginnt der JSON-Pfad mit dem Arrayelement ohne $. |
Nein |
| type | Interimsdatentyp der Quell- oder Senkenspalte. Im Allgemeinen müssen Sie diese Eigenschaft nicht angeben oder ändern. Weitere Informationen zu Datentypzuordnung. | Nein |
| culture | Kultur der Quell- oder Senkenspalte. Anwenden, wenn der Typ Datetime oder Datetimeoffset ist. Der Standardwert lautet en-us.Im Allgemeinen müssen Sie diese Eigenschaft nicht angeben oder ändern. Weitere Informationen zu Datentypzuordnung. |
Nein |
| format | Zu verwendende Formatzeichenfolge, wenn der Typ Datetime oder Datetimeoffset ist. Informationen zum Formatieren von Datum und Uhrzeit finden Sie unter Benutzerdefinierte Formatzeichenfolgen für Datum und Uhrzeit. Im Allgemeinen müssen Sie diese Eigenschaft nicht angeben oder ändern. Weitere Informationen zu Datentypzuordnung. |
Nein |
Die folgenden Eigenschaften werden unter translator und unter mappings unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| collectionReference | Wird beim Kopieren von Daten aus einer hierarchischen Quelle (z. B. Azure Cosmos DB-, MongoDB- oder REST-Connectors) angewendet. Wenn Sie Daten durchlaufen und Objekte innerhalb eines Arrayfelds mit demselben Muster extrahieren, und wenn Sie möchten, dass jedes Objekt in einer neuen Zeile steht, geben Sie den JSON-Pfad dieses Arrays für die übergreifende Anwendung an. |
Nein |
Tabellarische Quelle zu tabellarischer Senke
Beispielsweise zum Kopieren von Daten aus Salesforce in Azure SQL-Datenbank und zum expliziten Zuordnen von drei Spalten:
Klicken Sie in der Kopieraktivität auf der Registerkarte –>„Zuordnung“ auf die Schaltfläche Schemas importieren, um das Quell- und das Senkenschema zu importieren.
Ordnen Sie die erforderlichen Felder zu, und schließen Sie die restlichen Felder aus bzw. löschen Sie sie.

Dieselbe Zuordnung kann als folgende Nutzlast der Kopieraktivität konfiguriert werden (siehe translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Beim Kopieren von Daten aus durch Trennzeichen getrennten Textdateien ohne Kopfzeile werden die Spalten durch Ordnungszahlen statt durch Namen dargestellt.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Hierarchische Quelle zu tabellarischer Senke
Beim Kopieren von Daten aus einer hierarchischen Quelle in eine tabellarische Senke werden von der Kopieraktivität die folgenden Funktionen unterstützt:
- Extrahieren von Daten aus Objekten und Arrays.
- Übergreifendes Anwenden mehrerer Objekte mit demselben Muster aus einem Array, wobei im tabellarischen Ergebnis ein JSON-Objekt in mehrere Datensätze konvertiert wird.
Für eine erweiterte Transformation von hierarchisch zu tabellarisch können Sie Datenfluss verwenden.
Sie besitzen zum Beispiel ein MongoDB-Quelldokument mit folgendem Inhalt:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
Wenn Sie es in eine Textdatei im folgenden Format mit Kopfzeile kopieren möchten, indem Sie die Daten im Array (order_pd und order_price) vereinfachen und mit den allgemeinen Stamminformationen (Anzahl, Datum und Stadt) überkreuzt verknüpfen, dann gilt Folgendes:
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Sie können eine Zuordnung dieser Art über die Data Factory-Benutzeroberfläche für die Erstellung definieren:
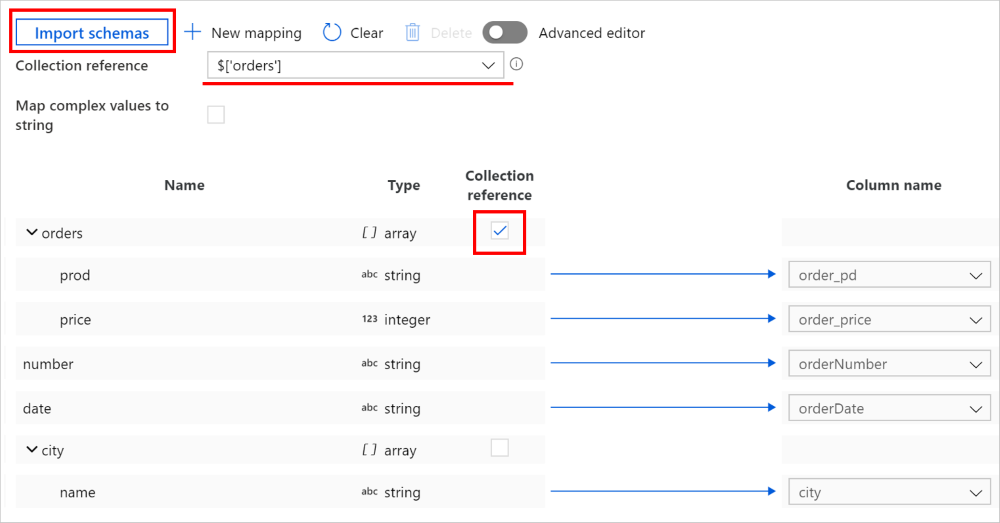
Klicken Sie in der Kopieraktivität auf der Registerkarte –>„Zuordnung“ auf die Schaltfläche Schemas importieren, um das Quell- und das Senkenschema zu importieren. Da der Dienst beim Importieren eines Schemas die obersten Objekte abfragt, können Sie, falls ein Feld nicht angezeigt wird, dieses der entsprechenden Ebene in der Hierarchie hinzufügen. Zeigen Sie hierzu auf einen vorhandenen Feldnamen, und geben Sie an, dass Sie einen Knoten, ein Objekt oder ein Array hinzufügen möchten.
Wählen Sie das Array aus, in dem Sie Daten durchlaufen und aus dem Sie Daten extrahieren möchten. Das Feld wird automatisch als Auflistungsverweis ausgefüllt. Bei diesem Vorgang wird nur ein einzelnes Array unterstützt.
Ordnen Sie der Senke die erforderlichen Felder zu. Die zugehörigen JSON-Pfade für die hierarchische Seite werden automatisch vom Dienst bestimmt.
Hinweis
Wenn bei einem Datensatz das als Sammlungsverweis markierte Array leer und das Kontrollkästchen aktiviert ist, wird der gesamte Datensatz übersprungen.
Sie können auch zum erweiterten Editor wechseln. Dann können Sie die JSON-Pfade der Felder direkt anzeigen und bearbeiten. Wenn Sie neue Zuordnungen in dieser Ansicht hinzufügen möchten, geben Sie den JSON-Pfad an.
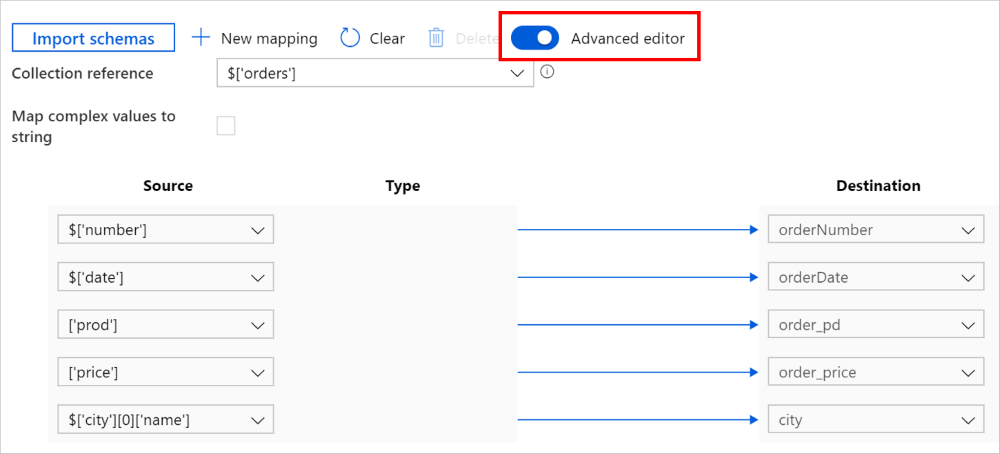
Dieselbe Zuordnung kann als folgende Nutzlast der Kopieraktivität konfiguriert werden (siehe translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Tabellarische/hierarchische Quelle zu hierarchischer Senke
Der Ablauf für den Benutzer ist mit dem bei der Zuordnung einer hierarchischen Quelle zu einer tabellarischen Senke vergleichbar.
Beim Kopieren von Daten aus einer tabellarischen Quelle in eine hierarchische Senke wird das Schreiben in ein Array innerhalb des Objekts nicht unterstützt.
Beim Kopieren von Daten aus einer hierarchischen Quelle in eine hierarchische Senke können Sie zusätzlich die gesamte Hierarchie der Ebene beibehalten, indem Sie das Objekt/Array auswählen und der Senke zuordnen, ohne die internen Felder bearbeiten zu müssen.
Für eine erweiterte Transformation zur Umstrukturierung von Daten können Sie Datenfluss verwenden.
Parametrisieren von Zuordnungen
Wenn Sie eine vorlagenbasierte Pipeline zum dynamischen Kopieren einer großen Anzahl von Objekten erstellen möchten, ermitteln Sie, ob Sie die Standardzuordnung nutzen können oder expliziten Zuordnungen für die jeweiligen Objekte definieren müssen.
Wenn eine explizite Zuordnung erforderlich ist, haben Sie folgende Möglichkeiten:
Definieren Sie einen Parameter mit einem Objekttyp auf Pipelineebene, z. B.
mapping.Parametrisieren Sie die Zuordnung: Wählen Sie in der Kopieraktivität auf der Registerkarte –>„Zuordnung“, dass Sie dynamischen Inhalt hinzufügen möchten, und wählen Sie den oben angegebenen Parameter aus. Die Nutzlast der Aktivität lautet wie folgt:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Erstellen Sie den Wert, der an den Parameter „mapping“ übergeben werden soll. Hierbei muss es sich um das gesamte Objekt der Definition von
translatorhandeln. Informieren Sie sich über die Beispiele im Abschnitt Explizite Zuordnung. Beim Kopieren von einer tabellarischen Quelle in eine tabellarische Senke muss der Wert beispielsweise{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}lauten.
Datentypzuordnung
Bei der Kopieraktivität werden Zuordnungen von Quelltypen zu Senkentypen mit dem folgenden Schritten durchgeführt:
- Wandeln Sie die nativen Quelldatentypen in Interimsdatentypen um, die von Azure Data Factory- und Synapse-Pipelines verwendet werden.
- Automatisches Konvertieren von Zwischendatentypen zu entsprechenden Senkentypen bei der Standardzuordnung und bei der expliziten Zuordnung
- Wandeln Sie die Interimsdatentypen in native Senkendatentypen um.
Von der Kopieraktivität werden derzeit die folgenden Zwischendatentypen unterstützt: Boolean, Byte, Bytearray, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 und UInt64.
Die folgenden Datentypkonvertierungen werden unter den Zwischendatentypen von Quelle zu Senke unterstützt.
| Quelle\Senke | Boolean | Bytearray | Datum/Uhrzeit | Decimal | Float-point | GUID | Ganzzahl | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Bytearray | ✓ | ✓ | |||||||
| Date/Time | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Float-point | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) „Date/Time“ beinhaltet „DateTime“ und „DateTimeOffset“.
(2) „Float-point“ beinhaltet „Single“ und „Double“.
(3) „Integer“ beinhaltet „SByte“, „Byte“, „Int16“, „UInt16“, „Int32“, „UInt32“, „Int64“ und „UInt64“.
Hinweis
- Diese Datentypkonvertierung wird derzeit beim Kopieren von tabellarischen Daten unterstützt. Hierarchische Quellen/Senken werden nicht unterstützt. Das bedeutet, dass keine systemdefinierte Datentypkonvertierung zwischen den Zwischendatentypen von Quelle zu Senke erfolgt.
- Dieses Feature funktioniert nur beim neuesten Datasetmodell. Wenn diese Option auf der Benutzeroberfläche nicht angezeigt wird, versuchen Sie, ein neues Dataset zu erstellen.
Die folgenden Eigenschaften werden in der Kopieraktivität für die Datentypkonvertierung unterstützt (im Abschnitt translator für die programmatische Erstellung):
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| typeConversion | Aktiviert den neuen Workflow für die Datentypkonvertierung. Der Standardwert lautet aufgrund der Abwärtskompatibilität FALSE. Bei neuen Kopieraktivitäten, die seit Ende Juni 2020 über die Data Factory-Benutzeroberfläche für die Dokumenterstellung erstellt wurden, ist diese Datentypkonvertierung für die optimale Nutzung standardmäßig aktiviert. Außerdem werden in der Kopieraktivität auf der Registerkarte –>„Zuordnung“ die folgenden Einstellungen zur Typkonvertierung für entsprechende Szenarien angezeigt. Wenn Sie Pipelines programmgesteuert erstellen möchten, müssen Sie die Eigenschaft typeConversion explizit auf TRUE festlegen, um sie zu aktivieren.Bei vorhandenen Kopieraktivitäten, die vor der Einführung dieses Features erstellt wurden, werden in der Benutzeroberfläche für die Erstellung aus Gründen der Abwärtskompatibilität keine Optionen für die Datentypkonvertierung angezeigt. |
Nein |
| typeConversionSettings | Eine Gruppe von Datentypkonvertierungseinstellungen. Wird angewendet, wenn typeConversion auf true festgelegt ist. Die folgenden Eigenschaften befinden sich in dieser Gruppe. |
Nein |
Unter typeConversionSettings |
||
| allowDataTruncation | Ermöglicht das Abschneiden von Daten, wenn beim Kopieren Quelldaten in Senkendaten mit unterschiedlichem Datentyp konvertiert werden, beispielsweise von „Decimal“ zu „Integer“ bzw. von „DatetimeOffset“ zu „Datetime“. Der Standardwert ist true. |
Nein |
| treatBooleanAsNumber | Behandelt boolesche Werte wie Zahlen, z. B. TRUE wie 1. Der Standardwert ist „false“. |
Nein |
| dateTimeFormat | Formatzeichenfolge beim Konvertieren von Datumsangaben ohne Zeitzonenoffset und Zeichenfolgen, z. B. yyyy-MM-dd HH:mm:ss.fff. Ausführliche Informationen hierzu finden Sie unter Benutzerdefinierte Formatzeichenfolgen für Datum und Uhrzeit. |
Nein |
| dateTimeOffsetFormat | Formatzeichenfolge beim Konvertieren von Datumsangaben mit Zeitzonenoffset und Zeichenfolgen, z. B. yyyy-MM-dd HH:mm:ss.fff zzz. Ausführliche Informationen hierzu finden Sie unter Benutzerdefinierte Formatzeichenfolgen für Datum und Uhrzeit. |
Nein |
| timeSpanFormat | Formatzeichenfolge beim Konvertieren von Zeiträumen und Zeichenfolgen, z. B. dd\.hh\:mm. Ausführliche Informationen hierzu finden Sie unter Benutzerdefinierte TimeSpan-Formatzeichenfolgen. |
Nein |
| culture | Kulturinformationen, die beim Konvertieren von Datentypen verwendet werden sollen, z. B. en-us oder fr-fr. |
Nein |
Beispiel:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Legacy-Modelle
Hinweis
Die folgenden Modelle zum Zuordnen von Quellspalten/-feldern zur Senke werden aus Gründen der Abwärtskompatibilität weiterhin unverändert unterstützt. Es wird empfohlen, das unter Schemazuordnung erwähnte neue Modell zu verwenden. Die Benutzeroberfläche für die Erstellung wurde auf die Erzeugung des neuen Modells umgestellt.
Alternative Spaltenzuordnung (Legacy-Modell)
Sie können die Kopieraktivität –>translator –>columnMappings angeben, um tabellarisch strukturierte Daten zuzuordnen. In diesem Fall ist der Abschnitt „structure“ für Eingabe- und Ausgabedatasets erforderlich. Die Spaltenzuordnung unterstützt die Zuordnung aller oder einer Teilmenge der Spalten in „structure“ des Quelldatasets zu allen Spalten in „structure“ des Senkendatasets. Im Folgenden sind Fehlerbedingungen angegeben, die zu einer Ausnahme führen:
- Das Ergebnis der Abfrage des Quelldatenspeichers enthält keinen Spaltennamen, der im Abschnitt „structure“ des Eingabedatasets angegeben wird.
- Der Senkendatenspeicher (sofern mit vordefiniertem Schema) enthält keinen Spaltennamen, der im Abschnitt „structure“ des Ausgabedatasets angegeben wird.
- Entweder sind weniger Spalten oder mehr Spalten in „structure“ des Senkendatasets, als in der Zuordnung angegeben.
- Doppelte Zuordnung.
Im folgenden Beispiel verfügt das Eingabedataset über eine Struktur, die auf eine Tabelle in einer lokalen Oracle-Datenbank verweist.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
In diesem Beispiel verfügt das Ausgabedataset über eine Struktur, und diese verweist auf eine Tabelle in Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Der folgende JSON-Code definiert eine Kopieraktivität in einer Pipeline. Die Spalten der Quelle werden mithilfe der Eigenschaft translator –>columnMappings den Spalten der Senke zugeordnet.
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Wenn Sie zum Angeben der Spaltenzuordnung die Syntax "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" verwenden, wird sie weiterhin unverändert unterstützt.
Alternative Schemazuordnung (Legacy-Modell)
Sie können die Kopieraktivität ->translator ->schemaMapping angeben, um hierarchisch und tabellarisch strukturierte Daten zuzuordnen, z. B. Kopieren aus MongoDB/REST in eine Textdatei oder aus Oracle zu Azure Cosmos DB for MongoDB. Folgende Eigenschaften werden im Abschnitt translator der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Kopieraktivität „translator“ muss auf Folgendes festgelegt werden: TabularTranslator | Ja |
| schemaMapping | Eine Sammlung von Schlüssel-Wert-Paaren, die die Zuordnungsbeziehung von der Quelle zur Senke darstellt. - Schlüssel: stellt die Quelle dar. Für eine tabellarische Quelle legen Sie den Spaltennamen wie in der Datasetstruktur definiert fest. Für eine hierarchische Quelle legen Sie den Ausdruck des JSON-Pfads für jedes zu extrahierende und zuzuordnende Feld fest. - Wert: stellt die Senke dar. Für eine tabellarische Senke legen Sie den Spaltennamen wie in der Datasetstruktur definiert fest. Für eine hierarchische Senke legen Sie den Ausdruck des JSON-Pfads für jedes zu extrahierende und zuzuordnende Feld fest. Bei hierarchischen Daten beginnt der JSON-Pfad für Felder unter der Stammobjekt mit dem Stamm „$“. Für Felder innerhalb des von der collectionReference-Eigenschaften ausgewählten Arrays beginnt der JSON-Pfad mit dem Array-Element. |
Ja |
| collectionReference | Wenn Sie Daten durchlaufen und Objekte innerhalb eines Arrayfelds mit demselben Muster extrahieren, und wenn Sie möchten, dass jedes Objekt in einer neuen Zeile steht, geben Sie den JSON-Pfad dieses Arrays für die übergreifende Anwendung an. Diese Eigenschaft wird nur unterstützt, wenn hierarchische Daten die Quelle sind. | Nein |
Beispiel: Kopieren aus MongoDB nach Oracle:
Sie besitzen zum Beispiel ein MongoDB-Dokument mit folgendem Inhalt:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
Wenn Sie es in eine Azure SQL-Tabelle im folgenden Format kopieren möchten, indem Sie die Daten im Array (order_pd und order_price) vereinfachen und mit den allgemeinen Stamminformationen (Anzahl, Datum und Stadt) überkreuzt verknüpfen, dann gilt Folgendes:
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Konfigurieren Sie die Regel für die Schemazuordnung wie im folgenden JSON-Beispiel für die Kopieraktivität:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Zugehöriger Inhalt
Weitere Informationen finden Sie in den anderen Artikeln zur Kopieraktivität:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für