Tutorial: Kopieren von Daten aus einer SQL Server-Datenbank in Azure Blob Storage
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie Azure PowerShell zum Erstellen einer Data Factory-Pipeline, mit der Daten aus einer SQL Server-Datenbank in Azure Blob Storage kopiert werden. Sie erstellen und verwenden eine selbstgehostete Integration Runtime, die Daten zwischen lokalen Speichern und Clouddatenspeichern verschiebt.
Hinweis
Dieser Artikel enthält keine ausführliche Einführung in den Data Factory-Dienst. Weitere Informationen finden Sie unter Einführung in Azure Data Factory.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Erstellen von verknüpften SQL Server- und Azure Storage-Diensten
- Erstellen von SQL Server- und Azure Blob-Datasets
- Erstellen einer Pipeline mit Kopieraktivität zum Verschieben der Daten
- Starten einer Pipelineausführung
- Überwachen der Pipelineausführung.
Voraussetzungen
Azure-Abonnement
Wenn Sie nicht bereits ein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Azure-Rollen
Damit Sie Data Factory-Instanzen erstellen können, muss dem Benutzerkonto, mit dem Sie sich bei Azure anmelden, die Rolle Mitwirkender oder Besitzer zugewiesen sein, oder es muss ein Administrator des Azure-Abonnements sein.
Wählen Sie im Azure-Portal in der oberen rechten Ecke Ihren Benutzernamen und dann Berechtigungen, um Ihre Berechtigungen im Abonnement anzuzeigen. Wenn Sie Zugriff auf mehrere Abonnements besitzen, wählen Sie das entsprechende Abonnement aus. Beispielanleitungen zum Hinzufügen eines Benutzers zu einer Rolle finden Sie im Artikel Hinzufügen von Azure-Rollenzuweisungen über das Azure-Portal.
SQL Server 2014, 2016 und 2017
In diesem Tutorial verwenden Sie eine SQL Server-Datenbank als Quelldatenspeicher. Die Pipeline in der in diesem Tutorial erstellten Data Factory kopiert Daten aus dieser SQL Server-Datenbank (Quelle) in Azure Blob Storage (Senke). Anschließend erstellen Sie eine Tabelle mit dem Namen emp in Ihrer SQL Server-Datenbank und fügen einige Einträge in die Tabelle ein.
Starten Sie SQL Server Management Studio. Falls die Installation auf Ihrem Computer noch nicht vorhanden ist, helfen Ihnen die Informationen unter Herunterladen von SQL Server Management Studio (SSMS) weiter.
Stellen Sie eine Verbindung mit Ihrer SQL Server-Instanz her, indem Sie Ihre Anmeldeinformationen verwenden.
Erstellen Sie eine Beispieldatenbank. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf Datenbanken, und wählen Sie anschließend Neue Datenbank.
Geben Sie im Fenster Neue Datenbank einen Namen für die Datenbank ein, und wählen Sie dann OK.
Führen Sie das folgende Abfrageskript für die Datenbank aus, um die Tabelle emp zu erstellen und einige Beispieldaten einzufügen. Klicken Sie in der Strukturansicht mit der rechten Maustaste auf die von Ihnen erstellte Datenbank, und wählen Sie anschließend Neue Abfrage.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure-Speicherkonto
Sie verwenden in diesem Tutorial ein allgemeines Azure-Speicherkonto (Azure Blob Storage) als Ziel/Senke-Datenspeicher. Falls Sie noch nicht über ein allgemeines Azure-Speicherkonto verfügen, helfen Ihnen die Informationen unter Erstellen Sie ein Speicherkonto weiter. Die Pipeline in der in diesem Tutorial erstellten Data Factory kopiert Daten aus der SQL Server-Datenbank (Quelle) in diese Azure Blob Storage-Instanz (Senke).
Abrufen des Speicherkontonamens und des Kontoschlüssels
In diesem Tutorial verwenden Sie Name und Schlüssel Ihres Azure-Speicherkontos. Beschaffen Sie den Namen und Schlüssel Ihres Speicherkontos, indem Sie wie folgt vorgehen:
Melden Sie sich mit Ihrem Azure-Benutzernamen und dem dazugehörigen Kennwort am Azure-Portal an.
Wählen Sie im linken Bereich die Option Weitere Dienste, filtern Sie nach dem Schlüsselwort Speicher, und wählen Sie dann Speicherkonten aus.
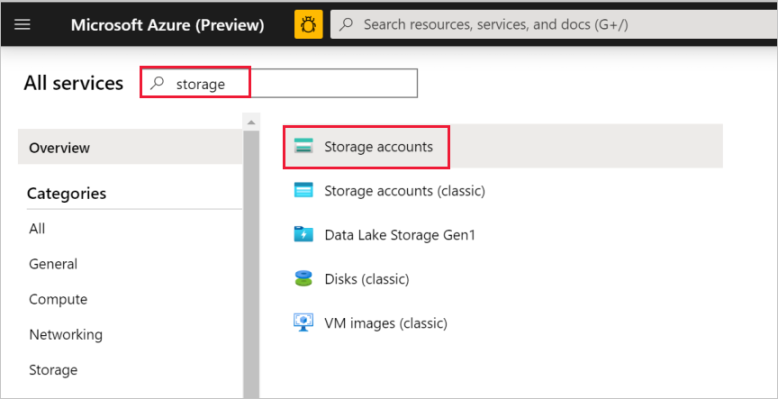
Filtern Sie in der Liste mit den Speicherkonten nach Ihrem Speicherkonto (falls erforderlich), und wählen Sie Ihr Speicherkonto aus.
Wählen Sie im Fenster Speicherkonto die Option Zugriffsschlüssel.
Kopieren Sie in den Feldern Speicherkontoname und key1 die Werte, und fügen Sie sie zur späteren Verwendung im Tutorial in einen Editor ein.
Erstellen des Containers „adftutorial“
In diesem Abschnitt erstellen Sie einen Blobcontainer mit dem Namen adftutorial in Ihrer Azure Blob Storage-Instanz.
Wechseln Sie im Fenster Speicherkonto zu Übersicht, und wählen Sie die Option Blobs.
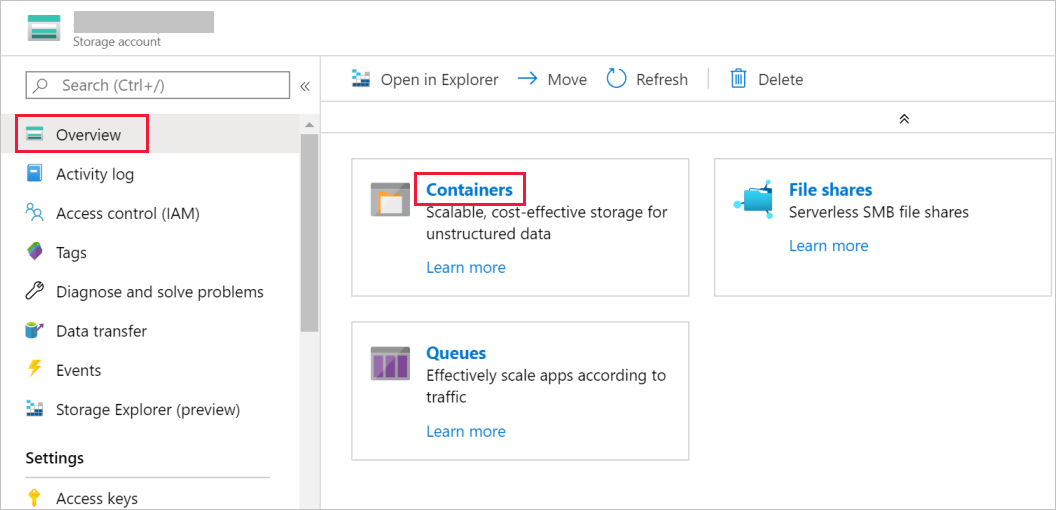
Wählen Sie im Fenster Blob-Dienst die Option Container.
Geben Sie im Fenster Neuer Container im Feld Name den Namen adftutorial ein, und wählen Sie OK.
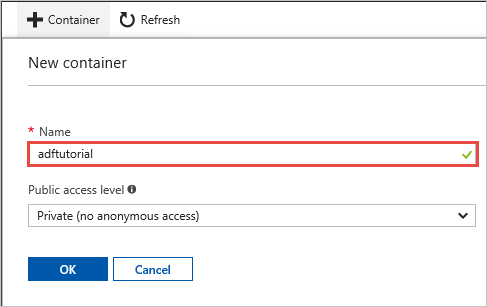
Wählen Sie in der Liste mit den Containern die Option adftutorial.
Lassen Sie das Fenster Container für adftutorial geöffnet. Sie überprüfen darauf am Ende des Tutorials die Ausgabe. Data Factory erstellt den Ausgabeordner automatisch in diesem Container, damit Sie ihn nicht selbst erstellen müssen.
Windows PowerShell
Installieren von Azure Powershell
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Installieren Sie die neueste Version von Azure PowerShell, falls sie auf Ihrem Computer noch nicht vorhanden ist. Ausführliche Anweisungen finden Sie unter Installieren und Konfigurieren von Azure PowerShell.
Anmelden an PowerShell
Starten Sie PowerShell auf Ihrem Computer, und lassen Sie die Anwendung geöffnet, während Sie dieses Schnellstarttutorial durcharbeiten. Wenn Sie PowerShell schließen und wieder öffnen, müssen Sie die Befehle erneut ausführen.
Führen Sie den folgenden Befehl aus, und geben Sie anschließend den Azure-Benutzernamen und das Kennwort ein, den bzw. das Sie bei der Anmeldung beim Azure-Portal verwendet haben:
Connect-AzAccountFühren Sie den folgenden Befehl aus, um das zu verwendende Abonnement auszuwählen, wenn Sie über mehrere Azure-Abonnements verfügen. Ersetzen Sie SubscriptionId durch die ID Ihres Azure-Abonnements:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Erstellen einer Data Factory
Definieren Sie eine Variable für den Ressourcengruppennamen zur späteren Verwendung in PowerShell-Befehlen. Kopieren Sie den folgenden Befehl nach PowerShell, geben Sie einen Namen für die Azure-Ressourcengruppe an (in doppelten Anführungszeichen, z.B.
"adfrg"), und führen Sie dann den Befehl aus.$resourceGroupName = "ADFTutorialResourceGroup"Führen Sie den folgenden Befehl aus, um die Azure-Ressourcengruppe zu erstellen:
New-AzResourceGroup $resourceGroupName -location 'East US'Beachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$resourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Data Factory-Namen zur späteren Verwendung in PowerShell-Befehlen. Der Name muss mit einem Buchstaben oder einer Zahl beginnen und darf nur Buchstaben, Zahlen und Bindestriche (-) enthalten.
Wichtig
Ersetzen Sie den Data Factory-Namen durch einen global eindeutigen Namen. Ein Beispiel hierfür ist ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Definieren Sie eine Variable für den Speicherort der Data Factory:
$location = "East US"Führen Sie das folgende
Set-AzDataFactoryV2-Cmdlet aus, um die Data Factory zu erstellen:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Hinweis
- Der Name der Data Factory muss global eindeutig sein. Wenn die folgende Fehlermeldung angezeigt wird, ändern Sie den Namen, und wiederholen Sie den Vorgang.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Damit Sie Data Factory-Instanzen erstellen können, muss dem Benutzerkonto, mit dem Sie sich bei Azure anmelden, die Rolle Mitwirkender oder Besitzer zugewiesen sein, oder es muss ein Administrator des Azure-Abonnements sein.
- Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computeeinheiten (Azure HDInsight usw.), die von der Data Factory genutzt werden, können sich in anderen Regionen befinden.
Erstellen einer selbstgehosteten Integration Runtime
In diesem Abschnitt erstellen Sie eine selbstgehostete Integration Runtime und ordnen sie einem lokalen Computer mit der SQL Server-Datenbank zu. Die selbstgehostete Integration Runtime ist die Komponente, die Daten aus der SQL Server-Datenbank auf Ihrem Computer in Azure Blob Storage kopiert.
Erstellen Sie eine Variable für den Namen der Integration Runtime. Verwenden Sie einen eindeutigen Namen, und notieren Sie ihn. Sie benötigen ihn später in diesem Tutorial.
$integrationRuntimeName = "ADFTutorialIR"Erstellen Sie eine selbstgehostete Integration Runtime.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Hier ist die Beispielausgabe:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Führen Sie den folgenden Befehl aus, um den Status der erstellten Integration Runtime abzurufen:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusHier ist die Beispielausgabe:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Führen Sie den folgenden Befehl aus, um die Authentifizierungsschlüssel abzurufen, mit denen Sie die selbstgehostete Integration Runtime beim Data Factory-Dienst in der Cloud registrieren können. Kopieren Sie einen der Schlüssel (ohne Anführungszeichen) zum Registrieren der selbstgehosteten Integration Runtime, die Sie im nächsten Schritt auf Ihrem Computer installieren.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonHier ist die Beispielausgabe:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Installieren der Integration Runtime
Laden Sie die Azure Data Factory Integration Runtime auf einen lokalen Windows-Computer herunter, und führen Sie anschließend die Installation aus.
Wählen Sie auf der Willkommensseite des Einrichtungsassistenten für die Microsoft Integration Runtime die Option Weiter.
Stimmen Sie im Fenster mit dem Endbenutzer-Lizenzvertrag den Bedingungen bzw. dem Lizenzvertrag zu, und wählen Sie Weiter.
Wählen Sie im Fenster Zielordner die Option Weiter.
Wählen Sie im Fenster Ready to install Microsoft Integration Runtime (Bereit für Installation der Microsoft Integration Runtime) die Option Installieren.
Wählen Sie unter Completed the Microsoft Integration Runtime Setup Wizard (Setup-Assistent für Microsoft Integration Runtime abgeschlossen) die Option Fertig stellen.
Fügen Sie im Fenster Integrationslaufzeit (selbstgehostet) registrieren den Schlüssel ein, den Sie im vorherigen Abschnitt gespeichert haben, und wählen Sie dann die Option Registrieren.
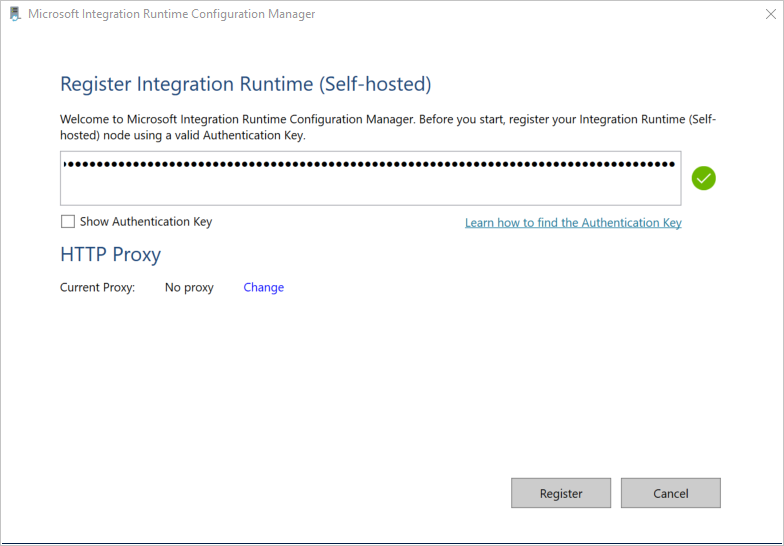
Wählen Sie im Fenster Neuer Integration Runtime-Knoten (selbstgehostet) die Option Fertig stellen.
Wenn die selbstgehostete Integration Runtime erfolgreich registriert wurde, wird die folgende Meldung angezeigt:
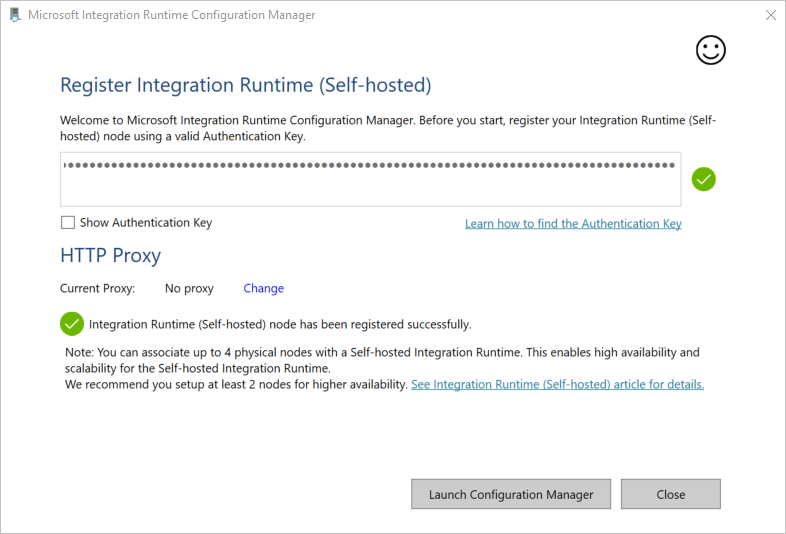
Wählen Sie im Fenster Integrationslaufzeit (selbstgehostet) registrieren die Option Konfigurations-Manager starten.
Wenn der Knoten mit dem Clouddienst verbunden ist, wird die folgende Meldung angezeigt:
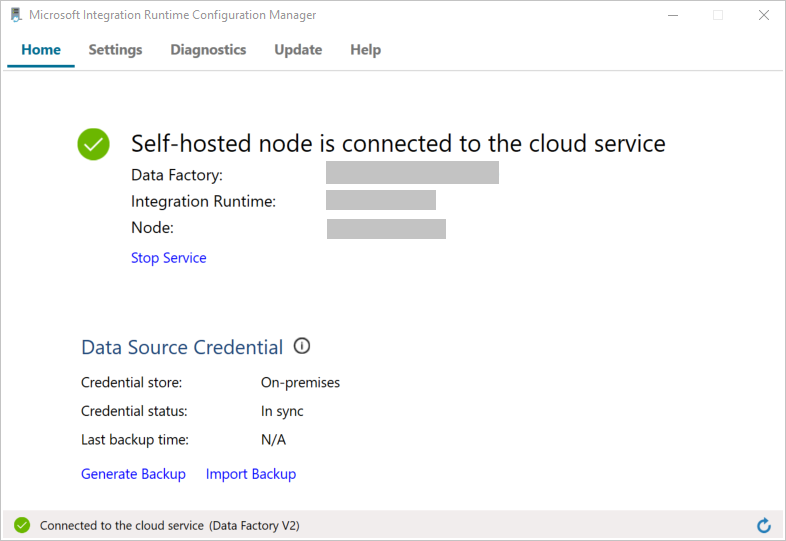
Testen Sie die Verbindung mit Ihrer SQL Server-Datenbank, indem Sie wie folgt vorgehen:
a. Wechseln Sie im Fenster Konfigurations-Manager zur Registerkarte Diagnose.
b. Wählen Sie im Feld Datenquellentyp die Option SqlServer.
c. Geben Sie den Servernamen ein.
d. Geben Sie den Datenbanknamen ein.
e. Wählen Sie den Authentifizierungsmodus aus.
f. Geben Sie den Benutzernamen ein.
g. Geben Sie das Kennwort ein, das dem Benutzernamen zugeordnet ist.
h. Wählen Sie die Option Test, um zu überprüfen, ob die Integration Runtime eine Verbindung mit SQL Server herstellen kann.
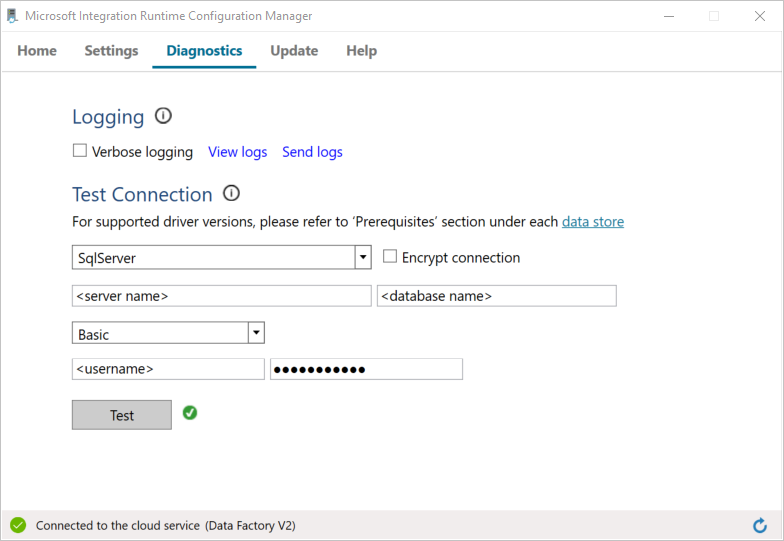
Wenn die Verbindungsherstellung erfolgreich war, wird ein grünes Häkchen angezeigt. Andernfalls wird eine Fehlermeldung angezeigt. Beheben Sie alle Probleme, und stellen Sie sicher, dass die Integration Runtime eine Verbindung mit Ihrer SQL Server-Instanz herstellen kann.
Notieren Sie sich alle obigen Werte zur späteren Verwendung in diesem Tutorial.
Erstellen von verknüpften Diensten
Erstellen Sie verknüpfte Dienste in einer Data Factory, um Ihre Datenspeicher und Computedienste mit der Data Factory zu verknüpfen. In diesem Tutorial verknüpfen Sie Ihr Azure-Speicherkonto und die SQL Server-Instanz mit dem Datenspeicher. Die verknüpften Dienste enthalten die Verbindungsinformationen, die der Data Factory-Dienst zur Verbindungsherstellung zur Laufzeit verwendet.
Erstellen eines verknüpften Azure Storage-Diensts (Ziel/Senke)
In diesem Schritt verknüpfen Sie Ihr Azure-Speicherkonto mit der Data Factory.
Erstellen Sie im Ordner C:\ADFv2Tutorial eine JSON-Datei mit dem Namen AzureStorageLinkedService.json und folgendem Code. Erstellen Sie den Ordner ADFv2Tutorial, falls er noch nicht vorhanden ist.
Wichtig
Ersetzen Sie vor dem Speichern der Datei <accountName> und <accountKey> durch den Namen bzw. Schlüssel Ihres Azure-Speicherkontos. Sie haben sich diese Angaben im Abschnitt Voraussetzungen notiert.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Wechseln Sie in PowerShell zum Ordner C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Führen Sie das folgende
Set-AzDataFactoryV2LinkedService-Cmdlet aus, um den verknüpften Dienst „AzureStorageLinkedService“ zu erstellen:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Hier ist eine Beispielausgabe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceWenn Sie einen Fehler vom Typ „Datei nicht gefunden“ erhalten, sollten Sie das Vorhandensein der Datei überprüfen, indem Sie den Befehl
dirausführen. Entfernen Sie für den Dateinamen die Erweiterung .txt (z.B. „AzureStorageLinkedService.json.txt“), falls vorhanden, und führen Sie den PowerShell-Befehl dann erneut aus.
Erstellen und Verschlüsseln einen verknüpftes SQL Server-Diensts (Quelle)
In diesem Schritt verknüpfen Sie Ihre SQL Server-Instanz mit der Data Factory.
Erstellen Sie im Ordner C:\ADFv2Tutorial eine JSON-Datei mit dem Namen SqlServerLinkedService.json, indem Sie den folgenden Code verwenden:
Wichtig
Wählen Sie basierend auf der Authentifizierung, die Sie zum Herstellen einer Verbindung mit SQL Server verwenden, den Abschnitt aus.
Verwenden der SQL-Authentifizierung (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Verwenden der Windows-Authentifizierung:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Wichtig
- Wählen Sie basierend auf der Authentifizierung, die Sie zum Herstellen einer Verbindung mit Ihrer SQL Server-Instanz verwenden, den Abschnitt aus.
- Ersetzen Sie <Name der Integration Runtime> durch den Namen Ihrer Integration Runtime.
- Ersetzen Sie vor dem Speichern der Datei <Servername>, <Datenbankname>, <Benutzername> und <Kennwort> durch die Werte Ihrer SQL Server-Instanz.
- Wenn Ihr Benutzerkonto- oder Servername einen umgekehrten Schrägstrich (\) enthält, ist es erforderlich, ein Escapezeichen (\) voranzustellen. Verwenden Sie beispielsweise mydomain\\myuser.
Führen Sie zum Verschlüsseln der sensiblen Daten (Benutzername, Kennwort usw.) das
New-AzDataFactoryV2LinkedServiceEncryptedCredential-Cmdlet aus.
Mit dieser Verschlüsselung wird sichergestellt, dass die Anmeldeinformationen per DPAPI (Data Protection Application Programming Interface) verschlüsselt werden. Die verschlüsselten Anmeldeinformationen werden lokal auf dem selbstgehosteten Integration Runtime-Knoten (lokaler Computer) gespeichert. Die Ausgabenutzlast kann an eine weitere JSON-Datei umgeleitet werden (in diesem Fall encryptedLinkedService.json), die verschlüsselte Anmeldeinformationen enthält.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonFühren Sie den folgenden Befehl aus, um EncryptedSqlServerLinkedService zu erstellen:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Erstellen von Datasets
In diesem Schritt erstellen Sie Eingabe- und Ausgabedatasets. Sie stellen Eingabe- und Ausgabedaten für den Kopiervorgang dar, bei dem Daten aus der SQL Server-Datenbank in Azure Blob Storage kopiert werden.
Erstellen eines Datasets für die SQL Server-Quelldatenbank
In diesem Schritt definieren Sie ein Dataset, das Daten in der SQL Server-Datenbankinstanz darstellt. Das Dataset ist vom Typ „SqlServerTable“. Es verweist auf den mit SQL Server verknüpften Dienst, den Sie im vorherigen Schritt erstellt haben. Der verknüpfte Dienst enthält die Verbindungsinformationen, die der Data Factory-Dienst zum Herstellen einer Verbindung mit Ihrer SQL Server-Instanz zur Laufzeit verwendet. Dieses Dataset gibt die SQL-Tabelle in der Datenbank mit den Daten an. In diesem Tutorial enthält die Tabelle emp die Quelldaten.
Erstellen Sie im Ordner C:\ADFv2Tutorial eine JSON-Datei mit dem Namen SqlServerDataset.json und folgendem Code:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Führen Sie das
Set-AzDataFactoryV2Dataset-Cmdlet aus, um das Dataset „SqlServerDataset“ zu erstellen.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Hier ist die Beispielausgabe:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Erstellen eines Datasets für Azure Blob Storage (Senke)
In diesem Schritt definieren Sie ein Dataset für Daten, die in Azure Blob Storage kopiert werden sollen. Das Dataset ist vom Typ „AzureBlob“. Es verweist auf den mit Azure Storage verknüpften Dienst, den Sie weiter oben in diesem Tutorial erstellt haben.
Der verknüpfte Dienst enthält die Verbindungsinformationen, die von der Data Factory zur Laufzeit zum Herstellen einer Verbindung mit Ihrem Azure-Speicherkonto verwendet werden. Dieses Dataset gibt den Ordner im Azure-Speicher an, in den die Daten aus der SQL Server-Datenbank kopiert werden. In diesem Tutorial lautet der Ordner adftutorial/fromonprem. Hierbei ist adftutorial der Blobcontainer und fromonprem der Ordner.
Erstellen Sie im Ordner C:\ADFv2Tutorial eine JSON-Datei mit dem Namen AzureBlobDataset.json und folgendem Code:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Führen Sie das
Set-AzDataFactoryV2Dataset-Cmdlet aus, um das Dataset „AzureBlobDataset“ zu erstellen.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Hier ist die Beispielausgabe:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Erstellen einer Pipeline
In diesem Tutorial erstellen Sie eine Pipeline mit einer Kopieraktivität. Die Kopieraktivität verwendet „SqlServerDataset“ als Eingabedataset und „AzureBlobDataset“ als Ausgabedataset. Der Quellentyp ist auf SqlSource und der Senkentyp auf BlobSink festgelegt.
Erstellen Sie im Ordner C:\ADFv2Tutorial eine JSON-Datei mit dem Namen SqlServerToBlobPipeline.json und folgendem Code:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Führen Sie das
Set-AzDataFactoryV2Pipeline-Cmdlet aus, um die Pipeline „SQLServerToBlobPipeline“ zu erstellen.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Hier ist die Beispielausgabe:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Erstellen einer Pipelineausführung
Starten Sie eine Pipelineausführung für die Pipeline „SQLServerToBlobPipeline“, und erfassen Sie die ID der Pipelineausführung für die zukünftige Überwachung.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Überwachen der Pipelineausführung
Führen Sie das folgende Skript in PowerShell aus, um den Ausführungsstatus der Pipeline „SQLServerToBlobPipeline“ kontinuierlich zu überprüfen und das Endergebnis auszugeben:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Hier ist die Ausgabe der Beispielausführung:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Sie können die Ausführungs-ID der Pipeline „SQLServerToBlobPipeline“ abrufen und das detaillierte Ergebnis der Aktivitätsausführung mit dem folgenden Befehl überprüfen:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Hier ist die Ausgabe der Beispielausführung:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Überprüfen der Ausgabe
Die Pipeline erstellt den Ausgabeordner fromonprem automatisch im Blobcontainer adftutorial. Vergewissern Sie sich, dass die Datei dbo.emp.txt im Ausgabeordner enthalten ist.
Wählen Sie im Azure-Portal im Fenster des Containers adftutorial die Option Aktualisieren, um den Ausgabeordner anzuzeigen.
Wählen Sie in der Liste mit den Ordnern die Option
fromonprem.Vergewissern Sie sich, dass die Datei
dbo.emp.txtangezeigt wird.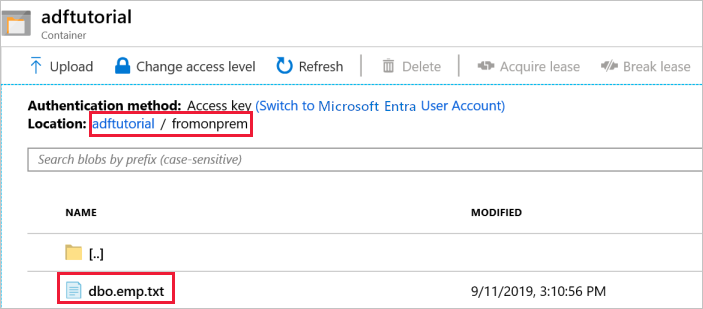
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel kopiert Daten in Azure Blob Storage von einem Speicherort an einen anderen. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Erstellen Sie eine selbstgehostete Integration Runtime.
- Erstellen von verknüpften SQL Server- und Azure Storage-Diensten
- Erstellen von SQL Server- und Azure Blob-Datasets
- Erstellen einer Pipeline mit Kopieraktivität zum Verschieben der Daten
- Starten einer Pipelineausführung
- Überwachen der Pipelineausführung.
Eine Liste mit den von der Data Factory unterstützten Datenspeichern finden Sie unter Unterstützte Datenspeicher.
Fahren Sie mit dem folgenden Tutorial fort, um mehr über das Kopieren von Daten per Massenvorgang aus einer Quelle in ein Ziel zu erfahren:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für