Transformieren von Daten in der Cloud mithilfe einer Spark-Aktivität in Azure Data Factory
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial verwenden Sie das Azure-Portal, um eine Azure Data Factory-Pipeline zu erstellen. In dieser Pipeline werden Daten transformiert, indem eine Spark-Aktivität und ein bedarfsabhängiger verknüpfter Azure HDInsight-Dienst verwendet wird.
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen Sie eine Pipeline, für die eine Spark-Aktivität verwendet wird.
- Auslösen einer Pipelineausführung
- Überwachen der Pipelineausführung.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
- Azure-Speicherkonto. Sie erstellen ein Python-Skript und eine Eingabedatei und laden diese in Azure Storage hoch. Die Ausgabe des Spark-Programms wird in diesem Speicherkonto gespeichert. Der bedarfsgesteuerte Spark-Cluster verwendet dieses Storage-Konto als primären Speicher.
Hinweis
HdInsight unterstützt nur universelle Speicherkonten mit dem Standard-Tarif. Stellen Sie sicher, dass das Konto kein Premium- oder ausschließlich für Blobs vorgesehenes Speicherkonto ist.
- Azure PowerShell. Befolgen Sie die Anweisungen unter Get started with Azure PowerShell cmdlets (Erste Schritte mit Azure PowerShell-Cmdlets).
Hochladen des Python-Skripts in Ihr BLOB-Speicherkonto
Erstellen Sie eine Python-Datei mit dem Namen WordCount_Spark.py und dem folgenden Inhalt:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Ersetzen Sie <storageAccountName> durch den Namen Ihres Azure-Speicherkontos. Speichern Sie dann die Datei.
Erstellen Sie in Azure Blob Storage einen Container mit dem Namen adftutorial, falls dieser noch nicht vorhanden ist.
Erstellen Sie einen Ordner mit dem Namen spark.
Erstellen Sie unterhalb des Ordners spark einen Unterordner mit dem Namen script.
Laden Sie die Datei WordCount_Spark.py in den Unterordner script hoch.
Hochladen der Eingabedatei
- Erstellen Sie eine Datei mit dem Namen minecraftstory.txt und etwas Text darin. Das Spark-Programm zählt die Wörter in diesem Text.
- Erstellen Sie im Ordner spark einen Unterordner mit dem Namen inputfiles.
- Laden Sie die Datei minecraftstory.txt in den Unterordner inputfiles hoch.
Erstellen einer Data Factory
Wenn Sie noch nicht über eine Data Factory verfügen, mit der Sie arbeiten können, führen Sie die im Artikel Schnellstart: Erstellen einer Data Factory im Azure-Portal aufgeführten Schritte aus, um eine Data Factory zu erstellen.
Erstellen von verknüpften Diensten
In diesem Abschnitt erstellen Sie zwei verknüpfte Dienste:
- Einen verknüpften Azure Storage-Dienst, der ein Azure-Speicherkonto mit der Data Factory verknüpft. Dieser Speicher wird vom bedarfsgesteuerten HDInsight-Cluster verwendet. Er enthält auch das Spark-Skript, das ausgeführt werden soll.
- Einen bedarfsgesteuerten verknüpften HDInsight-Dienst. Azure Data Factory erstellt automatisch einen HDInsight-Cluster und führt das Spark-Programm aus. Anschließend wird der HDInsight-Cluster gelöscht, nachdem er sich für einen vorkonfigurierten Zeitraum im Leerlauf befunden hat.
Erstellen eines verknüpften Azure Storage-Diensts
Wechseln Sie auf der Startseite im linken Bereich zur Registerkarte Verwalten.
Wählen Sie unten im Fenster die Option Verbindungen und dann + Neu.
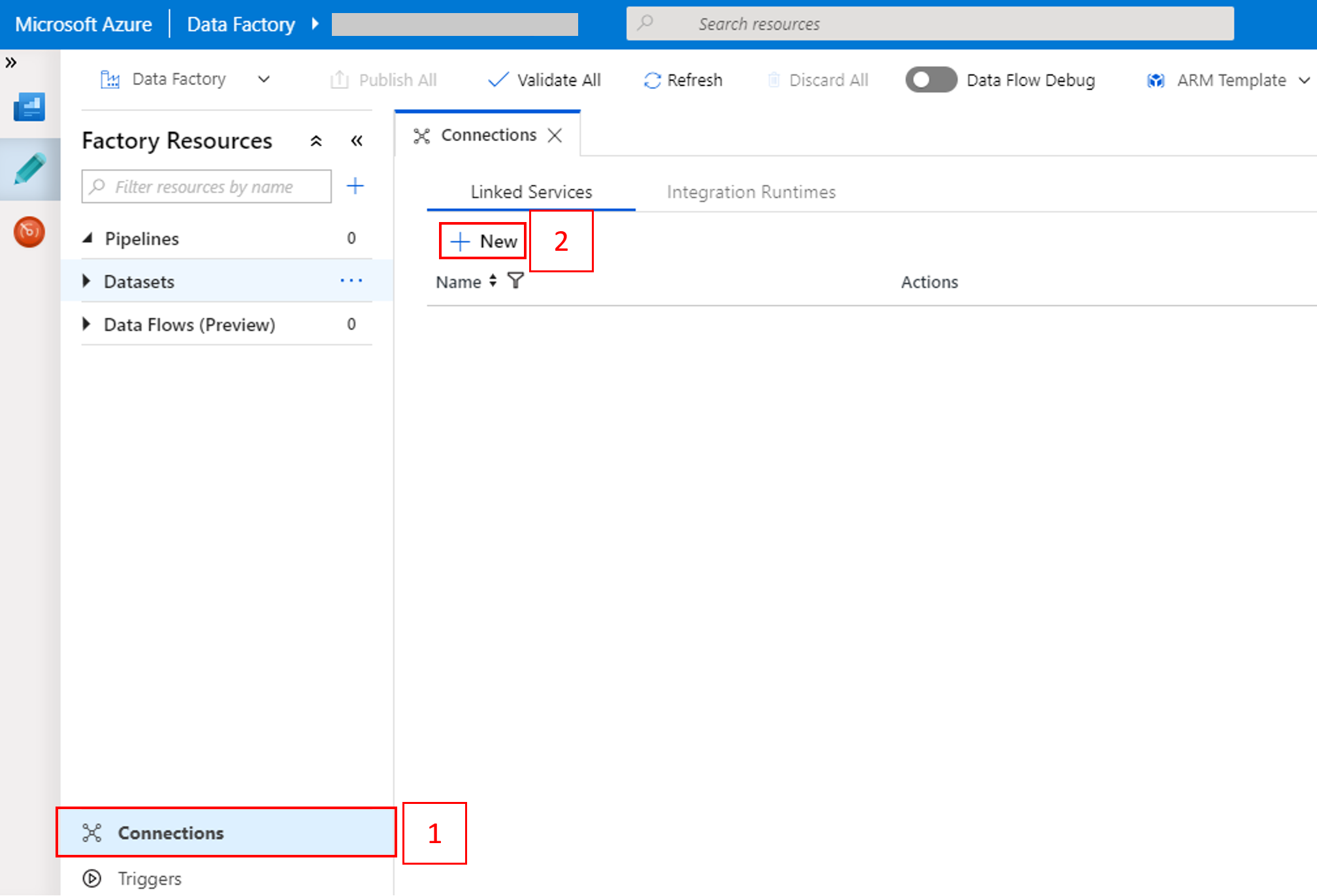
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Datenspeicher>Azure Blob Storage und dann Weiter.

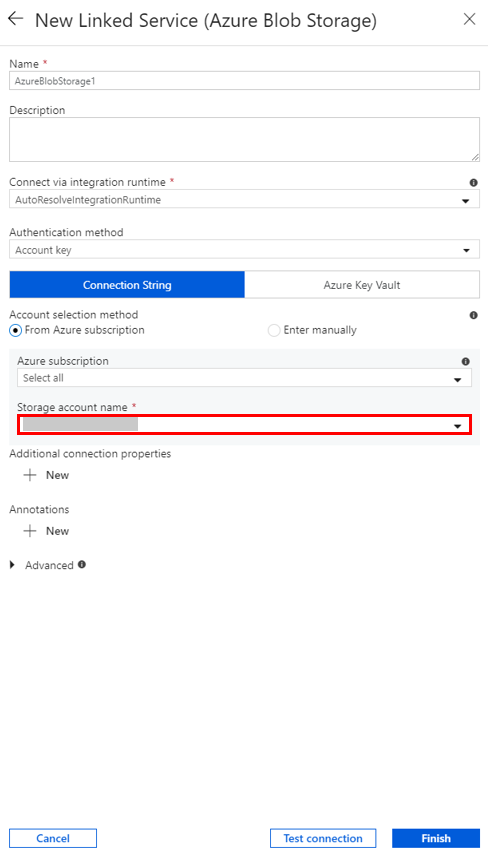
Wählen Sie für Speicherkontoname den Namen in der Liste aus, und wählen Sie anschließend die Option Speichern.
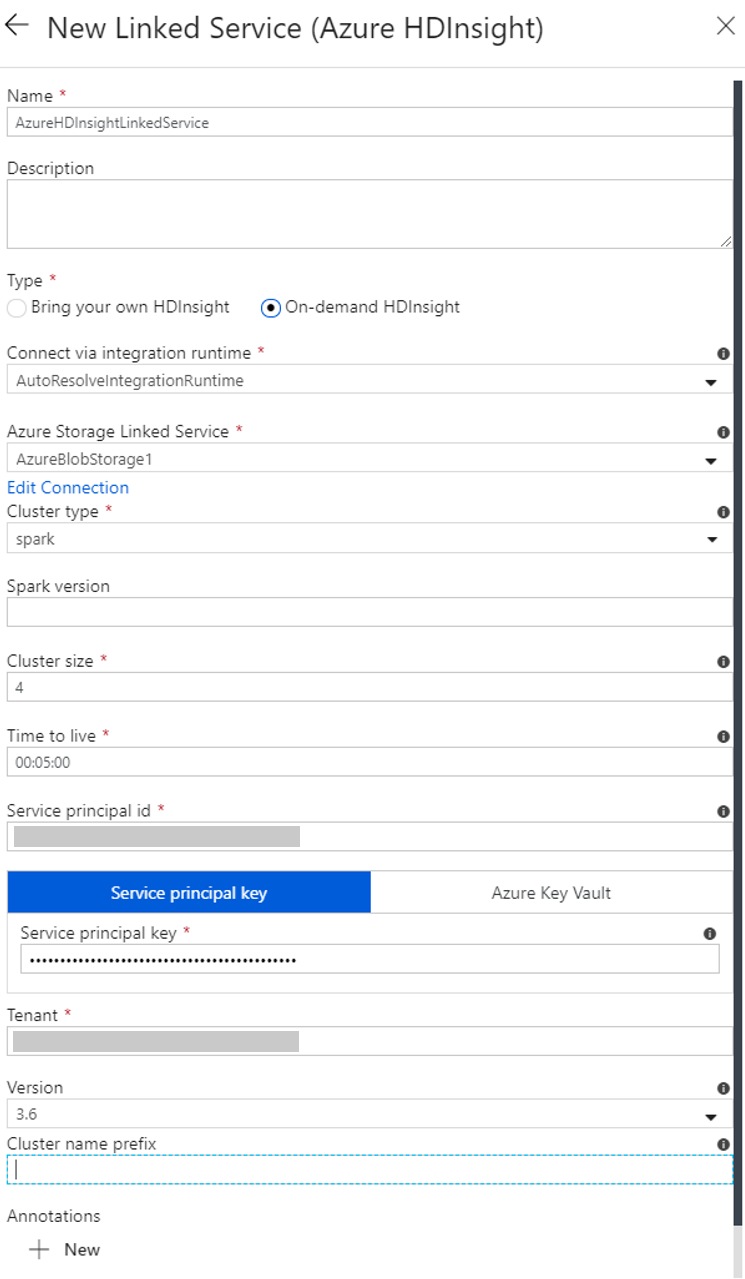
Erstellen eines bedarfsgesteuerten verknüpften HDInsight-Diensts
Wählen Sie erneut die Schaltfläche + Neu, um einen weiteren verknüpften Dienst zu erstellen.
Wählen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die Option Compute>Azure HDInsight und dann Weiter.

Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
a. Geben Sie unter Name die Zeichenfolge AzureHDInsightLinkedService ein.
b. Vergewissern Sie sich, dass unter Typ die Option On-demand HDInsight (HDInsight (bedarfsgesteuert)) ausgewählt ist.
c. Wählen Sie unter Mit Azure Storage verknüpfter Dienst die Option AzureBlobStorage1 aus. Diesen verknüpften Dienst haben Sie in einem früheren Schritt erstellt. Sollten Sie einen anderen Namen verwendet haben, geben Sie hier stattdessen diesen Namen ein.
d. Wählen Sie unter Clustertyp die Option spark.
e. Geben Sie unter Dienstprinzipal-ID die ID des Dienstprinzipals ein, der zum Erstellen eines HDInsight-Clusters berechtigt ist.
Dieser Dienstprinzipal muss Mitglied der Rolle „Mitwirkender“ in dem Abonnement oder der Ressourcengruppe sein, in dem bzw. der der Cluster erstellt wird. Weitere Informationen finden Sie unter Erstellen einer Microsoft Entra-Anwendung und eines Dienstprinzipals. Die Dienstprinzipal-ID entspricht der Anwendungs-ID und ein Dienstprinzipalschlüssel dem Wert für ein Clientgeheimnis.
f. Geben Sie unter Dienstprinzipalschlüssel den Schlüssel ein.
g. Wählen Sie unter Ressourcengruppe dieselbe Ressourcengruppe aus, die Sie auch beim Erstellen der Data Factory verwendet haben. Der Spark-Cluster wird in dieser Ressourcengruppe erstellt.
h. Erweitern Sie Betriebssystemtyp.
i. Geben Sie einen Namen für Clusterbenutzername ein.
j. Geben Sie das Clusterkennwort für den Benutzer ein.
k. Wählen Sie Fertig stellenaus.
Hinweis
Die Gesamtanzahl von Kernen, die Sie in jeder von Azure HDInsight unterstützten Azure-Region verwenden können, ist begrenzt. Beim bedarfsgesteuerten verknüpften HDInsight-Dienst wird der HDInsight-Cluster an demselben Azure Storage-Speicherort erstellt, der als primärer Speicher verwendet wird. Stellen Sie sicher, dass Sie über genügend Kernkontingente verfügen, sodass der Cluster erfolgreich erstellt werden kann. Weitere Informationen finden Sie unter Einrichten von Clustern in HDInsight mit Hadoop, Spark, Kafka usw.
Erstellen einer Pipeline
Wählen Sie die Schaltfläche + (Pluszeichen) und dann im Menü die Option Pipeline aus.
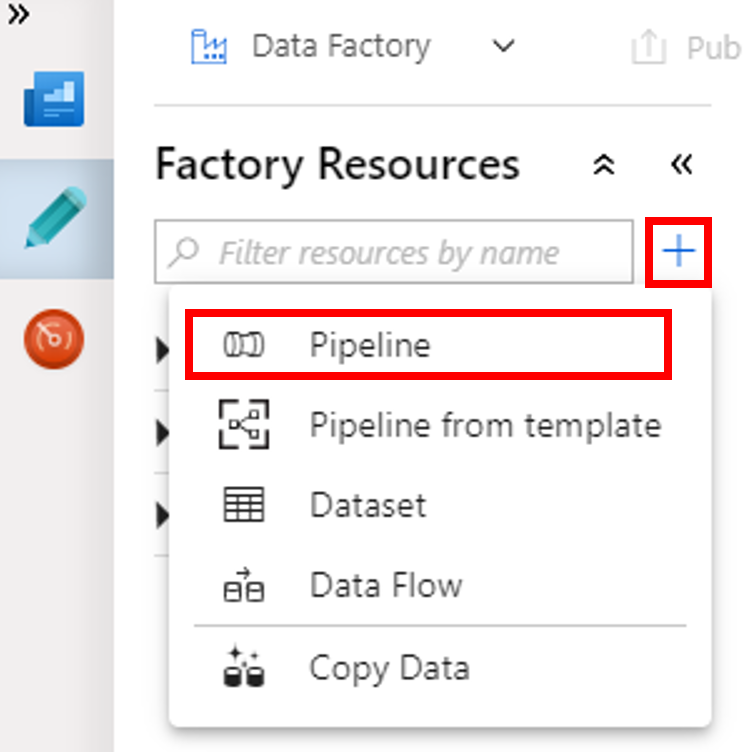
Erweitern Sie in der Toolbox Aktivitäten die Option HDInsight. Ziehen Sie die Spark-Aktivität aus der Toolbox Aktivitäten auf die Oberfläche des Pipeline-Designers.
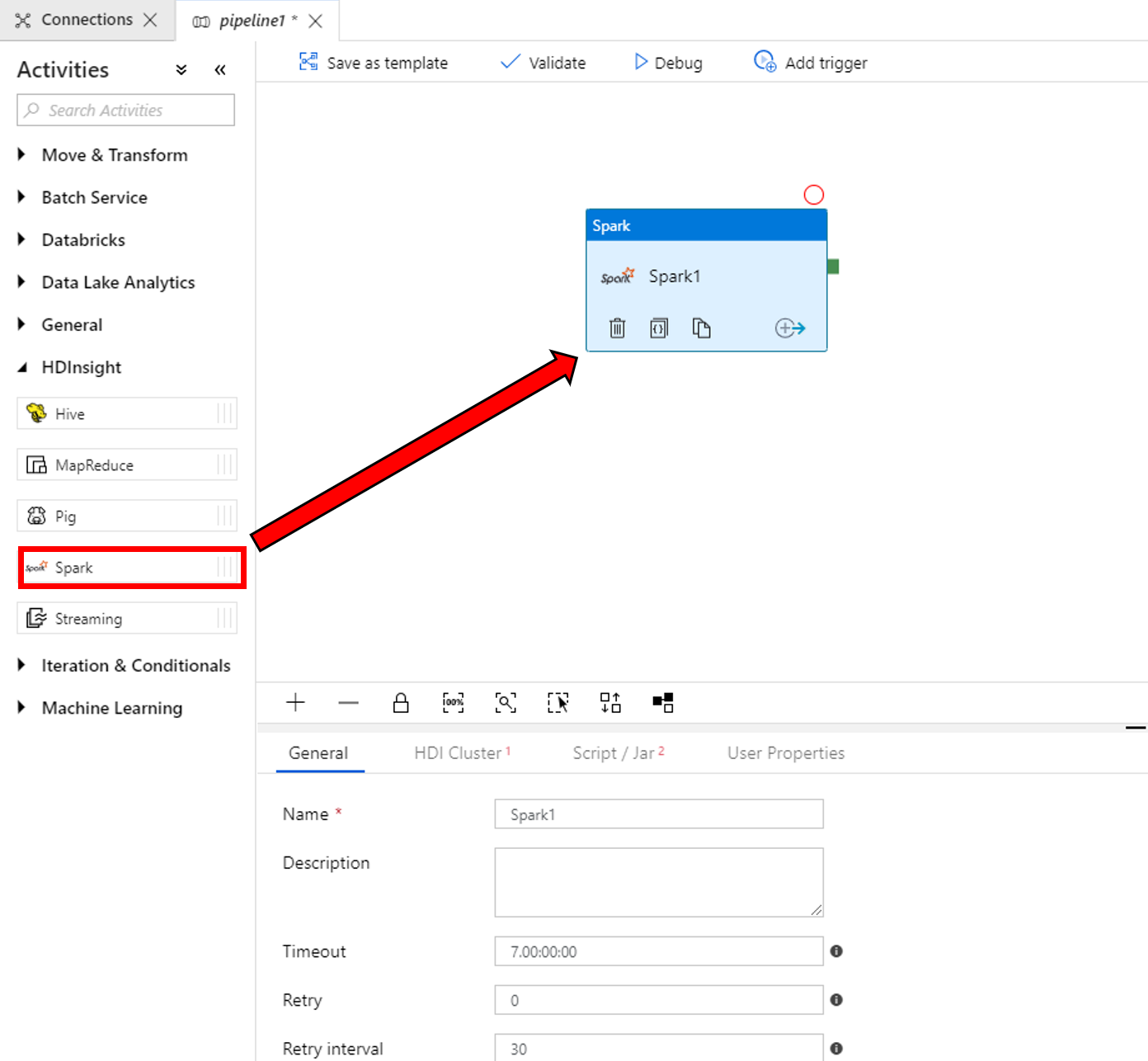
Führen Sie in den Eigenschaften im unteren Bereich des Fensters für die Spark-Aktivität die folgenden Schritte aus:
a. Wechseln Sie zur Registerkarte HDI Cluster (HDI-Cluster).
b. Wählen Sie den verknüpften Dienst AzureHDInsightLinkedService aus, den Sie im vorherigen Verfahren erstellt haben.
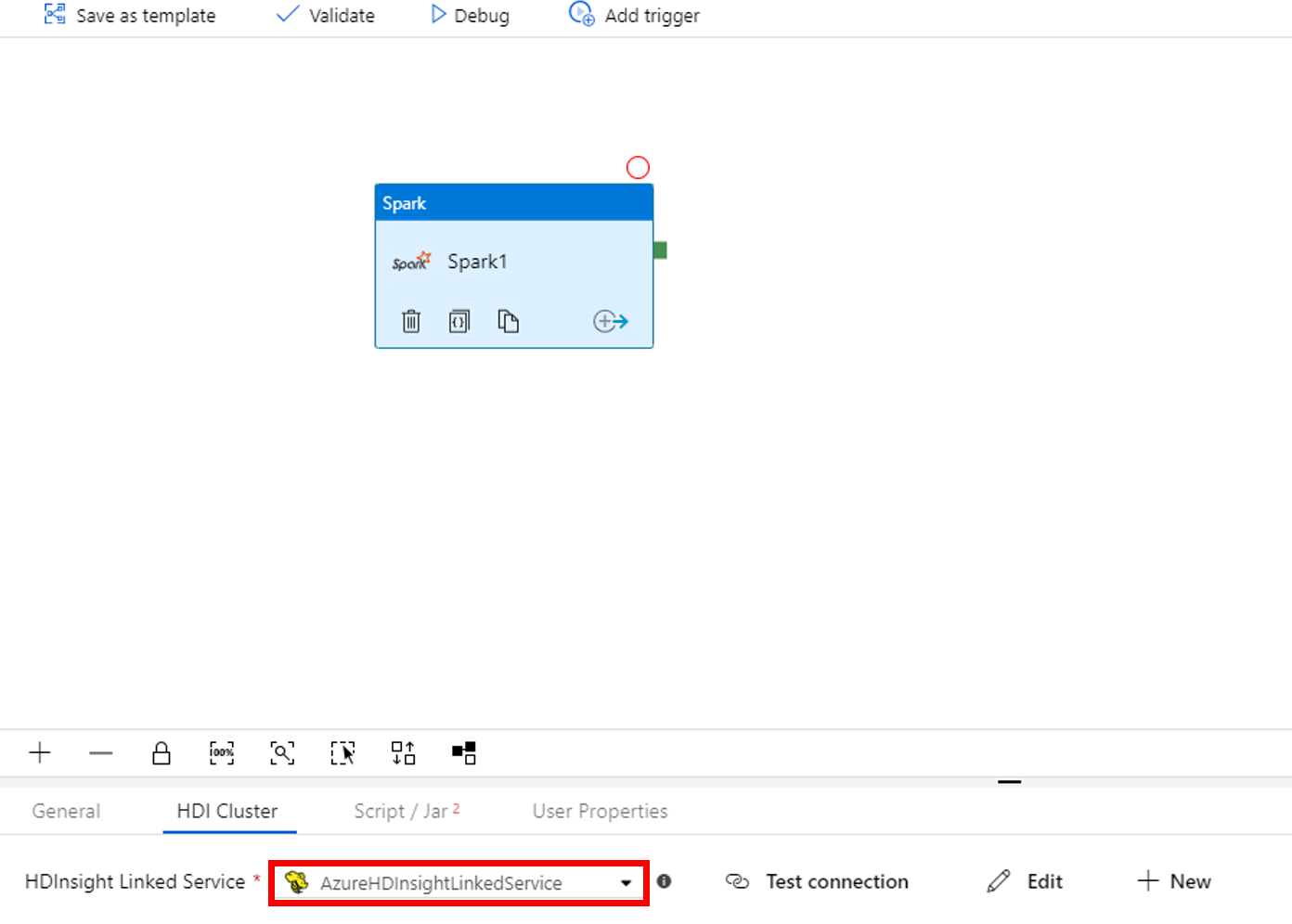
Wechseln Sie zur Registerkarte Script/Jar (Skript/JAR), und führen Sie die folgenden Schritte aus:
a. Wählen Sie unter Mit Auftrag verknüpfter Dienst die Option AzureBlobStorage1 aus.
b. Wählen Sie Speicher durchsuchen.

c. Navigieren Sie zum Ordner adftutorial/spark/script, wählen Sie WordCount_Spark.py aus, und wählen Sie dann die Option Fertig stellen.
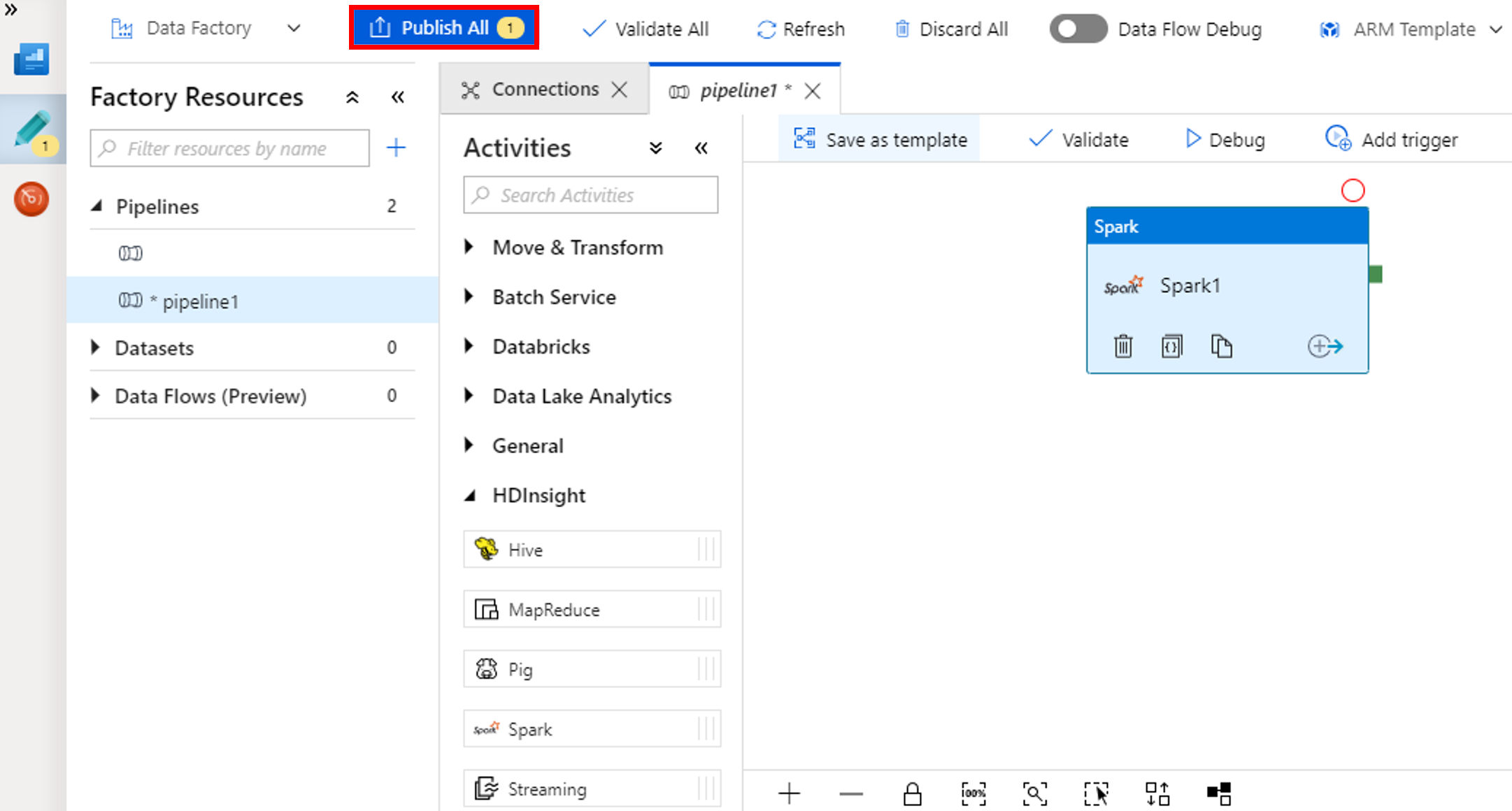
Wählen Sie zum Überprüfen der Pipeline in der Symbolleiste die Schaltfläche Überprüfen. Wählen Sie die Schaltfläche >> (Pfeil nach rechts), um das Überprüfungsfenster zu schließen.
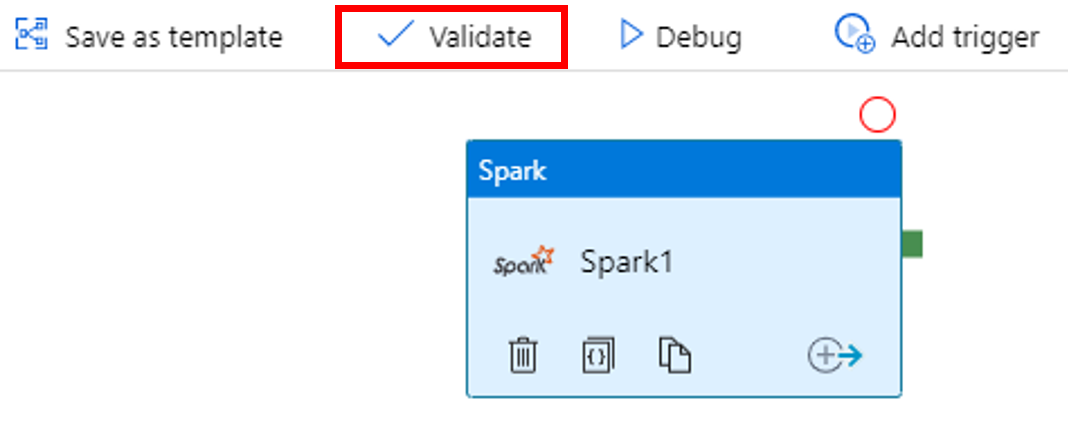
Wählen Sie Alle veröffentlichen. Die Data Factory-Benutzeroberfläche veröffentlicht Entitäten (verknüpfte Dienste und Pipeline) für den Azure Data Factory-Dienst.
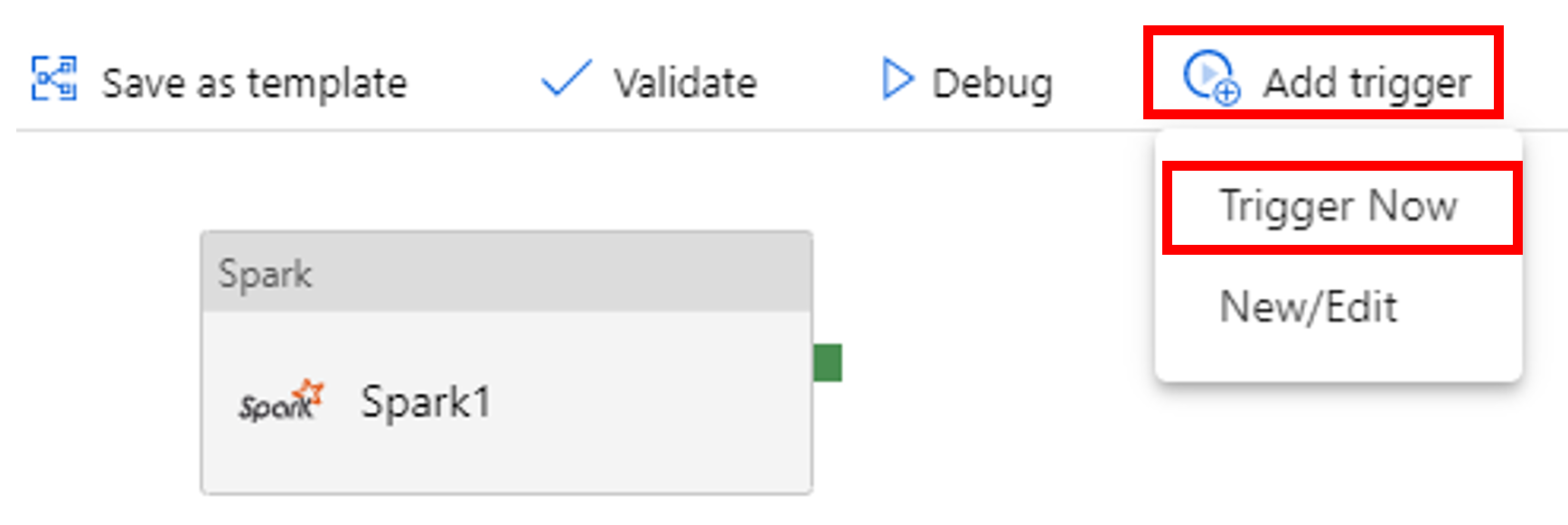
Auslösen einer Pipelineausführung
Wählen Sie in der Symbolleiste die Option Trigger hinzufügen und dann Jetzt auslösen.
Überwachen der Pipelineausführung
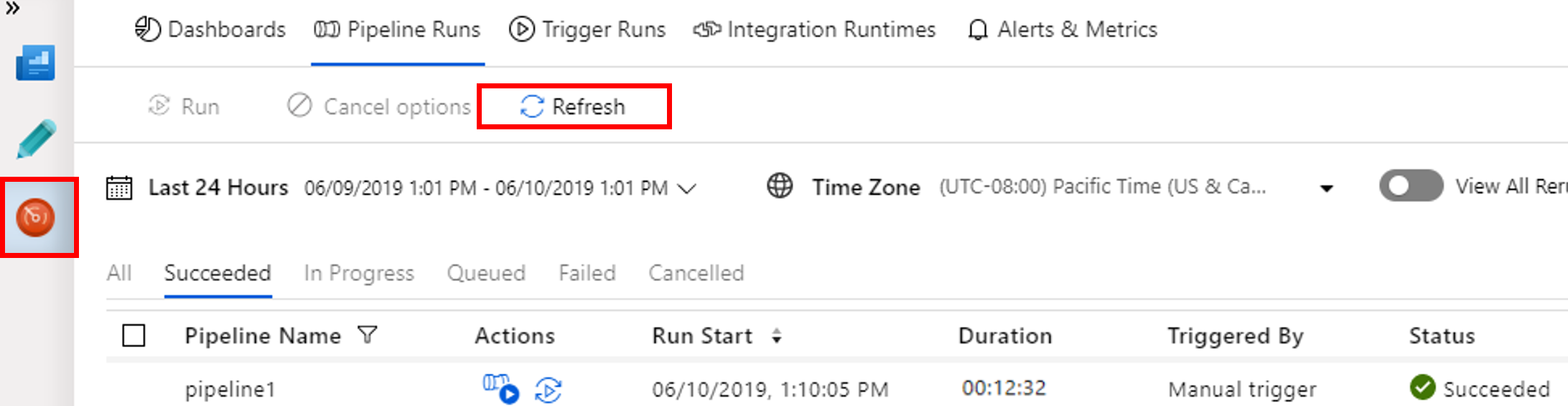
Wechseln Sie zur Registerkarte Überwachen. Vergewissern Sie sich, dass eine Pipelineausführung angezeigt wird. Die Erstellung eines Spark-Clusters dauert etwa 20 Minuten.
Wählen Sie von Zeit zu Zeit die Option Aktualisieren, um den Status der Pipelineausführung zu überprüfen.
Wenn Sie mit der Pipelineausführung verknüpfte Aktivitätsausführungen anzeigen möchten, wählen Sie in der Spalte Aktionen die Optionen View Activity Runs (Aktivitätsausführungen anzeigen).
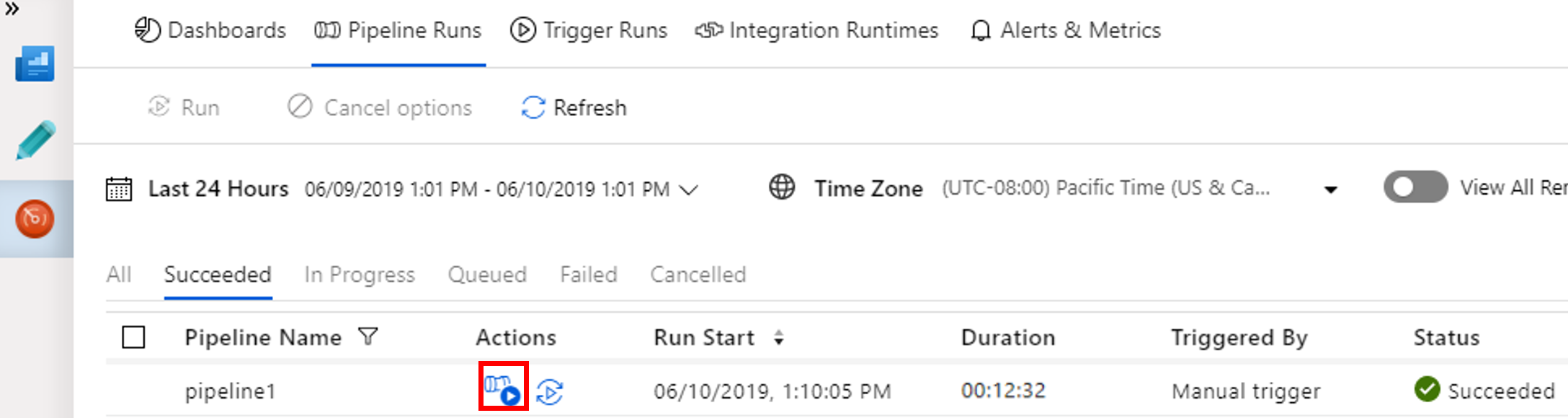
Durch Wählen des Links Alle Pipelineausführungen im oberen Bereich können Sie zur Ansicht mit den Pipelineausführungen zurückkehren.
Überprüfen der Ausgabe
Vergewissern Sie sich, dass die Ausgabedatei im Ordner „spark/outputfiles/wordcount“ des Containers „adftutorial“ erstellt wird.
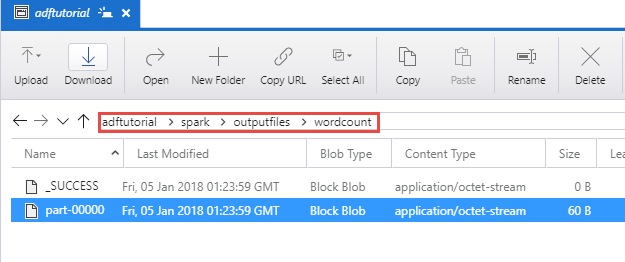
Die Datei sollte für jedes Wort aus der Eingabetextdatei angeben, wie oft es in der Datei vorkommt. Zum Beispiel:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel transformiert Daten mithilfe einer Spark-Aktivität und eines bedarfsgesteuerten verknüpften HDInsight-Diensts. Sie haben Folgendes gelernt:
- Erstellen einer Data Factory.
- Erstellen Sie eine Pipeline, für die eine Spark-Aktivität verwendet wird.
- Auslösen einer Pipelineausführung
- Überwachen der Pipelineausführung.
Fahren Sie mit dem nächsten Tutorial fort, um zu erfahren, wie Sie Daten transformieren, indem Sie ein Hive-Skript in einem Azure HDInsight-Cluster ausführen, der sich in einem virtuellen Netzwerk befindet:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für