Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
In diesem Artikel wird beschrieben, wie Sie aus Google BigQuery-Tabellen in Azure Databricks lesen und schreiben.
Wichtig
Die Legacy-Abfrageverbunddokumentation wurde eingestellt und kann nicht aktualisiert werden. Die in diesem Inhalt genannten Konfigurationen werden nicht offiziell von Databricks unterstützt oder getestet. Wenn Lakehouse Federation Ihre Quelldatenbank unterstützt, empfiehlt Databricks stattdessen die Verwendung.
Sie müssen mithilfe der schlüsselbasierten Authentifizierung eine Verbindung mit BigQuery herstellen.
Erlaubnisse
Ihre Projekte müssen über bestimmte Google-Berechtigungen zum Lesen und Schreiben mit BigQuery verfügen.
Hinweis
In diesem Artikel werden materialisierte Ansichten in BigQuery erläutert. Ausführliche Informationen finden Sie im Google-Artikel "Einführung in materialisierte Ansichten". Weitere BigQuery-Terminologie und das BigQuery-Sicherheitsmodell finden Sie in der Google BigQuery-Dokumentation.
Das Lesen und Schreiben von Daten mit BigQuery hängt von zwei Google Cloud-Projekten ab:
- Projekt (
project): Die ID für das Google Cloud-Projekt, aus dem Azure Databricks die BigQuery-Tabelle liest oder schreibt. - Übergeordnetes Projekt (
parentProject): Die ID für das übergeordnete Projekt, die Google Cloud-Projekt-ID, über die Lese- und Schreibvorgänge abgerechnet werden. Legen Sie dies auf das Google Cloud-Projekt fest, das dem Google-Dienstkonto zugeordnet ist, für das Sie Schlüssel generieren.
Sie müssen die Werte project und parentProject explizit im Code angeben, der auf BigQuery zugreift. Verwenden Sie Code ähnlich wie die folgenden:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Die erforderlichen Berechtigungen für die Google Cloud-Projekte hängen davon ab, ob project und parentProject identisch sind. In den folgenden Abschnitten werden die erforderlichen Berechtigungen für jedes Szenario aufgeführt.
Erforderliche Berechtigungen, wenn project und parentProject übereinstimmen
Wenn die IDs für Ihre project und parentProject die gleichen sind, verwenden Sie die folgende Tabelle, um mindestberechtigungen zu ermitteln:
| Azure Databricks-Aufgabe | Im Projekt erforderliche Google-Berechtigungen |
|---|---|
| Lesen einer BigQuery-Tabelle ohne materialisierte Ansicht | Im project-Projekt:
|
| Lesen einer BigQuery-Tabelle mit materialisierter Sicht | Im project-Projekt:
Im Materialisierungsprojekt:
|
| Schreiben einer BigQuery-Tabelle | Im project-Projekt:
|
Erforderliche Berechtigungen, wenn project und parentProject unterschiedlich sind
Wenn die IDs für project und parentProject unterschiedlich sind, verwenden Sie die folgende Tabelle, um Mindestberechtigungen festzustellen:
| Azure Databricks-Aufgabe | Google-Berechtigungen erforderlich |
|---|---|
| Lesen einer BigQuery-Tabelle ohne materialisierte Ansicht | Im parentProject-Projekt:
Im project-Projekt:
|
| Lesen einer BigQuery-Tabelle mit materialisierter Sicht | Im parentProject-Projekt:
Im project-Projekt:
Im Materialisierungsprojekt:
|
| Schreiben einer BigQuery-Tabelle | Im parentProject-Projekt:
Im project-Projekt:
|
Schritt 1: Einrichten der Google Cloud
Aktivieren der BigQuery Storage-API
Die BigQuery Storage-API ist standardmäßig in neuen Google Cloud-Projekten aktiviert, in denen BigQuery aktiviert ist. Wenn Sie jedoch über ein vorhandenes Projekt verfügen und die BigQuery Storage-API nicht aktiviert ist, führen Sie die Schritte in diesem Abschnitt aus, um es zu aktivieren.
Sie können die BigQuery Storage-API mithilfe der Google Cloud CLI oder der Google Cloud Console aktivieren.
Aktivieren der BigQuery Storage-API mit Google Cloud CLI
gcloud services enable bigquerystorage.googleapis.com
Aktivieren der BigQuery Storage-API mithilfe der Google Cloud Console
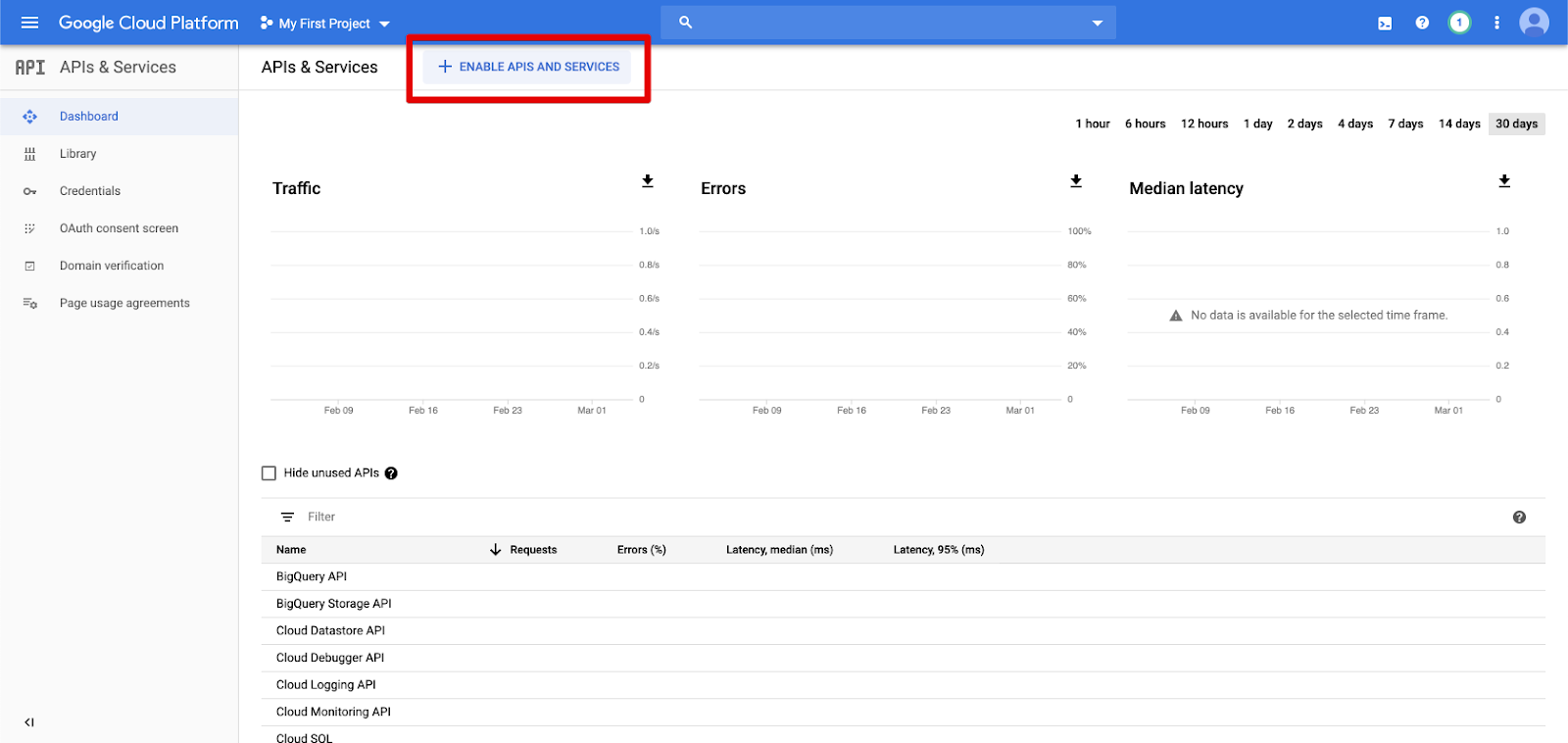
Klicken Sie im linken Navigationsbereich auf APIs & Dienste .
Klicken Sie auf die Schaltfläche "APIS UND DIENSTE AKTIVIEREN ".
Geben Sie
bigquery storage apiin die Suchleiste ein, und wählen Sie das erste Ergebnis aus.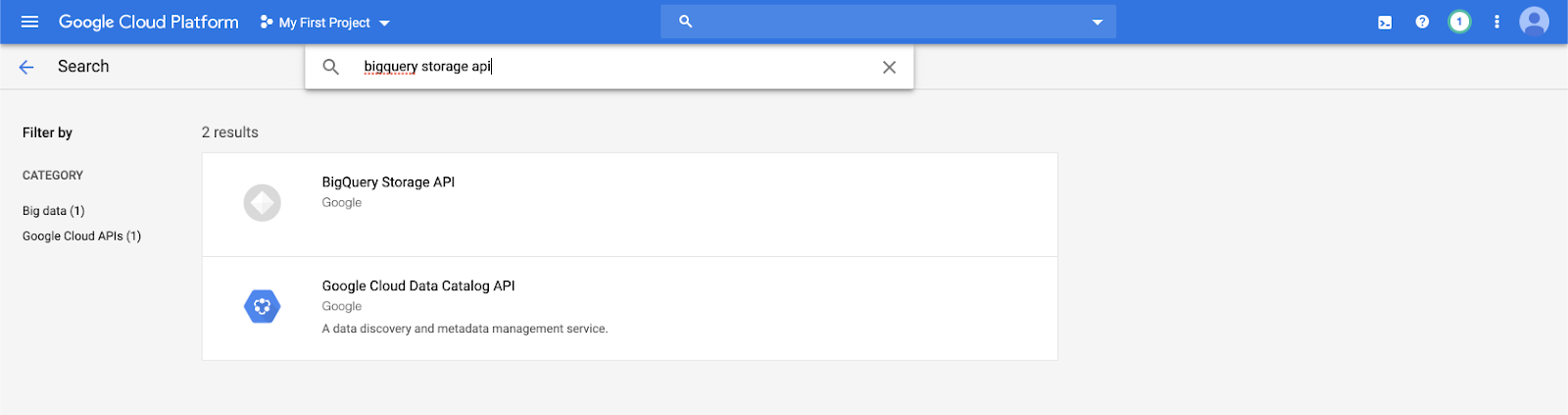
Stellen Sie sicher, dass die BigQuery Storage-API aktiviert ist.
Erstellen eines Google-Dienstkontos für Azure Databricks
Erstellen Sie ein Dienstkonto für den Azure Databricks-Cluster. Databricks empfiehlt, diesem Dienstkonto die geringsten Berechtigungen zu erteilen, die zum Ausführen seiner Aufgaben erforderlich sind. Siehe BigQuery-Rollen und -Berechtigungen.
Sie können ein Dienstkonto über die Google Cloud CLI oder die Google Cloud Console erstellen.
Erstellen eines Google-Dienstkontos mithilfe der Google Cloud CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Erstellen Sie die Schlüssel für Ihr Dienstkonto:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Erstellen eines Google-Dienstkontos mithilfe der Google Cloud Console
So erstellen Sie das Konto:
Klicken Sie im linken Navigationsbereich auf IAM und Admin .
Klicken Sie auf "Dienstkonten".
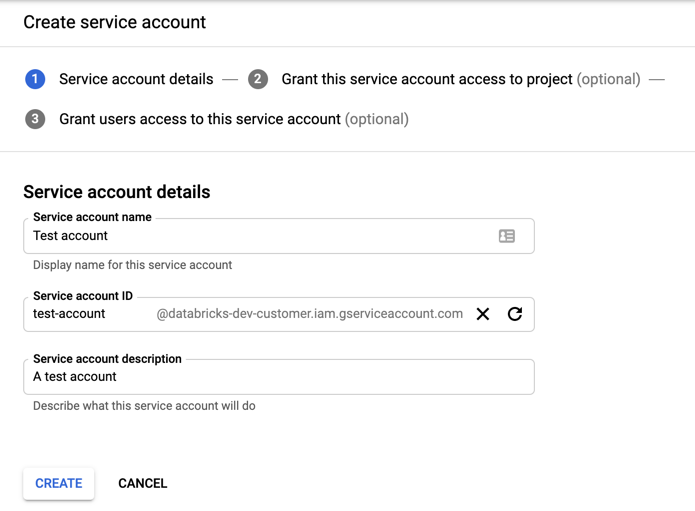
Klicken Sie auf +DIENSTKONTO ERSTELLEN.
Geben Sie den Namen und die Beschreibung des Dienstkontos ein.
Klicken Sie auf ERSTELLEN.
Geben Sie Rollen für Ihr Dienstkonto an. Geben Sie in der Dropdownliste "
BigQuery" ein und fügen Sie die folgenden Rollen hinzu: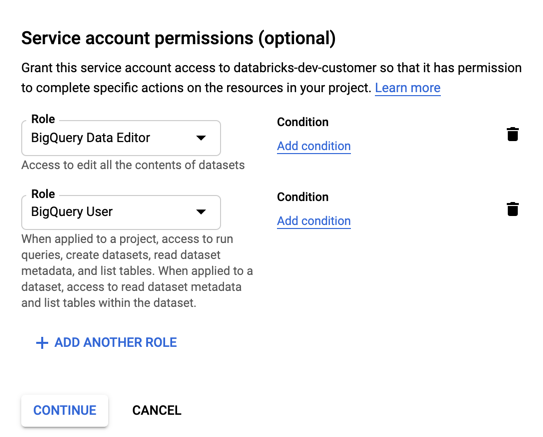
Klicken Sie auf WEITER.
Klicken Sie auf FERTIG.
So erstellen Sie Schlüssel für Ihr Dienstkonto:
Klicken Sie in der Liste der Dienstkonten auf Ihr neu erstelltes Konto.
Wählen Sie im Abschnitt "Schlüssel" die Schaltfläche " NEUEN > SCHLÜSSEL erstellen " aus.
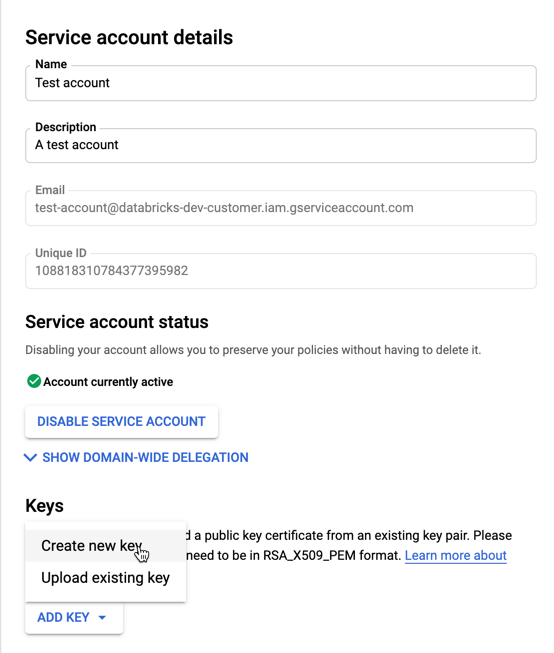
Akzeptieren Sie den JSON-Schlüsseltyp .
Klicken Sie auf ERSTELLEN. Die JSON-Schlüsseldatei wird auf Ihren Computer heruntergeladen.
Wichtig
Die JSON-Schlüsseldatei, die Sie für das Dienstkonto generieren, ist ein privater Schlüssel, der nur für autorisierte Benutzer freigegeben werden sollte, da sie den Zugriff auf Datasets und Ressourcen in Ihrem Google Cloud-Konto steuert.
Erstellen eines Google Cloud Storage (GCS)-Buckets für temporären Speicher
Zum Schreiben von Daten in BigQuery benötigt die Datenquelle Zugriff auf einen GCS-Bucket.
Klicken Sie im linken Navigationsbereich auf " Speicher ".
Klicken Sie auf Bucket erstellen.
Konfigurieren Sie die Bucketdetails.
Klicken Sie auf ERSTELLEN.
Klicken Sie auf die Registerkarte "Berechtigungen ", und fügen Sie Mitglieder hinzu.
Geben Sie die folgenden Berechtigungen für das Dienstkonto im Bucket an.
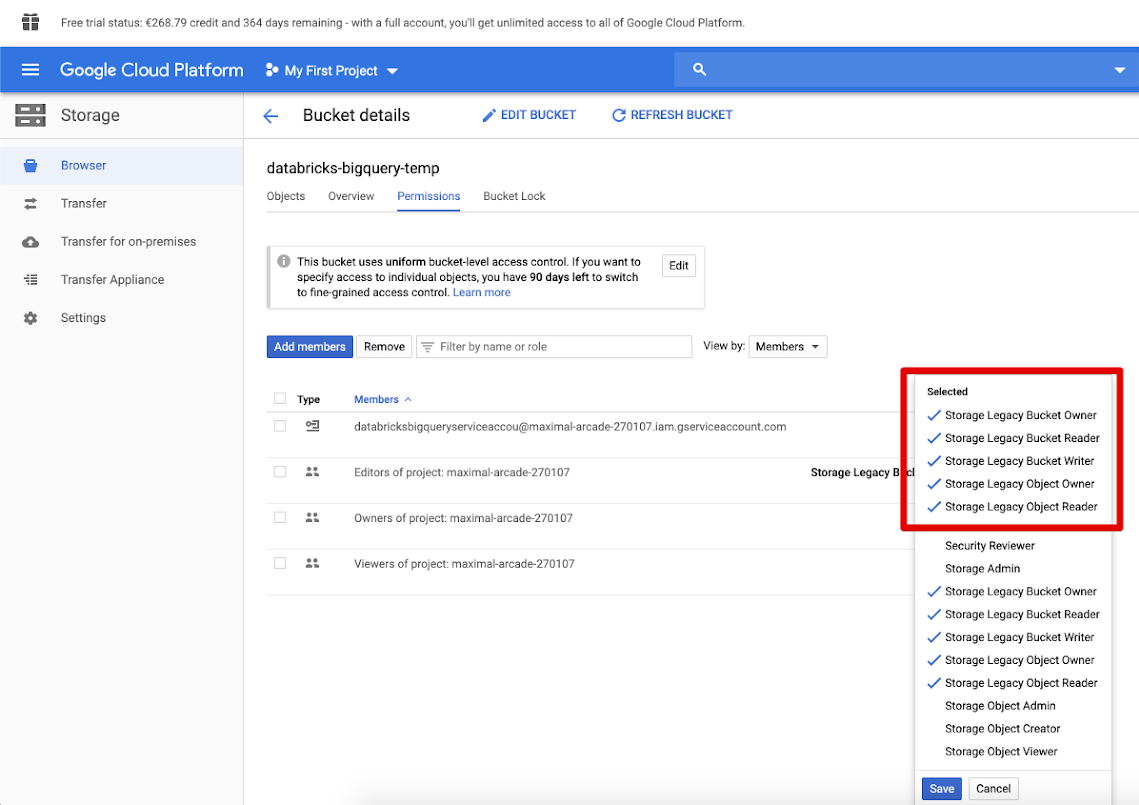
Klicken Sie auf SPEICHERN.
Schritt 2: Einrichten von Azure Databricks
Um einen Cluster für den Zugriff auf BigQuery-Tabellen zu konfigurieren, müssen Sie Ihre JSON-Schlüsseldatei als Spark-Konfiguration bereitstellen. Verwenden Sie ein lokales Tool zum Base64-Codieren Ihrer JSON-Schlüsseldatei. Für Sicherheitszwecke wird kein webbasiertes oder Remotetool verwendet, das auf Ihre Schlüssel zugreifen kann.
Wenn Sie Ihren Cluster konfigurieren:
Fügen Sie auf der Registerkarte "Spark Config" die folgende Spark-Konfiguration hinzu. Ersetzen Sie sie <base64-keys> durch die Zeichenfolge Ihrer Base64-codierten JSON-Schlüsseldatei. Ersetzen Sie die anderen Elemente in eckigen Klammern (z. B. <client-email>) mit den Werten aus diesen Feldern aus der JSON-Schlüsseldatei.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Lesen und Schreiben in eine BigQuery-Tabelle
Zum Lesen einer BigQuery-Tabelle geben Sie an
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Um in eine BigQuery-Tabelle zu schreiben, geben Sie an
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
Dabei handelt es sich um den Namen des Buckets, den Sie unter <bucket-name> erstellt haben. Informationen zu Anforderungen und <project-id> Werten finden Sie unter <parent-id>".
Erstellen einer externen Tabelle aus BigQuery
Wichtig
Dieses Feature wird vom Unity-Katalog nicht unterstützt.
Sie können eine nicht verwaltete Tabelle in Databricks deklarieren, die Daten direkt aus BigQuery liest:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Python-Notizbuchbeispiel: Laden einer Google BigQuery-Tabelle in einen DataFrame
Das folgende Python-Notizbuch lädt eine Google BigQuery-Tabelle in ein Azure Databricks DataFrame.
Google BigQuery Python-Beispielnotizbuch
Scala-Notizbuchbeispiel: Laden einer Google BigQuery-Tabelle in einen DataFrame
Das folgende Scala-Notizbuch lädt eine Google BigQuery-Tabelle in einen Azure Databricks DataFrame.