Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Diese Seite zeigt die am häufigsten verwendeten Authentifizierungsmethoden für den Kafka-Connector auf Azure Databricks.
Die vollständige Liste der unterstützten Authentifizierungsmethoden finden Sie in der Kafka-Dokumentation.
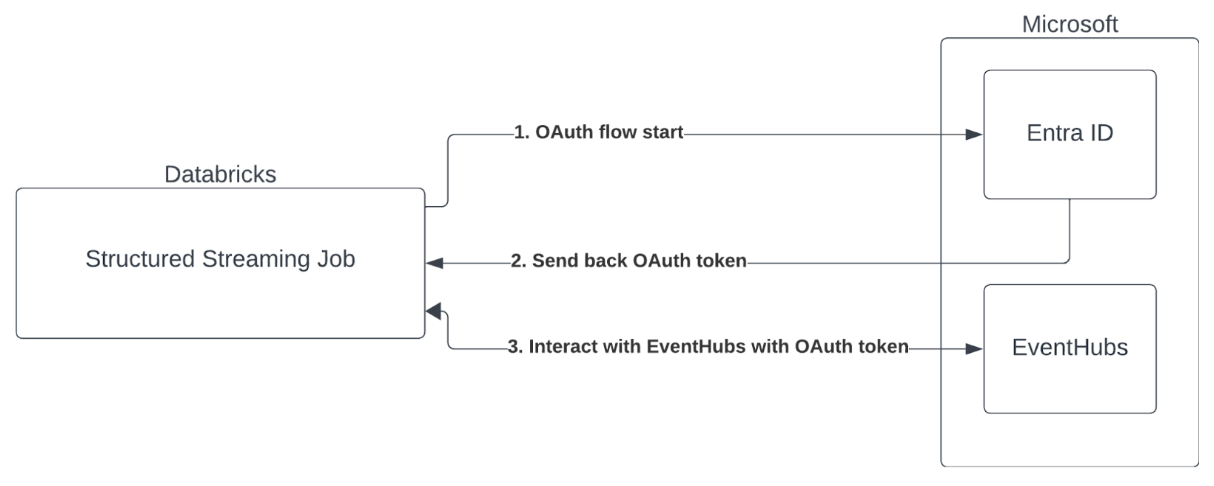
Verbindung zu Azure Event Hubs mit einem Dienstprinzipal herstellen
Azure Databricks unterstützt die Authentifizierung von Spark-Aufträgen mit Event Hubs-Diensten mit OAuth mit Microsoft Entra ID.
Verbinden mit Unity Catalog-Dienstanmeldeinformationen
In Databricks Runtime 16.1 und höher unterstützt Azure Databricks Unity Catalog-Dienstanmeldeinformationen für die Authentifizierung für Azure Event Hubs. Databricks empfiehlt diesen Ansatz, wenn Sie Kafka-Streaming auf gemeinsam genutzten Clustern oder serverlosen Berechnungen ausführen.
Gehen Sie wie folgt vor, um anmeldeinformationen für den Unity-Katalogdienst für die Authentifizierung zu verwenden:
- Erstellen Sie ein neues Unity-Katalogdienst-Anmeldeinformation. Siehe Erstellen von Dienstanmeldeinformationen.
- Vergewissern Sie sich, dass der an Ihre Dienstanmeldeinformationen angefügte Zugriffsconnector über die richtigen Berechtigungen zum Herstellen einer Verbindung mit Azure Event Hubs verfügt.
- Legen Sie die Quelloption
databricks.serviceCredentialauf den Namen Ihrer Dienstanmeldeinformationen fest.
Im folgenden Beispiel wird Kafka als Quelle unter Verwendung von Service-Anmeldeinformationen konfiguriert.
Python
kafka_options = {
"kafka.bootstrap.servers": "<bootstrap-hostname>:9092",
"subscribe": "<topic>",
"databricks.serviceCredential": "<service-credential-name>",
# Optional: set this only if Databricks can't infer the scope for your Kafka service.
# "databricks.serviceCredential.scope": "https://<event-hubs-server>/.default",
}
df = spark.readStream.format("kafka").options(**kafka_options).load()
Scala
val kafkaOptions = Map(
"kafka.bootstrap.servers" -> "<bootstrap-hostname>:9092",
"subscribe" -> "<topic>",
"databricks.serviceCredential" -> "<service-credential-name>",
// Optional: set this only if Databricks can't infer the scope for your Kafka service.
// "databricks.serviceCredential.scope" -> "https://<event-hubs-server>/.default",
)
val df = spark.readStream.format("kafka").options(kafkaOptions).load()
SQL
SELECT * FROM read_kafka(
bootstrapServers => '<bootstrap-hostname>:9092',
subscribe => '<topic>',
serviceCredential => '<service-credential-name>'
);
Hinweis
Wenn Sie eine Unity Catalog-Dienstanmeldeinformationen zum Herstellen einer Verbindung mit Kafka verwenden, verwenden Sie nicht die folgenden Optionen:
kafka.sasl.mechanismkafka.sasl.jaas.configkafka.security.protocolkafka.sasl.client.callback.handler.classkafka.sasl.oauthbearer.token.endpoint.url
Verbinden mit einer Client-ID und einem Secret
Azure Databricks unterstützt die Microsoft Entra ID Authentifizierung mit einer Client-ID und einem geheimen Schlüssel in den folgenden Computeumgebungen:
- Databricks Runtime 12.2 LTS und höher für Compute, die für den dedizierten Zugriffsmodus konfiguriert sind.
- Databricks Runtime 14.3 LTS und höher für Compute-Ressourcen, die mit dem Standardzugriffsmodus konfiguriert sind.
- Lakeflow Spark Declarative Pipelines ohne Unity-Katalog konfiguriert.
Azure Databricks unterstützt keine Microsoft Entra ID-Authentifizierung mit einem Zertifikat in einer Berechnungsumgebung oder in Lakeflow Spark Deklarative Pipelines, die mit Unity Catalog konfiguriert sind.
Diese Authentifizierung funktioniert nicht bei der Berechnung mit Standardzugriffsmodus oder in Unity Catalog Lakeflow Spark Declarative Pipelines.
Um die Authentifizierung mit Microsoft Entra ID durchzuführen, müssen Sie die folgenden Werte haben:
Eine Mandanten-ID. Dies finden Sie auf der Registerkarte Microsoft Entra ID Services.
Eine Client-ID, auch bekannt als Anwendungs-ID.
Einen geheimen Clientschlüssel. Fügen Sie dies Ihrem Databricks-Arbeitsbereich als Geheimnis hinzu. Siehe Verwaltung von Geheimnissen.
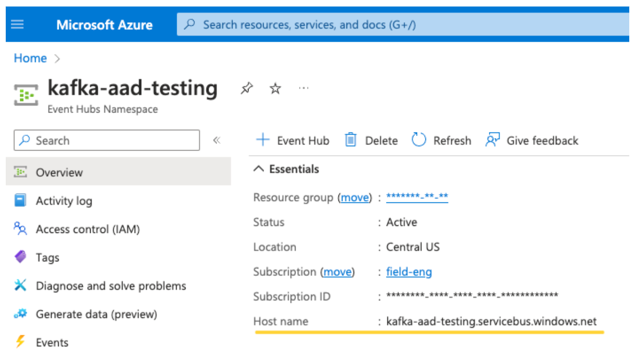
Ein EventHubs-Thema. Eine Liste der Themen finden Sie im Abschnitt Event Hubs unter dem Abschnitt Entitäten auf einer bestimmten Seite des Event Hubs-Namespace. Um mit mehreren Themen zu arbeiten, können Sie die IAM-Rolle auf Event Hubs-Ebene festlegen.
Einen EventHubs-Server. Diesen finden Sie auf der Übersichtsseite Ihres bestimmten Event Hubs-Namespace:
Um Entra ID zu verwenden, müssen Sie Kafka so konfigurieren, dass die OAuth SASL verwendet wird:
- Legen Sie
kafka.security.protocolaufSASL_SSLfest. - Legen Sie
kafka.sasl.mechanismaufOAUTHBEARERfest. - Legen Sie
kafka.sasl.login.callback.handler.classauf einen vollqualifizierten Namen der Java Klasse fest. Der qualifizierte Name istkafkashadedund der Login-Callback-Handler der Databricks-shaded-Kafka-Klasse. Das folgende Beispiel zeigt die genaue Klasse.
SASL ist ein generisches Authentifizierungsprotokoll, und OAuth ist ein SASL-Mechanismus.
Im folgenden Beispiel wird Kafka so konfiguriert, dass eine Verbindung mit Azure Event Hubs mithilfe Microsoft Entra ID Authentifizierung mit einer Client-ID und einem geheimen Schlüssel hergestellt wird:
Python
# This is the only section you need to modify for auth purposes
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
"kafka.bootstrap.servers": f"{event_hubs_server}:9093", # Port 9093 is the EventHubs Kafka port
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
Scala
// This is the only section you need to modify for auth purposes
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093", // Port 9093 is the EventHubs Kafka port
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
SQL
CREATE OR REFRESH STREAMING TABLE <table_name>
AS
SELECT * FROM STREAM read_kafka(
bootstrapServers => '<event-hubs-server>:9093',
subscribe => '<event-hubs-topic>',
`kafka.security.protocol` => 'SASL_SSL',
`kafka.sasl.mechanism` => 'OAUTHBEARER',
`kafka.sasl.jaas.config` => 'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="<client-id>" clientSecret="<client-secret>" scope="https://<event-hubs-server>/.default" ssl.protocol="SSL";',
`kafka.sasl.oauthbearer.token.endpoint.url` => 'https://login.microsoft.com/<tenant-id>/oauth2/v2.0/token',
`kafka.sasl.login.callback.handler.class` => 'kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler'
);
Verwenden von SASL/PLAIN zur Authentifizierung
Um eine Verbindung mit Kafka mithilfe der SASL/PLAIN-Authentifizierung (Benutzername und Kennwort) herzustellen, konfigurieren Sie die folgenden Optionen. Verwenden Sie den Namen der schattierten PlainLoginModule Klasse:
Python
kafka_options = {
"kafka.bootstrap.servers": "<bootstrap-server>:9093",
"subscribe": "<topic>",
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config":
'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="<username>" password="<password>";',
}
df = spark.readStream.format("kafka").options(**kafka_options).load()
Scala
val kafkaOptions = Map(
"kafka.bootstrap.servers" -> "<bootstrap-server>:9093",
"subscribe" -> "<topic>",
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "PLAIN",
"kafka.sasl.jaas.config" ->
"""kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="<username>" password="<password>";""",
)
val df = spark.readStream.format("kafka").options(kafkaOptions).load()
SQL
SELECT * FROM STREAM read_kafka(
bootstrapServers => '<bootstrap-server>:9093',
subscribe => '<topic>',
`kafka.security.protocol` => 'SASL_SSL',
`kafka.sasl.mechanism` => 'PLAIN',
`kafka.sasl.jaas.config` => 'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="<username>" password="<password>";'
);
Azure Databricks empfiehlt, Ihr Kennwort nicht direkt in Ihren Code einzugeben, sondern als geheimer Schlüssel zu speichern. Weitere Informationen finden Sie unter "Geheime Verwaltung".
Verwenden von SASL/SCRAM zur Authentifizierung
Um eine Verbindung mit Kafka mithilfe von SASL/SCRAM (SCRAM-SHA-256 oder SCRAM-SHA-512) herzustellen, konfigurieren Sie die folgenden Optionen. Verwenden Sie den Namen der schattierten ScramLoginModule Klasse:
Python
kafka_options = {
"kafka.bootstrap.servers": "<bootstrap-server>:9093",
"subscribe": "<topic>",
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "SCRAM-SHA-512",
"kafka.sasl.jaas.config":
'kafkashaded.org.apache.kafka.common.security.scram.ScramLoginModule required username="<username>" password="<password>";',
}
df = spark.readStream.format("kafka").options(**kafka_options).load()
Scala
val kafkaOptions = Map(
"kafka.bootstrap.servers" -> "<bootstrap-server>:9093",
"subscribe" -> "<topic>",
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "SCRAM-SHA-512",
"kafka.sasl.jaas.config" ->
"""kafkashaded.org.apache.kafka.common.security.scram.ScramLoginModule required username="<username>" password="<password>";""",
)
val df = spark.readStream.format("kafka").options(kafkaOptions).load()
SQL
SELECT * FROM STREAM read_kafka(
bootstrapServers => '<bootstrap-server>:9093',
subscribe => '<topic>',
`kafka.security.protocol` => 'SASL_SSL',
`kafka.sasl.mechanism` => 'SCRAM-SHA-512',
`kafka.sasl.jaas.config` => 'kafkashaded.org.apache.kafka.common.security.scram.ScramLoginModule required username="<username>" password="<password>";'
);
Hinweis
Ersetzen Sie SCRAM-SHA-512 durch SCRAM-SHA-256, wenn Ihr Kafka-Cluster für die Verwendung von SCRAM-SHA-256 konfiguriert ist.
Azure Databricks empfiehlt, Ihr Kennwort nicht direkt in Ihren Code einzugeben, sondern als geheimer Schlüssel zu speichern. Weitere Informationen finden Sie unter "Geheime Verwaltung".
Verwenden Sie SSL, um Azure Databricks mit Kafka zu verbinden.
Um SSL/TLS-Verbindungen zu Kafka zu ermöglichen, setzen Sie kafka.security.protocol auf SSL und geben Sie die Konfigurationsoptionen für den Vertrauensspeicher und den Schlüsselspeicher mit dem Präfix kafka. an. Für SSL-Verbindungen, die nur serverbasierte Authentifizierung (unidirektionales TLS) erfordern, müssen Sie einen Vertrauensspeicher verwenden. Bei gegenseitigem TLS (mTLS), bei dem der Kafka-Broker auch den Client authentifiziert, müssen Sie sowohl einen Vertrauensspeicher als auch einen Schlüsselspeicher verwenden.
Die folgenden SSL/TLS-Optionen sind verfügbar. Die vollständige Liste der SSL-Eigenschaften finden Sie in der Dokumentation zur Apache Kafka SSL-Konfiguration und Verschlüsselung und Authentifizierung mit SSL in der Confluent-Dokumentation.
| Auswahl | Beschreibung |
|---|---|
kafka.security.protocol |
Legen Sie diesen Wert fest, SSL um die TLS-Verschlüsselung zu aktivieren. |
kafka.ssl.truststore.location |
Pfad zur Truststore-Datei, die vertrauenswürdige CA-Zertifikate enthält. |
kafka.ssl.truststore.password |
Kennwort für die Vertrauensspeicherdatei. |
kafka.ssl.truststore.type |
Dateiformat des Vertrauensspeichers (Standard: JKS). |
kafka.ssl.keystore.location |
Pfad zur Schlüsselspeicherdatei, die das Clientzertifikat und den privaten Schlüssel enthält (erforderlich für mTLS). |
kafka.ssl.keystore.password |
Kennwort für die Schlüsselspeicherdatei. |
kafka.ssl.key.password |
Kennwort für den privaten Schlüssel im Schlüsselspeicher. |
kafka.ssl.endpoint.identification.algorithm |
Hostnamenüberprüfungsalgorithmus. Wird standardmäßig auf https festgelegt. Legen Sie diese auf eine leere Zeichenfolge fest, wenn Sie sie deaktivieren wollen. |
Wenn Sie SSL verwenden, empfiehlt Databricks Folgendes:
- Speichern Sie Ihre Zertifikate in einem Unity-Katalogvolume. Benutzer, die Zugriff auf Leseberechtigungen des Volumens haben, können Ihre Kafka-Zertifikate verwenden. Weitere Informationen finden Sie unter Was sind Unity Catalog-Volumes?.
- Speichern Sie Ihre Zertifikat-Kennwörter als geheime Schlüssel in einem geheimen Bereich. Weitere Informationen finden Sie unter Verwalten geheimer Bereiche.
Im folgenden Beispiel werden Objektspeicherorte und Databricks-Geheimnisse verwendet, um eine SSL-Verbindung zu aktivieren:
Python
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<bootstrap-server>:9093")
.option("kafka.security.protocol", "SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Scala
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<bootstrap-server>:9093")
.option("kafka.security.protocol", "SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope = <certificate-scope-name>, key = <keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope = <certificate-scope-name>, key = <truststore-password-key-name>))
SQL
SELECT * FROM read_kafka(
bootstrapServers => '<bootstrap-server>:9093',
subscribe => '<topic>',
`kafka.security.protocol` => 'SSL',
`kafka.ssl.truststore.location` => '<truststore-location>',
`kafka.ssl.keystore.location` => '<keystore-location>',
`kafka.ssl.keystore.password` => secret('<certificate-scope-name>', '<keystore-password-key-name>'),
`kafka.ssl.truststore.password` => secret('<certificate-scope-name>', '<truststore-password-key-name>')
);
Kafka in HDInsight mit Azure Databricks verbinden
Erstellen Sie einen Kafka-Cluster in HDInsight.
Anweisungen finden Sie unter Connect to Kafka on HDInsight through an Azure Virtual Network.
Konfigurieren Sie die Kafka-Broker so, dass sie die richtige Adresse ankündigen.
Befolgen Sie die Anweisungen unter Konfigurieren von Kafka zum Ankündigen der IP-Adresse. Wenn Sie Kafka selbst auf Azure Virtual Machines verwalten, stellen Sie sicher, dass die konfiguration
advertised.listenersder Broker auf die interne IP der Hosts festgelegt ist.Erstellen Sie einen Azure Databricks Cluster.
Verknüpfen Sie das Kafka-Cluster mit dem Azure Databricks-Cluster.
Befolgen Sie die Anweisungen unter Einrichten eines Peerings von virtuellen Netzwerken.
Verwenden Sie die von Databricks bereitgestellten Kafka-Klassennamen
Azure Databricks bündeln proprietäre, schattierte Versionen der Kafka-Clientbibliotheken. Alle Kafka-Clientklassennamen, auf die Sie in Authentifizierungskonfigurationsoptionen verweisen, müssen anstelle des Standardmäßigen Open-Source-Klassennamens das Präfix der schattierten Klasse verwenden. Dies gilt für alle Klassen, auf die in Optionen wie kafka.sasl.jaas.config, kafka.sasl.login.callback.handler.class und kafka.sasl.client.callback.handler.class verwiesen wird.
Wenn Sie nicht abgeschattete Klassennamen verwenden, löst Ihr Code einen RESTRICTED_STREAMING_OPTION_PERMISSION_ENFORCED Fehler aus. Weitere Informationen finden Sie in den häufig gestellten Fragen .
Behandeln potenzieller Fehler
Fehler beim Erstellen eines neuen
KafkaAdminClientDieser interne Kafka-Fehler wird ausgelöst, wenn eine der folgenden Authentifizierungsoptionen falsch ist:
- Client-ID (auch als Anwendungs-ID bezeichnet)
- Mieter-ID
- Event Hubs-Server
Um den Fehler zu beheben, überprüfen Sie, ob die Werte für diese Optionen korrekt sind. Darüber hinaus wird dieser Fehler möglicherweise angezeigt, wenn Sie die im Beispiel standardmäßig bereitgestellten Konfigurationsoptionen (wie zum Beispiel
kafka.security.protocol) ändern.Keine Datensätze zurückgegeben
Wenn Sie versuchen, Ihren DataFrame anzuzeigen oder zu verarbeiten, aber keine Ergebnisse erhalten, sehen Sie folgendes in der Benutzeroberfläche.
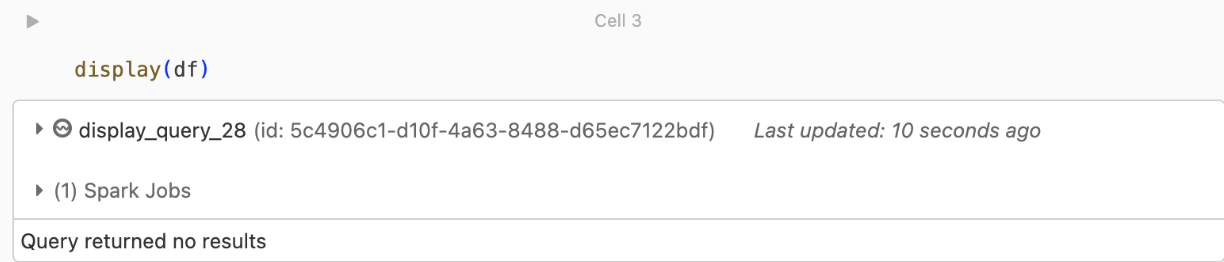
Diese Meldung bedeutet, dass die Authentifizierung erfolgreich war, aber EventHubs hat keine Daten zurückgegeben. Einige mögliche (aber keineswegs vollständige) Gründe sind:
- Sie haben das falsche EventHubs-Thema angegeben.
- Die Standard-Kafka-Konfigurationsoption für „
startingOffsets“ ist „latest“, und Sie erhalten derzeit noch keine Daten über das Thema. Sie können „startingOffsets“ auf „earliest“ setzen, um mit dem Lesen von Daten ab den frühesten Offsets von Kafka zu beginnen.