Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält Empfehlungen und Ressourcen zum Konfigurieren von Compute für Lakeflow-Aufträge.
Wichtig
Einschränkungen für das serverlose Computing von Aufträgen umfassen Folgendes:
- Keine Unterstützung für kontinuierliche Planung.
- Keine Unterstützung für Standard- oder zeitbasierte Intervalltrigger im strukturierten Streaming.
Weitere Einschränkungen finden Sie unter Beschränkungen von serverlosem Computing.
Jeder Auftrag kann eine oder mehrere Aufgaben enthalten. Sie definieren Computing-Ressourcen für jede Aufgabe. Mehrere Aufgaben, die für denselben Auftrag definiert sind, können dieselbe Computing-Ressource verwenden.
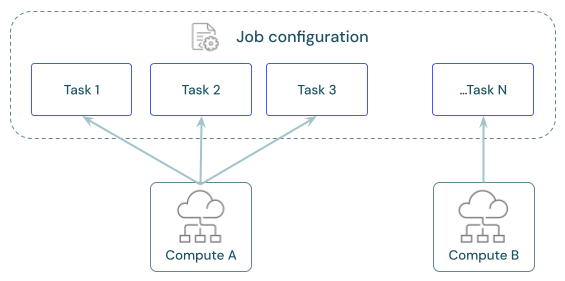
Was ist die empfohlene Berechnung für jede Aufgabe?
In der folgenden Tabelle sind die empfohlenen und unterstützten Computing-Typen für jeden Aufgabentyp aufgeführt.
Hinweis
Serverloses Computing für Aufträge unterliegt Einschränkungen und unterstützt nicht alle Workloads. Siehe Beschränkungen von serverlosem Computing.
| Aufgabe | Empfohlene Rechenleistung | Unterstützte Rechenleistung |
|---|---|---|
| Notizbücher | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| Python-Skript | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| Python Wheel | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| SQL | Serverloses SQL-Warehouse | Serverloses SQL-Datenlager, Pro-SQL-Datenlager |
| Lakeflow Spark-Deklarative Pipelines | Serverlose Pipeline | Serverlose Pipeline, klassische Pipeline |
| dbt | Serverloses SQL-Warehouse | Serverloses SQL-Warehouse, Pro-SQL-Warehouse |
| dbt CLI-Befehle | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| KRUG | Klassische Aufträge | Klassische Aufträge, klassische Allzweckaufträge |
| Spark Submit | Klassische Aufträge | Klassische Aufträge |
Die Preise für Lakeflow-Aufträge sind an die Berechnung gebunden, die zum Ausführen von Aufgaben verwendet wird. Weitere Informationen finden Sie unter Databricks Preise.
Wie konfiguriere ich Compute für Aufträge?
Klassische Jobs werden direkt über die Lakeflow-Jobs-Benutzeroberfläche konfiguriert, und diese Konfigurationen sind Teil der Job-Definition. Alle anderen verfügbaren Compute-Typen speichern ihre Konfigurationen in anderen Arbeitsbereichsressourcen. Weitere Informationen hierzu finden Sie in der folgenden Tabelle:
| Computetyp | Einzelheiten |
|---|---|
| Klassisches Jobs Compute | Sie konfigurieren das Computing für klassische Aufträge mit der gleichen Benutzeroberfläche und den gleichen Einstellungen wie für die universelle Rechenleistung. Siehe Computekonfigurationsreferenz. |
| Serverloses Computing für Aufträge | Serverloses Computing für Aufgaben ist die Standardeinstellung für alle Aufgaben, die dies unterstützen. Databricks verwaltet Computing-Einstellungen für das serverlose Computing. Siehe Ausführen von Lakeflow-Aufträgen mit serverloser Berechnung für Workflows. |
| SQL-Warenhäuser | Serverlose und pro SQL-Lagerorte werden von Arbeitsbereich-Administratoren oder Benutzern mit uneingeschränkten Berechtigungen zur Cluster-Erstellung konfiguriert. Sie konfigurieren Aufgaben, um sie in bestehenden SQL-Warenhäusern auszuführen. Siehe Herstellen einer Verbindung mit einem SQL-Warehouse. |
| Lakeflow Spark Deklarative Pipelines berechnen | Sie konfigurieren die Computeeinstellungen für Lakeflow Spark Declarative Pipelines während der Pipelinekonfiguration. Siehe Konfigurieren der klassischen Berechnung für Pipelines. Azure Databricks verwaltet Computeressourcen für serverlose Lakeflow Spark Declarative Pipelines. Siehe Konfigurieren einer serverlosen Pipeline. |
| Allzweckrechnen | Sie können Aufgaben optional mithilfe von klassischem All-Purpose Compute konfigurieren. Databricks empfiehlt diese Konfiguration nicht für Produktionsaufträge. Siehe Computekonfigurationsreferenz und Sollte All-Purpose Compute jemals für Aufträge verwendet werden?. |
Freigeben von Rechenressourcen über Aufgaben hinweg
Konfigurieren Sie Tasks so, dass sie dieselben Job-Rechenressourcen verwenden, um die Ressourcennutzung mit Jobs zu optimieren, die mehrere Tasks orchestrieren. Die Freigabe von Rechenleistung über Aufgaben hinweg kann die Latenz, die mit den Startzeiten der Aufgaben verbunden ist, reduzieren.
Sie können eine einzelne Compute-Ressource verwenden, um alle Aufgaben auszuführen, die Teil des Auftrags sind, oder mehrere Auftragsressourcen, die für bestimmte Workloads optimiert sind. Jede als Teil eines Auftrags konfigurierte Auftragsberechnung ist für alle anderen Aufgaben in diesem Auftrag verfügbar.
Die folgende Tabelle zeigt die Unterschiede zwischen der für eine einzelne Aufgabe konfigurierten Auftragsberechnung und der von mehreren Aufgaben gemeinsam genutzten Auftragsberechnung:
| Einzelne Aufgabe | Gemeinsame Nutzung über Aufgaben hinweg | |
|---|---|---|
| Starten | Wenn der Aufgabenlauf beginnt. | Wenn der erste für die Nutzung der Computing-Ressource konfigurierte Aufgabenlauf beginnt. |
| beenden | Nach Ausführung der Aufgabe. | Nachdem die letzte Aufgabe, die zur Nutzung der Rechenressource konfiguriert wurde, ausgeführt ist. |
| Compute im Leerlauf | Nicht zutreffend. | Compute bleibt eingeschaltet und im Leerlauf, während Aufgaben ausgeführt werden, die die Computing-Ressource nicht verwenden. |
Ein freigegebener Auftragscluster ist auf eine einzelne Auftragsausführung beschränkt und kann nicht von anderen Aufträgen oder Ausführungen desselben Auftrags verwendet werden.
Bibliotheken können in einer Konfiguration für einen geteilten Auftragscluster nicht angegeben werden. Sie müssen abhängige Bibliotheken in den Aufgabeneinstellungen hinzufügen.
Gemeinsam genutzter Treiberstatus über Aufgaben hinweg
Wenn mehrere Vorgänge eine Auftragsberechnungsressource gemeinsam nutzen, werden die Vorgänge auf demselben Treiber-JVM ausgeführt. Klassenstatus und Singletons werden während der Laufzeit des Auftrags über Aufgaben hinweg beibehalten. Für die meisten Workloads ist dies transparent, beachten Sie jedoch die folgenden Auswirkungen:
- Skala-Singletons und Begleitobjekte werden aufgabenübergreifend gemeinsam genutzt. Der veränderbare Zustand in einem Scala-Begleitobjekt wird zwischen Aufgaben beibehalten, die auf demselben geteilten Cluster ausgeführt werden. Wenn parallele Aufgaben aus der gleichen Begleitobjektvariable gelesen oder in die gleiche Begleitobjektvariable geschrieben werden, kann der Wert einer Aufgabe die Anderen überschreiben. Ein funktionierendes Beispiel finden Sie im Knowledge Base-Artikel "Multiaufgabenworkflows" mit falschen Parameterwerten.
- Bibliotheken, die von einer Aufgabe geladen wurden, bleiben für nachfolgende Aufgaben für die Dauer der Ausführung des Auftrags verfügbar.
Wenn Ihr Code eine Isolation auf Aufgabenebene erfordert, verwenden Sie einen der folgenden Ansätze:
- Konfigurieren Sie jeden Vorgang so, dass eine separate Auftragsberechnungsressource verwendet wird.
- Fügen Sie explizite Vorgangsabhängigkeiten hinzu, damit die Aufgaben sequenziell und nicht parallel ausgeführt werden.
- Umgestalten Sie den Code, um die Verwendung von Singleton oder freigegebenem änderbarem Zustand zu vermeiden. Übergeben Sie beispielsweise Parameter explizit an jede Funktion, anstatt sie aus einem Begleitobjekt zu lesen.
Überprüfen, Konfigurieren und Tauschen von Rechenaufträgen
Der Abschnitt Compute im Fenster Job-Details listet alle für Aufgaben im aktuellen Job konfigurierten Berechnungen auf.
Aufgaben, die für die Verwendung einer Computing-Ressource konfiguriert sind, werden im Aufgabendiagramm hervorgehoben, wenn Sie den Mauszeiger über die Spezifikation der Computing-Ressource bewegen.
Verwenden Sie die Schaltfläche Austauschen, um die Berechnung für alle mit einer Computing-Ressource verbundenen Vorgänge zu ändern.
Klassische Compute-Ressourcen-Aufträge verfügen über eine Konfigurieren-Option. Andere Compute-Ressourcen bieten Ihnen Optionen zum Anzeigen und Ändern von Details der Compute-Konfiguration.
Mehr Informationen
Weitere Informationen zum Konfigurieren von klassischen Azure Databricks-Aufträgen finden Sie unter Bewährte Methoden zum Konfigurieren von klassischen Lakeflow-Aufträgen.