Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Dieser Artikel enthält Empfehlungen für die Implementierung von Erwartungen im Maßstab und Beispiele für fortgeschrittene Muster, die von Erwartungen unterstützt werden. Diese Muster verwenden mehrere Datasets in Verbindung mit Erwartungen und erfordern, dass Benutzer die Syntax und Semantik materialisierter Ansichten, Streamingtabellen und Erwartungen verstehen.
Eine grundlegende Übersicht über das Verhalten und die Syntax von Erwartungen finden Sie unter Verwalten der Datenqualität mit Pipelineerwartungen.
Tragbare und wiederverwendbare Vorgaben
Databricks empfiehlt die folgenden bewährten Methoden bei der Implementierung von Erwartungen zur Verbesserung der Portabilität und zur Verringerung der Wartungslasten:
| Empfehlung | Auswirkung |
|---|---|
| Speichern Sie Erwartungsdefinitionen getrennt von der Pipelinelogik. | Wenden Sie auf einfache Weise Erwartungen auf mehrere Datasets oder Pipelines an. Aktualisieren, Überwachen und Verwalten von Erwartungen, ohne den Pipeline-Quellcode zu ändern. |
| Fügen Sie benutzerdefinierte Tags hinzu, um Gruppen verwandter Erwartungen zu erstellen. | Filtert Erwartungen basierend auf Tags. |
| Wenden Sie Erwartungen konsistent in ähnlichen Datasets an. | Verwenden Sie die gleichen Erwartungen in mehreren Datasets und Pipelines, um identische Logik auszuwerten. |
Die folgenden Beispiele veranschaulichen die Verwendung einer Delta-Tabelle oder eines Wörterbuchs zum Erstellen eines zentralen Erwartungs-Repositorys. Benutzerdefinierte Python-Funktionen wenden diese Erwartungen dann auf Datasets in einer Beispielpipeline an:
Delta-Tabelle
Im folgenden Beispiel wird eine Tabelle erstellt, die zum Verwalten von Regeln benannt ist rules :
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
Im folgenden Python-Beispiel werden die Erwartungen an die Datenqualität basierend auf den Regeln in der rules Tabelle definiert. Die get_rules() Funktion liest die Regeln aus der rules Tabelle und gibt ein Python-Wörterbuch zurück, das Regeln enthält, die dem tag Argument entsprechen, das an die Funktion übergeben wird.
In diesem Beispiel wird das Wörterbuch mithilfe von @dp.expect_all_or_drop() Dekoratoren angewendet, um Einschränkungen für die Datenqualität zu erzwingen.
Beispielsweise werden alle Datensätze, bei denen die mit den Regeln markierten Regeln nicht übereinstimmen validity , aus der raw_farmers_market Tabelle gelöscht:
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Python-Modul
Im folgenden Beispiel wird ein Python-Modul zum Verwalten von Regeln erstellt. Speichern Sie in diesem Beispiel den Code in einer Datei namens rules_module.py im selben Ordner wie das Notizbuch, das als Quellcode für die Pipeline dient.
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
Im folgenden Python-Beispiel werden die Erwartungen an die Datenqualität basierend auf den in der rules_module.py Datei definierten Regeln definiert. Die get_rules()-Funktion gibt ein Python-Wörterbuch zurück, das die mit dem übergebenen tag Argument übereinstimmenden Regeln enthält.
In diesem Beispiel wird das Wörterbuch mithilfe von @dp.expect_all_or_drop() Dekoratoren angewendet, um Einschränkungen für die Datenqualität zu erzwingen.
Beispielsweise werden alle Datensätze, bei denen die mit den Regeln markierten Regeln nicht übereinstimmen validity , aus der raw_farmers_market Tabelle gelöscht:
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Überprüfung der Zeilenanzahl
Im folgenden Beispiel wird die Gleichheit der Zeilenanzahl zwischen table_a und table_b validiert, um sicherzustellen, dass während der Transformationen keine Daten verloren gehen.
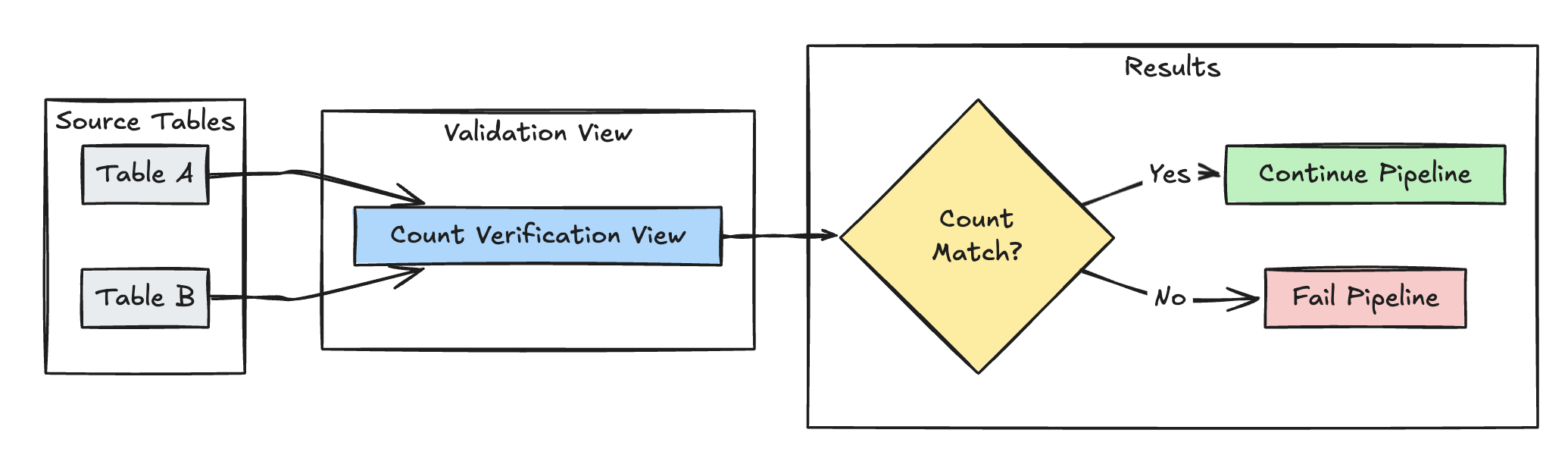
Python
@dp.view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
SQL
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Erkennung fehlender Datensätze
Im folgenden Beispiel wird überprüft, ob alle erwarteten Datensätze in der report Tabelle vorhanden sind:
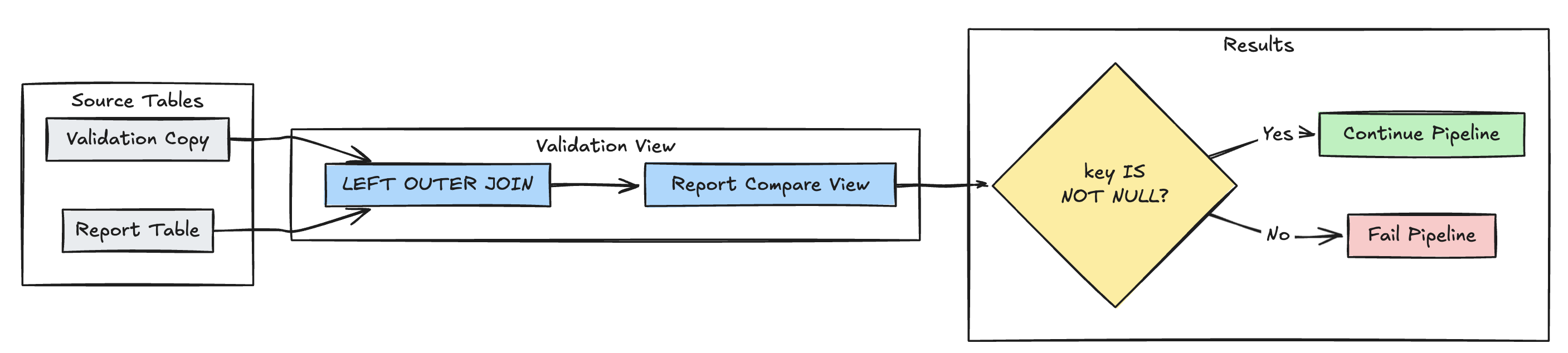
Python
@dp.view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Eindeutigkeit des Primärschlüssels
Im folgenden Beispiel werden Primärschlüsseleinschränkungen in Tabellen überprüft:
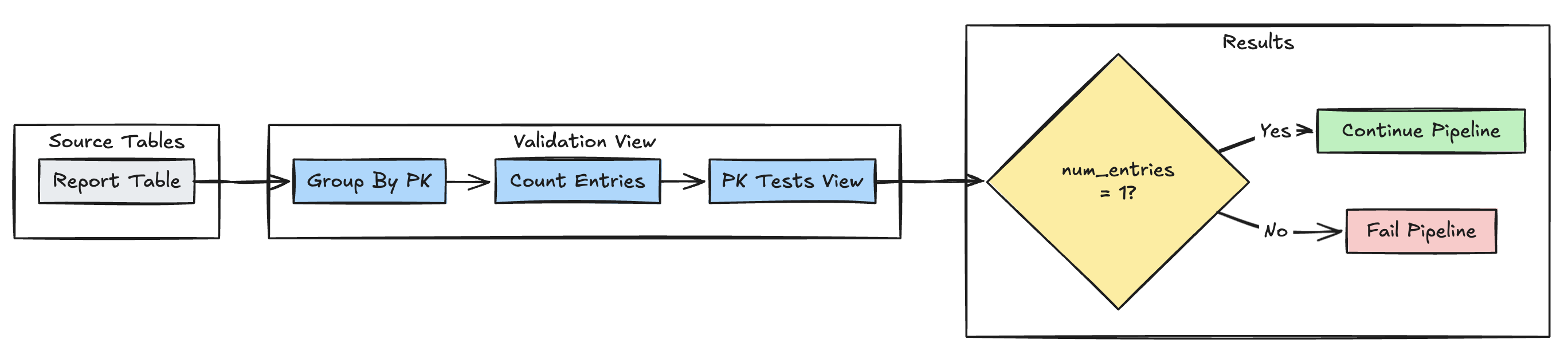
Python
@dp.view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
SQL
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Schemaentwicklungsmuster
Das folgende Beispiel zeigt, wie die Schemaentwicklung für zusätzliche Spalten behandelt wird. Verwenden Sie dieses Muster, wenn Sie Datenquellen migrieren oder mehrere Versionen von Daten aus vorgelagerten Quellen verarbeiten, um die Abwärtskompatibilität zu gewährleisten und gleichzeitig die Datenqualität sicherzustellen.
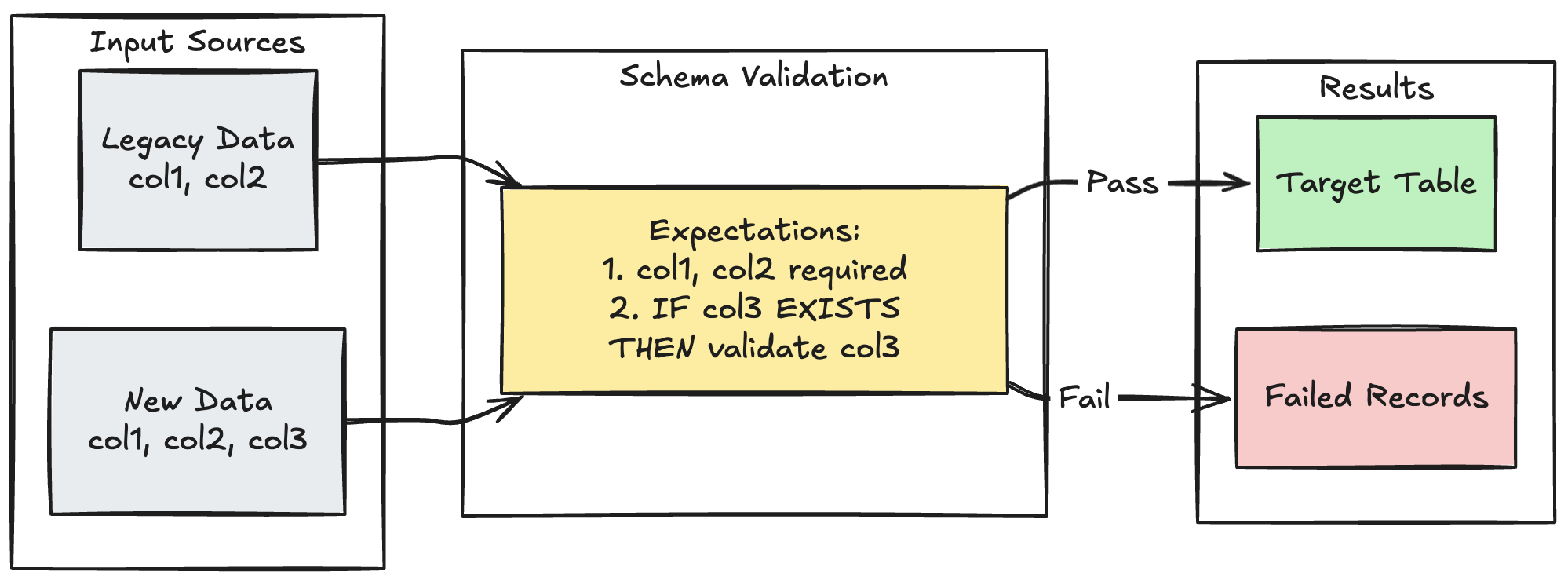
Python
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
SQL
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
Bereichsbasiertes Überprüfungsmuster
Im folgenden Beispiel wird veranschaulicht, wie neue Datenpunkte anhand historischer statistischer Bereiche überprüft werden, um Ausreißer und Anomalien in Ihrem Datenfluss zu identifizieren:
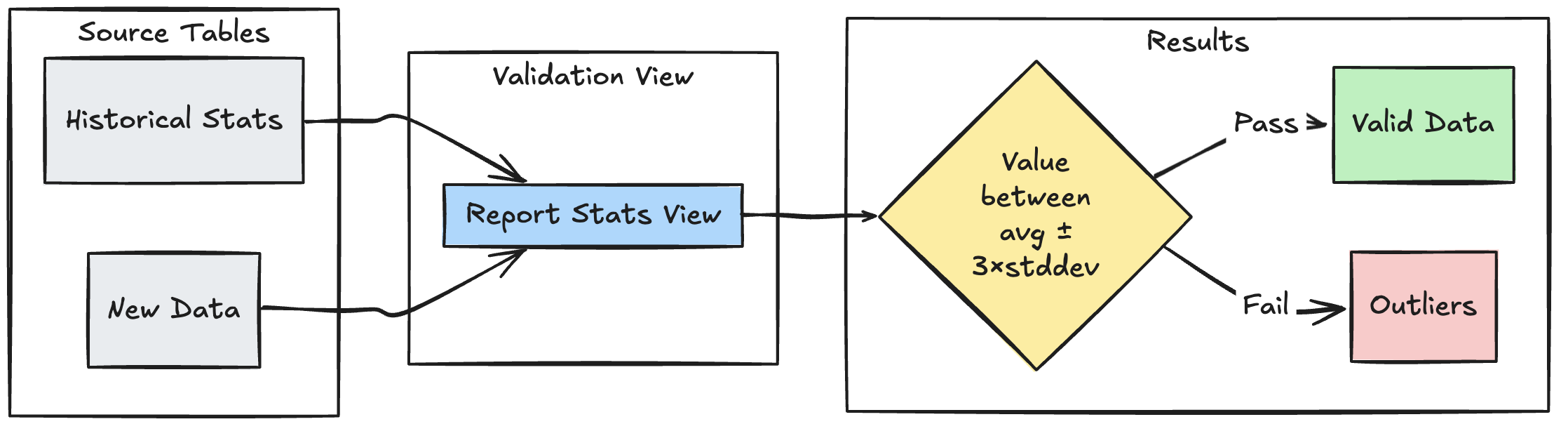
Python
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
SQL
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
Ungültige Datensätze unter Quarantäne
Dieses Muster kombiniert Erwartungen mit temporären Tabellen und Ansichten, um Datenqualitätsmetriken während pipelineupdates nachzuverfolgen und separate Verarbeitungspfade für gültige und ungültige Datensätze in downstream-Vorgängen zu ermöglichen.
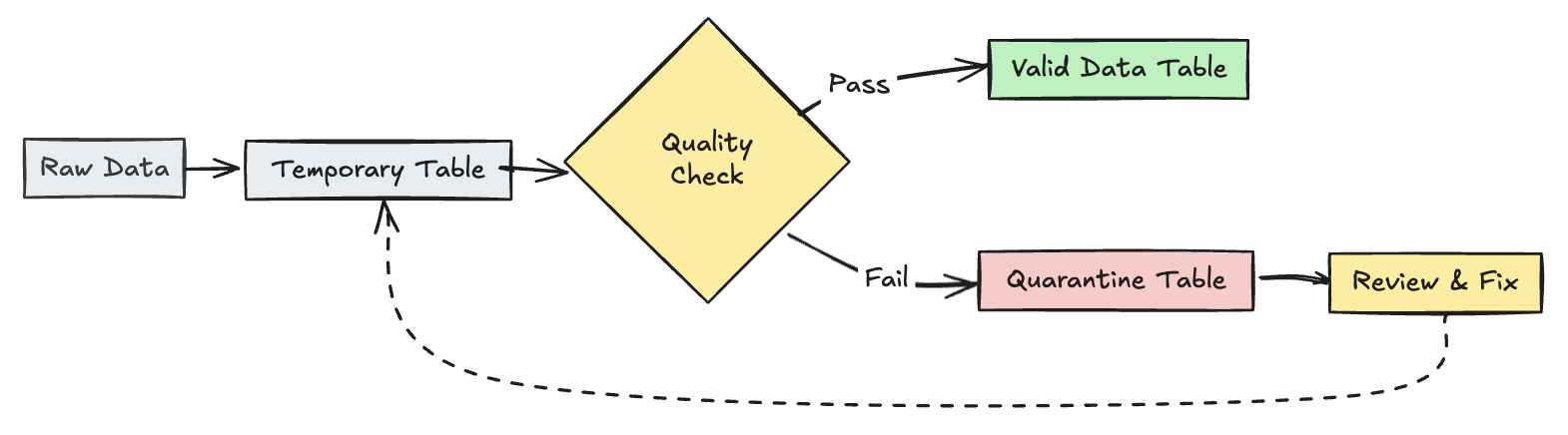
Python
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
SQL
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;