Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
In der Datentechnik bezieht sich das Ausfüllen auf den Prozess der rückwirkenden Verarbeitung von historischen Daten über eine Datenpipeline, die für die Verarbeitung aktueller oder Streamingdaten entwickelt wurde.
Dies ist in der Regel ein separater Fluss, der Daten in Ihre vorhandenen Tabellen sendet. Die folgende Abbildung zeigt einen Rückausfüllfluss, der historische Daten an die Bronzetabellen in Ihrer Pipeline sendet.
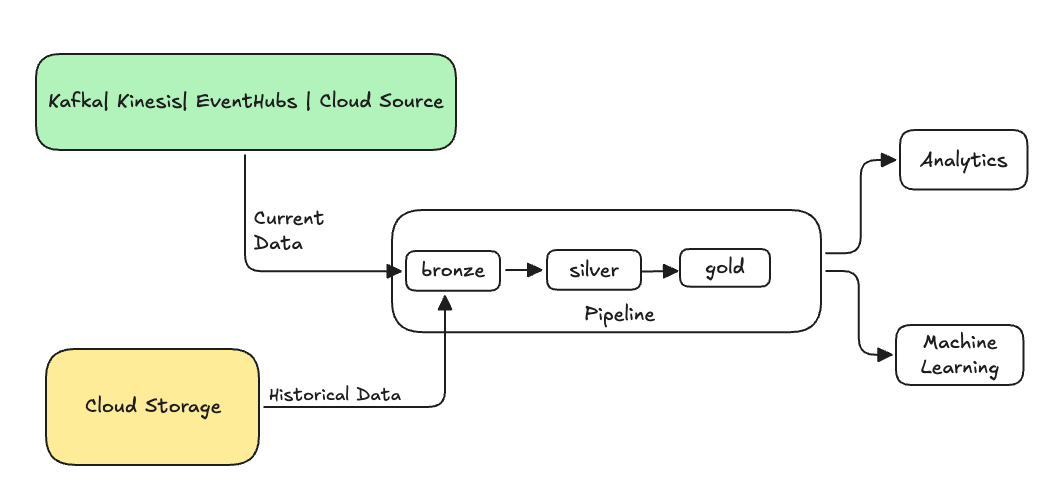
Einige Szenarien, für die ein Rückfüllen erforderlich sein kann:
- Verarbeiten Sie historische Daten aus einem älteren System, um ein Ml-Modell (Machine Learning) zu trainieren oder ein historisches Trendanalysedashboard zu erstellen.
- Neu verarbeiten einer Teilmenge von Daten wegen eines Datenqualitätsproblems mit vorgelagerten Datenquellen.
- Ihre geschäftlichen Anforderungen wurden geändert, und Sie müssen Daten für einen anderen Zeitraum zurückfüllen, der nicht von der ursprünglichen Pipeline abgedeckt wurde.
- Ihre Geschäftslogik hat sich geändert, und Sie müssen sowohl historische als auch aktuelle Daten neu verarbeiten.
Ein Backfill-Prozess in Lakeflow Spark Declarative Pipelines wird mit einem speziellen Append-Flow unterstützt, der die ONCE Option verwendet. Für weitere Informationen zur Option siehe append_flow oder ONCE.
Überlegungen beim Zurückfüllen von historischen Daten in eine Streamingtabelle
- In der Regel fügen Sie die Daten an die Bronzestreamingtabelle an. Nachgelagerte Silber- und Goldschichten nehmen die neuen Daten aus der Bronzeschicht auf.
- Stellen Sie sicher, dass Ihre Pipeline doppelte Daten ordnungsgemäß verarbeiten kann, falls dieselben Daten mehrmals angefügt werden.
- Stellen Sie sicher, dass das Verlaufsdatenschema mit dem aktuellen Datenschema kompatibel ist.
- Berücksichtigen Sie die Größe des Datenvolumes und die erforderliche Verarbeitungszeit SLA, und konfigurieren Sie entsprechend die Cluster- und Batchgrößen.
Beispiel: Hinzufügen eines Rückfüllens zu einer vorhandenen Pipeline
Angenommen, Sie haben eine Pipeline, die rohe Ereignisregistrierungsdaten aus einer Cloudspeicherquelle ab dem 01. Januar 2025 erfasst. Letztendlich stellen Sie fest, dass Sie den historischen Datenbestand der letzten drei Jahre nachträglich für Berichte und Analysezwecke der nachfolgenden Prozesse ergänzen möchten. Alle Daten befinden sich an einem Ort, partitioniert nach Jahr, Monat und Tag im JSON-Format.
Erste Pipeline
Hier sehen Sie den Startpipelinecode, der die rohen Ereignisregistrierungsdaten inkrementell aus dem Cloudspeicher erfasst.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Hier verwenden wir die modifiedAfter Option "Auto Loader", um sicherzustellen, dass wir nicht alle Daten aus dem Cloudspeicherpfad verarbeiten. Die inkrementelle Verarbeitung wird an dieser Grenze abgeschnitten.
Tipp
Andere Datenquellen wie Kafka, Kinesis und Azure Event Hubs verfügen über entsprechende Leseoptionen, um dasselbe Verhalten zu erzielen.
Auffüllung von Daten aus den vergangenen 3 Jahren
Jetzt möchten Sie einen oder mehrere Datenflüsse hinzufügen, um vorherige Daten aufzufüllen. Führen Sie in diesem Beispiel die folgenden Schritte aus:
- Verwenden Sie den
append onceFluss. Dadurch wird ein einmaliges Nachfüllen ausgeführt, ohne nach diesem ersten Rückfüllen weiter ausgeführt zu werden. Der Code verbleibt in Ihrer Pipeline und wenn die Pipeline jemals vollständig aktualisiert wird, wird das Rückfüllen erneut ausgeführt. - Erstellen Sie drei Backfill-Flüsse, eine für jedes Jahr (in diesem Fall werden die Daten nach Jahr im Pfad aufgeteilt). Für Python parametrisieren wir die Erstellung der Flüsse, aber in SQL wiederholen wir den Code dreimal, einmal für jeden Fluss.
Wenn Sie an Ihrem eigenen Projekt arbeiten und keine serverlose Berechnung verwenden, sollten Sie die maximalen Mitarbeiter für die Pipeline aktualisieren. Indem Sie die maximalen Arbeitskräfte erhöhen, gewährleisten Sie, dass Sie über die Ressourcen verfügen, um die historischen Daten zu verarbeiten und gleichzeitig die aktuellen Streaming-Daten innerhalb des erwarteten Service Level Agreements zu verarbeiten.
Tipp
Wenn Sie serverlose Berechnung mit erweiterter automatischer Skalierung (Standardeinstellung) verwenden, erhöht sich ihr Cluster automatisch in der Größe, wenn die Auslastung zunimmt.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Diese Implementierung hebt mehrere wichtige Muster hervor.
Trennung von Bedenken
- Die inkrementelle Verarbeitung ist unabhängig von Backfill-Vorgängen.
- Jeder Fluss verfügt über eigene Konfigurations- und Optimierungseinstellungen.
- Es gibt einen klaren Unterschied zwischen inkrementellen und Backfill-Vorgängen.
Kontrollierte Ausführung
- Durch die Verwendung der Option
ONCEwird sichergestellt, dass jeder Backfill genau einmal ausgeführt wird. - Der Rückfüllprozess verbleibt in der Pipeline-Grafik, befindet sich danach jedoch im Leerlauf. Sie ist für die vollständige Aktualisierung automatisch einsatzbereit.
- Es gibt einen klaren Prüfpfad für Backfill-Vorgänge in der Pipelinedefinition.
Verarbeitungsoptimierung
- Sie können den großen Rückfüller zur schnelleren Verarbeitung oder zur Steuerung der Verarbeitung in mehrere kleinere Rückfüllungen aufteilen.
- Durch die Verwendung der erweiterten automatischen Skalierung wird die Clustergröße basierend auf der aktuellen Clusterlast dynamisch skaliert.
Schemaentwicklung
- Die Verwendung von
schemaEvolutionMode="addNewColumns"geht mit Schemaänderungen ordnungsgemäß um. - Sie haben konsistente Schema-Inferenz über historische und aktuelle Daten hinweg.
- Es gibt eine sichere Handhabung neuer Spalten in neueren Daten.