Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Eine Streamingtabelle ist eine Delta-Tabelle mit zusätzlicher Unterstützung für Streaming oder inkrementelle Datenverarbeitung. Eine Streamingtabelle kann von einem oder mehreren Datenflüssen in einer Pipeline adressiert werden.
Streamingtabellen sind aus folgenden Gründen eine gute Wahl für die Datenaufnahme:
- Jede Eingabezeile wird nur einmal behandelt, wodurch die überwiegende Mehrheit der Erfassungsworkloads modelliert wird (d. a. indem Zeilen an eine Tabelle angefügt oder heraufgestrigt werden).
- Sie können große Mengen von Daten verarbeiten, die nur hinzugefügt werden können.
Streamingtabellen sind auch eine gute Wahl für Streamingtransformationen mit geringer Latenz, da sie über Zeilen und Zeitfenster hinweg Berechnungen anstellen können, hohe Datenmengen verarbeiten und eine Verarbeitung mit niedriger Latenz ermöglichen.
Das folgende Diagramm zeigt, wie Flüsse aus Streamingquellen gelesen und inkrementell in eine Streamingtabelle in einer Pipeline geschrieben werden.
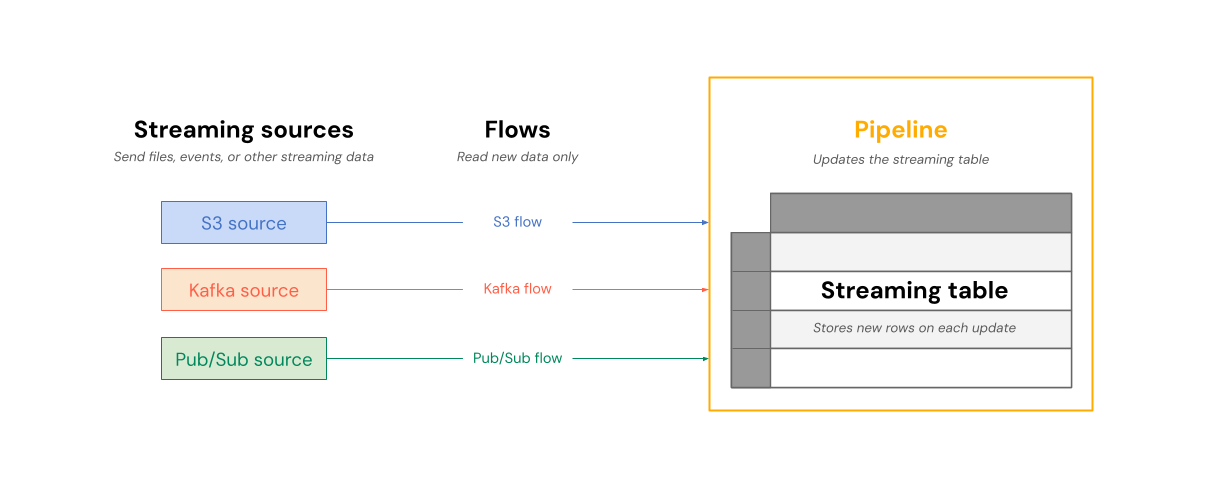
Bei jeder Aktualisierung lesen die Flüsse, die einer Streamingtabelle zugeordnet sind, die geänderten Informationen in einer Streamingquelle und fügen neue Informationen an diese Tabelle an.
Streamingtabellen sind eigentum und werden von einer einzigen Pipeline aktualisiert. Sie definieren Streamingtabellen explizit im Quellcode der Pipeline. Tabellen, die von einer Pipeline definiert sind, können von keiner anderen Pipeline geändert oder aktualisiert werden. Sie können mehrere Flüsse definieren, die an eine einzelne Streamingtabelle angefügt werden sollen.
Azure Databricks erstellt interne Tabellen zur Unterstützung der Streaming-Tabellenverarbeitung. Diese Tabellen erscheinen in system.information_schema.tables, sind jedoch im Katalog Explorer oder auf anderen Arbeitsbereichs-UI-Seiten nicht sichtbar.
Hinweis
Wenn Sie eine Streamingtabelle außerhalb einer Pipeline mit Databricks SQL erstellen, erstellt Azure Databricks eine Pipeline, die zum Aktualisieren der Tabelle verwendet wird. Sie können die Pipeline anzeigen, indem Sie Aufträge und Pipelines aus dem linken Navigationsbereich in Ihrem Arbeitsbereich auswählen. Sie können der Ansicht die Spalte " Pipelinetyp" hinzufügen. Streamingtabellen, die in einer Pipeline definiert sind, haben den Typ ETL. Streamingtabellen, die in Databricks SQL erstellt werden, haben den Typ MV/ST.
Weitere Informationen zu Flows finden Sie unter Daten inkrementell laden und verarbeiten mit Lakeflow Spark deklarativen Pipeline-Flows.
Streamingtabellen für die Dateneinspeisung
Streamingtabellen sind nur für Anfügedatenquellen vorgesehen und verarbeiten Eingaben nur einmal. Dies macht sie gut geeignet für Erfassungsworkloads, bei denen Daten kontinuierlich eingehen und zuverlässig erfasst werden müssen, ohne vorhandene Datensätze erneut zu verarbeiten. Azure Databricks unterstützt das Aufnehmen von Daten aus Cloudspeicher- und Streamingnachrichtenbussen.
Aufnehmen von Dateien aus dem Cloudspeicher
Sie können eine Streamingtabelle verwenden, um neue Dateien aus dem Cloudspeicher aufzunehmen. In diesen Beispielen wird das automatische Laden verwendet, um neue Dateien beim Eintreffen inkrementell zu verarbeiten.
Python
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Zum Erstellen einer Streamingtabelle muss die Datensatzdefinition ein Datenstromtyp sein. Wenn Sie die spark.readStream Funktion in einer Datasetdefinition verwenden, wird ein Streaming-Dataset zurückgegeben.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Streamingtabellen erfordern Streaming-Datensätze. Das STREAM Schlüsselwort vor read_files der Abfrage weist die Abfrage an, die Datenmenge als Datenstrom zu behandeln.
Aufnehmen von Streamingnachrichten
Sie können auch Streamingtabellen verwenden, um Daten aus Nachrichtenbussen aufzunehmen. Im folgenden Beispiel wird das Erstellen einer Streamingtabelle veranschaulicht, die aus einem Pub/Sub-Thema gelesen wird.
Python
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks empfiehlt die Verwendung von Geheimnissen beim Bereitstellen von Autorisierungsoptionen. Weitere Informationen finden Sie unter Konfigurieren des Zugriffs auf Pub/Sub für alle Authentifizierungsoptionen.
Weitere Informationen zum Laden von Daten in die Streamingtabelle finden Sie unter Laden von Daten in Pipelines.
Das folgende Diagramm veranschaulicht, wie Nur-Anfüge-Streamingtabellen funktionieren.
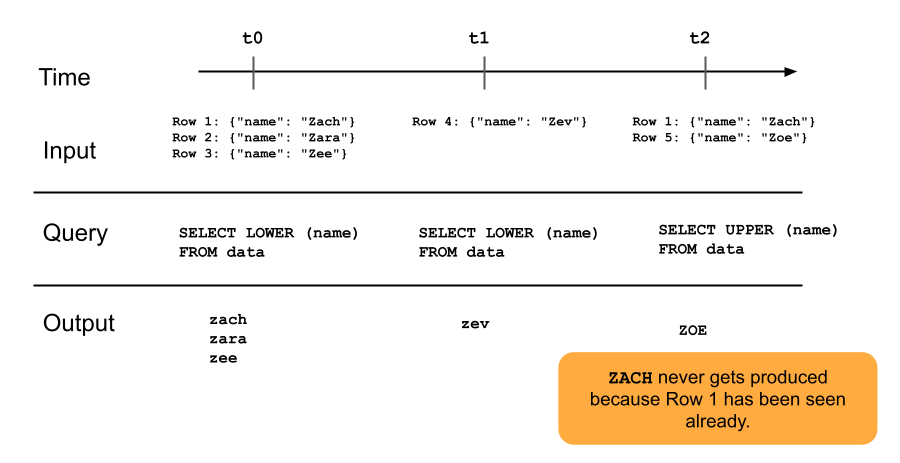
Eine Zeile, die bereits an eine Streamingtabelle angefügt wurde, wird mit späteren Aktualisierungen der Pipeline nicht erneut abgefragt. Wenn Sie die Abfrage ändern (z. B. von SELECT LOWER (name) zu SELECT UPPER (name)), werden vorhandene Zeilen nicht in Großbuchstaben aktualisiert, aber neue Zeilen sind Großbuchstaben. Sie können eine vollständige Aktualisierung auslösen, um sämtliche vorherige Daten aus der Quelltabelle erneut abzufragen und alle Zeilen in der Streaming-Tabelle zu aktualisieren.
Streamingtabellen und Streaming mit geringer Latenz
Streamingtabellen sind für Streaming mit geringer Latenz über den gebundenen Zustand ausgelegt. Streamingtabellen verwenden die Prüfpunktverwaltung, wodurch sie gut für Streaming mit geringer Latenz geeignet sind. Sie erwarten jedoch Ströme, die natürlich gebunden oder mit einem Wasserzeichen begrenzt sind.
Ein natürlich gebundener Datenstrom wird von einer Streamingdatenquelle erzeugt, die einen klar definierten Start- und End-Vorgang aufweist. Ein Beispiel für einen natürlich gebundenen Datenstrom ist das Lesen von Daten aus einem Verzeichnis mit Dateien, in denen keine neuen Dateien hinzugefügt werden, nachdem ein anfänglicher Batch von Dateien platziert wurde. Der Datenstrom wird als gebunden betrachtet, da die Anzahl der Dateien endlich ist und der Datenstrom endet, nachdem alle Dateien verarbeitet wurden.
Sie können auch ein Wasserzeichen verwenden, um einen Strom zu binden. Ein Wasserzeichen in strukturiertem Streaming ist ein Mechanismus, mit dem späte Daten behandelt werden können, indem angegeben wird, wie lange das System auf verzögerte Ereignisse warten soll, bevor das Zeitfenster als abgeschlossen betrachtet wird. Ein ungebundener Datenstrom ohne Wasserzeichen kann dazu führen, dass eine Pipeline aufgrund von Speicherdruck fehlschlägt.
Weitere Informationen zur zustandsbehafteten Datenstromverarbeitung finden Sie unter Optimieren der zustandsbehafteten Verarbeitung mit Wasserzeichen.
Stream-Snapshot-Verknüpfungen
Stream-Snapshot-Verknüpfungen verbinden ein Streaming-Dataset mit einer Dimensionstabelle, die beim Streamstart gesnapshottet wird. Da die Dimensionstabelle zu diesem Zeitpunkt als festgelegt behandelt wird, werden alle Änderungen, die nach dem Start des Streams vorgenommen werden, in der Verknüpfung nicht widergespiegelt. Dies ist akzeptabel, wenn kleine Abweichungen nicht wichtig sind , z. B. wenn die Anzahl der Transaktionen viele Größenordnungen größer als die Anzahl der Kunden ist.
Im folgenden Codebeispiel wird eine Dimensionstabelle namens customers mit zwei Zeilen mit einem ständig wachsenden Datensatz, transactions, verknüpft. Es materialisiert eine Verknüpfung zwischen diesen beiden Datensätzen in einer Tabelle, die den Namen sales_report trägt. Wenn ein externer Prozess die Kundentabelle aktualisiert, indem eine neue Zeile (customer_id=3, name=Zoya) hinzugefügt wird, ist diese neue Zeile nicht in der Verknüpfung vorhanden, da die statische Dimensionstabelle beim Starten von Datenströmen snapshott wurde.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Einschränkungen der Streamingtabelle
Streamingtabellen haben die folgenden Einschränkungen:
-
Begrenzte Entwicklung: Sie können die Abfrage ändern, ohne den gesamten Datensatz neu zu komputieren. Ohne vollständige Aktualisierung sieht eine Streamingtabelle nur einmal jede Zeile, sodass unterschiedliche Abfragen unterschiedliche Zeilen verarbeitet haben. Wenn Sie z. B. zu einem Feld in der Abfrage hinzufügen
UPPER(), werden nach der Änderung nur Zeilen in Großbuchstaben verarbeitet. Dies bedeutet, dass Sie alle vorherigen Versionen der Abfrage kennen müssen, die in Ihrem Dataset ausgeführt werden. Um vorhandene Zeilen erneut zu verarbeiten, die vor der Änderung verarbeitet wurden, ist eine vollständige Aktualisierung erforderlich. - Zustandsverwaltung: Streamingtabellen haben eine niedrige Latenz und erfordern Datenströme, die entweder natürlich begrenzt oder mit einem Wasserzeichen versehen sind. Weitere Informationen finden Sie unter Optimierung der zustandsbehafteten Verarbeitung mit Wasserzeichen.
- Verknüpfungen werden nicht neu berechnet: Verknüpfungen in Streamingtabellen werden nicht neu berechnet, wenn sich Dimensionen ändern. Diese Eigenschaft kann für "schnelle, aber falsche" Szenarien gut sein. Wenn Ihre Ansicht immer korrekt sein soll, möchten Sie möglicherweise eine Materialisierte Ansicht verwenden. Materialisierte Ansichten sind immer richtig, da sie Verknüpfungen automatisch neu kompensieren, wenn sich Dimensionen ändern. Weitere Informationen finden Sie unter Materialisierte Ansichten.