Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auf dieser Seite wird beschrieben, wie Delta-Tabellen als Quellen und Senken für Spark Structured Streaming mit readStream und writeStream verwendet werden. Delta Lake löst häufige Leistungs- und Zuverlässigkeitsprobleme für Streamingsysteme und Dateien. Zu diesen Vorteilen gehören:
- Konsolidieren Sie kleine Dateien, die mit geringer Latenz erzeugt wurden, um die Leistung zu verbessern.
- Beibehalten der "genau einmaligen" Verarbeitung mit mehr als einem Datenstrom (oder gleichzeitigen Batchaufträgen).
- Effizientes Ermitteln neuer Dateien bei Verwendung von Dateien als Streamquelle.
Informationen zum Laden von Daten mithilfe von Streamingtabellen in Databricks SQL finden Sie unter Verwenden von Streamingtabellen in Databricks SQL.
Informationen zu datenstromstatischen Verknüpfungen mit Delta Lake finden Sie unter Stream-static joins.
Verwenden von Delta-Tabellen als Spüle
Sie können Daten mithilfe von strukturiertem Streaming in eine Delta-Tabelle schreiben. Das Delta Lake-Transaktionsprotokoll garantiert eine genau einmalige Verarbeitung, auch dann, wenn andere Datenströme oder Batchabfragen parallel zur Tabelle laufen.
Wenn Sie mit einer Strukturierten Streaming-Sink in eine Delta-Tabelle schreiben, könnten leere Commits mit epochId = -1 auftreten. Diese werden erwartet und treten in der Regel auf:
- Im ersten Batch jeder Ausführung der Streamingabfrage (dies geschieht in jedem Batch für
Trigger.AvailableNow). - Wenn ein Schema geändert wird (z. B. hinzufügen einer Spalte).
Diese leeren Commits sind beabsichtigt und geben keinen Fehler an. Sie wirken sich nicht auf die Richtigkeit oder Leistung der Abfrage in irgendeiner Weise aus.
Note
Die Delta Lake-Funktion VACUUM entfernt alle Dateien, die nicht von Delta Lake verwaltet werden. Es werden aber alle Verzeichnisse übersprungen, die mit _ beginnen. Sie können Prüfpunkte mit anderen Daten und Metadaten für eine Delta-Tabelle mit einer Verzeichnisstruktur wie z. B. <table-name>/_checkpoints sicher speichern.
Überwachen des Backlogs mit Metriken
Verwenden Sie die folgenden Metriken, um den Backlog eines Streamingabfrageprozesses zu überwachen:
-
numBytesOutstanding: Anzahl der Bytes, die noch im Backlog verarbeitet werden sollen. -
numFilesOutstanding: Die Anzahl der Dateien, die noch im Backlog verarbeitet werden müssen. -
numNewListedFiles: Anzahl der aufgeführten Delta Lake-Dateien zum Berechnen des Backlogs für diesen Batch. -
backlogEndOffset: Die Delta-Tabellenversion, die zum Berechnen des Backlogs verwendet wird.
Zeigen Sie in einem Notizbuch diese Metriken auf der Registerkarte " Rohdaten " im Statusdashboard der Streamingabfrage an:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Anfügemodus
Standardmäßig werden Datenströme im Anfügemodus ausgeführt und fügen der Tabelle nur neue Datensätze hinzu.
Verwenden Sie die toTable Methode beim Streamen in Tabellen:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Vollständiger Modus
Verwenden Sie strukturiertes Streaming mit vollständigem Modus, um die gesamte Tabelle nach jedem Batch zu ersetzen. Sie können z. B. eine aggregierte Zusammenfassungstabelle von Ereignissen nach Kunden kontinuierlich aktualisieren:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Für Anwendungen ohne strenge Latenzanforderungen können Sie Computerressourcen und Kosten mit einmaligen Triggern wie z. B. AvailableNow sparen. Verwenden Sie beispielsweise diesen Trigger, um Zusammenfassungsaggregationstabellen in einem bestimmten Zeitplan zu aktualisieren, wobei nur neue Daten verarbeitet werden, die seit der letzten Aktualisierung eingegangen sind. Siehe AvailableNow: Inkrementelle Batchverarbeitung.
Behandeln von Änderungen an Delta-Quelltabellen
Beim strukturierten Streaming werden Delta-Tabellen inkrementell gelesen. Wenn eine Streamingabfrage aus einer Delta-Tabelle liest, werden neue Datensätze idempotent verarbeitet, sobald neue Tabellenversionen in der Quelltabelle bestätigt werden. Strukturiertes Streaming akzeptiert nur Anfügeeingaben und löst eine Ausnahme aus, wenn Änderungen in der Quell-Delta-Tabelle auftreten. Wenn z. B. ein UPDATE, DELETE, MERGE INTO oder OVERWRITE Vorgang eine Delta-Quelltabelle ändert, die von einer Streaming-Abfrage gelesen wird, tritt ein Fehler im Datenstrom auf.
Je nach Anwendungsfall gibt es vier typische Ansätze für die Behandlung von upstream-Änderungen an Delta-Quelltabellen. Unten finden Sie eine Referenztabelle und Details zu den einzelnen Themen:
| Vorgehensweise | Pros | Cons |
|---|---|---|
skipChangeCommits |
Einfach, erfordert nicht, dass Sie komplexe Logik schreiben. Nützlich für die Anfügeverarbeitung, bei der Upstream-Änderungen separat behandelt werden, oder für die vorübergehende Bearbeitung eines fehlerhaften Datensatzes. | Änderungen werden nicht weitergegeben und es werden nur Anfügungen verarbeitet. |
| Vollständige Aktualisierung | Es ist außerdem einfach, Sie müssen keine komplexe Logik schreiben. Nützlich für kleine Datasets mit seltenen vorgelagerten Änderungen. | Teuer für große Datasets. Erfordert die Erneute Verarbeitung aller nachgelagerten Tabellen. |
| Daten-Feed ändern | Verarbeiten aller Änderungstypen (Einfügungen, Aktualisierungen und Löschungen). Databricks empfiehlt, wann immer möglich, aus dem CDC-Feed einer Delta-Tabelle zu streamen, anstatt direkt aus der Tabelle. | Erfordert, dass Sie komplexere Logik schreiben, um jeden Änderungstyp zu behandeln. |
| Materialisierte Ansichten | Einfache Alternative zu strukturiertem Streaming mit automatischer Änderungsverteilung. | Höhere Latenz. Nur in Lakeflow Spark Declarative Pipelines und Databricks SQL verfügbar. |
Upstream-Änderungen überspringen mit skipChangeCommits
skipChangeCommits festlegen, um Transaktionen zu ignorieren, die vorhandene Datensätze löschen oder ändern, und nur Anhänge zu verarbeiten. Dies ist nützlich, wenn Änderungen an vorhandenen Daten nicht über den Datenstrom weitergegeben werden müssen oder wenn Sie eine separate Logik bevorzugen, um diese Änderungen zu behandeln. Sie können skipChangeCommits ein- und ausschalten, wenn Sie einmalige Änderungen vorübergehend ignorieren müssen.
Databricks empfiehlt die Verwendung skipChangeCommits für die meisten Workloads, die keine Änderungsdatenfeeds verwenden.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Wenn sich das Schema für eine Delta-Tabelle ändert, nachdem ein Streaminglesevorgang für die Tabelle beginnt, dann schlägt die Abfrage fehl. Bei den meisten Schemaänderungen können Sie den Stream neu starten, um Schemakonflikte zu beheben und die Verarbeitung fortzusetzen.
In Databricks Runtime 12.2 LTS und früher können Sie nicht aus einer Delta-Tabelle mit aktivierter Spaltenzuordnung streamen, die eine nicht additive Schemaentwicklung durchlaufen hat, z. B. durch Umbenennen oder Löschen von Spalten. Ausführliche Informationen finden Sie unter Spaltenzuordnung und Streaming.
Note
In Databricks Runtime 12.2 LTS und höher ersetzt skipChangeCommitsignoreChanges. In Databricks Runtime 11.3 LTS und früher ist ignoreChanges die einzige unterstützte Option. Weitere Informationen finden Sie unter Legacyoption ignoreChanges .
Legacyoption: ignoreDeletes
ignoreDeletes ist eine Legacyoption, die nur Transaktionen verarbeitet, die Daten an Partitionsgrenzen löschen (d. a. vollständige Partitionsabbrüche). Wenn Sie nicht-partitionierte Löschungen, Aktualisierungen oder andere Änderungen behandeln müssen, verwenden Sie skipChangeCommits stattdessen.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Legacyoption: ignoreChanges
ignoreChanges ist in Databricks Runtime 11.3 LTS und niedriger verfügbar. In Databricks Runtime 12.2 LTS und höher wird sie durch skipChangeCommitsersetzt.
Wenn ignoreChanges aktiviert ist, werden neu geschriebene Datendateien in der Quelltabelle nach einem Datenänderungsvorgang wie UPDATE, MERGE INTO, DELETE (innerhalb von Partitionen) oder OVERWRITE erneut ausgegeben. Unveränderte Zeilen werden häufig zusammen mit neuen Zeilen ausgegeben, sodass Downstream-Consumer in der Lage sein müssen, mit Duplikaten umzugehen. Löschungen werden nicht nachgeschaltet propagiert.
ignoreChanges hat Vorrang vor ignoreDeletes.
Im Gegensatz dazu skipChangeCommits werden dateiverändernde Vorgänge vollständig ignoriert. Umgeschriebene Datendateien in der Quelltabelle aufgrund von Datenänderungsvorgängen wie UPDATE, MERGE INTO, DELETEund OVERWRITE werden vollständig ignoriert. Um Änderungen in Datenstromquelltabellen widerzuspiegeln, müssen Sie separate Logik implementieren, um diese Änderungen zu verteilen.
Databricks empfiehlt die Verwendung skipChangeCommits für alle neuen Workloads. Um eine Workload von ignoreChanges zu skipChangeCommits zu migrieren, refaktorieren Sie Ihre Streaminglogik.
Vollständige Aktualisierung der nachgeschalteten Tabellen
Wenn Upstream-Änderungen selten sind und die Daten klein genug sind, um sie erneut zu verarbeiten, können Sie den Streaming-Prüfpunkt und die Ausgabetabelle löschen und dann den Stream von Anfang an neu starten. Dies bewirkt, dass der Datenstrom alle Daten aus der Quelltabelle neu verarbeitet. Beachten Sie, dass bei diesem Ansatz auch alle nachgelagerten Tabellen neu verarbeitet werden müssen, die von der Ausgabe dieses Datenstroms abhängen.
Dieser Ansatz eignet sich am besten für kleinere Datasets oder Workloads, bei denen upstream-Änderungen selten sind und die Kosten einer vollständigen Aktualisierung akzeptabel sind.
Verwenden Sie den Change Data Feed
Verwenden Sie für Workloads, die alle Arten von Änderungen verarbeiten (Einfügungen, Aktualisierungen und Löschungen), den Delta Lake-Änderungsdatenfeed. Der Datenfeed zeichnet Änderungen auf Zeilenebene in einer Delta-Tabelle auf, sodass Sie diese Änderungen streamen und Logik schreiben können, um jeden Änderungstyp in nachgeschalteten Tabellen zu behandeln. Dies ist der robusteste Ansatz, da Ihr Code explizit jede Art von Änderungsereignis behandelt. Siehe Verwenden Sie den Change Data Feed von Delta Lake auf Azure Databricks.
Wenn Sie Lakeflow Spark Declarative Pipelines verwenden, lesen Sie die AUTO CDC-APIs: Vereinfachen der Änderungsdatenerfassung mit Pipelines.
Important
In Databricks Runtime 12.2 LTS und unten können Sie keinen Stream aus dem Änderungsdatenfeed für eine Delta-Tabelle mit aktivierter Spaltenzuordnung durchführen, die eine nicht-additive Schemaentwicklung durchlaufen hat, z. B. Umbenennen oder Ablegen von Spalten. Siehe Spaltenzuordnung und Streaming.
Verwenden materialisierter Sichten
Materialisierte Ansichten behandeln automatisch vorgelagerte Änderungen, indem Ergebnisse beim Ändern der Quelldaten neu komputiert werden. Wenn Sie die niedrigste mögliche Latenz nicht benötigen und die Verwaltung der Streamingkomplexität vermeiden möchten, kann eine materialisierte Ansicht Ihre Architektur vereinfachen. Materialisierte Ansichten sind in Lakeflow Spark Declarative Pipelines Pipelines und in Databricks SQL verfügbar. Siehe Materialisierte Ansichten.
Example
Angenommen, Sie haben eine Tabelle user_events mit den Spalten date, user_email und action, die bis date partitioniert ist. Sie streamen aus der Tabelle user_events und müssen Daten aus dieser Tabelle aufgrund der DSGVO löschen.
skipChangeCommits ermöglicht das Löschen von Daten in mehreren Partitionen (in diesem Beispiel filtern nach user_email). Verwenden Sie die folgende Syntax:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Wenn Sie eine user_email mit der Anweisung UPDATE aktualisieren, wird die Datei, die das betreffende user_email enthält, neu geschrieben. Verwenden Sie skipChangeCommits, um die geänderten Datendateien zu ignorieren.
Databricks empfiehlt die Verwendung von skipChangeCommits anstelle von ignoreDeletes, es sei denn, Sie sind sicher, dass Löschvorgänge immer vollständige Partitionslöschungen sind.
Verwenden Sie foreachBatch für idempotente Tabellenschreibvorgänge
Note
Databricks empfiehlt die Konfiguration eines separaten Streaming-Schreibvorgangs für jede Spüle, die Sie aktualisieren möchten, anstatt foreachBatchzu verwenden. Schreibvorgänge an mehrere Senken foreachBatch reduzieren die Parallelisierung und erhöhen die Gesamtlatenz, da Schreibvorgänge in mehrere Tabellen foreachBatch serialisiert werden.
Delta-Tabellen unterstützen die folgenden DataFrameWriter Optionen, um Schreibvorgänge in mehrere Tabellen in foreachBatch idempotent zu machen.
-
txnAppId: Eine eindeutige Zeichenfolge, die Sie bei DataFrame-Schreibvorgang übergeben können. Beispielsweise können Sie die StreamingQuery ID alstxnAppIdverwenden.txnAppIdkann eine beliebige vom Benutzer generierte eindeutige Zeichenfolge sein und muss nicht mit der Datenstrom-ID verknüpft sein. -
txnVersion: Eine monoton steigende Zahl, die als Transaktionsversion fungiert.
Delta Lake verwendet txnAppId und txnVersion, um doppelte Schreibvorgänge zu identifizieren und zu ignorieren. Wenn beispielsweise ein Fehler einen Batchschreibvorgang unterbrochen hat, können Sie den Batch erneut mit demselben txnAppId ausführen und txnVersion so Duplikate korrekt identifizieren und ignorieren. Siehe Verwenden von foreachBatch zum Schreiben in beliebige Datensenken.
Warning
Wenn Sie den Streamingprüfpunkt löschen und die Abfrage mit einem neuen Prüfpunkt neu starten, müssen Sie einen anderen txnAppId-Wert angeben. Neue Prüfpunkte beginnen mit der Batch-ID 0. Delta Lake verwendet die Batch-ID und txnAppId als eindeutigen Schlüssel und überspringt Batches mit bereits gesehenen Werten.
Im folgenden Codebeispiel wird dieses Muster veranschaulicht:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Ausführen eines Upsert aus Streamingabfragen mithilfe von foreachBatch
Sie können merge und foreachBatch verwenden, um komplexe Upserts aus einer Streamingabfrage in eine Delta-Tabelle zu schreiben. Siehe Verwenden von foreachBatch zum Schreiben in beliebige Datensenken.
Dieser Ansatz hat viele Anwendungen:
- Verbessern Sie die Schreibleistung im
updateAusgabemodus, währendcompleteder Ausgabemodus die gesamte Ergebnistabelle für jede Mikrobatch neu schreiben muss. - Wenden Sie kontinuierlich einen Strom von Änderungen auf eine Delta-Tabelle an, indem Sie eine Zusammenführungsabfrage verwenden, um Änderungsdaten in
foreachBatchzu schreiben. Sehen Sie sich langsam ändernde Daten (SCD) und die Datenerfassung (CDC) mit Delta Lake an. - Deduplizierung während der Streamverarbeitung bearbeiten. Sie können eine Nur-Einfügungs-Merge-Abfrage in
foreachBatchverwenden, um kontinuierlich Daten in eine Delta-Tabelle mit automatischer Deduplizierung zu schreiben. Siehe Datendeduplizierung beim Schreiben in Delta-Tabellen.
Note
Stellen Sie sicher, dass Ihre
mergeAnweisung innerhalb vonforeachBatchidempotent ist. Andernfalls können Neustarts der Streamingabfrage den Vorgang mehrmals auf denselben Datenbatch anwenden. Siehe Verwendung vonforeachBatchfür idempotente Tabellenschreibvorgänge.Wenn
mergeinforeachBatchverwendet wird, kann die Eingabedatenratenmetrik ein Vielfaches der tatsächlichen Rate zurückgeben, mit der Daten an der Quelle generiert werden.mergeliest Eingabedaten mehrmals, wodurch die Metriken multipliziert werden. Um die metrische Multiplikation zu verhindern, cachen Sie den DataFrame-Batch vormergeund löschen Sie den Cache danach nachmerge.Die Eingabedatenrate ist über
StreamingQueryProgressund im Streaming-Rategrafen des Notizbuchs verfügbar. Weitere Informationen finden Sie unter Monitoring Structured Streaming queries on Azure Databricks.
Z. B. können Sie MERGE SQL-Anweisungen in foreachBatch verwenden:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Sie können auch die Delta Lake-APIs für Streaming-Upserts verwenden:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Festlegen der anfänglichen Tabellenversion zum Verarbeiten von Änderungen
Standardmäßig beginnen Datenströme mit der neuesten verfügbaren Delta-Tabellenversion. Dazu gehört eine vollständige Momentaufnahme der Tabelle zu diesem Zeitpunkt und alle zukünftigen Änderungen. Databricks empfiehlt, für die meisten Workloads die Standardversion der ersten Tabelle zu verwenden.
Optional können Sie die folgenden Optionen verwenden, um den Ausgangspunkt der Delta Lake-Streamingquelle anzugeben, ohne die gesamte Tabelle zu verarbeiten.
startingVersion: Die Delta-Tabellenversion, von der aus gelesen werden soll. Alle Tabellenänderungen, die an oder nach der angegebenen Version übernommen wurden, werden vom Datenstrom gelesen. Wenn die angegebene Version nicht verfügbar ist, kann der Datenstrom nicht gestartet werden.Um verfügbare Commitversionen zu finden, führen Sie
DESCRIBE HISTORYaus und überprüfen Sieversion. Um nur die neuesten Änderungen zurückzugeben, geben Sielatestan. Informationen zu Delta-Tabellenversionen finden Sie unter "Arbeiten mit Tabellenverlauf".startingTimestamp: Der Zeitstempel, von dem aus gelesen werden soll. Alle Tabellenänderungen, die an oder nach dem angegebenen Zeitstempel zugesichert wurden, werden vom Datenstrom gelesen. Wenn der angegebene Zeitstempel allen Tabellencommits vorangestellt ist, beginnt der Streaminglesevorgang mit dem frühesten verfügbaren Zeitstempel. Legen Sie eine der folgenden Optionen fest:- Eine Zeitstempelzeichenfolge. Beispiel:
"2019-01-01T00:00:00.000Z". - Eine Datumszeichenfolge. Beispiel:
"2019-01-01".
- Eine Zeitstempelzeichenfolge. Beispiel:
Sie können nicht beide startingVersion und startingTimestamp gleichzeitig festlegen. Diese Einstellungen gelten nur für neue Streamingabfragen. Wenn eine Streamingabfrage gestartet wurde und der Fortschritt im Prüfpunkt aufgezeichnet wurde, werden diese Einstellungen ignoriert.
Important
Obwohl Sie die Streamingquelle von einer angegebenen Version oder einem angegebenen Zeitstempel starten können, ist das Schema der Streamingquelle immer das neueste Schema der Delta-Tabelle. Sie müssen sicherstellen, dass es nach der angegebenen Version oder dem angegebenen Zeitstempel keine inkompatible Schemaänderung an der Delta-Tabelle gibt. Andernfalls gibt die Streamingquelle beim Lesen der Daten mit einem falschen Schema möglicherweise falsche Ergebnisse zurück.
Example
Beispiel: Sie haben eine Tabelle user_events. Wenn Sie Änderungen ab Version 5 lesen möchten, verwenden Sie:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Wenn Sie Änderungen ab Version 2018-10-18 lesen möchten, verwenden Sie:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Verarbeitung einer anfänglichen Momentaufnahme ohne Verlust von Daten
Dieses Feature ist in Databricks Runtime 11.3 LTS und höher verfügbar.
In einer zustandsbehafteten Streaming-Abfrage mit einem definierten Wasserzeichen kann die Verarbeitung von Dateien basierend auf der Änderungszeit dazu führen, dass Datensätze in der falschen Reihenfolge verarbeitet werden. Dies kann dazu führen, dass das Wasserzeichen Datensätze falsch als späte Ereignisse markiert und sie verwirft. Dies kann nur auftreten, wenn die anfängliche Delta-Momentaufnahme in der Standardreihenfolge verarbeitet wird.
Bei Datenströmen mit einer Delta-Quelltabelle verarbeitet die Abfrage zunächst alle daten, die in der Tabelle vorhanden sind, und erstellt eine Version, die als anfängliche Momentaufnahme bezeichnet wird. Standardmäßig werden die Datendateien der Delta-Tabelle basierend auf der zuletzt geänderten Datei verarbeitet. Der Zeitpunkt der letzten Änderung entspricht jedoch nicht unbedingt der zeitlichen Reihenfolge der Aufzeichnungsereignisse.
Aktivieren Sie die withEventTimeOrder Option, um Datenverluste während der anfänglichen Momentaufnahmeverarbeitung zu vermeiden.
withEventTimeOrder teilt den Ereigniszeitbereich der anfänglichen Momentaufnahmedaten in Zeit-Buckets auf. Jeder Mikro-Batch verarbeitet einen Bucket, indem Daten innerhalb des angegebenen Zeitraums gefiltert werden. Die Optionen maxFilesPerTrigger und maxBytesPerTrigger sind weiterhin anwendbar, um die Mikrobatchgröße zu steuern, jedoch nur ungefähr, da der Verarbeitungsansatz dies bedingt.
Das folgende Diagramm zeigt diesen Prozess:
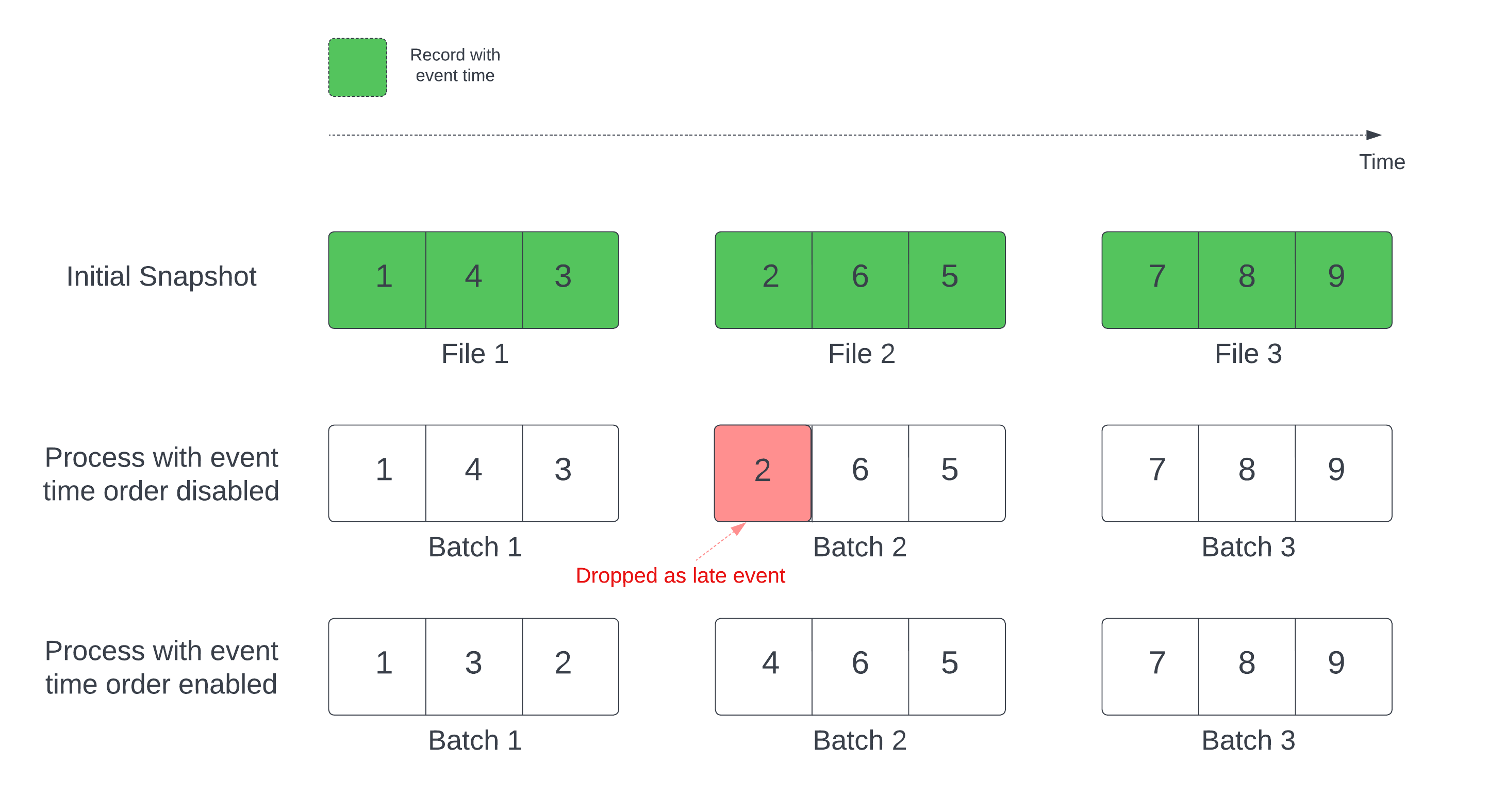
Constraints
- Sie können
withEventTimeOrdernicht ändern, wenn die Stream-Abfrage gestartet wurde und der anfängliche Schnappschuss aktiv verarbeitet wird. Um mit geändertenwithEventTimeOrderneu zu starten, müssen Sie den Prüfpunkt löschen. - Wenn
withEventTimeOrderaktiviert ist, können Sie einen Datenstrom nicht auf eine Databricks-Runtime-Version herabstufen, die dieses Feature nicht unterstützt, bis die anfängliche Momentaufnahmeverarbeitung abgeschlossen ist. Warten Sie zum Downgrade, bis der anfängliche Snapshot abgeschlossen ist, oder löschen Sie den Checkpoint und starten Sie die Abfrage erneut. - Dieses Feature wird in den folgenden Szenarien nicht unterstützt:
- Die Ereigniszeitspalte ist eine generierte Spalte und es gibt nicht projektive Transformationen zwischen der Delta-Quelle und dem Grenzwert.
- Es gibt ein Wasserzeichen, das mehr als eine Delta-Quelle in der Streamabfrage umfasst.
Leistung
Wenn withEventTimeOrder diese Option aktiviert ist, ist die Leistung der anfänglichen Momentaufnahmeverarbeitung möglicherweise langsamer. Jeder Mikrobatch überprüft die anfängliche Momentaufnahme, um Daten innerhalb des entsprechenden Ereigniszeitbereichs zu filtern. So verbessern Sie die Filterleistung:
- Verwenden Sie eine Delta-Quellspalte als Ereigniszeitpunkt, sodass Datenüberspringen angewendet werden kann. Siehe Datenüberspringen.
- Partitionieren Sie die Tabelle entlang der Ereigniszeitspalte.
Verwenden Sie die Spark-Benutzeroberfläche, um zu sehen, wie viele Delta-Dateien für einen bestimmten Mikrobatch gescannt werden.
Example
Angenommen, Sie haben Tabelle user_events mit der Spalte event_time. Ihre Streamingabfrage ist eine Aggregationsabfrage. Wenn Sie sicherstellen möchten, dass während der Verarbeitung der Anfangsmomentaufnahme keine Daten verloren gehen, können Sie Folgendes verwenden:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Sie können eine Spark-Konfiguration auf dem Cluster festlegenwithEventTimeOrder, um sie auf alle Streamingabfragen anzuwenden: spark.databricks.delta.withEventTimeOrder.enabled true
Einschränken der Eingaberate zur Verbesserung der Verarbeitungsleistung
Standardmäßig verarbeitet strukturiertes Streaming so viele Dateien wie möglich in jedem Mikrobatch. Verwenden Sie die folgenden Optionen, um die Menge der pro Batch verarbeiteten Daten zu begrenzen und die Speicherauslastung zu verwalten, die Latenz zu stabilisieren oder die Kosten für Cloudspeicher zu verringern:
-
maxFilesPerTrigger: Die Anzahl der neuen Dateien, die in jedem Mikrobatch berücksichtigt werden sollen. Der Standardwert lautet 1000. -
maxBytesPerTrigger: Die Datenmenge, die in jedem Mikrobatch verarbeitet wird. Mit dieser Option wird ein "soft max" festgelegt, d. h., dass ein Batch ungefähr diese Datenmenge verarbeitet und möglicherweise mehr als den Grenzwert verarbeitet, um die Streamingabfrage in Fällen vorwärts zu verschieben, in denen die kleinste Eingabeeinheit größer als dieser Grenzwert ist. Dies ist nicht standardmäßig festgelegt.
Wenn Sie sowohl maxBytesPerTrigger als auch maxFilesPerTrigger verwenden, verarbeitet das Mikrobatch die Daten, bis entweder der maxFilesPerTrigger- oder maxBytesPerTrigger-Grenzwert erreicht ist.
Note
logRetentionDuration Wenn Transaktionen in der Quelltabelle bereinigt werden und die Streamingabfrage versucht, diese Versionen zu verarbeiten, verhindert die Abfrage den Datenverlust nicht. Sie können die Option failOnDataLoss auf false festlegen, um verlorene Daten zu ignorieren und die Verarbeitung fortzusetzen. Siehe Konfigurieren der Datenaufbewahrung für Zeitreiseabfragen.
Steuern der Cloudspeicherkosten
Streamingabfragen stehen mehrere Triggermodi zur Verfügung, mit denen Sie Kosten und Latenz ausgleichen können, einschließlich processingTime, availableNowund realTime. Siehe Steuern der Cloudspeicherkosten.