Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
Dieses Feature befindet sich in der Public Preview.
Benutzerdefinierte Funktionen (UDFs) im Unity-Katalog erweitern SQL- und Python-Fähigkeiten in Azure Databricks. Sie ermöglichen es, benutzerdefinierte Funktionen für computerübergreifende Umgebungen zu definieren, zu verwenden und sicher gemeinsam zu nutzen und zu regeln.
Python-UDFs, die in Unity Catalog als Funktionen registriert sind, unterscheiden sich in Umfang und Unterstützung von PySpark-UDFs, die einem Notebook-Bereich oder SparkSession zugeordnet sind. Weitere Informationen finden Sie unter Benutzerdefinierte Skalarfunktionen: Python.
Vollständige SQL-Sprachreferenz finden Sie unter CREATE FUNCTION (SQL und Python).
Anforderungen
Um UDFs im Unity-Katalog zu verwenden, müssen Sie die folgenden Anforderungen erfüllen:
- Um Python-Code in UDFs zu verwenden, die im Unity-Katalog registriert sind, müssen Sie ein serverloses oder pro SQL Warehouse oder einen Cluster mit Databricks Runtime 13.3 LTS oder höher verwenden.
- Wenn eine Ansicht ein Unity Catalog Python UDF enthält, schlägt sie bei klassischen SQL-Warehouses fehl.
- Arm-Instanzunterstützung für Scala UDFs auf Unity-Katalogfähigen Clustern ist in Databricks Runtime 15.2 und höher verfügbar.
Erstellen von UDFs im Unity-Katalog
Um eine UDF im Unity-Katalog zu erstellen, benötigen Benutzende USAGE- und CREATE-Berechtigungen für das Schema und die USAGE-Berechtigung für den Katalog. Weitere Details finden Sie im Unity-Katalog .
Um eine UDF auszuführen, benötigen Benutzer EXECUTE-Berechtigungen für die UDF. Benutzer benötigen auch die VERWENDUNGsberechtigung für das Schema und den Katalog.
Um eine UDF in einem Unity-Katalogschema zu erstellen und zu registrieren, sollte der Funktionsname dem Format catalog.schema.function_nameentsprechen. Alternativ können Sie den richtigen Katalog und das richtige Schema im SQL-Editor auswählen.
In diesem Fall sollte ihr Funktionsname nicht catalog.schema vorangestellt sein:

Im folgenden Beispiel wird eine neue Funktion für das my_schema Schema im my_catalog Katalog registriert:
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight DOUBLE, height DOUBLE)
RETURNS DOUBLE
LANGUAGE SQL
RETURN
SELECT weight / (height * height);
Python-UDFs für den Unity Catalog verwenden Anweisungen, die durch doppelte Dollarzeichen ($$) versetzt werden. Sie müssen eine Datentypzuordnung angeben. Im folgenden Beispiel wird eine Benutzerdefinierte Funktion (UDF) registriert, die den Körpermasseindex berechnet.
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight_kg DOUBLE, height_m DOUBLE)
RETURNS DOUBLE
LANGUAGE PYTHON
AS $$
return weight_kg / (height_m ** 2)
$$;
Sie können diese Unity-Katalogfunktion jetzt in Ihren SQL-Abfragen oder PySpark-Code verwenden:
SELECT person_id, my_catalog.my_schema.calculate_bmi(weight_kg, height_m) AS bmi
FROM person_data;
Weitere UDF-Beispiele finden Sie unter Zeilenfilterbeispiele und Spaltenmaskenbeispiele.
Erweitern von UDFs mithilfe von benutzerdefinierten Abhängigkeiten
Wichtig
Dieses Feature befindet sich in der Public Preview.
Erweitern Sie die Funktionalität von Unity Catalog Python UDFs über die Databricks-Runtime-Umgebung hinaus, indem Sie benutzerdefinierte Abhängigkeiten für externe Bibliotheken definieren.
Installieren Sie Abhängigkeiten aus den folgenden Quellen:
- PyPI-Pakete
-
Dateien, die in Unity-Katalogvolumes gespeichert sind Der Benutzer, der die UDF aufruft, muss
READ VOLUMEüber Berechtigungen für das Quellvolume verfügen. - Dateien, die in öffentlichen URLs verfügbar sind Ihre Arbeitsbereichsnetzwerksicherheitsregeln müssen den Zugriff auf öffentliche URLs zulassen.
Hinweis
Informationen zum Konfigurieren von Netzwerksicherheitsregeln für den Zugriff auf öffentliche URLs aus einem serverlosen SQL-Warehouse finden Sie unter Validate with Databricks SQL.
- Serverlose SQL-Lagerhäuser erfordern das Aktivieren des Public Preview-Features Netzwerk für isolierte Workloads in Serverless SQL Warehouses aktivieren auf der Vorschauseite Ihres Arbeitsbereichs, um für benutzerdefinierte Abhängigkeiten auf das Internet zugreifen zu können.
Benutzerdefinierte Abhängigkeiten für Unity Catalog UDFs werden für die folgenden Computetypen unterstützt:
- Serverlose Notizbücher und Jobs
- Allzweck-Compute mit Databricks Runtime Version 16.2 und höher
- Pro oder serverloses SQL Warehouse
Verwenden Sie den ENVIRONMENT Abschnitt der UDF-Definition, um Abhängigkeiten anzugeben:
CREATE OR REPLACE FUNCTION my_catalog.my_schema.mixed_process(data STRING)
RETURNS STRING
LANGUAGE PYTHON
ENVIRONMENT (
dependencies = '["simplejson==3.19.3", "/Volumes/my_catalog/my_schema/my_volume/packages/custom_package-1.0.0.whl", "https://my-bucket.s3.amazonaws.com/packages/special_package-2.0.0.whl?Expires=2043167927&Signature=abcd"]',
environment_version = 'None'
)
AS $$
import simplejson as json
import custom_package
return json.dumps(custom_package.process(data))
$$;
Der ENVIRONMENT Abschnitt enthält die folgenden Felder:
| Feld | BESCHREIBUNG | Typ | Anwendungsbeispiel |
|---|---|---|---|
dependencies |
Eine Liste der zu installierenden kommagetrennten Abhängigkeiten. Jeder Eintrag ist eine Zeichenfolge, die dem Pip Requirements-Dateiformat entspricht. | STRING |
dependencies = '["simplejson==3.19.3", "/Volumes/catalog/schema/volume/packages/my_package-1.0.0.whl"]'dependencies = '["https://my-bucket.s3.amazonaws.com/packages/my_package-2.0.0.whl?Expires=2043167927&Signature=abcd"]' |
environment_version |
Gibt die serverlose Umgebungsversion an, in der die UDF ausgeführt werden soll. Derzeit wird nur der Wert None unterstützt. |
STRING |
environment_version = 'None' |
Verwenden von Unity-Katalog-UDFs in PySpark
from pyspark.sql.functions import expr
result = df.withColumn("bmi", expr("my_catalog.my_schema.calculate_bmi(weight_kg, height_m)"))
display(result)
Upgrade einer sitzungsbezogenen UDF
Hinweis
Syntax und Semantik für Python-UDFs in Unity Catalog unterscheiden sich von Python-UDFs, die für SparkSession registriert sind. Siehe benutzerdefinierte skalare Funktionen – Python.
Angenommen, Sie haben die folgende sitzungsbasierte UDF in einem Azure Databricks-Notebook:
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
@udf(StringType())
def greet(name):
return f"Hello, {name}!"
# Using the session-based UDF
result = df.withColumn("greeting", greet("name"))
result.show()
Um dies als Unity-Katalogfunktion zu registrieren, verwenden Sie wie im folgenden Beispiel eine SQL-Anweisung CREATE FUNCTION :
CREATE OR REPLACE FUNCTION my_catalog.my_schema.greet(name STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
return f"Hello, {name}!"
$$
Teilen von UDFs im Unity-Katalog
Berechtigungen für UDFs werden basierend auf den Zugriffssteuerelementen verwaltet, die auf den Katalog, das Schema oder die Datenbank angewendet werden, in denen die UDF registriert ist. Weitere Informationen finden Sie unter Verwalten von Berechtigungen im Unity-Katalog .
Verwenden Sie die Azure Databricks SQL- oder azure Databricks-Arbeitsbereich-UI, um Einem Benutzer oder einer Gruppe Berechtigungen zu erteilen (empfohlen).
Berechtigungen in der Benutzeroberfläche des Arbeitsbereichs
- Suchen Sie den Katalog und das Schema, in dem Ihre UDF gespeichert ist, und wählen Sie die UDF aus.
- Suchen Sie in den UDF-Einstellungen nach einer Berechtigungsoption . Fügen Sie Benutzer oder Gruppen hinzu, und geben Sie den Typ des Zugriffs an, über den sie verfügen sollen, z. B. EXECUTE oder MANAGE.
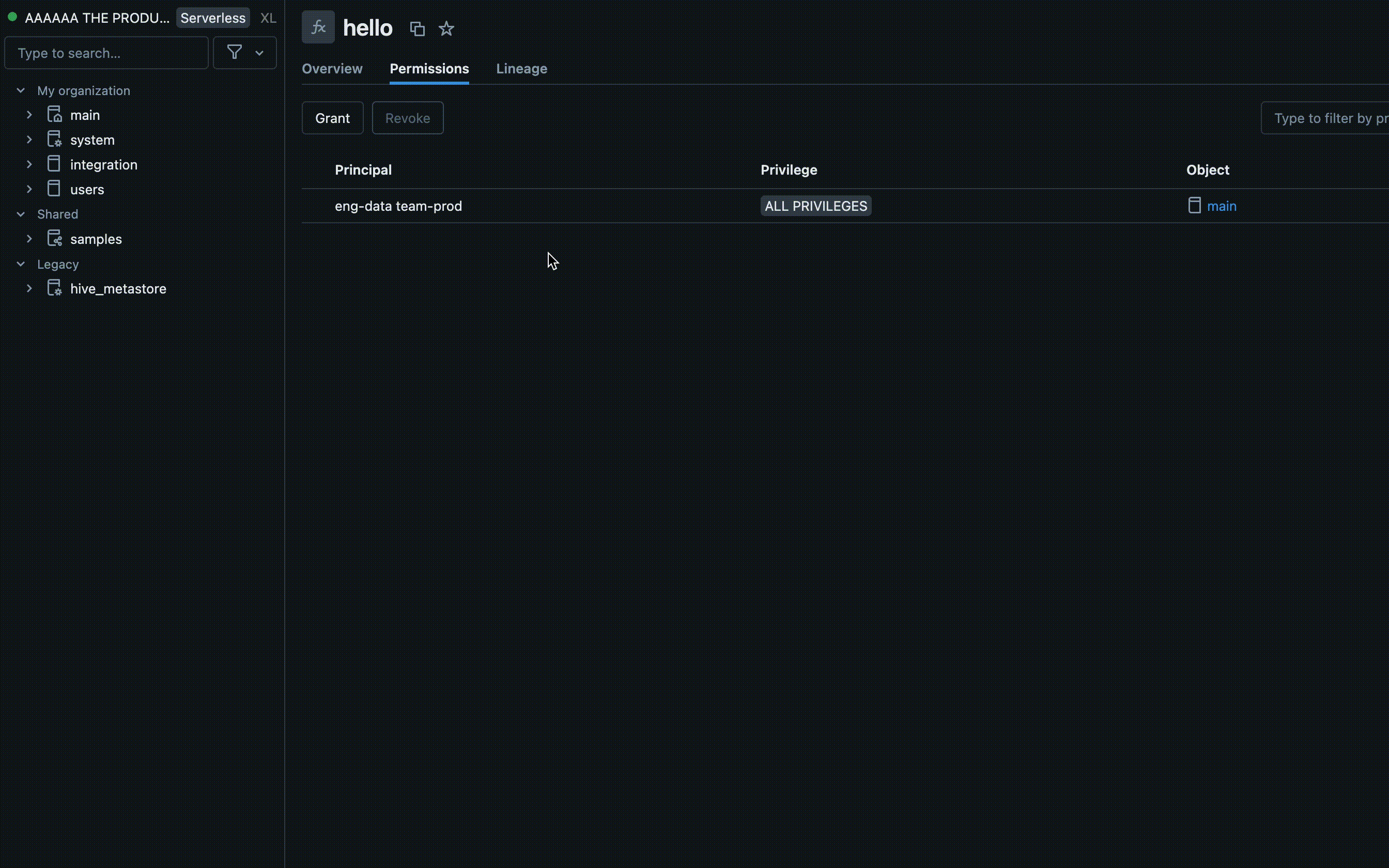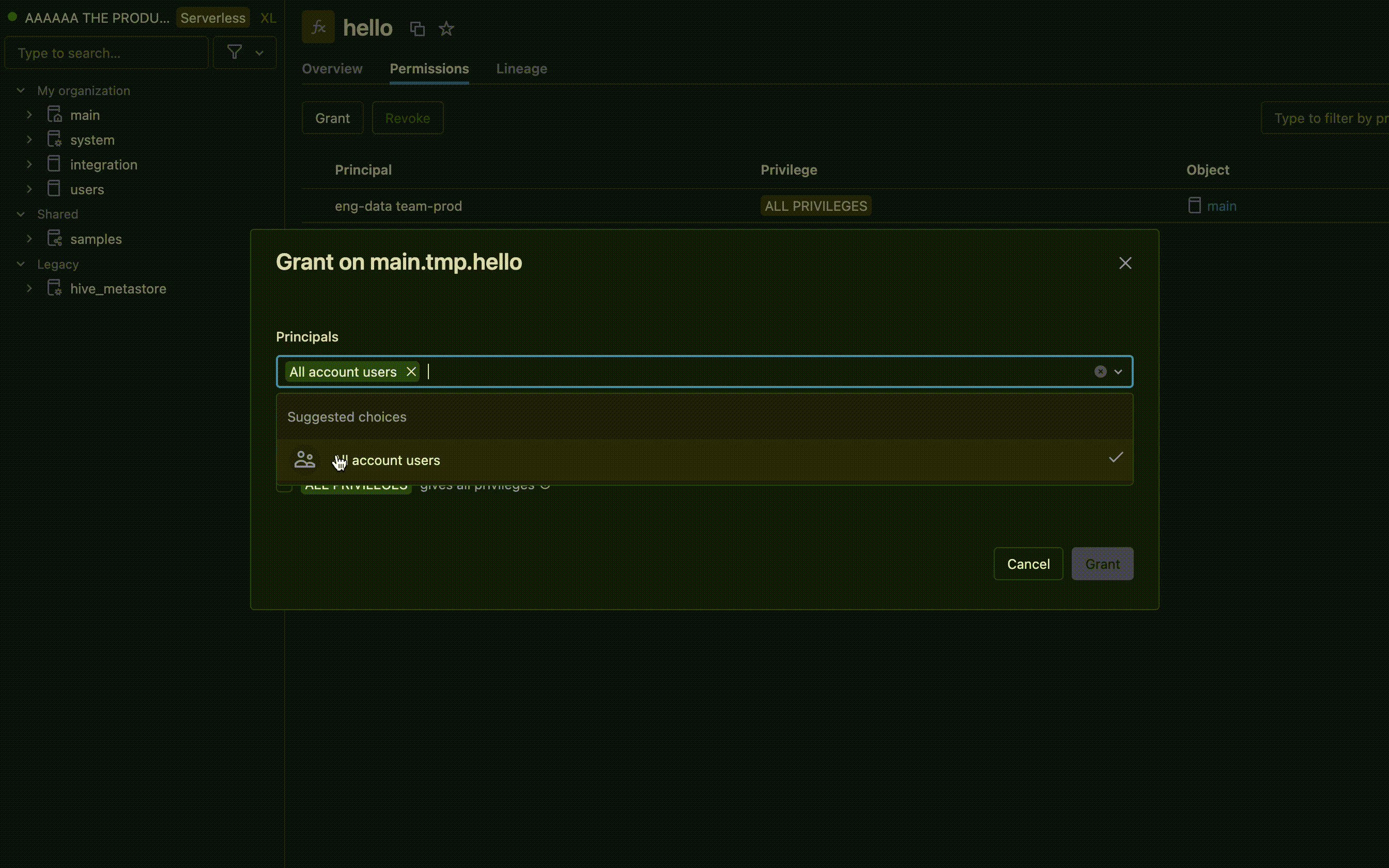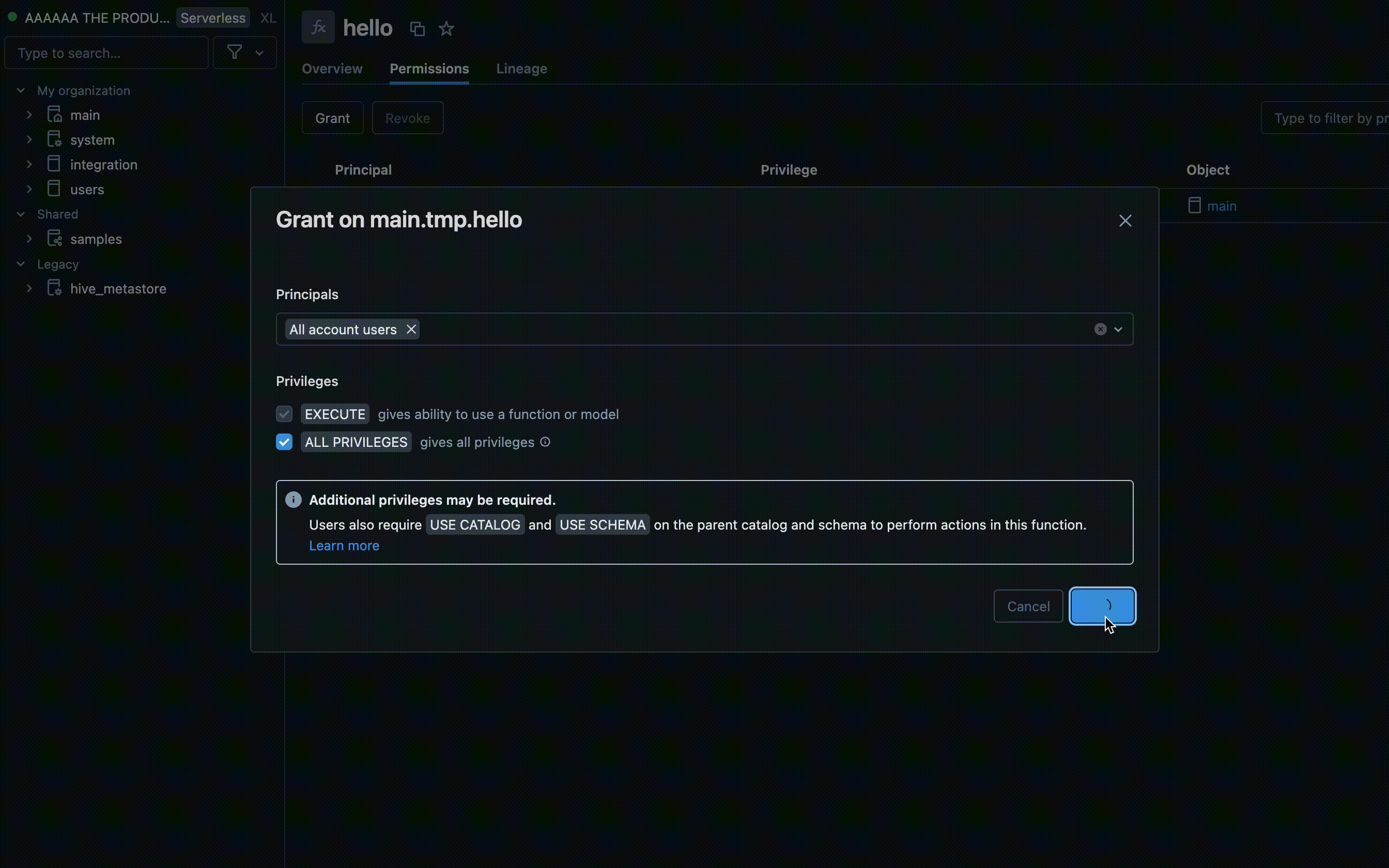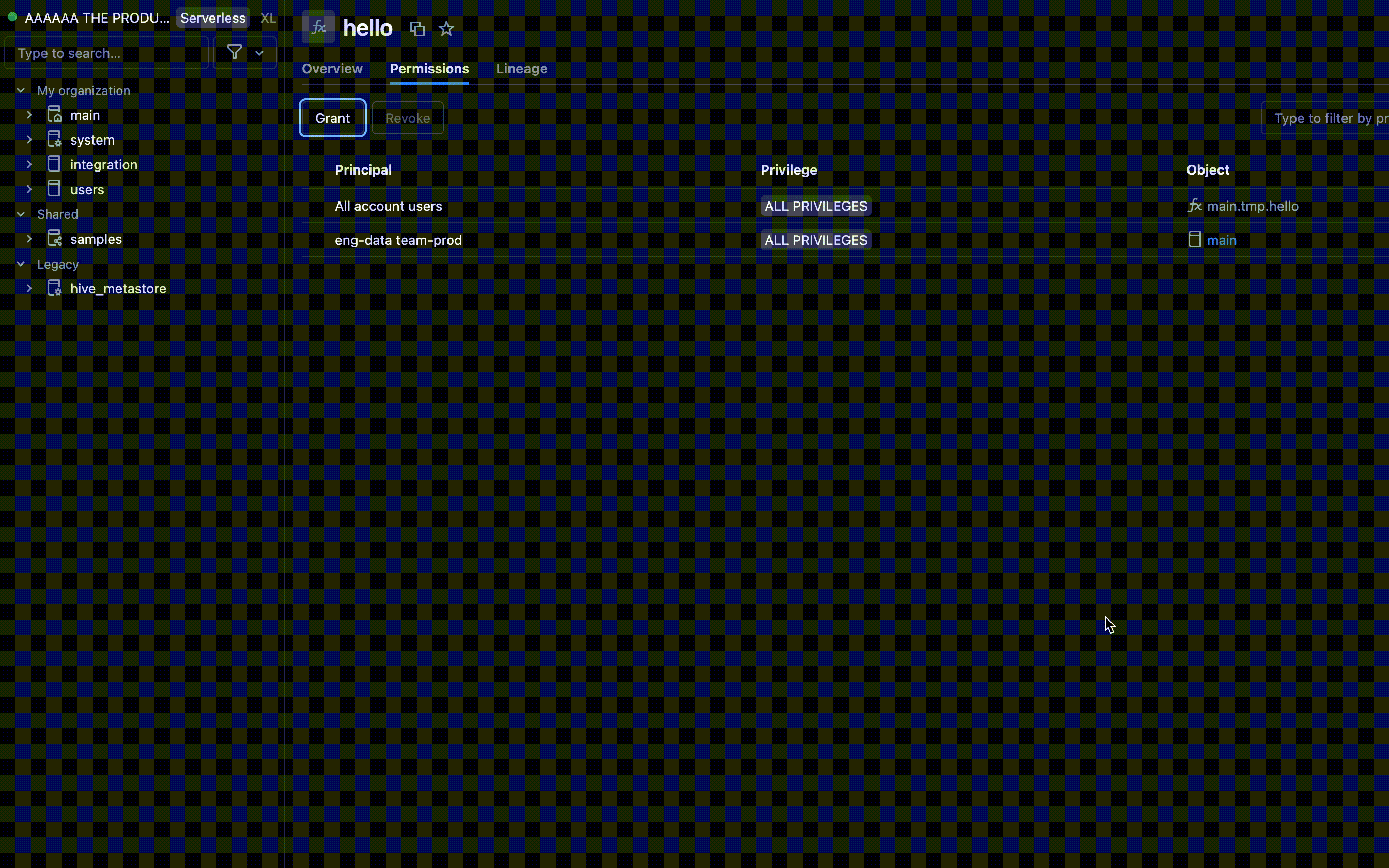
Berechtigungen mit Azure Databricks SQL
Im folgenden Beispiel wird einem Benutzer die EXECUTE-Berechtigung für eine Funktion gewährt:
GRANT EXECUTE ON FUNCTION my_catalog.my_schema.calculate_bmi TO `user@example.com`;
Um Berechtigungen zu entfernen, verwenden Sie den REVOKE Befehl wie im folgenden Beispiel:
REVOKE EXECUTE ON FUNCTION my_catalog.my_schema.calculate_bmi FROM `user@example.com`;
Umgebungsisolation
Hinweis
Isolationsumgebungen im freigegebenen Modus erfordern Databricks Runtime 18.0 und höher. In früheren Versionen werden alle Unity Catalog Python UDFs im strikten Isolationsmodus ausgeführt.
Unity Catalog Python UDFs mit demselben Besitzer und derselben Sitzung können standardmäßig eine Isolationsumgebung verwenden. Dies verbessert die Leistung und verringert die Speicherauslastung, indem die Anzahl der separaten Umgebungen reduziert wird, die gestartet werden müssen.
Strenge Isolierung
Um sicherzustellen, dass eine UDF immer in einer eigenen, vollständig isolierten Umgebung ausgeführt wird, fügen Sie die STRICT ISOLATION Merkmalsklausel hinzu.
Die meisten UDFs benötigen keine strenge Isolierung. Standarddatenverarbeitungs-UDFs profitieren von der standardmäßigen gemeinsamen Isolationsumgebung und können schneller bei geringerer Speichernutzung ausgeführt werden.
Fügen Sie die STRICT ISOLATION Merkmalsklausel zu UDFs hinzu, die:
- Führen Sie Eingaben als Code mithilfe von
eval(),exec()oder ähnlichen Funktionen aus. - Schreiben Sie Dateien in das lokale Dateisystem.
- Ändern sie globale Variablen oder den Systemstatus.
- Zugreifen oder Ändern von Umgebungsvariablen
Der folgende Code zeigt ein Beispiel für eine UDF, die mit STRICT ISOLATION ausgeführt werden sollte. Diese UDF führt beliebigen Python-Code aus, sodass sie den Systemzustand ändern, auf Umgebungsvariablen zugreifen oder in das lokale Dateisystem schreiben kann. Die Verwendung der STRICT ISOLATION Klausel trägt dazu bei, Störungen oder Datenlecks über UDFs hinweg zu verhindern.
CREATE OR REPLACE TEMPORARY FUNCTION run_python_snippet(python_code STRING)
RETURNS STRING
LANGUAGE PYTHON
STRICT ISOLATION
AS $$
import sys
from io import StringIO
# Capture standard output and error streams
captured_output = StringIO()
captured_errors = StringIO()
sys.stdout = captured_output
sys.stderr = captured_errors
try:
# Execute the user-provided Python code in an empty namespace
exec(python_code, {})
except SyntaxError:
# Retry with escaped characters decoded (for cases like "\n")
def decode_code(raw_code):
return raw_code.encode('utf-8').decode('unicode_escape')
python_code = decode_code(python_code)
exec(python_code, {})
# Return everything printed to stdout and stderr
return captured_output.getvalue() + captured_errors.getvalue()
$$
Festlegen DETERMINISTIC , ob Ihre Funktion konsistente Ergebnisse erzeugt
Fügen Sie DETERMINISTIC ihrer Funktionsdefinition hinzu, wenn sie dieselben Ausgaben für die gleichen Eingaben erzeugt. Dadurch können Abfrageoptimierungen die Leistung verbessern.
Standardmäßig wird angenommen, dass Die Python-UDFs des Batch-Unity-Katalogs nicht deterministisch sind, es sei denn, sie werden explizit deklariert. Beispiele für nicht deterministische Funktionen sind das Generieren von Zufallswerten, der Zugriff auf aktuelle Uhrzeiten oder Datumsangaben oder das Tätigen externer API-Aufrufe.
Siehe CREATE FUNCTION (SQL und Python)
UDFs für KI-Agent-Tools
Generative KI-Agents können Unity Catalog UDFs als Tools verwenden, um Aufgaben auszuführen und benutzerdefinierte Logik auszuführen.
Siehe Erstellen von KI-Agent-Tools mithilfe von Unity-Katalogfunktionen.
UDFs für den Zugriff auf externe APIs
Sie können UDFs verwenden, um über SQL auf externe APIs zuzugreifen. Im folgenden Beispiel wird die Python-Bibliothek requests verwendet, um eine HTTP-Anforderung zu erstellen.
Hinweis
Python-UDFs ermöglichen TCP/UDP-Netzwerkdatenverkehr über die Ports 80, 443 und 53 bei Verwendung von serverlosem Computing oder von Compute-Konfigurationen im Standardzugriffsmodus.
CREATE FUNCTION my_catalog.my_schema.get_food_calories(food_name STRING)
RETURNS DOUBLE
LANGUAGE PYTHON
AS $$
import requests
api_url = f"https://example-food-api.com/nutrition?food={food_name}"
response = requests.get(api_url)
if response.status_code == 200:
data = response.json()
# Assume the API returns a JSON object with a 'calories' field
calories = data.get('calories', 0)
return calories
else:
return None # API request failed
$$;
UDFs für Sicherheit und Compliance
Verwenden Sie Python UDFs, um benutzerdefinierte Tokenisierung, Datenmasken, Daten redaction oder Verschlüsselungsmechanismen zu implementieren.
Im folgenden Beispiel wird die Identität einer E-Mail-Adresse maskiert, während Länge und Domäne beibehalten werden:
CREATE OR REPLACE FUNCTION my_catalog.my_schema.mask_email(email STRING)
RETURNS STRING
LANGUAGE PYTHON
DETERMINISTIC
AS $$
parts = email.split('@', 1)
if len(parts) == 2:
username, domain = parts
else:
return None
masked_username = username[0] + '*' * (len(username) - 2) + username[-1]
return f"{masked_username}@{domain}"
$$
Im folgenden Beispiel wird diese UDF in einer dynamischen Ansichtsdefinition angewendet:
-- First, create the view
CREATE OR REPLACE VIEW my_catalog.my_schema.masked_customer_view AS
SELECT
id,
name,
my_catalog.my_schema.mask_email(email) AS masked_email
FROM my_catalog.my_schema.customer_data;
-- Now you can query the view
SELECT * FROM my_catalog.my_schema.masked_customer_view;
+---+------------+------------------------+------------------------+
| id| name| email| masked_email |
+---+------------+------------------------+------------------------+
| 1| John Doe| john.doe@example.com | j*******e@example.com |
| 2| Alice Smith|alice.smith@company.com |a**********h@company.com|
| 3| Bob Jones| bob.jones@email.org | b********s@email.org |
+---+------------+------------------------+------------------------+
Bewährte Methoden
Damit UDFs für alle Benutzer zugänglich sind, empfehlen wir das Erstellen eines dedizierten Katalogs und Schemas mit entsprechenden Zugriffssteuerungen.
Verwenden Sie für teamspezifische UDFs ein dediziertes Schema im Teamkatalog für Speicher und Verwaltung.
Databricks empfiehlt Ihnen, die folgenden Informationen in den UDF-Dokstring einzubeziehen:
- Die aktuelle Versionsnummer
- Ein Änderungsprotokoll zum Nachverfolgen von Änderungen in allen Versionen
- Zweck, Parameter und Rückgabewert der UDF
- Ein Beispiel für die Verwendung der UDF
Nachfolgend wird ein Beispiel für eine UDF mit den folgenden bewährten Methoden angezeigt:
CREATE OR REPLACE FUNCTION my_catalog.my_schema.calculate_bmi(weight_kg DOUBLE, height_m DOUBLE)
RETURNS DOUBLE
COMMENT "Calculates Body Mass Index (BMI) from weight and height."
LANGUAGE PYTHON
DETERMINISTIC
AS $$
"""
Parameters:
calculate_bmi (version 1.2):
- weight_kg (float): Weight of the individual in kilograms.
- height_m (float): Height of the individual in meters.
Returns:
- float: The calculated BMI.
Example Usage:
SELECT calculate_bmi(weight, height) AS bmi FROM person_data;
Change Log:
- 1.0: Initial version.
- 1.1: Improved error handling for zero or negative height values.
- 1.2: Optimized calculation for performance.
Note: BMI is calculated as weight in kilograms divided by the square of height in meters.
"""
if height_m <= 0:
return None # Avoid division by zero and ensure height is positive
return weight_kg / (height_m ** 2)
$$;
Timestamp-Zeitzonenverhalten für Eingaben
Wenn in Databricks Runtime 18.0 und höher TIMESTAMP-Werte an Python-UDFs übergeben werden, bleiben die Werte in UTC, aber die Zeitzonenmetadaten (Attribut tzinfo) sind im datetime-Objekt nicht enthalten.
Diese Änderung vereinheitlicht Unity Catalog Python-UDFs mit Arrow-optimierten Python-UDFs in Apache Spark.
Beispielsweise in der folgenden Abfrage:
CREATE FUNCTION timezone_udf(date TIMESTAMP)
RETURNS STRING
LANGUAGE PYTHON
AS $$
return f"{type(date)} {date} {date.tzinfo}"
$$;
SELECT timezone_udf(TIMESTAMP '2024-10-23 10:30:00');
Diese Ausgabe wurde zuvor in Databricks-Runtime-Versionen vor 18.0 erstellt:
<class 'datetime.datetime'> 2024-10-23 10:30:00+00:00 Etc/UTC
In Databricks Runtime 18.0 und höher erzeugt sie nun diese Ausgabe:
<class 'datetime.datetime'> 2024-10-23 10:30:00+00:00 None
Wenn Ihre UDF auf die Zeitzoneninformationen angewiesen ist, müssen Sie sie explizit wiederherstellen:
from datetime import timezone
date = date.replace(tzinfo=timezone.utc)
Begrenzungen
- Sie können eine beliebige Anzahl von Python-Funktionen innerhalb einer Python-UDF definieren, aber alle müssen einen skalaren Wert zurückgeben.
- Python-Funktionen müssen NULL-Werte unabhängig verarbeiten, und alle Typzuordnungen müssen Azure Databricks SQL-Sprachzuordnungen folgen.
- Wenn kein Katalog oder Schema angegeben ist, werden Python-UDFs für das aktuelle aktive Schema registriert.
- Python-UDFs werden in einer sicheren, isolierten Umgebung ausgeführt und haben keinen Zugriff auf Dateisysteme oder interne Dienste.
- Sie können nicht mehr als fünf benutzerdefinierte Funktionen (UDFs) pro Abfrage aufrufen.