Konzepte für die Erfassung durch CSV-Parser
Eine CSV-Datei (Comma-Separated Values) ist eine durch Trennzeichen getrennte Textdatei, die zum Speichern von Daten in einem strukturierten Tabellenformat verwendet wird.
Der gerichtete azyklische Graph eines CSV-Parsers ermöglicht es einem Kunden, Daten basierend auf einem benutzerdefinierten Schema in eine Microsoft Azure Data Manager for Energy-Instanz zu laden, bei dem es sich um ein Schema handelt, das nicht mit dem OSDU® Well Known Schema übereinstimmt. Kunden müssen das benutzerdefinierte Schema mithilfe des Schemadiensts erstellen und registrieren, bevor die Daten geladen werden.
Der gerichtete azyklische Graph eines CSV-Parsers implementiert einen ELT-Ansatz (Extrahieren, Laden und Transformieren) für das Laden von Daten, d. h. Daten werden zuerst aus dem Quellsystem in einem CSV-Format extrahiert und in die Azure Data Manager for Energy-Instanz geladen. Anschließend könnten sie mithilfe eines Mappingdiensts in das OSDU® Well Known Schema transformiert werden.
Was tut die CSV-Erfassung?
Der gerichtete azyklische Graph eines CSV-Parsers ermöglicht es den Kunden, die CSV-Daten in die Microsoft Azure Data Manager for Energy-Instanz zu laden. Er parst jede Zeile einer CSV-Datei und erstellt einen Speichermetadatensatz. Er führt schema validation aus, um sicherzustellen, dass die CSV-Daten dem registrierten benutzerdefinierten Schema entsprechen. Er führt automatisch type coercion für die Spalten basierend auf der Schemadatentypdefinition aus. Er generiert unique id für jede Zeile des CSV-Datensatzes, indem Quelle, Entitätstyp und eine Base64-codierte Zeichenfolge kombiniert werden, die durch Verketten von natürlichen Schlüsseln in den Daten gebildet wird. Er führt unit conversion durch, indem er deklarierte Verweisrahmeninformationen mithilfe des Einheitsdiensts in den entsprechenden dauerhaften Verweis konvertiert. Er führt CRS conversion für Spalten mit räumlichem Bezug basierend auf den im Schema vorhandenen Verweisrahmeninformationen (Frame of Reference, FoR) durch. Er erstellt relationships-Metadaten, wie im Quellschema deklariert. Schließlich persists er den Metadatensatz mithilfe des Speicherdiensts.
Komponenten der Erfassung durch CSV-Parser
Der Workflow des gerichteten azyklischen Graphen eines CSV-Parsers besteht aus den folgenden Diensten:
- Der Dateidienst unterstützt die Verwaltung von Dateien in der Azure Data Manager for Energy-Instanz. Er ermöglicht es Benutzern, Dateien von der Datenplattform sicher hochzuladen, zu ermitteln und herunterzuladen.
- Der Schemadienst unterstützt die Verwaltung von Schemas in der Azure Data Manager for Energy-Instanz. Er ermöglicht es Benutzern, Schemas auf der Datenplattform zu erstellen, abzurufen und zu suchen.
- Der Speicherdienst unterstützt die Speicherung von Metadateninformationen für Domänenentitäten, die auf der Datenplattform erfasst werden. Er löst außerdem Änderungsereignisse für Speicherdatensätze aus, die nachgelagerten Diensten das Ausführen von Vorgängen für erfasste Metadatensätze ermöglichen.
- Der Einheitsdienst unterstützt die Verwaltung und Konvertierung von Einheiten.
- Der Workflowdienst unterstützt die Verwaltung von Workflows in der Azure Data Manager for Energy-Instanz. Er ist ein Wrapperdienst auf Basis des Airflow-Orchestrierungsmoduls.
Diagramm der Komponenten für die CSV-Erfassung
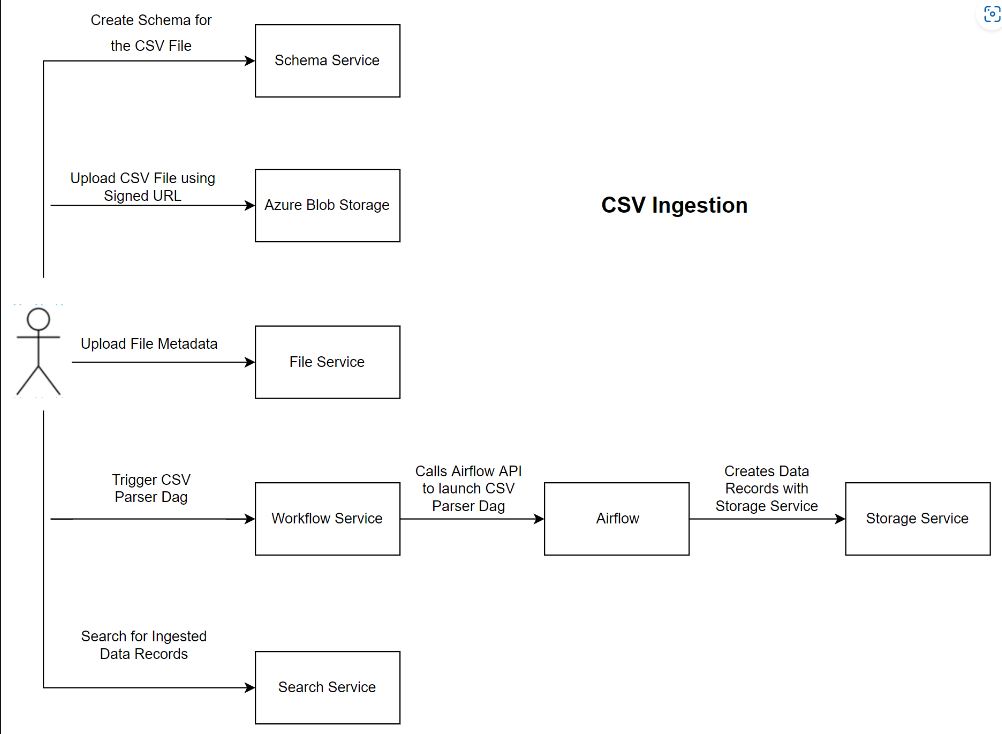
Workflow zur Erfassung durch den CSV-Parser
Um den Workflow des gerichteten azyklischen Graphen eines CSV-Parsers auszuführen, müssen Benutzer über ein gültiges Autorisierungstoken und entsprechenden Zugriff auf die folgenden Dienste verfügen: Such-, Speicher-, Schema-, Datei-, Berechtigungs-, Rechts- und Workflowdienst.
Das folgende Workflowdiagramm veranschaulicht den Workflow des gerichteten azyklischen Graphen eines CSV-Parsers: 
Um den Workflow des gerichteten azyklischen Graphen eines CSV-Parsers auszuführen, müssen Benutzer zuerst das Schema mithilfe des Workflowdiensts erstellen und registrieren. Nachdem das Schema erstellt wurde, verwendet der Benutzer dann den Dateidienst, um die CSV-Datei in die Microsoft Azure Data Manager for Energy-Instanzen hochzuladen, und erstellt außerdem den Speicherdatensatz des generischen Dateityps. Der Dateidienst stellt Benutzern dann eine Datei-ID bereit, die beim Auslösen des CSV-Parserworkflows mithilfe des Workflowdiensts verwendet wird. Der Workflowdienst stellt eine Ausführungs-ID bereit, mit der Benutzer den Ausführungsstatus des CSV-Parserworkflows nachverfolgen können.
OSDU® ist eine Marke von The Open Group.
Nächste Schritte
Wechseln Sie zum CSV-Parser-Tutorial, und erfahren Sie, wie Sie eine Erfassung durch CSV-Parser ausführen.