Erstellen eines Apache Flink-Clusters® in HDInsight auf AKS mit Azure-Portal
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bedingungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight in AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
Führen Sie die folgenden Schritte aus, um einen Apache Flink-Cluster im Azure-Portal zu erstellen.
Voraussetzungen
Erfüllen Sie die Voraussetzungen in den folgenden Abschnitten:
Wichtig
- Um einen Cluster in einem neuen Clusterpool zu erstellen, weisen Sie der MSI des AKS-Agentpools die Rolle „Operator für verwaltete Identität“ für die benutzerseitig zugewiesene verwaltete Identität zu, die im Rahmen der Ressourcenvoraussetzungen erstellt wurde. Falls Sie über erforderliche Berechtigungen verfügen, wird dieser Schritt während der Erstellung automatisiert.
- Die verwaltete Identität des AKS-Agentpools wird während der Erstellung des Clusterpools erstellt. Sie können die verwaltete Identität des AKS-Agentpools anhand von (Ihr Clusterpoolname)-agentpool ermitteln. Führen Sie zum Zuweisen der Rolle diese Schritte aus.
Erstellen eines Apache Flink-Clusters
Flink-Cluster können erstellt werden, nachdem die Bereitstellung eines Clusterpools abgeschlossen wurde. Sehen wir uns die Schritte für den Fall an, dass Sie mit einem vorhandenen Clusterpool beginnen.
Geben Sie im Azure-Portal HDInsight-Clusterpools/HDInsight/HDInsight on AKS ein, und wählen Sie Azure HDInsight on AKS-Clusterpools aus, um zur Seite „Clusterpools“ zu navigieren. Wählen Sie auf der Seite „HDInsight on AKS-Clusterpools“ den Clusterpool aus, in dem Sie einen neuen Flink-Cluster erstellen möchten.

Klicken Sie auf der Seite für einen bestimmten Clusterpool auf + Neuer Cluster, und geben Sie die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Subscription Dieses Feld wird automatisch mit dem Azure-Abonnement aufgefüllt, das für den Clusterpool registriert wurde. Ressourcengruppe Dieses Feld wird automatisch aufgefüllt und zeigt die Ressourcengruppe im Clusterpool an. Region Dieses Feld wird automatisch aufgefüllt und zeigt die für den Clusterpool ausgewählte Ressourcengruppe an. Clusterpool Dieses Feld wird automatisch aufgefüllt und zeigt den Namen des Clusterpools an, in dem der Cluster jetzt erstellt wird. Um einen Cluster in einem anderen Pool zu erstellen, suchen Sie diesen Clusterpool im Portal, und klicken Sie auf + Neuer Cluster. Version des HDInsight on AKS-Pools Dieses Feld wird automatisch aufgefüllt und zeigt die Version des Clusterpools an, mit der der Cluster jetzt erstellt wird. HDInsight on AKS-Version Wählen Sie die Neben- oder Patchversion der HDInsight on AKS-Version des neuen Clusters aus. Clustertyp Wählen Sie in der Dropdownliste „Flink“ aus. Clustername Geben Sie den Namen des neuen Clusters ein. Benutzerseitig zugewiesene verwaltete Identität Wählen Sie in der Dropdownliste die verwaltete Identität aus, die mit dem Cluster verwendet werden soll. Wenn Sie der Besitzer oder die Besitzerin der verwalteten Dienstidentität (Managed Service Identity, MSI) sind und die MSI nicht über die Rolle „Operator für verwaltete Identität“ im Cluster verfügt, klicken Sie auf den Link unterhalb des Felds, um die für die MSI des AKS-Agentpools erforderliche Berechtigung zuzuweisen. Wenn die MSI bereits über die richtigen Berechtigungen verfügt, wird kein Link angezeigt. Weitere Rollenzuweisungen, die für die MSI erforderlich sind, finden Sie unter Voraussetzungen. Speicherkonto Wählen Sie in der Dropdownliste das Speicherkonto aus, das dem Flink-Cluster zugeordnet werden soll, und geben Sie den Containernamen an. Der verwalteten Identität wird außerdem mithilfe der Rolle „Besitzer von Speicherblobdaten“ Zugriff auf das angegebene Speicherkonto gewährt. Virtuelles Netzwerk Das virtuelle Netzwerk für den Cluster. Subnet Das virtuelle Subnetz für den Cluster. Aktivieren des Hive-Katalogs für Flink SQL
Eigenschaft Beschreibung Hive-Katalog verwenden Aktivieren Sie diese Option, um einen externen Hive-Metastore zu verwenden. SQL-Datenbank für Hive Wählen Sie in der Dropdownliste die SQL-Datenbank-Instanz aus, in der Hive-Metastore-Tabellen hinzugefügt werden sollen. SQL-Administratorbenutzername Geben Sie den SQL Server-Administratorbenutzernamen ein. Dieses Konto wird vom Metastore verwendet, um mit SQL-Datenbank zu kommunizieren. Key Vault (Schlüsseltresor) Wählen Sie in der Dropdownliste die Key Vault-Instanz aus, die ein Geheimnis mit Kennwort für den SQL Server-Administratorbenutzernamen enthält. Sie müssen eine Zugriffsrichtlinie mit allen erforderlichen Berechtigungen wie Schlüsselberechtigungen, Geheimnisberechtigungen und Zertifikatberechtigungen für die MSI einrichten, die für die Clustererstellung verwendet wird. Die MSI benötigt eine Key Vault-Administratorrolle. Fügen Sie die erforderlichen Berechtigungen mithilfe von IAM hinzu. Name des geheimen SQL-Kennworts Geben Sie den Geheimnisnamen aus der Key Vault-Instanz ein, in der das Kennwort für SQL-Datenbank gespeichert ist. 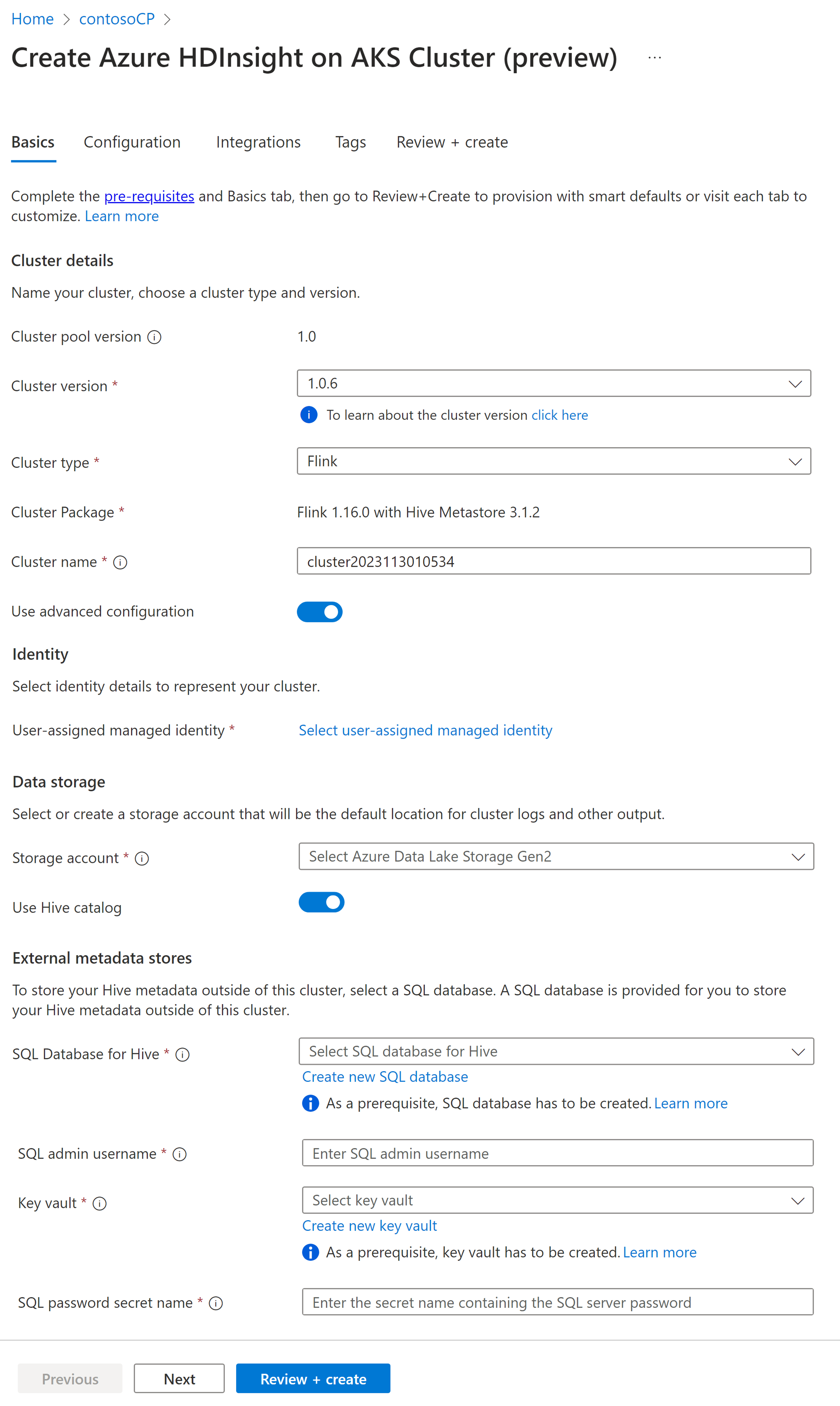
Hinweis
Standardmäßig verwenden wir für den Hive-Katalog dasselbe Speicherkonto und denselben Container, die auch bei der Clustererstellung verwendet wurden.
Klicken Sie auf Weiter: Konfiguration, um fortzufahren.
Geben Sie auf der Seite Konfiguration die folgenden Informationen ein:
Eigenschaft Beschreibung Knotengröße Wählen Sie die Knotengröße aus, die für die Haupt- und Workerknoten der Flink-Knoten verwendet werden soll. Anzahl von Knoten Wählen Sie die Anzahl der Knoten für den Flink-Cluster aus. Standardmäßig sind zwei Hauptknoten festgelegt. Die Größe der Workerknoten hilft bei der Ermittlung der Task-Manager-Konfigurationen für Flink. Der Auftrags-Manager und der Verlaufsserver befinden sich auf Hauptknoten. Geben Sie im Abschnitt Serverkonfiguration die folgenden Informationen ein:
Eigenschaft Beschreibung Task-Manager-CPU Integer. Geben Sie die Größe der Task-Manager-CPUs (in Kernen) ein. Task-Manager-Speicher in MB Geben Sie die Größe des Task-Manager-Speichers in MB ein. Mind. 1.800 MB Auftrags-Manager-CPU Integer. Geben Sie die Anzahl der CPUs für den Auftrags-Manager (in Kernen) ein. Speicher des Auftrags-Managers in MB Geben Sie die Speichergröße in MB an. Mind. 1.800 MB Verlaufsserver-CPU Integer. Geben Sie die Anzahl der CPUs für den Auftrags-Manager (in Kernen) ein. Verlaufsserverspeicher in MB Geben Sie die Speichergröße in MB an. Mind. 1.800 MB 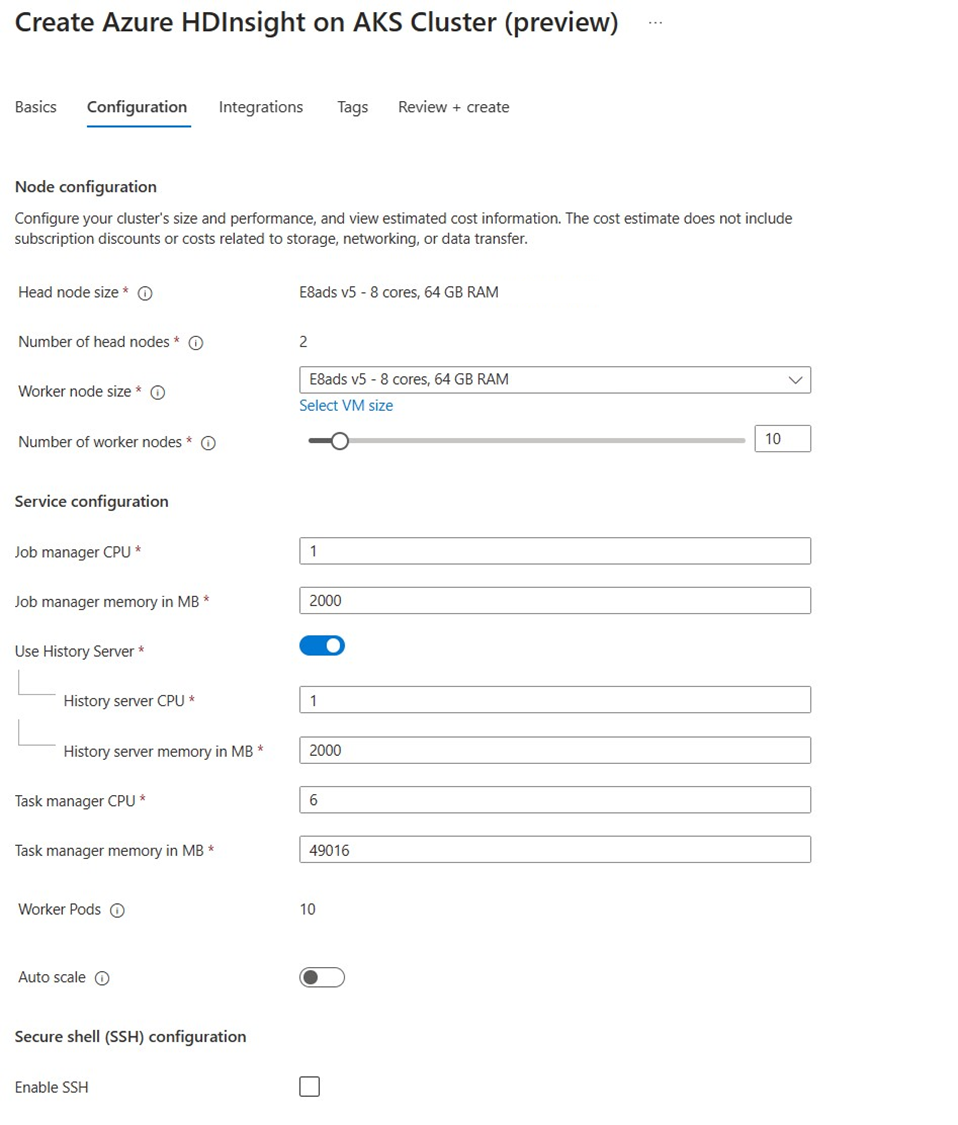
Hinweis
- Der Verlaufsserver kann bei Bedarf aktiviert/deaktiviert werden.
- Die zeitplanbasierte Autoskalierung wird in Flink unterstützt. Sie können die Anzahl der Workerknoten nach Bedarf planen. Beispielsweise wird eine zeitplanbasierte Autoskalierung mit einer Standardanzahl von drei Workerknoten aktiviert. An Wochentagen von 9:00 Uhr UTC bis 20:00 Uhr UTC werden zehn Workerknoten geplant. Später am Tag muss die Anzahl standardmäßig auf drei Knoten festgelegt werden ( zwischen 20:00 Uhr UTC und 09:00 Uhr UTC am nächsten Tag). Am Wochenende sind von 9:00 Uhr UTC bis 20:00 Uhr UTC vier Workerknoten festgelegt.
Aktualisieren Sie im Abschnitt Autoskalierung und SSH Folgendes:
Eigenschaft Beschreibung Automatische Skalierung Bei der Auswahl können Sie die zeitplanbasierte Autoskalierung auswählen, um den Zeitplan für Skalierungsvorgänge zu konfigurieren. Aktivieren von SSH Bei der Auswahl können Sie die Gesamtanzahl der erforderlichen SSH-Knoten festlegen, bei denen es sich um die Zugriffspunkte für die Flink CLI mit Secure Shell handelt. Die maximal zulässige Anzahl von SSH-Knoten beträgt 5. 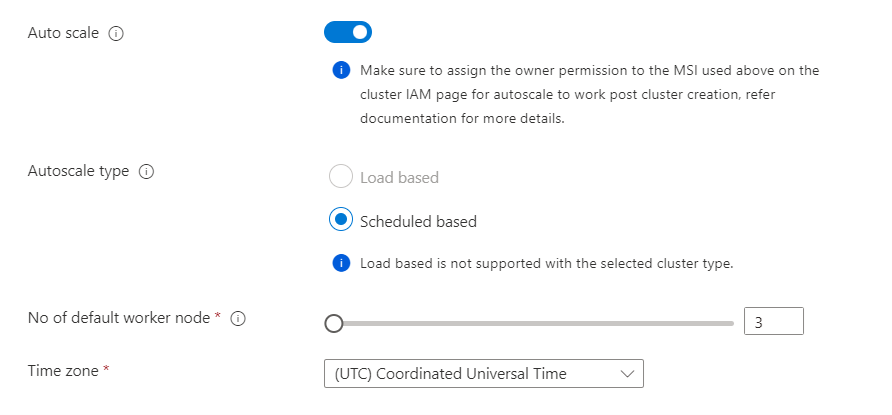

Klicken Sie auf die Schaltfläche Weiter: Integration, um auf der nächsten Seite fortzufahren.
Geben Sie auf der Seite Integration die folgenden Informationen ein:
Eigenschaft Beschreibung Log Analytics Dieses Feature ist nur verfügbar, wenn dem Clusterpool ein Log Analytics-Arbeitsbereich zugeordnet ist. Nach der Aktivierung können die Protokolle, die erfasst werden sollen, ausgewählt werden. Azure Prometheus Dieses Feature dient dazu, Erkenntnisse und Protokolle direkt im Cluster anzuzeigen, indem Sie Metriken und Protokolle an einen Azure Monitor-Arbeitsbereich senden. 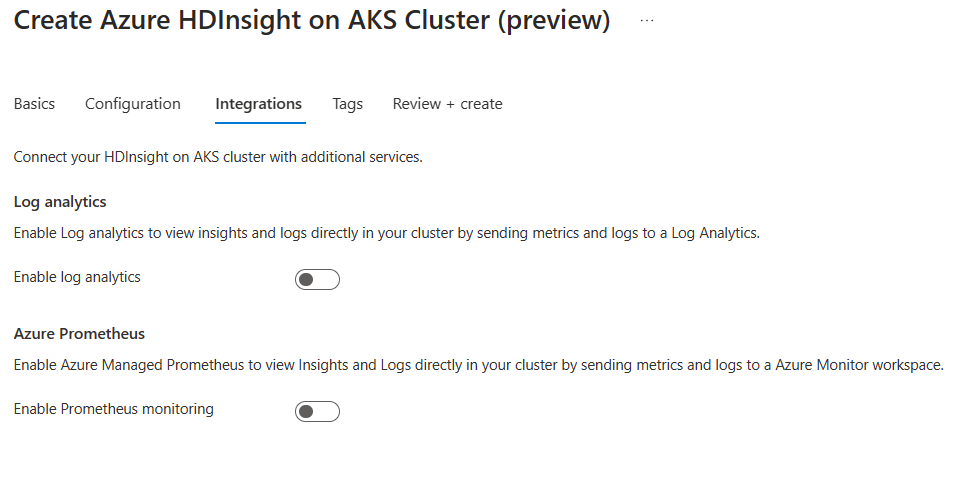
Klicken Sie auf die Schaltfläche Weiter: Tags, um auf der nächsten Seite fortzufahren.
Geben Sie auf der Seite Tags die folgenden Informationen ein:
Eigenschaft Beschreibung Name Optional. Geben Sie einen Namen wie „HDInsight on AKS“ ein, um einfach alle Ressourcen zu identifizieren, die Ihren Clusterressourcen zugeordnet sind. Wert Kann leer bleiben. Ressource Wählen Sie „Alle Ressourcen ausgewählt“ aus. Wählen Sie zum Fortfahren Next. Review + create (Weiter: Überprüfen + erstellen) aus.
Suchen Sie auf der Seite Überprüfen + erstellen nach der Meldung Validierung erfolgreich oben auf der Seite, und klicken Sie dann auf Erstellen.
Die Seite Bereitstellung wird gerade durchgeführt. wird mit dem Cluster angezeigt, der gerade erstellt wird. Die Erstellung des Clusters dauert fünf bis zehn Minuten. Nachdem der Cluster erstellt wurde, wird die Meldung Ihre Bereitstellung wurde abgeschlossen. angezeigt. Wenn Sie von der Seite weg navigieren, können Sie Ihre Benachrichtigungen auf den aktuellen Status überprüfen.
Hinweis
Apache, Apache Flink, Flink und zugehörige Open Source-Projektnamen sind Handelsmarken der Apache Software Foundation (ASF).