Übermitteln und Verwalten von Aufträgen auf einem Apache Spark-Cluster™ in HDInsight auf AKS
Wichtig
Azure HDInsight auf AKS wurde am 31. Januar 2025 eingestellt. Erfahren Sie mehr in dieser Ankündigung.
Sie müssen Ihre Workloads zu Microsoft Fabric oder ein gleichwertiges Azure-Produkt migrieren, um eine abrupte Beendigung Ihrer Workloads zu vermeiden.
Wichtig
Dieses Feature befindet sich derzeit in der Vorschau. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure Previews weitere rechtliche Bestimmungen enthalten, die für Azure-Features gelten, die in der Betaversion, in der Vorschau oder auf andere Weise noch nicht in die allgemeine Verfügbarkeit veröffentlicht werden. Informationen zu dieser spezifischen Vorschau finden Sie unter Azure HDInsight auf AKS-Vorschauinformationen. Für Fragen oder Funktionsvorschläge reichen Sie bitte eine Anfrage ein auf AskHDInsight mit den Details und folgen Sie uns, um weitere Updates zur Azure HDInsight Communityzu erhalten.
Nachdem der Cluster erstellt wurde, kann der Benutzer verschiedene Schnittstellen verwenden, um Aufträge zu übermitteln und zu verwalten.
- Verwenden von Jupyter
- Verwendung von Zeppelin
- Verwendung von SSH (spark-submit)
Verwenden von Jupyter
Voraussetzungen
Ein Apache Spark-Cluster™ auf HDInsight auf AKS. Weitere Informationen finden Sie unter Erstellen eines Apache Spark-Clusters.
Jupyter Notebook ist eine interaktive Notizbuchumgebung, die verschiedene Programmiersprachen unterstützt.
Erstellen eines Jupyter-Notizbuchs
Navigieren Sie zur Apache Spark-Clusterseite™, und öffnen Sie die Registerkarte Übersicht. Klicken Sie auf Jupyter, sie fordert Sie auf, sich zu authentifizieren und die Jupyter-Webseite zu öffnen.

Wählen Sie auf der Jupyter-Webseite "Neu" > PySpark aus, um ein Notizbuch zu erstellen.
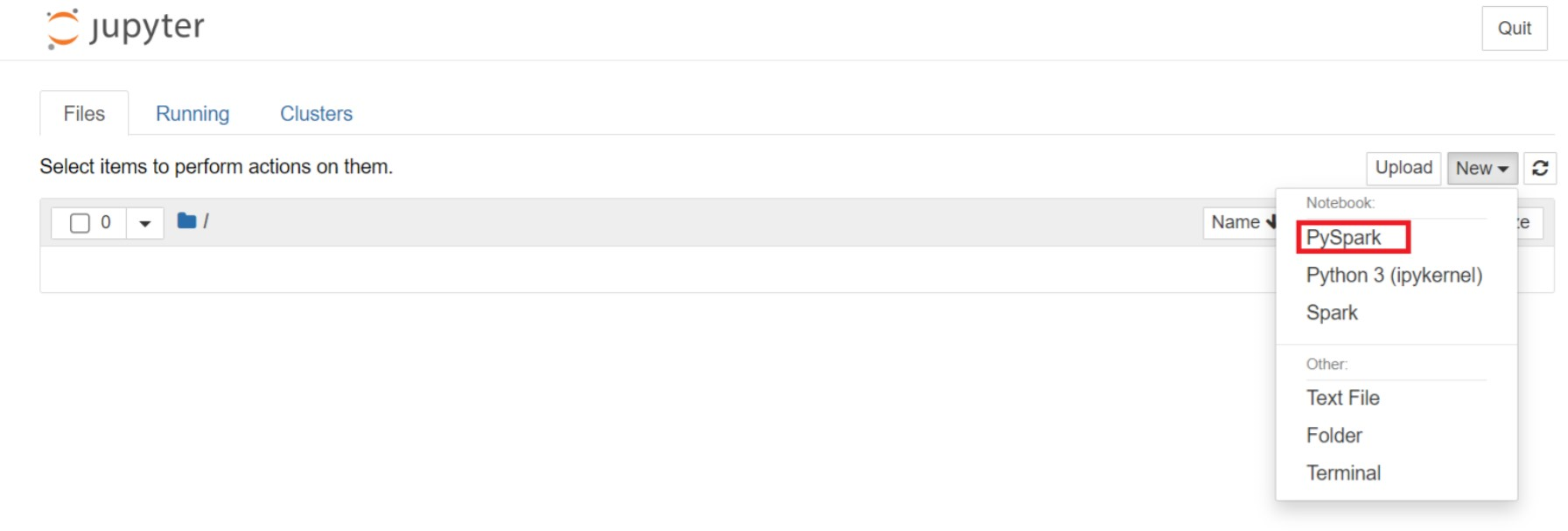
Ein neues Notizbuch mit dem Namen
Untitled(Untitled.ipynb)wurde erstellt und geöffnet.Anmerkung
Mithilfe des PySpark- oder Python 3-Kernels zum Erstellen eines Notizbuchs wird die Spark-Sitzung automatisch für Sie erstellt, wenn Sie die erste Codezelle ausführen. Sie müssen die Sitzung nicht explizit erstellen.
Fügen Sie den folgenden Code in eine leere Zelle des Jupyter-Notizbuchs ein, und drücken Sie dann UMSCHALT+EINGABETASTE, um den Code auszuführen. Weitere Steuerelemente für Jupyter finden Sie hier .
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Zeichnen eines Diagramms mit Gehalt und Alter als X- und Y-Achse
Fügen Sie im selben Notizbuch den folgenden Code in eine leere Zelle des Jupyter-Notizbuchs ein, und drücken Sie dann UMSCHALT+EINGABETASTE, um den Code auszuführen.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()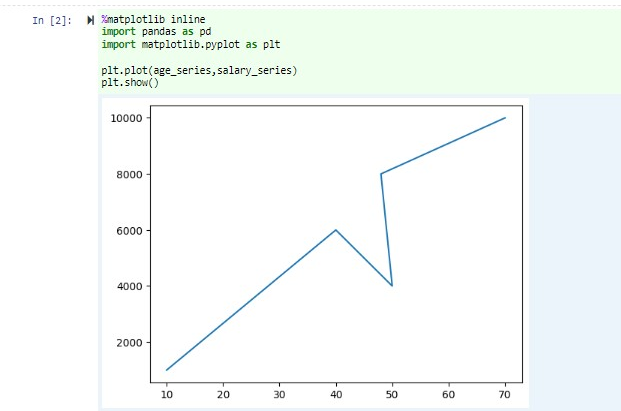




Speichern des Notizbuchs
Navigieren Sie in der Menüleiste des Notizbuchs zu "Datei" > "Speichern und Prüfpunkt".
Schließen Sie das Notizbuch, um die Clusterressourcen freizugeben: Navigieren Sie in der Menüleiste des Notizbuchs zu "Datei" > "Schließen und Beenden". Sie können auch alle Notizbücher unter dem Beispielordner ausführen.


Verwenden von Apache Zeppelin-Notizbüchern
Apache Spark Cluster in HDInsight auf AKS umfassen Apache Zeppelin-Notebooks. Verwenden Sie die Notizbücher, um Apache Spark-Aufträge auszuführen. In diesem Artikel erfahren Sie, wie Sie das Zeppelin-Notizbuch auf einem HDInsight-Cluster auf AKS verwenden.
Voraussetzungen
Ein Apache Spark-Cluster auf HDInsight auf AKS. Anweisungen finden Sie unter Erstellen eines Apache Spark-Clusters.
Starten eines Apache Zeppelin-Notizbuchs
Navigieren Sie zur Seite "Apache Spark-Clusterübersicht" und wählen Sie "Zeppelin-Notizbuch" aus den Cluster-Dashboards aus. Er fordert auf, sich zu authentifizieren und die Seite "Zeppelin" zu öffnen.
Erstellen Sie ein neues Notizbuch. Navigieren Sie im Kopfzeilenbereich zu "Notizbuch" > "Neue Notiz erstellen". Stellen Sie sicher, dass der Notizbuchkopf einen verbundenen Status anzeigt. Er zeigt einen grünen Punkt in der oberen rechten Ecke an.
Führen Sie den folgenden Code im Zeppelin-Notizbuch aus:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Wählen Sie die Schaltfläche Wiedergabe für den Absatz aus, um den Ausschnitt auszuführen. Der Status in der rechten Ecke des Absatzes sollte sich von BEREIT, AUSSTEHEND, LÄUFT zu ABGESCHLOSSEN ändern. Die Ausgabe wird unten im selben Absatz angezeigt. Der Screenshot sieht wie in der folgenden Abbildung aus:
Ausgabe:





Verwendung von Spark-Submit-Aufträgen
Erstellen einer Datei mit dem folgenden Befehl "#vim samplefile.py"
Mit diesem Befehl wird die Vim-Datei geöffnet.
Fügen Sie den folgenden Code in die Vim-Datei ein.
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Speichern Sie die Datei mit der folgenden Methode.
- Drücken Der Escape-Taste
- Geben Sie den Befehl
:wqein.
Führen Sie den folgenden Befehl aus, um den Auftrag auszuführen.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Überwachen von Abfragen auf einem Apache Spark-Cluster in HDInsight auf AKS
Spark-Verlaufs-UI
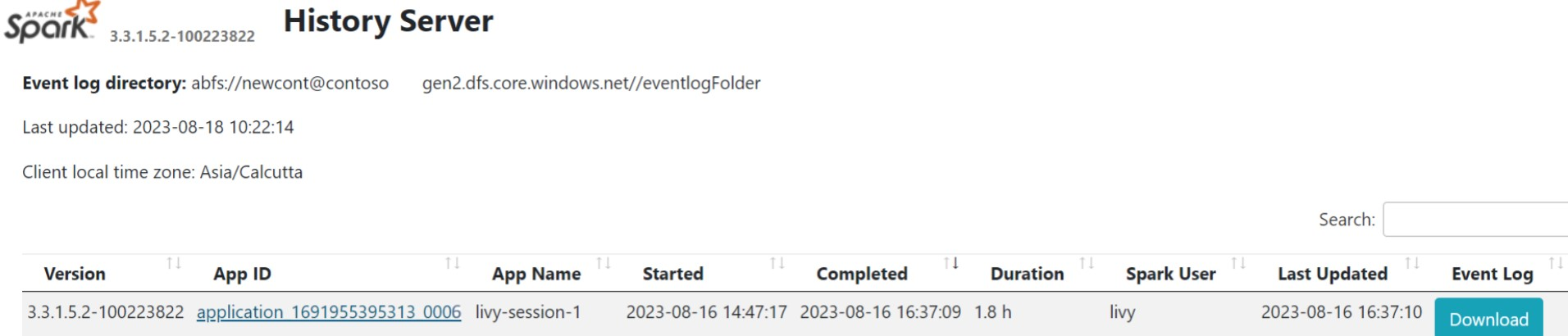
Klicken Sie auf der Registerkarte "Übersicht" auf die Spark History Server-Benutzeroberfläche.

Wählen Sie die zuletzt ausgeführte Ausführung auf der Benutzeroberfläche mit derselben Anwendungs-ID aus.
Zeigen Sie die Phasen des Jobs und den gerichteten azyklischen Graphen in der Spark History-Server-UI an.
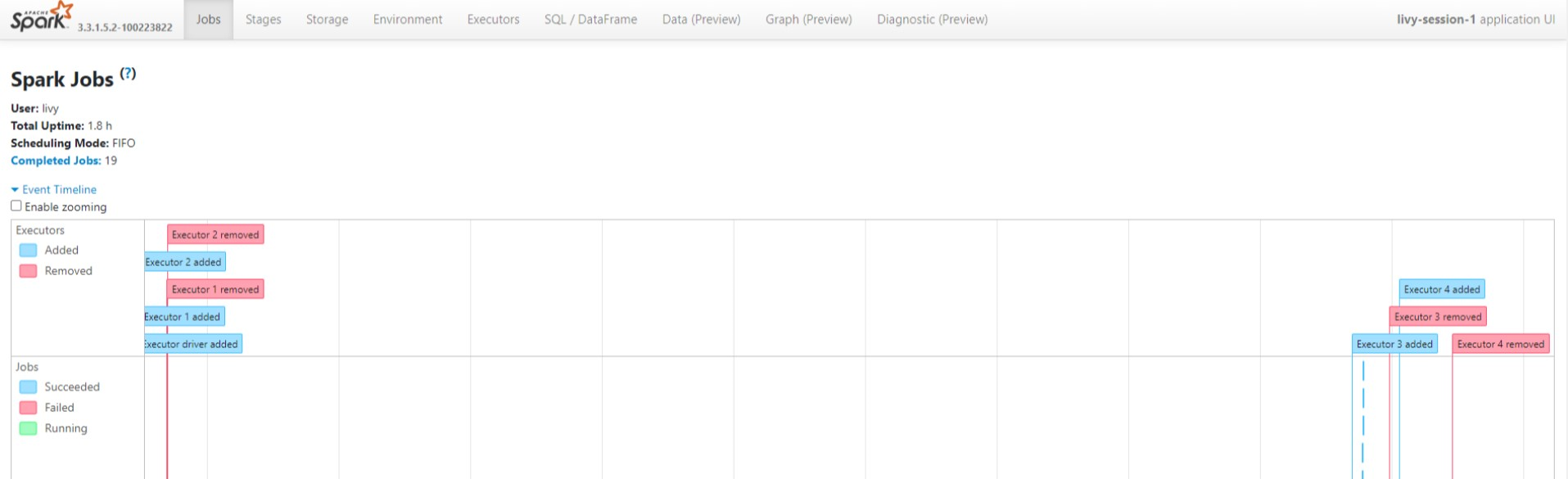



Livy Session UI
Um die Livy-Sitzungs-UI zu öffnen, geben Sie den folgenden Befehl in Ihren Browser
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui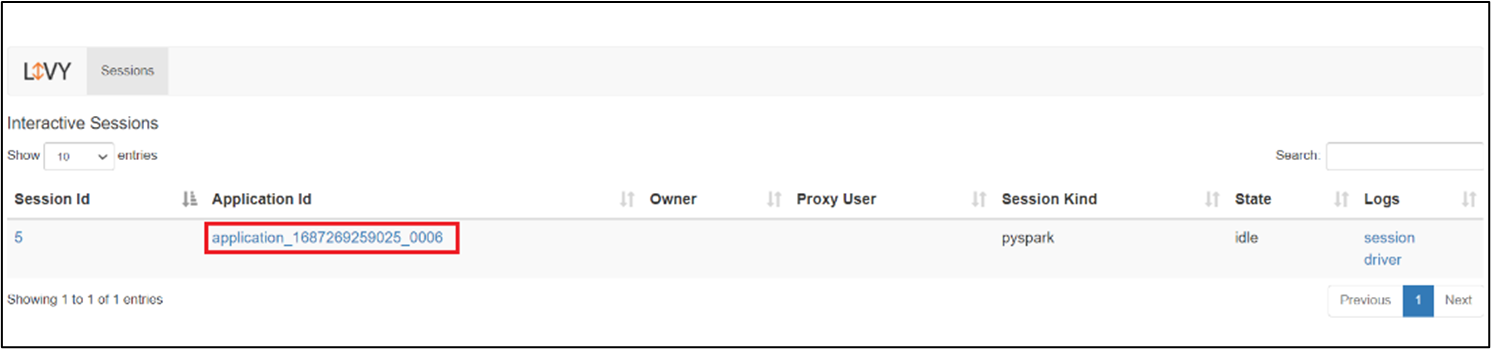
Zeigen Sie die Treiberprotokolle an, indem Sie unter Protokollen auf die Treiberoption klicken.

Yarn UI-
Klicken Sie auf der Registerkarte "Übersicht" auf Yarn, und öffnen Sie die Yarn-Benutzeroberfläche.
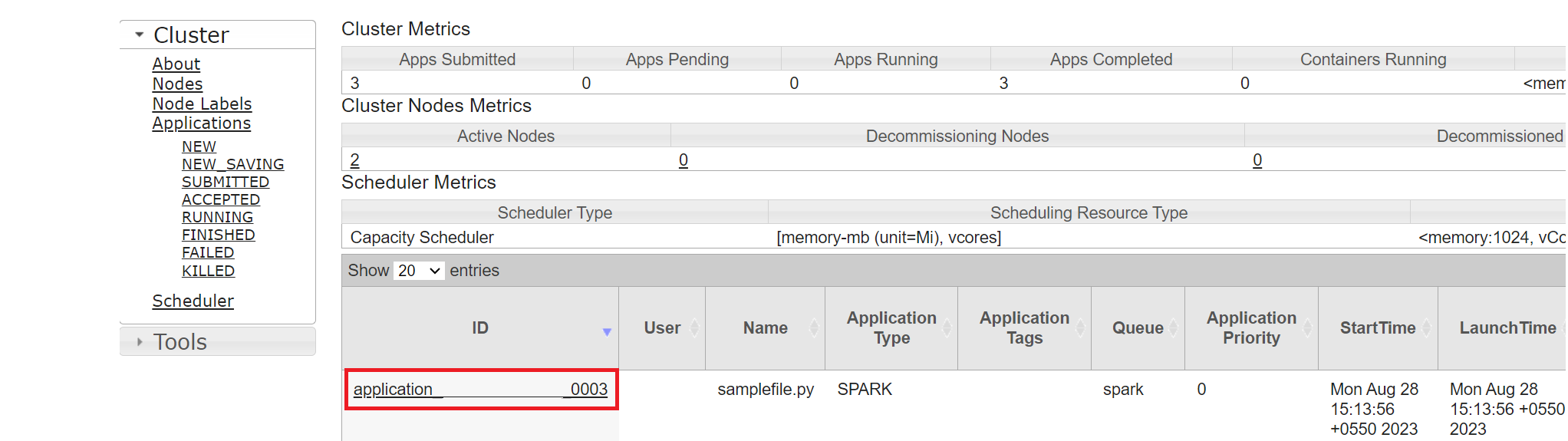
Sie können den Auftrag nachverfolgen, den Sie kürzlich ausgeführt haben, indem Sie dieselbe Anwendungs-ID verwenden.
Klicken Sie in Yarn auf die Anwendungs-ID, um detaillierte Protokolle des Auftrags anzuzeigen.


Referenz
- Apache, Apache Spark, Spark und damit verbundene Open-Source-Projektnamen sind Marken der Apache Software Foundation (ASF).