Verwenden des Hive-Metastores mit Apache Spark-Cluster™
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight on AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
Es ist wichtig, die Daten und den Metastore über mehrere Dienste hinweg zu teilen. Einer der häufig verwendeten Metastores ist der Hive-Metastore. HDInsight on AKS bietet Benutzer*innen die Möglichkeit, eine Verbindung mit einem externen Metastore herzustellen. Dieser Schritt ermöglicht es den HDInsight-Benutzer*innen, sich nahtlos mit anderen Diensten im Ökosystem zu verbinden.
Azure HDInsight on AKS unterstützt auch benutzerdefinierte Metastores, die für Produktionscluster empfohlen werden. Die wichtigsten Schritte lauten wie folgt:
- Erstellen einer Azure SQL-Datenbank
- Erstellen eines Schlüsseltresors zum Speichern der Anmeldeinformationen
- Konfigurieren des Metastores beim Erstellen eines HDInsight auf AKS-Cluster mit Apache Spark™
- Arbeiten mit dem externen Metastore (Datenbanken anzeigen und Grenzwert 1 auswählen)
Beim Erstellen des Clusters muss der HDInsight-Dienst eine Verbindung mit dem externen Metastore herstellen und Ihre Anmeldeinformationen überprüfen.
Erstellen einer Azure SQL-Datenbank
Vor dem Einrichten eines benutzerdefinierten Hive-Metastores für einen HDInsight-Cluster müssen Sie eine Azure SQL-Datenbank erstellen, oder es muss bereits eine Azure SQL-Datenbank vorhanden sein.
Hinweis
Derzeit wird nur Azure SQL-Datenbank für den Hive-Metastore unterstützt. Aufgrund von Hive-Einschränkungen wird das Zeichen „-“ (Bindestrich) im Metastore-Datenbanknamen nicht unterstützt.
Erstellen eines Schlüsseltresors zum Speichern der Anmeldeinformationen
Erstellen Sie eine Azure Key Vault-Instanz.
Der Schlüsseltresor ermöglicht es Ihnen, das SQL Server-Administratorkennwort zu speichern, das während der Erstellung der SQL-Datenbank festgelegt wird. Die HDInsight on AKS-Plattform verarbeitet die Anmeldeinformationen nicht direkt. Daher ist es erforderlich, Ihre wichtigen Anmeldeinformationen in Azure Key Vault zu speichern. Die Schritte zum Erstellen einer Azure Key Vault-Instanz finden Sie hier.
Weisen Sie nach der Erstellung der Azure Key Vault-Instanz die folgenden Rollen zu.
Object Role Hinweise Benutzerseitig zugewiesene verwaltete Identität (User Assigned Managed Identity, UAMI); dies ist die dieselbe UAMI, die vom HDInsight-Cluster verwendet wird Benutzer für Key Vault-Geheimnisse Erfahren Sie, wie Sie benutzerseitig zugewiesenen verwalteten Identitäten Rollen zuweisen. Benutzer*in (von dem*der das Geheimnis in Azure Key Vault erstellt wird) Key Vault-Administrator Erfahren Sie, wie Sie Benutzer*innen Rollen zuweisen. Hinweis
Ohne diese Rolle können Benutzer*innen kein Geheimnis erstellen.
Erstellen eines geheimen Schlüssels
In diesem Schritt können Sie Ihr SQL Server-Administratorkennwort als Geheimnis in Azure Key Vault speichern. Fügen Sie Ihr Kennwort (dasselbe Kennwort, das in der SQL-Datenbank für den*die Administrator*in angegeben wurde) im Feld „Wert“ hinzu, während Sie ein Geheimnis hinzufügen.
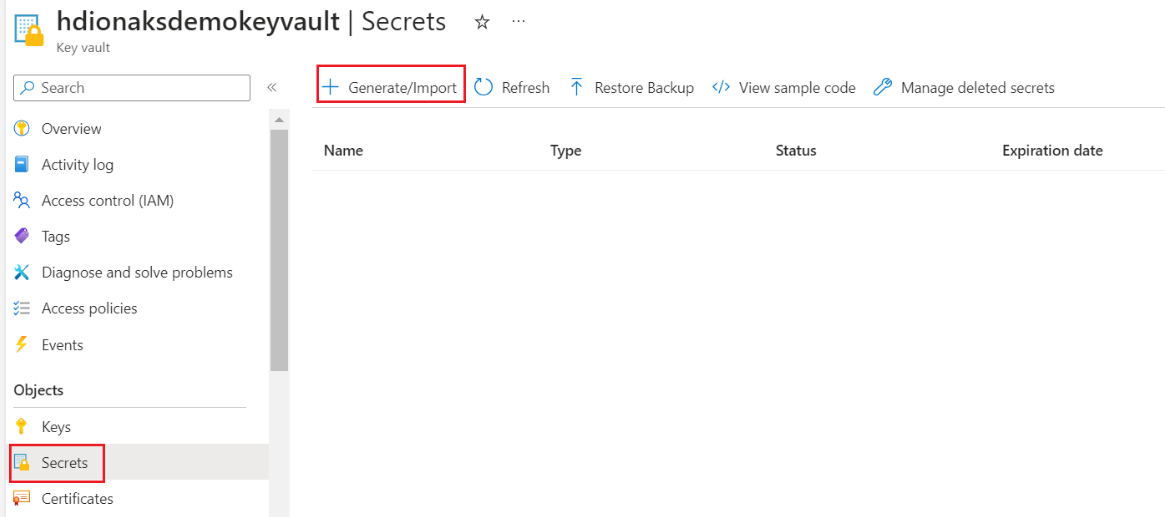
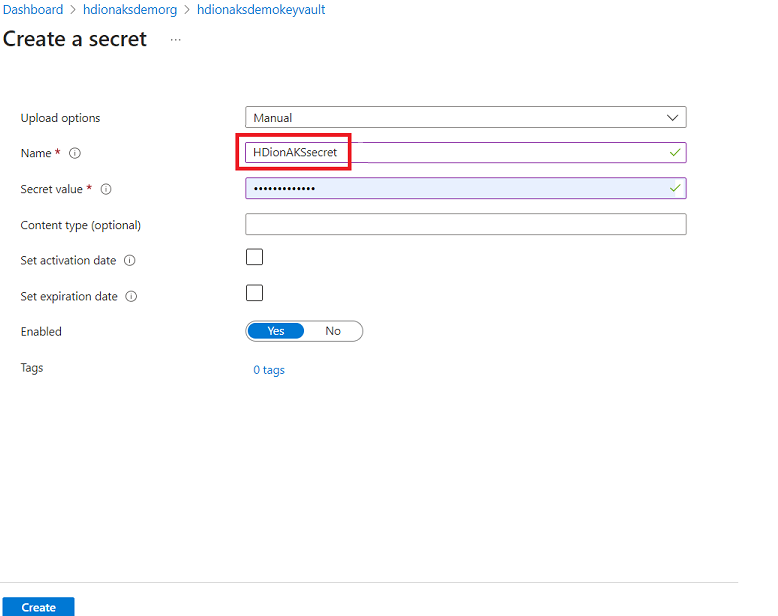
Hinweis
Denken Sie daran, den Geheimnisnamen zu notieren, da Sie diesen beim Erstellen des Clusters benötigen.


Konfigurieren des Metastores während der Erstellung eines HDInsight Spark-Clusters
Navigieren Sie zum HDInsight on AKS-Clusterpool, um Cluster zu erstellen.
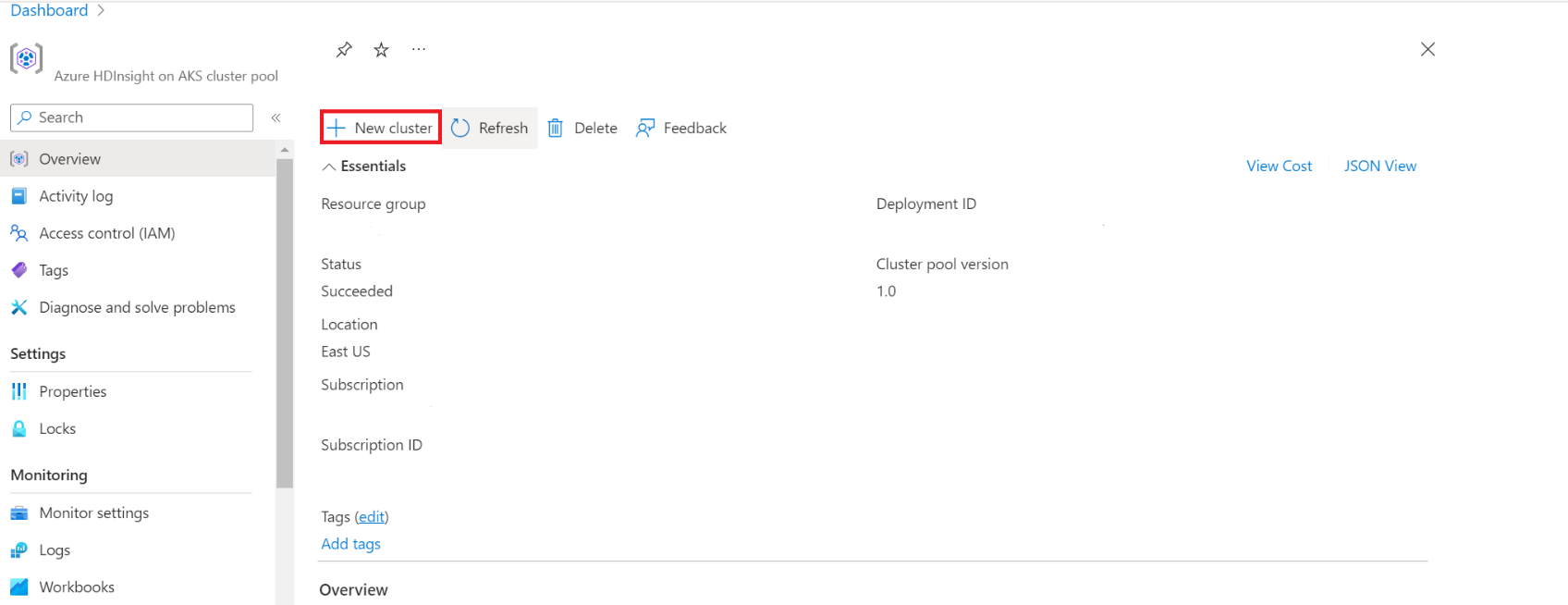
Aktivieren Sie die Umschaltfläche, um den externen Hive-Metastore hinzuzufügen, und geben Sie die folgenden Details ein.
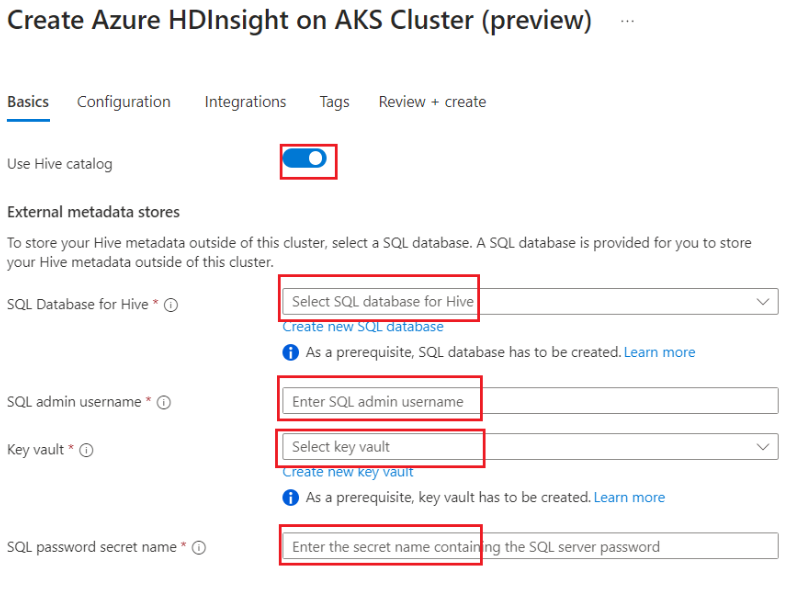
Die restlichen Details müssen gemäß den Regeln für die Erstellung eines Apache Spark-Clusters in HDInsight auf AKS ausgefüllt werden.
Klicken Sie auf Überprüfen und erstellen.
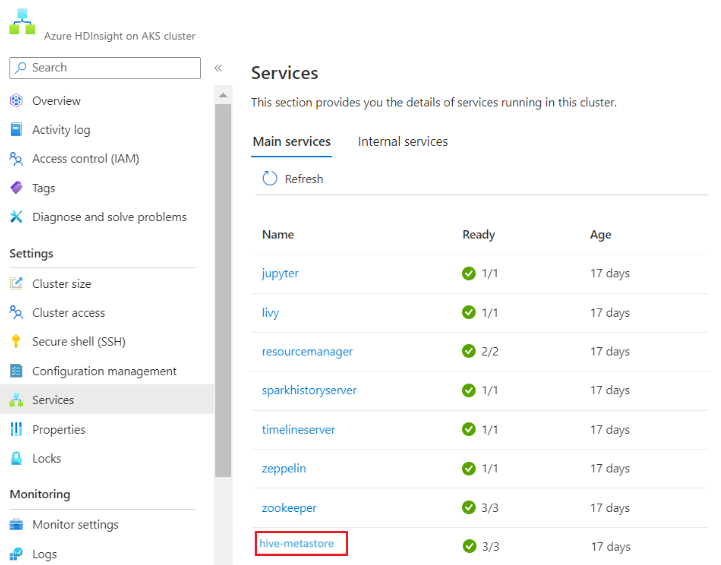
Hinweis
- Der Lebenszyklus des Metastore ist nicht an den Lebenszyklus eines Clusters gebunden, sodass Sie Cluster ohne Verlust von Metadaten erstellen und löschen können. Metadaten wie Ihre Hive-Schemas bleiben auch nach dem Löschen und Neuerstellen des HDInsight-Clusters erhalten.
- Ein benutzerdefinierter Metastore ermöglicht das Anfügen mehrerer Cluster und Clustertypen an diesen Metastore.



Arbeiten mit dem externen Metastores
Erstellen einer Tabelle
>> spark.sql("CREATE TABLE sampleTable (number Int, word String)")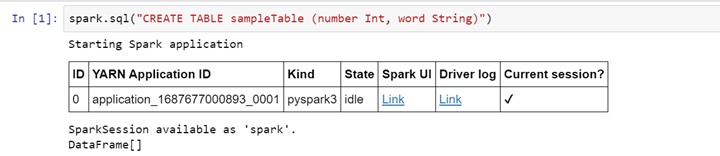
Hinzufügen von Daten zur Tabelle
>> spark.sql("INSERT INTO sampleTable VALUES (123, \"HDIonAKS\")");\
Lesen der Tabelle
>> spark.sql("select * from sampleTable").show()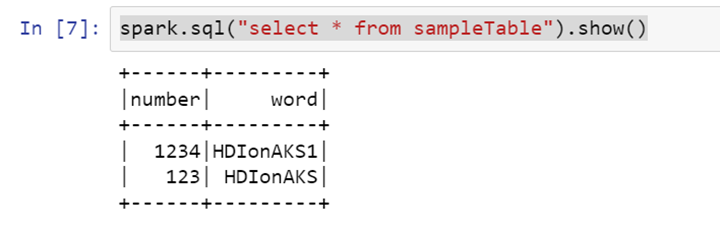



Verweis
- Apache, Apache Spark, Spark und zugehörige Open Source-Projektnamen sind Handelsmarken der Apache Software Foundation (ASF).