Verwenden eines Azure Machine Learning-Notebooks in Spark
Wichtig
Diese Funktion steht derzeit als Vorschau zur Verfügung. Die zusätzlichen Nutzungsbedingungen für Microsoft Azure-Vorschauen enthalten weitere rechtliche Bestimmungen, die für Azure-Features in Betaversionen, in Vorschauversionen oder anderen Versionen gelten, die noch nicht allgemein verfügbar gemacht wurden. Informationen zu dieser spezifischen Vorschau finden Sie unter Informationen zur Vorschau von Azure HDInsight in AKS. Bei Fragen oder Funktionsvorschlägen senden Sie eine Anfrage an AskHDInsight mit den entsprechenden Details, und folgen Sie uns für weitere Updates in der Azure HDInsight-Community.
Bei maschinellem Lernen handelt es sich um eine fortschreitende Technologie, mit der Computer automatisch aus früheren Daten lernen können. Maschinelles Lernen verwendet verschiedene Algorithmen zum Erstellen mathematischer Modelle und für Vorhersagen mithilfe von historischen Daten oder Informationen. Ein Modell ist mit Parametern definiert, und das Lernen ist die Ausführung eines Computerprogramms zum Optimieren der Parameter des Modells mithilfe der Trainingsdaten oder der Trainingsumgebung. Das Modell kann prädiktiv sein, um Vorhersagen für die Zukunft zu machen, oder deskriptiv, um Wissen aus Daten zu gewinnen.
Im folgenden Tutorial-Notebook wird ein Beispiel für das Trainieren von Machine Learning-Modellen mithilfe von Tabellendaten gezeigt. Sie können dieses Notebook importieren und selbst ausführen.
Hochladen der CSV-Datei in Ihren Speicher
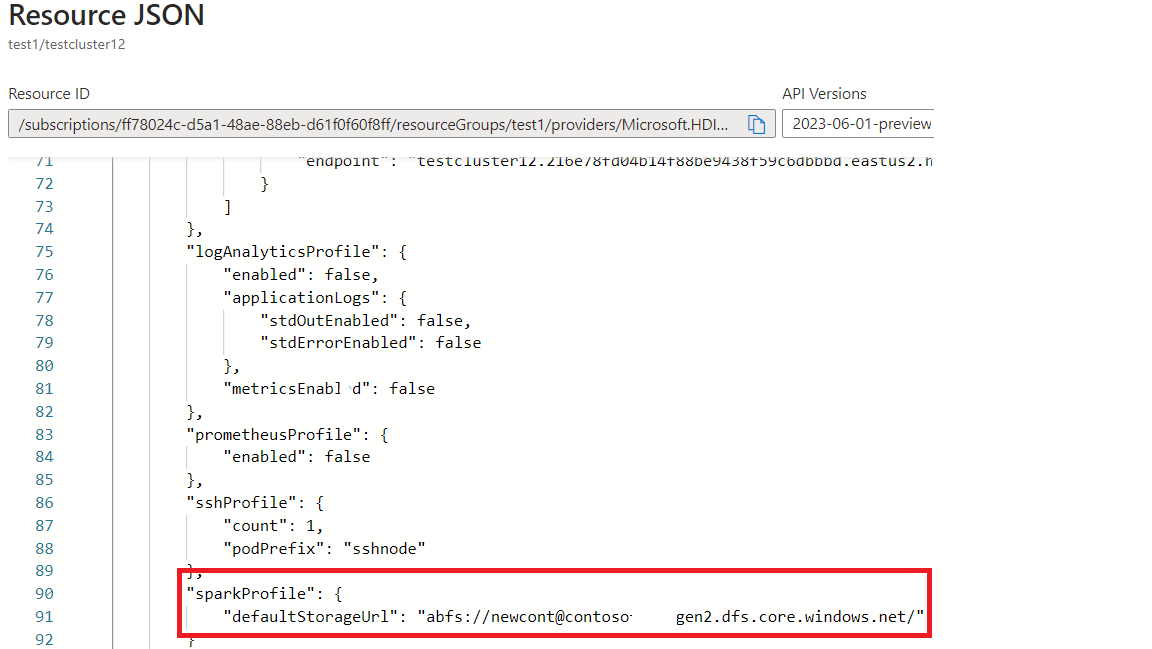
Suchen Sie den Speicher- und Containernamen in der JSON-Ansicht des Portals.
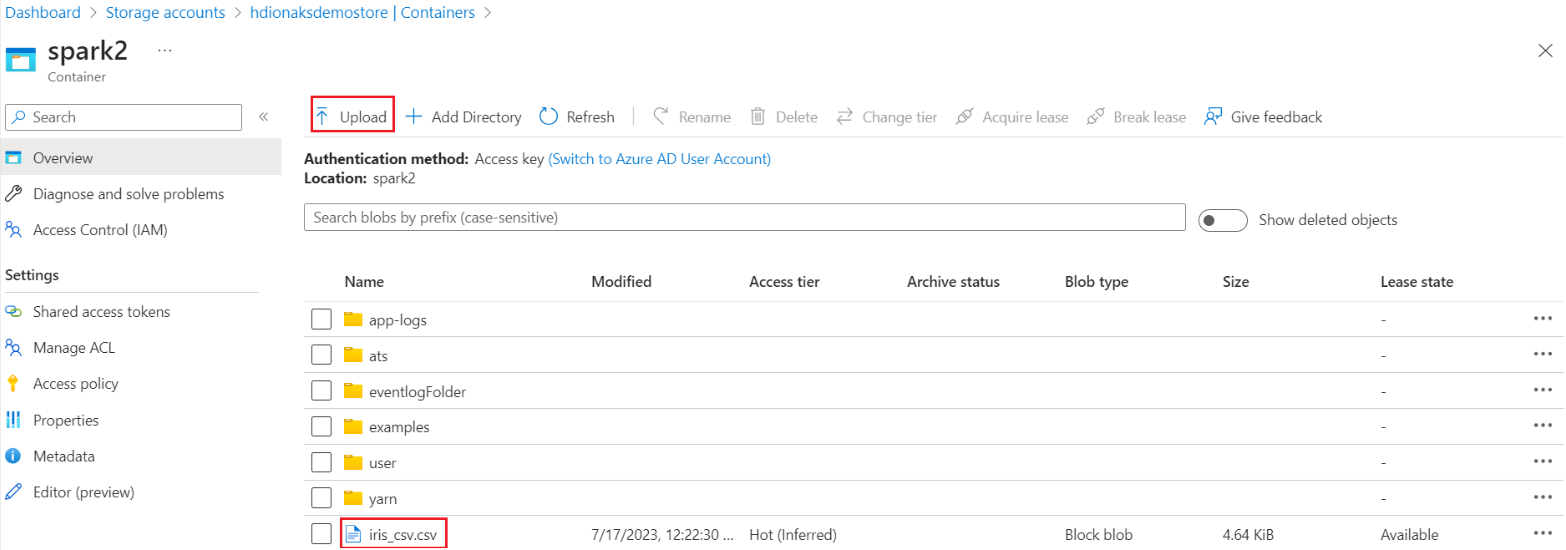
Navigieren Sie auf Ihrer primären HDI in Speicher>Container>Basisordner>, und laden Sie die CSV-Datei hoch.
Melden Sie sich bei Ihrem Cluster an, und öffnen Sie das Jupyter Notebook.
Importieren Sie Spark MLlib-Bibliotheken zum Erstellen der Pipeline.
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Lesen Sie die CSV-Datei in einen Spark-Dataframe.
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)Teilen Sie die Daten für Training und Testen.
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)Erstellen Sie die Pipeline, und trainieren Sie das Modell.
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
Bewerten Sie die Modellgenauigkeit.
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))





Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für