Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie über das Azure-Portal Apache Hadoop-Cluster in HDInsight erstellen und dann Apache Hive-Aufträge in HDInsight ausführen. Die meisten Hadoop-Aufträge sind Batchaufträge. Sie erstellen einen Cluster, führen einige Aufträge aus und löschen dann den Cluster. In diesem Artikel führen Sie alle drei Aufgaben durch. Eine ausführliche Beschreibung der verfügbaren Konfigurationen finden Sie unter Einrichten von Clustern in HDInsight. Weitere Informationen zur Nutzung des Portals zum Erstellen von Clustern finden Sie unter Erstellen von Clustern im Portal.
In dieser Schnellstartanleitung verwenden Sie das Azure-Portal, um einen HDInsight-Hadoop-Cluster zu erstellen. Sie können einen Cluster auch mithilfe der Azure Resource Manager-Vorlage erstellen.
Aktuell stehen in HDInsight sieben verschiedene Clustertypen zur Verfügung. Jeder Clustertyp unterstützt eine andere Gruppe von Komponenten. Alle Clustertypen unterstützen Hive. Eine Liste mit den unterstützten Komponenten in HDInsight finden Sie unter Neuheiten in den von HDInsight bereitgestellten Apache Hadoop-Clusterversionen.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Erstellen eines Apache Hadoop-Clusters
In diesem Abschnitt erstellen Sie im Azure-Portal einen Hadoop-Cluster in HDInsight.
Melden Sie sich beim Azure-Portal an.
Klicken Sie im oberen Menü auf + Ressource erstellen.
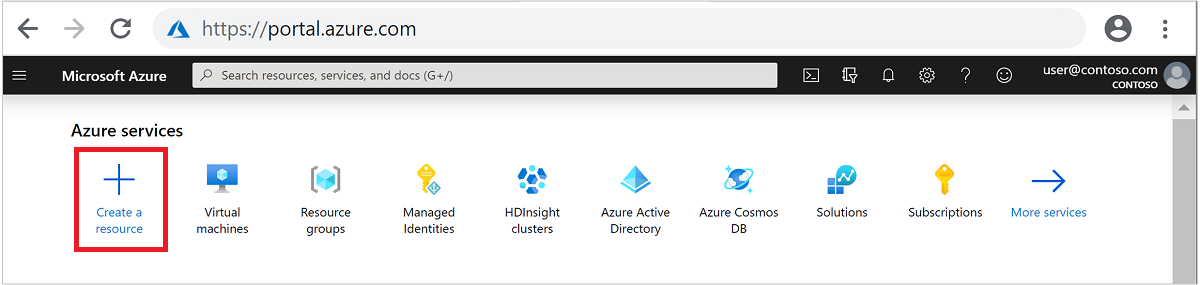
Wählen Sie Analytics>Azure HDInsight aus, um die Seite HDInsight-Cluster erstellen zu öffnen.
Geben Sie auf der Registerkarte Grundlagen die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Subscription Wählen Sie in der Dropdownliste das Azure-Abonnement aus, das für den Cluster verwendet wird. Ressourcengruppe Wählen Sie in der Dropdownliste Ihre vorhandene Ressourcengruppe oder die Option Neu erstellen aus. Clustername Geben Sie einen global eindeutigen Namen ein. Der Name kann aus bis zu 59 Zeichen mit Buchstaben, Zahlen und Bindestrichen bestehen. Das erste und das letzte Zeichen des Namens dürfen keine Bindestriche sein. Region Wählen Sie in der Dropdownliste eine Region für die Erstellung des Clusters aus. Je näher der Standort, desto besser die Leistung. Clustertyp Wählen Sie Clustertyp auswählen aus. Wählen Sie dann Hadoop als Clustertyp aus. Version Wählen Sie in der Dropdownliste eine Version aus. Verwenden Sie die Standardversion, wenn Sie nicht wissen, was Sie auswählen sollen. Benutzername und Kennwort der Clusteranmeldung Der Standardanmeldename ist admin. Das Kennwort muss mindestens zehn Zeichen lang sein und mindestens eine Ziffer, einen Groß- und einen Kleinbuchstaben sowie ein nicht alphanumerisches Zeichen enthalten (mit Ausnahme der Zeichen ' ` "). Stellen Sie sicher, dass Sie keine häufig verwendeten Kennwörter wie „Kennwort1“ angeben.SSH-Benutzername (Secure Shell) Der Standardbenutzername lautet sshuser. Sie können einen anderen SSH-Benutzernamen angeben.Verwenden des Clusteranmeldekennworts für SSH Aktivieren Sie dieses Kontrollkästchen, um für den SSH-Benutzer das gleiche Kennwort zu verwenden, das Sie für den Benutzer der Clusteranmeldung angegeben haben. 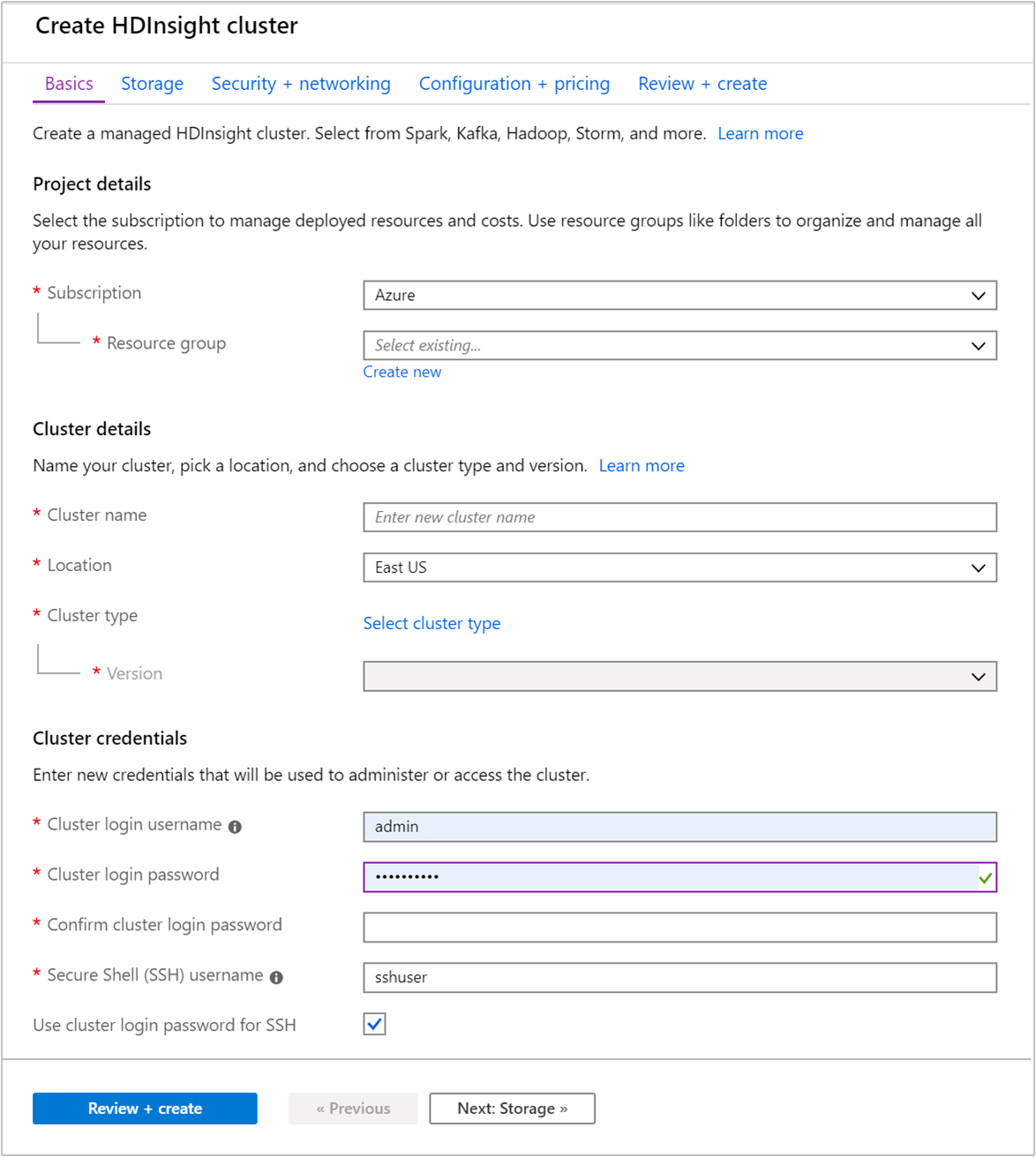
Wählen Sie Weiter: Speicher >> aus, um zu den Speichereinstellungen zu wechseln.
Geben Sie auf der Registerkarte Speicher die folgenden Werte ein:
Eigenschaft BESCHREIBUNG Primärer Speichertyp Übernehmen Sie den Standardwert Azure Storage. Auswahlmethode Übernehmen Sie den Standardwert Aus Liste auswählen. Primäres Speicherkonto Wählen Sie in der Dropdownliste ein vorhandenes Speicherkonto aus, oder wählen Sie Neu erstellen aus. Wenn Sie ein neues Konto erstellen, muss der Name zwischen 3 und 24 Zeichen lang sein und darf nur Zahlen und Kleinbuchstaben enthalten. Container Verwenden Sie den automatisch ausgefüllten Wert. 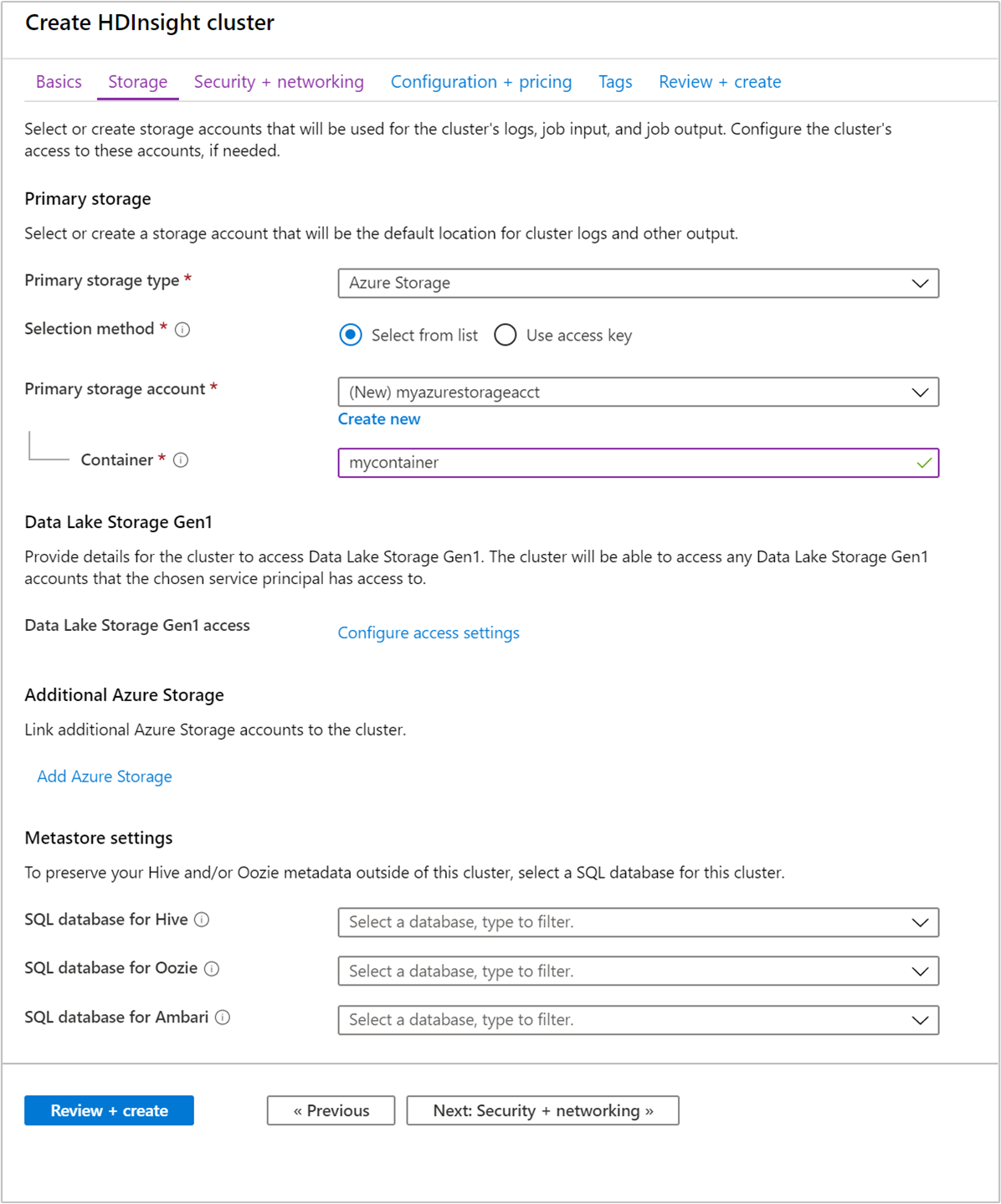
Jeder Cluster verfügt über ein Azure Storage-Konto, oder eine
Azure Data Lake Storage Gen2-Abhängigkeit. Dieses wird als Standardspeicherkonto bezeichnet. Der HDInsight-Cluster und das dazugehörige Speicherkonto müssen sich in derselben Azure-Region befinden. Beim Löschen von Clustern wird das Speicherkonto nicht gelöscht.Wählen Sie die Registerkarte Überprüfen + erstellen aus.
Überprüfen Sie auf der Registerkarte Überprüfen + erstellen die Werte, die Sie in den vorhergehenden Schritten ausgewählt haben.
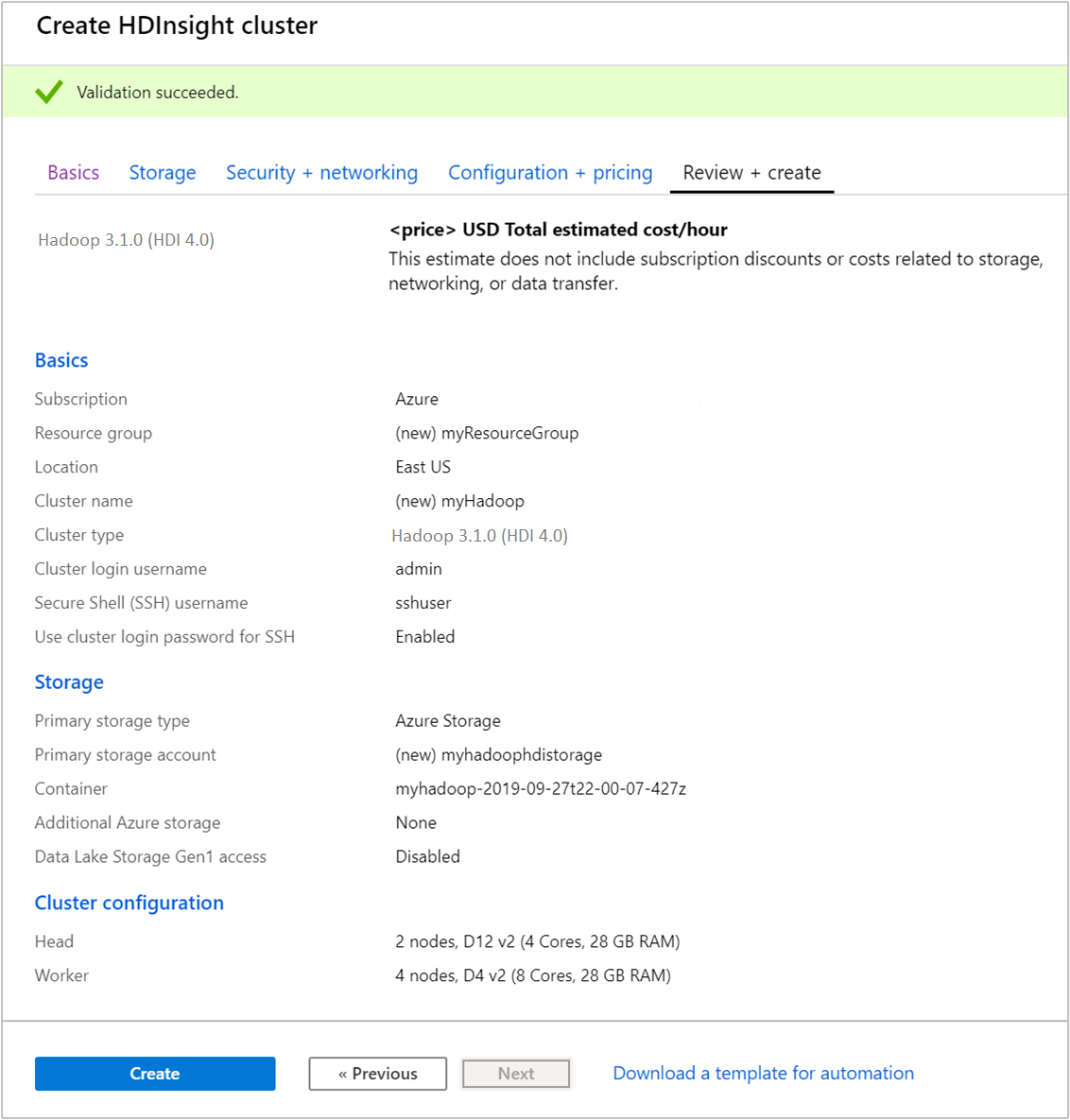
Klicken Sie auf Erstellen. Das Erstellen eines Clusters dauert ca. 20 Minuten.
Sobald der Cluster erstellt wurde, sehen Sie die Zusammenfassungsseite für den Cluster im Azure-Portal.
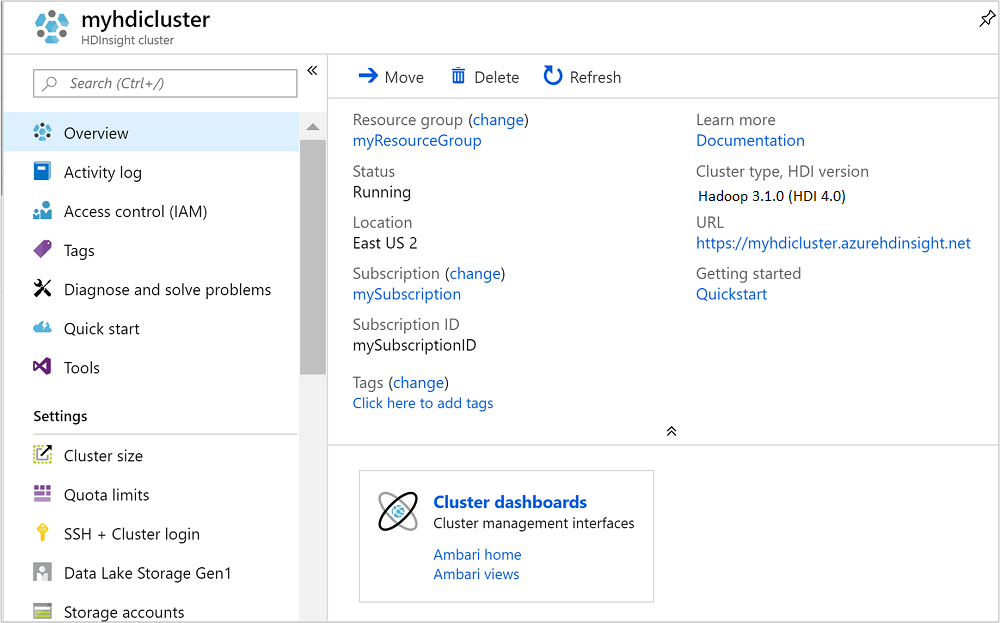
Ausführen von Apache Hive-Abfragen
Apache Hive ist die am häufigsten in HDInsight verwendete Komponente. Es gibt viele Verfahren zum Ausführen von Hive-Aufträgen in HDInsight. In diesem Schnellstart verwenden Sie die Ambari Hive-Ansicht aus dem Portal. Andere Methoden zum Übermitteln von Hive-Aufträgen finden Sie unter Verwenden von Hive in HDInsight.
Hinweis
Apache Hive View ist in HDInsight 4.0 nicht verfügbar.
Um Ambari zu öffnen, wählen Sie im vorherigen Screenshot Clusterdashboard aus. Sie können auch zu
https://ClusterName.azurehdinsight.netnavigieren.ClusterNameist hierbei der Cluster, den Sie im vorherigen Abschnitt erstellt haben.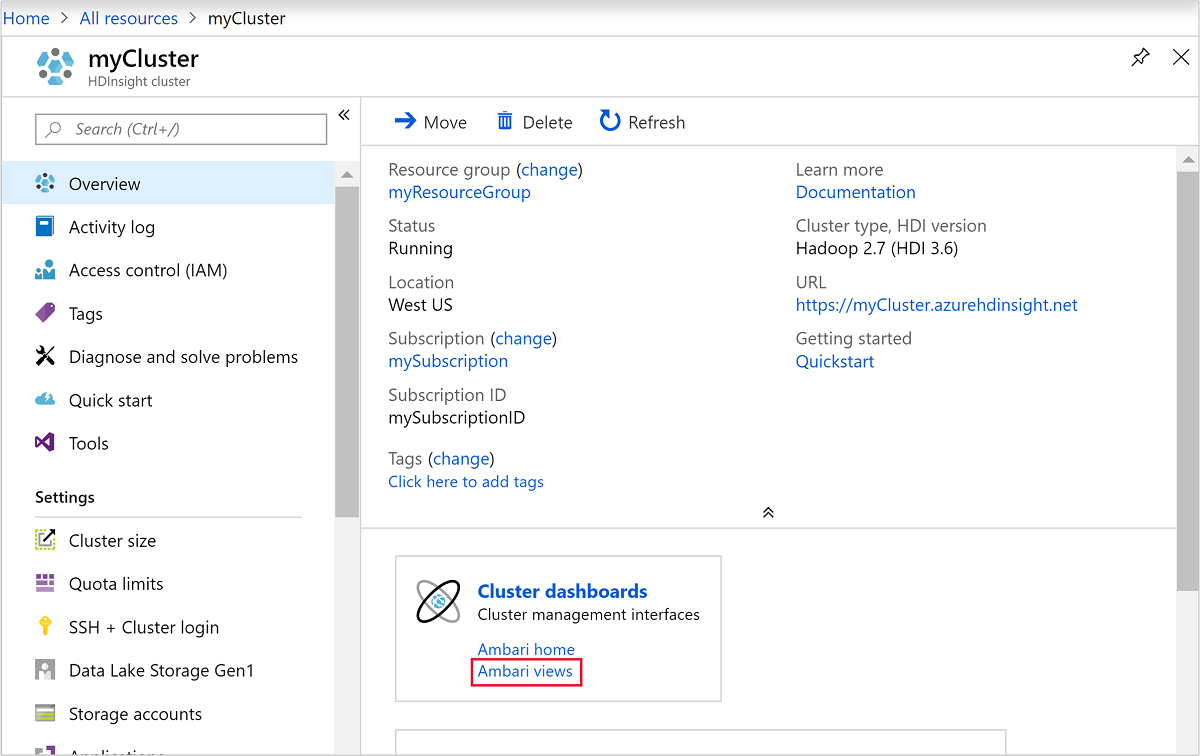
Geben Sie den Hadoop-Benutzernamen, den Sie beim Erstellen des Clusters angegeben haben, und das dazugehörige Kennwort ein. Der Standardbenutzername lautet
admin.Öffnen Sie die Hive-Ansicht wie im folgenden Screenshot dargestellt:
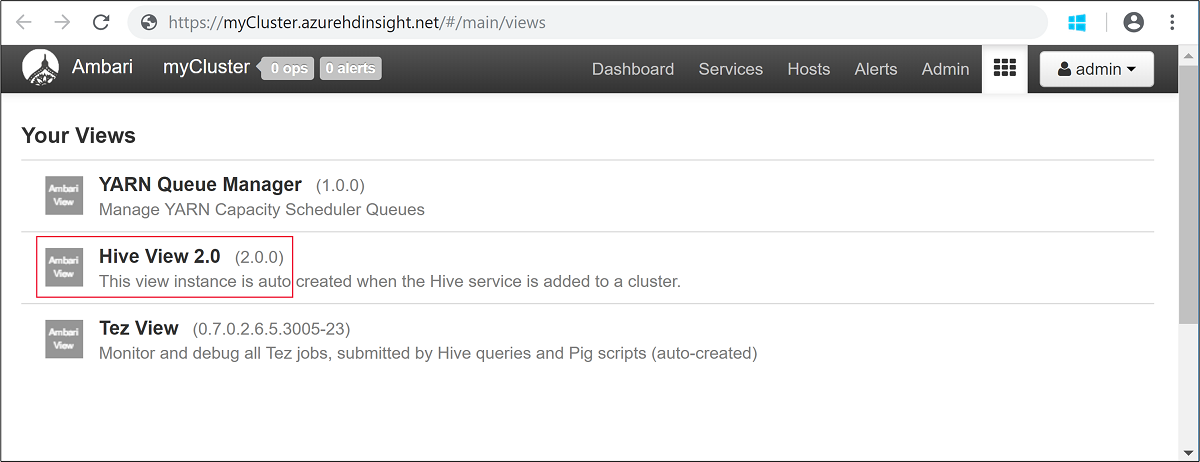
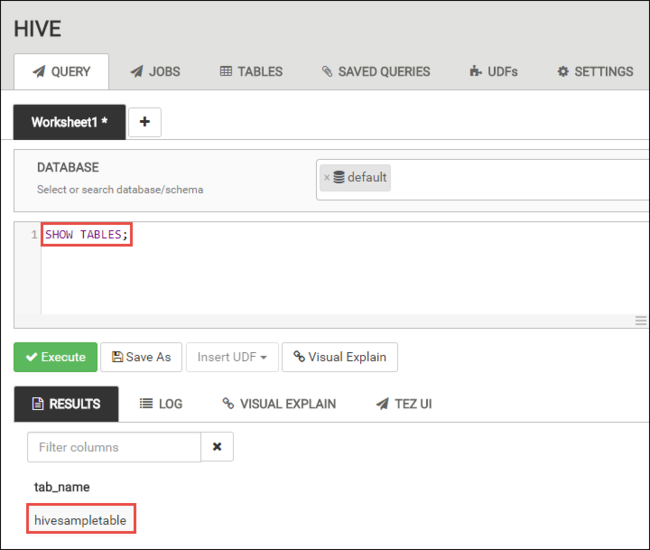
Fügen Sie auf der Registerkarte ABFRAGE die folgenden HiveQL-Anweisungen in das Arbeitsblatt ein:
SHOW TABLES;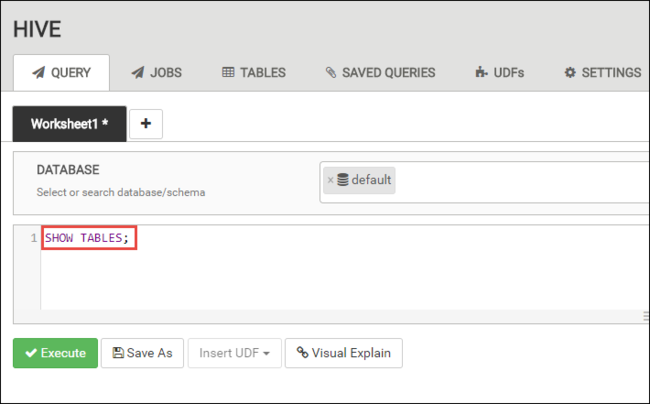
Wählen Sie Execute(Ausführen). Die Registerkarte ERGEBNISSE wird unterhalb der Registerkarte ABFRAGE angezeigt und enthält Informationen zum Auftrag.
Nach Abschluss der Abfrage werden auf der Registerkarte ABFRAGE die Ergebnisse des Vorgangs angezeigt. Sie sehen eine Tabelle mit dem Namen hivesampletable. Die ist eine Hive-Beispieltabelle mit allen HDInsight-Clustern.
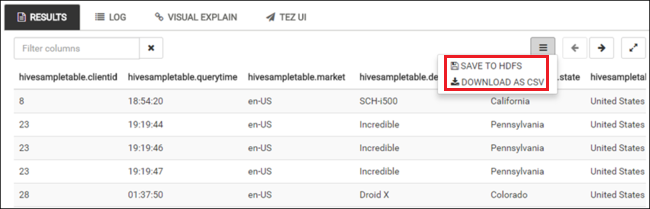
Wiederholen Sie die Schritte 4 und 5, um die folgende Abfrage ausführen:
SELECT * FROM hivesampletable;Sie können die Ergebnisse der Abfrage auch speichern. Wählen Sie die Menüschaltfläche rechts aus, und geben Sie an, ob Sie die Ergebnisse als CSV-Datei herunterladen oder in dem Speicherkonto speichern möchten, das dem Cluster zugeordnet ist.
Nachdem Sie einen Hive-Auftrag abgeschlossen haben, können Sie die Ergebnisse in eine Azure SQL-Datenbank oder eine SQL Server-Datenbank exportieren und die Abfrageergebnisse mithilfe von Excel visualisieren. Weitere Informationen zum Verwenden von Hive in HDInsight finden Sie unter Verwenden von Apache Hive und HiveQL mit Apache Hadoop in HDInsight zum Analysieren einer Apache Log4j-Beispieldatei.
Bereinigen von Ressourcen
Nachdem Sie den Schnellstart abgeschlossen haben, können Sie den Cluster löschen. Mit HDInsight werden Ihre Daten in Azure Storage gespeichert, sodass Sie einen Cluster problemlos löschen können, wenn er nicht verwendet wird. Für einen HDInsight-Cluster fallen auch dann Gebühren an, wenn er nicht verwendet wird. Da die Gebühren für den Cluster erheblich höher sind als die Kosten für den Speicher, ist es sinnvoll, nicht verwendete Cluster zu löschen.
Hinweis
Wenn Sie sofort mit dem nächsten Artikel fortfahren, um zu erfahren, wie Sie ETL-Vorgänge mithilfe von Hadoop in HDInsight ausführen, können Sie den Cluster weiterhin ausführen. Ansonsten müssen Sie in diesem Tutorial erneut einen Hadoop-Cluster erstellen. Wenn Sie jedoch nicht direkt mit dem nächsten Artikel fortfahren, sollten Sie den Cluster jetzt löschen.
So löschen Sie den Cluster bzw. das Standardspeicherkonto
Wechseln Sie zurück zur Browserregisterkarte für das Azure-Portal. Die Seite mit der Clusterübersicht sollte angezeigt werden. Klicken Sie auf Löschen, wenn Sie nur den Cluster löschen, aber das Standardspeicherkonto behalten möchten.
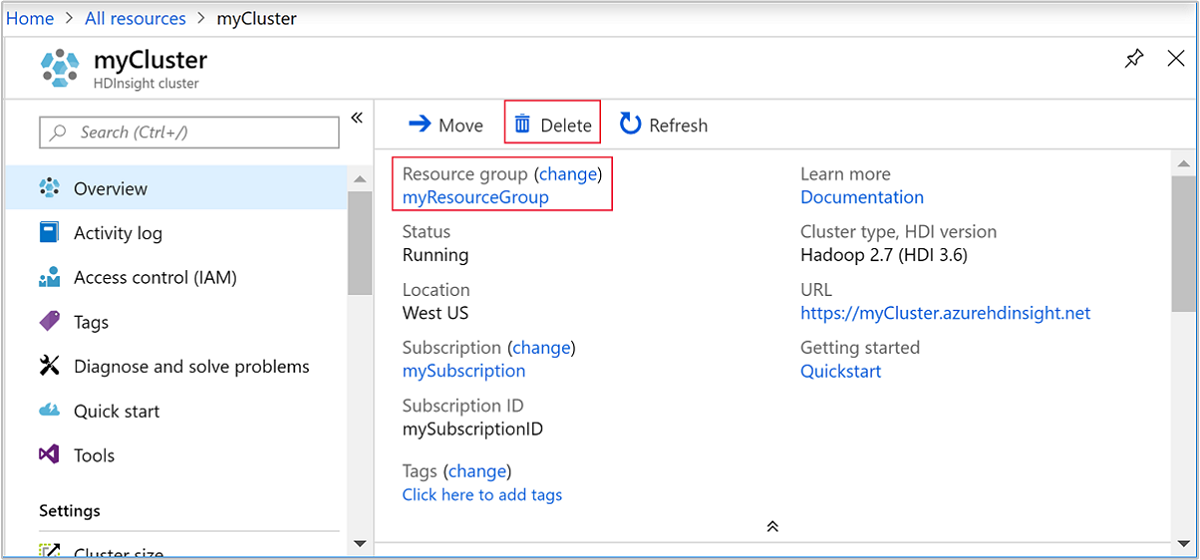
Wenn Sie den Cluster und das Standardspeicherkonto löschen möchten, wählen Sie den Ressourcengruppennamen (im vorherigen Screenshot markiert) aus, um die Seite für die Ressourcengruppe zu öffnen.
Klicken Sie auf Ressourcengruppe löschen, um die Ressourcengruppe zu löschen, die den Cluster und das Standardspeicherkonto enthält. Beachten Sie, dass das Speicherkonto beim Löschen der Ressourcengruppe ebenfalls gelöscht wird. Wenn Sie das Speicherkonto beibehalten möchten, müssen Sie auswählen, dass nur der Cluster gelöscht werden soll.
Nächste Schritte
In diesem Schnellstart haben Sie erfahren, wie Sie mithilfe einer Resource Manager-Vorlage einen Linux-basierten HDInsight-Cluster erstellen und einfache Hive-Abfragen ausführen. Im nächsten Artikel erfahren Sie, wie Sie mithilfe von Hadoop in HDInsight einen ETL-Vorgang zum Extrahieren, Transformieren und Laden von Daten ausführen.