Sicheres Verwalten der Python-Umgebung in Azure HDInsight mithilfe einer Skriptaktion
Für den Spark-Cluster verfügt HDInsight mit Anaconda Python 2.7 und Python 3.5 über zwei integrierte Python-Installationen. Kunden müssen die Python-Umgebung ggf. anpassen, um z. B. externe Python-Pakete zu installieren. Hier zeigen wir die bewährte Methode zur sicheren Verwaltung von Python-Umgebungen für Apache Spark-Cluster in HDInsight.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight. Wenn Sie noch nicht über einen Spark-Cluster in HDInsight verfügen, können Sie während der Clustererstellung Skriptaktionen ausführen. Informationen zum Verwenden benutzerdefinierter Skriptaktionen finden Sie in der Dokumentation.
Unterstützung für Open-Source-Software in HDInsight-Clustern
Der Dienst Microsoft Azure HDInsight verwendet eine Umgebung von Open-Source-Technologien für Apache Hadoop. Microsoft Azure bietet lediglich allgemeinen Support für Open-Source-Technologien. Weitere Informationen finden Sie unter Häufig gestellte Fragen zum Azure-Support. Der HDInsight-Dienst bietet zusätzliche Unterstützung für integrierte Komponenten.
Es gibt zwei Arten von Open-Source-Komponenten, die im HDInsight-Dienst verfügbar sind:
| Komponente | BESCHREIBUNG |
|---|---|
| Integriert | Diese Komponenten sind in HDInsight-Clustern vorinstalliert und stellen Kernfunktionen des Clusters bereit. So gehören beispielsweise Apache Hadoop YARN Resource Manager, die Apache Hive-Abfragesprache (HiveQL) und die Mahout Library zu dieser Kategorie. Eine vollständige Liste der Clusterkomponenten finden Sie unter Neuheiten in den von HDInsight bereitgestellten Apache Hadoop-Clusterversionen. |
| Benutzerdefiniert | Als Benutzer des Clusters können Sie in Ihrer Workload eine beliebige, in der Community verfügbare oder von Ihnen erstellte Komponente installieren oder verwenden. |
Wichtig
Mit dem HDInsight-Cluster bereitgestellte Komponenten werden vollständig unterstützt. Der Microsoft-Support unterstützt Sie beim Isolieren und Beheben von Problemen im Zusammenhang mit diesen Komponenten.
Für benutzerdefinierte Komponenten steht kommerziell angemessener Support für eine weiterführende Behebung des Problems zur Verfügung. Der Microsoft-Support kann das Problem möglicherweise beheben, ODER Sie werden aufgefordert, verfügbare Kanäle für Open-Source-Technologien in Anspruch zu nehmen, die über umfassende Kenntnisse für diese Technologien verfügen. So können viele Communitywebsites aufgesucht werden, z. B. die Microsoft Q&A-Seite für HDInsight, https://stackoverflow.com. Für Apache-Projekte gibt es auch Projektwebsites bei https://apache.org.
Grundlegendes zur Python-Standardinstallation
Für HDInsight Spark-Cluster ist Anaconda installiert. Im Cluster gibt es zwei Python-Installationen: Anaconda Python 2.7 and Python 3.5. In der folgenden Tabelle sind die Python-Standardeinstellungen für Spark, Livy und Jupyter aufgeführt.
| Einstellung | Python 2,7 | Python 3.5 |
|---|---|---|
| `Path` | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Spark-Version | Standard ist 2.7 | Die Konfiguration kann in „3,5“ geändert werden. |
| Livy-Version | Standard ist 2.7 | Die Konfiguration kann in „3,5“ geändert werden. |
| Jupyter | PySpark-Kernel | PySpark3-Kernel |
Für die Spark-Version 3.1.2 wird der Apache PySpark-Kernel entfernt und eine neue Python 3.8-Umgebung unter /usr/bin/miniforge/envs/py38/bin installiert, die vom PySpark3-Kernel verwendet wird. Die Umgebungsvariablen PYSPARK_PYTHON und PYSPARK3_PYTHON werden verwendet, um Folgendes zu aktualisieren:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Sicheres Installieren externer Python-Pakete
Der HDInsight-Cluster hängt von der integrierten Python-Umgebung (Python 2.7 oder 3.5) ab. Die direkte Installation von benutzerdefinierten Paketen in diesen standardmäßig integrierten Umgebungen kann zu unerwarteten Änderungen der Bibliotheksversionen führen und eine weitere Beschädigung des Clusters verursachen. Um benutzerdefinierte externe Python-Pakete für Ihre Spark-Anwendungen sicher zu installieren, führen Sie die folgenden Schritte aus.
Erstellen Sie mithilfe von Conda eine virtuelle Python-Umgebung. Eine virtuelle Umgebung bietet einen isolierten Raum für Ihre Projekte, ohne andere zu beeinträchtigen. Beim Erstellen der virtuellen Python-Umgebung können Sie die Python-Version angeben, die Sie verwenden möchten. Sie müssen immer noch eine virtuelle Umgebung erstellen, auch wenn Sie Python 2.7 und 3.5 verwenden möchten. Durch diese Anforderung wird sichergestellt, dass die Standardumgebung des Clusters nicht beschädigt wird. Führen Sie Skriptaktionen für alle Knoten in Ihrem Cluster mit dem folgenden Skript aus, um eine virtuelle Python-Umgebung zu erstellen.
--prefixgibt einen Pfad zu einer virtuellen Conda-Umgebung an. Es gibt mehrere Konfigurationen, für die basierend auf dem hier angegebenen Pfad weitere Änderungen vorgenommen werden müssen. In diesem Beispiel wird py35new verwendet, da der Cluster bereits über eine bestehende virtuelle Umgebung namens py35 verfügt.python=gibt die Python-Version für die virtuelle Umgebung an. In diesem Beispiel wird die Version 3.5 verwendet, die gleiche Version wie die bereits im Cluster integrierte. Sie können auch andere Python-Versionen verwenden, um die virtuelle Umgebung zu erstellen.anacondalegt package_spec als Anaconda fest, um Anaconda-Pakete in der virtuellen Umgebung zu installieren.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesInstallieren Sie bei Bedarf in der erstellten virtuellen Umgebung externe Python-Pakete. Führen Sie Skriptaktionen für alle Knoten in Ihrem Cluster mit dem folgenden Skript aus, um externe Python-Pakete zu installieren. Sie müssen über sudo-Berechtigungen verfügen, um Dateien in den Ordner der virtuellen Umgebung zu schreiben.
Durchsuchen Sie den Paketindex nach einer vollständigen Liste der verfügbaren Pakete. Sie können die Liste der verfügbaren Pakete auch aus anderen Quellen abrufen. So können Sie beispielsweise Pakete installieren, die über conda-forge verfügbar gemacht wurden.
Verwenden Sie den folgenden Befehl, wenn Sie eine Bibliothek mit der aktuellen Version installieren möchten:
Verwenden Sie den Conda-Kanal:
seabornist der Name des Pakets, das Sie installieren möchten.-n py35newgibt den Namen der virtuellen Umgebung an, die gerade erstellt wird. Stellen Sie sicher, dass Sie den Namen entsprechend der von Ihnen erstellten virtuellen Umgebung ändern.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesOder verwenden Sie das PyPi-Repository, und ändern Sie
seabornundpy35newentsprechend:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Verwenden Sie den folgenden Befehl, wenn Sie eine Bibliothek mit einer spezifischen Version installieren möchten:
Verwenden Sie den Conda-Kanal:
numpy=1.16.1ist der Paketname und die Version, die Sie installieren möchten.-n py35newgibt den Namen der virtuellen Umgebung an, die gerade erstellt wird. Stellen Sie sicher, dass Sie den Namen entsprechend der von Ihnen erstellten virtuellen Umgebung ändern.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesOder verwenden Sie das PyPi-Repository, und ändern Sie
numpy==1.16.1undpy35newentsprechend:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Wenn Sie den Namen der virtuellen Umgebung nicht kennen, können Sie SSH an den Hauptknoten des Clusters senden und
/usr/bin/anaconda/bin/conda info -eausführen, um alle virtuellen Umgebungen anzuzeigen.Ändern Sie die Spark- und Livy-Konfigurationen, und zeigen Sie auf die erstellte virtuelle Umgebung.
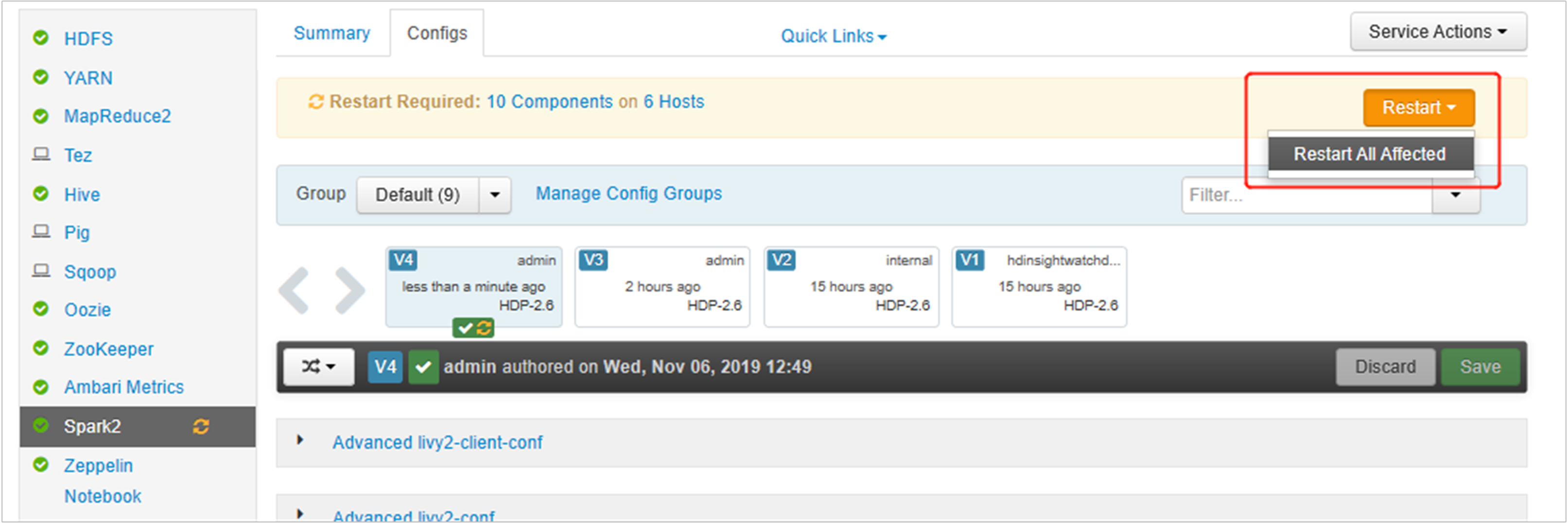
Öffnen Sie die Ambari-Benutzeroberfläche, und wechseln Sie zur Spark 2-Seite auf die Registerkarte „Konfigurationen“.

Erweitern Sie „livy2-env erweitert“, und fügen Sie die folgenden Anweisungen am Ende hinzu. Wenn Sie die virtuelle Umgebung mit einem anderen Präfix installiert haben, ändern Sie den Pfad entsprechend.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python
Erweitern Sie „Advanced spark2-env“, und ersetzen Sie unten die vorhandene PYSPARK_PYTHON-Anweisung für den Export. Wenn Sie die virtuelle Umgebung mit einem anderen Präfix installiert haben, ändern Sie den Pfad entsprechend.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}
Speichern Sie die Änderungen, und starten Sie die betreffenden Dienste neu. Damit diese Änderungen übernommen werden, müssen Sie den Spark 2-Dienst neu starten. Über die Ambari-Benutzeroberfläche werden Sie zu einem Neustart aufgefordert. Klicken Sie daher auf „Neu starten“, um alle betreffenden Dienste neu zu starten.
Legen Sie zwei Eigenschaften für Ihre Spark-Sitzung fest, um sicherzustellen, dass der Auftrag auf die aktualisierte Spark-Konfiguration verweist:
spark.yarn.appMasterEnv.PYSPARK_PYTHONundspark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Verwenden Sie die Funktion
spark.conf.setmithilfe des Terminals oder einer Notebooks.spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Fügen Sie die folgenden Eigenschaften im Anforderungstext hinzu, wenn Sie
livyverwenden:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Wenn Sie die neu erstellte virtuelle Umgebung unter Jupyter verwenden möchten, ändern Sie die Jupyter-Konfigurationen, und starten Sie Jupyter neu. Führen Sie Skriptaktionen für alle Hauptknoten mit der folgenden Anweisung aus, um Jupyter auf die neu erstellte virtuelle Umgebung zu verweisen. Stellen Sie sicher, dass Sie den Pfad zu dem Präfix ändern, das Sie für Ihre virtuelle Umgebung angegeben haben. Nachdem Sie diese Skriptaktion ausgeführt haben, starten Sie den Jupyter-Dienst über die Ambari-Benutzeroberfläche neu, um diese Änderung zu übernehmen.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonSie können die Python-Umgebung in Jupyter Notebook doppelt bestätigen, indem Sie den folgenden Code ausführen:
