Data Science mit einer Windows Data Science Virtual Machine
Die Windows Data Science Virtual Machine (DSVM) ist eine leistungsfähige Data Science-Entwicklungsumgebung, die Datenerforschung und Modellierungsaufgaben unterstützt. Die Umgebung ist bereits vorgefertigt und mit mehreren gängigen Datenanalysetools ausgestattet, die Ihnen den Einstieg in die Analyse für lokale, Cloud- oder Hybridbereitstellungen erleichtern.
Die DSVM arbeitet eng mit Azure-Diensten zusammen. Sie kann Daten lesen und verarbeiten, die bereits in Azure, Azure Synapse (früher SQL DW), Azure Data Lake, Azure Storage oder Azure Cosmos DB gespeichert sind. Sie kann auch andere Analysetools nutzen, wie z. B. Azure Machine Learning.
In diesem Artikel lernen Sie, wie Sie Ihre DSVM nutzen können, um sowohl Data Science-Aufgaben zu erledigen als auch mit anderen Azure-Diensten zu interagieren. Dies ist ein Beispiel von Aufgaben, welche die DSVM abdecken kann:
- Verwenden Sie ein Jupyter Notebook, um in einem Browser mit Ihren Daten durch Verwenden von Python 2, Python 3 und Microsoft R zu experimentieren. (Microsoft R ist eine für Unternehmen geeignete Version von R, die auf Hochleistung ausgelegt ist.)
- Erforschen Sie Daten und entwickeln Sie Modelle lokal auf der DSVM mithilfe von Microsoft Machine Learning Server und Python.
- Verwalten Sie Ihre Azure-Ressourcen mit dem Azure-Portal oder PowerShell.
- Erweitern Sie Ihren Speicherplatz und geben Sie umfangreiche Datasets/Codes für Ihr gesamtes Team frei mit einer Azure Files-Freigabe als einbindbares Laufwerk auf Ihrer DSVM.
- Teilen Sie Code mit Ihrem Team mit GitHub. Greifen Sie auf Ihr Repository zu mit den vorinstallierten Git-Clients: Git-Bash und Git-GUI.
- Greifen Sie auf Azure-Daten und -Analysedienste zu:
- Azure Blob Storage
- Azure Cosmos DB
- Azure Synapse (vormals SQL DW)
- Azure SQL-Datenbank
- Erstellen Sie Berichte und ein Dashboards mithilfe der Power BI Desktop-Instanz – die auf der DSVM vorinstalliert ist – und stellen Sie diese in der Cloud bereit.
- Installieren Sie weitere Tools auf Ihrer VM.
Hinweis
Für viele der in diesem Artikel aufgelisteten Datenspeicher- und Analysedienste fallen zusätzliche Nutzungsgebühren an. Weitere Informationen finden Sie auf der Seite Azure-Preise.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Eine bereitgestellte DSVM im Azure-Portal. Weitere Informationen finden Sie in der Ressource Erstellen einer VM.
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Verwenden von Jupyter-Notebooks
Jupyter Notebook stellt eine browserbasierte integrierte Entwicklungsumgebung für Datenauswertung und -modellierung bereit. Sie können Python 2, Python 3 oder R in einer Jupyter Notebook-Instanz verwenden.
Um das Jupyter-Notebook zu starten, wählen Sie das Jupyter Notebook-Symbol im Startmenü oder auf dem Desktop aus. An der DSVM-Eingabeaufforderung können Sie auch den Befehl jupyter notebook aus dem Verzeichnis ausführen, das vorhandene Notebooks hostet oder in dem Sie neue Notebooks erstellen möchten.
Nachdem Sie Jupyter gestartet haben, navigieren Sie zum Verzeichnis /notebooks. In diesem Verzeichnis werden Beispielnotebooks gehostet, die in der DSVM bereits integriert sind. Sie können Folgendes ausführen:
- Das Notebook auswählen, um den Code anzuzeigen.
- Wählen Sie UMSCHALT+EINGABE aus, um jede Zelle auszuführen.
- Wählen Sie Zelle>Ausführen aus, um das gesamte Notebook auszuführen.
- Erstellen eines neuen Notebooks: Wählen Sie das Jupyter-Symbol (obere linke Ecke), die Schaltfläche Neu und dann die Notebooksprache (auch als Kernel bezeichnet) aus.
Hinweis
Zurzeit werden in Jupyter die Kernel Python 2.7, Python 3.6, R, Julia und PySpark unterstützt. Der R-Kernel unterstützt die Programmierung sowohl in Open Source R als auch in Microsoft R. Im Notebook können Sie Ihre Daten erforschen, Ihr Modell erstellen und dieses Modell mit Bibliotheken Ihrer Wahl testen.
Auswerten von Daten und Entwickeln von Modellen mit Microsoft Machine Learning Server
Hinweis
Der Support für Machine Learning Server (eigenständig) endete am 1. Juli 2021. Wir haben es nach dem 30. Juni 2021 aus den DSVM-Images entfernt. Vorhandene Bereitstellungen können weiterhin auf die Software zugreifen, der Support wurde jedoch nach dem 1. Juli 2021 eingestellt.
Sie können R und Python für Ihre Datenanalyse direkt auf der DSVM verwenden.
Für R können Sie R Tools für Visual Studio verwenden. Microsoft stellt zusätzlich zur Open-Source-CRAN R-Ressource weitere Bibliotheken bereit. Diese Bibliotheken ermöglichen sowohl skalierbare Analysen als auch die Möglichkeit, Datenmassen zu analysieren, welche die Speichergrößenbeschränkungen der parallelen Blockanalyse überschreiten.
Für Python können Sie eine IDE – beispielsweise Visual Studio Community-Edition – verwenden, bei der die PTVS (Python Tools für Visual Studio)-Erweiterung vorinstalliert ist. Standardmäßig ist für PTVS nur Python 3.6 (Root-Conda-Umgebung) konfiguriert. So aktivieren Sie Anaconda Python 2.7:
- Erstellen Sie benutzerdefinierte Umgebungen für jede Version. Wählen Sie Tools>Python-Tools>Python-Umgebungen und dann in der Visual Studio Community-Edition + Benutzerdefiniert aus.
- Geben Sie eine Beschreibung an, und legen Sie den Umgebungspräfixpfad für Anaconda Python 2.7 auf c:\anaconda\envs\python2 fest.
- Wählen Sie Automatische Erkennung>Anwenden aus, um die Umgebung zu speichern.
Weitere Informationen zum Erstellen von Python-Umgebungen finden Sie in der Ressource PTVS-Dokumentation.
Sie können jetzt ein neues Python-Projekt erstellen. Wählen Sie Datei>Neu>Projekt>Python und dann den Typ der Python-Anwendung aus, die sie erstellen wollen. Sie können die Python-Umgebung für das aktuelle Projekt auf die gewünschte Version (Python 2.7 oder 3.6) festlegen, indem Sie mit der rechten Maustaste auf Python-Umgebungen klicken und dann Python-Umgebungen hinzufügen/entfernen auswählen. Weitere Informationen zum Arbeiten mit PTVS finden Sie in der Produktdokumentation.
Verwalten von Azure-Ressourcen
Mit der DSVM können Sie Ihre Analyselösung lokal auf der VM erstellen. sondern ermöglicht Ihnen auch, auf Dienste auf der Azure-Cloudplattform zuzugreifen. Azure stellt mehrere Dienste bereit, einschließlich Compute, Speicher, Datenanalyse und weitere, die Sie von Ihrer DSVM aus verwalten und darauf zugreifen können.
Sie haben zwei verfügbare Optionen, um Ihr Azure-Abonnement und Ihre Cloudressourcen zu verwalten:
Besuchen Sie das Azure-Portal in Ihrem Browser.
Verwenden Sie PowerShell-Skripts. Führen Sie Azure PowerShell über eine Desktop-Verknüpfung oder über das Menü Start aus. Weitere Informationen finden Sie in der Ressource Microsoft Azure PowerShell-Dokumentation.
Erweitern von Speicher durch Verwenden von freigegebenen Dateisystemen
Datenanalysten können große Datasets, Code oder andere Ressourcen innerhalb des Teams freigeben. Die DSVM verfügt über etwa 45 GB verfügbaren Speicherplatz. Um Ihren Speicher zu erweitern, können Sie Azure Files verwenden und dies entweder in einer oder mehrere DSVM-Instanzen einbinden oder über eine REST-API darauf zugreifen. Sie können auch das Azure-Portal oder Azure PowerShell verwenden, um zusätzliche dedizierte Datenträger hinzuzufügen.
Hinweis
Der maximale Speicherplatz für eine Azure-Dateifreigabe beträgt 5 TB. Jede Datei hat eine Größenbeschränkung von 1 TB.
Dieses Azure PowerShell-Skript erstellt eine Azure Files-Freigabe:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Sie können eine Azure Files-Freigabe auf einer beliebigen VM in Azure einbinden. Wir empfehlen Ihnen, die VM und das Speicherkonto im selben Azure-Rechenzentrum zu platzieren, um Wartezeit und Datenübertragungsgebühren zu vermeiden. Diese Azure PowerShell-Befehle binden das Laufwerk auf der DSVM ein:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Sie können auf dieses Laufwerk wie auf jedes normale Laufwerk auf der VM zugreifen.
Teilen von Code in GitHub
Das GitHub-Coderepository hostet Codebeispiele und Codequellen für viele Tools, welche die Entwicklercommunity freigibt. Sie nutzt Git als Technologie zum Nachverfolgen und speichern der Versionen der Codedateien. GitHub dient auch als Plattform zum Erstellen Ihres eigenen Repositorys. Ihr eigenes Repository kann den freigegebenen Code und die Dokumentation Ihres Teams speichern, Versionskontrolle implementieren und Zugriffsberechtigungen für Projektbeteiligte steuern, die Code anzeigen und dazu beitragen wollen. GitHub unterstützt die Zusammenarbeit innerhalb Ihres Teams, die Verwendung von Code, der von der Community entwickelt wurde, und die Weitergabe von Code zurück zur Community. Auf den GitHub-Hilfeseiten finden Sie weitere Informationen über Git.
Die DSVM wird mit Clienttools für die Befehlszeile und die grafische Benutzeroberfläche geliefert, um auf das GitHub-Repository zugreifen zu können. Das Befehlszeilentool Git-Bash arbeitet mit Git und GitHub. Visual Studio ist auf der DSVM installiert und hat die Git-Erweiterungen. Sowohl das Menü Start als auch der Desktop verfügen über Symbole für diese Tools.
Verwenden Sie den Befehl git clone zum Herunterladen von Code aus einem GitHub-Repository. Um beispielsweise das von Microsoft veröffentlichte Data Science-Repository in das aktuelle Verzeichnis herunterzuladen, führen Sie den folgenden Befehl in Git-Bash aus:
git clone https://github.com/Azure/DataScienceVM.git
Visual Studio kann denselben Klonvorgang verarbeiten. Dieser Screenshot zeigt, wie Sie in Visual Studio auf Git- und GitHub-Tools zugreifen:

Sie können mit verfügbaren github.com-Ressourcen in Ihrem GitHub-Repository arbeiten. Weitere Informationen finden Sie in der Ressource GitHub-Spickzettel.
Zugreifen auf Azure-Daten und -Analysedienste
Azure Blob Storage
Azure Blob Storage ist ein zuverlässiger, wirtschaftlicher Cloudspeicherdienst für große und kleine Datenressourcen. Dieser Abschnitt beschreibt, wie Sie Daten in Blobspeicher verschieben und auf Daten zugreifen, die in einem Azure-Blob gespeichert sind.
Voraussetzungen
Ein Azure Blob-Speicherkonto, das im Azure-Portal erstellt wurde.

Bestätigen Sie mit diesem Befehl, dass das Befehlszeilentool AzCopy vorinstalliert ist:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeDas Verzeichnis, das azcopy.exe hostet, ist bereits in Ihrer PATH-Umgebungsvariablen enthalten, sodass Sie nicht den vollständigen Befehlspfad eingeben müssen, wenn Sie dieses Tool ausführen. Weitere Informationen zum AzCopy-Tool finden Sie in der AzCopy-Dokumentation.
Starten Sie das Tool Azure Storage-Explorer. Sie können es von der Storage-Explorer-Webseite herunterladen.


Verschieben von Daten von einem virtuellen Computer in ein Azure-Blob: AzCopy
Um Daten zwischen Ihren lokalen Dateien und Blobspeicher zu verschieben, können Sie AzCopy in der Befehlszeile oder in PowerShell verwenden:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Ersetzen Sie C:\myfolder durch den Verzeichnispfad, der Ihre Datei hostet
- Ersetzen sie mystorageaccount durch den Namen Ihres Blob-Speicherkontos
- Ersetzen Sie mycontainer durch den Containernamen
- Ersetzen Sie Speicherkontoschlüssels durch Ihren Blob-Speicherzugriffsschlüssel
Sie finden die Anmeldeinformationen für Ihr Speicherkonto im Azure-Portal.
Führen Sie den AzCopy-Befehl in PowerShell oder an einer Eingabeaufforderung aus. Dies sind AzCopy-Befehlsbeispiele:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Nachdem Sie den AzCopy-Befehl ausgeführt haben, um die Datei in ein Azure-Blob zu kopieren, wird Ihre Datei in Azure Storage-Explorer angezeigt.

Verschieben von Daten von einem virtuellen Computer in ein Azure-Blob: Azure Storage-Explorer
Sie können auch Daten aus der lokalen Datei in Ihrer VM mit dem Azure Storage-Explorer hochladen:
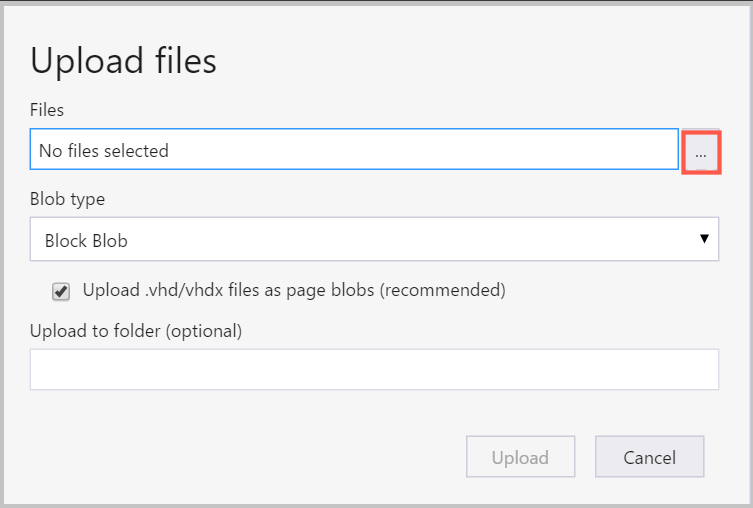
Um Daten in einen Container hochzuladen, wählen Sie den Zielcontainer und dann die Schaltfläche Hochladen aus.
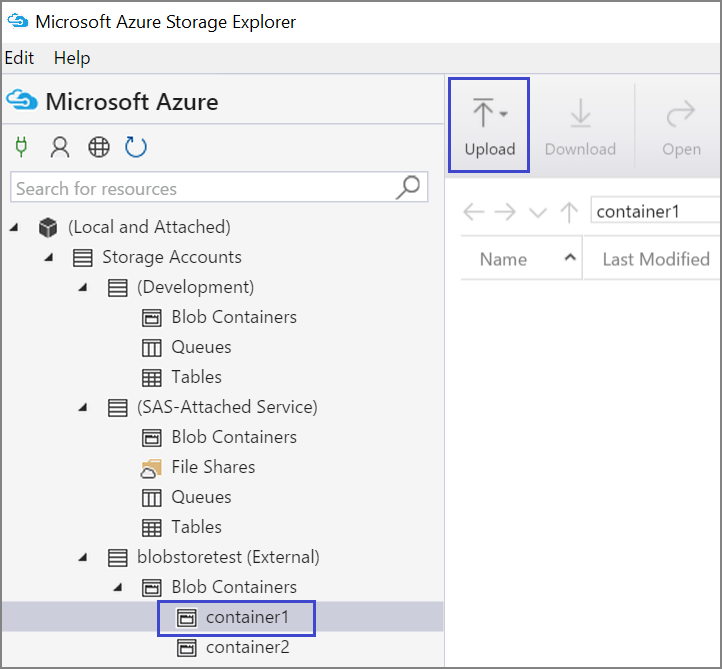
Wählen Sie rechts neben dem Feld Dateien die Auslassungspunkte (...) aus, wählen Sie eine oder mehrere Dateien zum Hochladen aus dem Dateisystem aus, und wählen Sie Hochladen aus, um mit dem Hochladen der Dateien zu beginnen.


Lesen von Daten aus einem Azure-Blob: Python ODBC
Die BlobService-Bibliothek kann Daten direkt aus einem Blob lesen, das sich in einem Jupyter Notebook oder in einem Python-Programm befindet. Importieren Sie zunächst die erforderlichen Pakete:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Tippen Sie Ihre Anmeldeinformationen für das Blobspeicherkonto ein, und lesen Sie Daten aus dem Blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Die Daten werden als Datenrahmen gelesen:

Azure Synapse Analytics und Datenbanken
Azure Synapse Analytics ist ein elastisches „Data Warehouse als ein Dienst“ mit einer SQL Server-Erfahrung der Unternehmensklasse. Diese Ressource beschreibt, wie Azure Synapse Analytics bereitgestellt wird. Nachdem Sie Azure Synapse Analytics bereitgestellt haben, erläutert diese exemplarische Vorgehensweise, wie Sie den Datenupload, die Erforschung und Modellierung handhaben, indem Sie Daten in Azure Synapse Analytics verwenden.
Azure Cosmos DB
Azure Cosmos DB ist eine cloudbasierte NoSQL-Datenbank. Sie kann beispielsweise JSON-Dokumente verarbeiten und die Dokumente speichern und abfragen. Diese Beispielschritte zeigen, wie Sie über die DSVM auf Azure Cosmos DB zugreifen:
Das Azure Cosmos DB Python SDK ist bereits auf der DSVM installiert. Um es zu aktualisieren, führen Sie
pip install pydocumentdb --upgradean einer Eingabeaufforderung aus.Erstellen Sie über das Azure-Portal ein Azure Cosmos DB-Konto und eine Azure Cosmos DB-Datenbank.
Laden Sie das Datenmigrationstool von Azure Cosmos DB aus dem Microsoft Download Center herunter, und extrahieren Sie es in ein Verzeichnis Ihrer Wahl.
Importieren Sie die in einem öffentlichen Blob gespeicherten JSON-Daten (Vulkandaten) nach Azure Cosmos DB. Verwenden Sie dazu die folgenden Befehlsparameter für das Migrationstool. (Verwenden Sie „dtui. exe“ aus dem Verzeichnis, in dem Sie das Datenmigrationstool für Azure Cosmos DB installiert haben.) Geben Sie die Quell-und Zielposition mit diesen Parametern ein:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Nachdem Sie die Daten importiert haben, können Sie zu Jupyter wechseln und das Notebook DocumentDBSample öffnen. Es enthält Python-Code für den Zugriff auf Azure Cosmos DB und zur Verarbeitung einiger einfachen Abfragen. Weitere Informationen zu Azure Cosmos DB finden Sie auf der Dokumentationsseite des Azure Cosmos DB-Diensts.
Verwenden von Power BI-Berichten und -Dashboards
Sie können die im vorherigen Azure Cosmos DB-Beispiel beschriebene Vulkan-JSON-Datei in Power BI Desktop visualisieren, um visuelle Erkenntnisse in die Daten zu erhalten. Dieser Power BI-Artikel enthält detaillierte Schritte. Dies sind die Schritte auf hoher Ebene:
- Öffnen Sie Power BI Desktop, und wählen Sie Daten abrufen aus. Geben Sie diese URL an:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Die JSON-Datensätze, die als Liste importiert wurden, sollten sichtbar werden. Konvertieren Sie die Liste in eine Tabelle, damit Power BI damit arbeiten kann.
- Wählen Sie das Symbol zum Erweitern (Pfeil) aus, um die Spalten zu erweitern.
- Die Position ist ein Feld Datensatz. Erweitern Sie den Datensatz und wählen Sie nur „coordinates“. coordinates ist eine Listenspalte.
- Fügen Sie eine neue Spalte hinzu, um die Listenspalte mit den Koordinaten in eine durch Trennzeichen getrennte LatLong-Spalte zu konvertieren. Verwenden Sie die Formel
Text.From([coordinates]{1})&","&Text.From([coordinates]{0}), um die beiden Elemente im Koordinatenlistenfeld zu verketten. - Konvertieren Sie die Spalte Höhe in eine Dezimalspalte, und wählen Sie die Schaltfläche Schließen und Anwenden aus.
Sie können den folgenden Code als Alternative zu den vorherigen Schritten verwenden. Er beschreibt die Schritte, die im Erweiterten Editor in Power BI verwendet werden, um die Datentransformationen in einer Abfragesprache zu schreiben:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Jetzt befinden sich die Daten in Ihrem Power BI-Datenmodell. Ihre Power BI Desktop-Instanz sollte folgendermaßen aussehen:

Sie können beginnen, Berichte und Visualisierungen mit dem Datenmodell zu erstellen. In diesem Power BI-Artikel wird erläutert, wie Sie einen Bericht erstellen.
Dynamisches Skalieren der DSVM
Sie können die DSVM nach oben und unten skalieren, um die Anforderungen Ihres Projekts zu erfüllen. Wenn Sie die VM weder abends noch an Wochenenden verwenden, können Sie die VM über das Azure-Portal herunterfahren.
Hinweis
Es fallen Computegebühren an, wenn Sie einfach nur die Schaltfläche „Herunterfahren“ für das Betriebssystem auf der VM verwenden. Stattdessen sollten Sie Ihre DSVM über das Azure-Portal oder Cloud Shell freigeben.
Für ein umfangreiches Analyseprojekt benötigen Sie möglicherweise mehr CPU-, Arbeitsspeicher- oder Datenträgerkapazität. Für diesen Fall können Sie VMs mit einer unterschiedlichen Anzahl von CPU-Kernen, Speicherkapazität, Festplattentypen (einschließlich Solid-State-Laufwerken) und GPU-basierten Instanzen für Deep Learning finden, die Ihren Compute- und Budgetanforderungen entsprechen. Die Azure Virtual Machines-Preisseite zeigt die vollständige Liste der VMs zusammen mit deren Compute-Preisen pro Stunde.
Hinzufügen weiterer Tools
Die DSVM bietet vorgefertigte Tools, die viele gängige Datenanalyseanforderungen erfüllen können. Sie sparen Ihnen Zeit, da Sie Ihre Umgebungen nicht einzeln installieren und konfigurieren müssen. Sie sparen Ihnen auch Geld, da Sie nur für Ressourcen bezahlen, die Sie verwenden.
Sie können weitere in diesem Artikel dargestellte Azure-Datendienste und -Analysedienste verwenden, um Ihre Analyseumgebung zu verbessern. In einigen Fällen benötigen Sie möglicherweise andere Tools, einschließlich spezifischer geschützter Partnertools. Sie haben vollen administrativen Zugriff auf die VM, um die Tools zu installieren, die Sie benötigen. Sie können auch andere Pakete in Python und R installieren, die nicht vorinstalliert sind. Für Python können Sie entweder conda oder pip verwenden. Für R können Sie install.packages() in der R-Konsole verwenden, oder Sie verwenden die IDE und wählen Pakete>Pakete installieren aus.
Deep Learning
Zusätzlich zu den Framework-basierten Beispielen können Sie auch eine Reihe umfassender exemplarischer Vorgehensweisen abrufen, die auf der DSVM validiert wurden. Diese exemplarischen Vorgehensweisen helfen Ihnen, Ihre Entwicklung von Deep-Learning-Anwendungen in den Bereichen Bild- und Text-/Sprachanalyse zu starten.
Betreiben neuronaler Netze in verschiedenen Frameworks: Diese exemplarische Vorgehensweise zeigt, wie Sie Code aus einem Framework zu einem anderen migrieren. Sie veranschaulicht auch, wie Sie Modelle und die Runtimeleistung in verschiedenen Frameworks vergleichen.
Eine Schrittanleitung zum Erstellen einer End-to-End-Lösung für das Erkennen von Produkten in Bildern: Die Bilderkennungstechnik kann Objekte innerhalb von Bildern lokalisieren und klassifizieren. Diese Technologie hat das Potenzial, in vielen realen Geschäftsbereichen enorme Vorteile zu bringen. Einzelhändler können diese Technik beispielsweise nutzen, um ein Produkt zu identifizieren, das ein Kunde aus dem Regal genommen hat. Diese Informationen helfen Einzelhandelsgeschäften beim Verwalten des Produktbestands.
Deep Learning for Audio: In diesem Tutorial wird gezeigt, wie Sie ein Deep Learning-Modell für die Erkennung von Audioereignissen für Urban sound datasets trainieren. Außerdem bietet es eine Übersicht darüber, wie mit Audiodaten gearbeitet wird.
Klassifizierung von Textdokumenten: In dieser exemplarischen Vorgehensweise wird gezeigt, wie zwei Architekturen neuronaler Netze erstellt und trainiert werden: Hierarchical Attention Networks und LTSM-Netzwerke (Long Short Term Memory). Diese neuronalen Netzwerke verwenden die Keras-API für Deep Learning, um Textdokumente zu klassifizieren.
Zusammenfassung
In diesem Artikel sind einige Dinge beschrieben, die mit der Microsoft Data Science Virtual Machine möglich sind. Sie können viele weitere Dinge tun, um die DSVM zu einer effizienten Analyseumgebung zu machen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für